完整代码获取关注微信公众号“八宝粥的科研日记”
回复“ Pearson皮尔逊热图”即可获得通道
代码运行问题可添加微信咨询:zhouysh001(八宝粥加油)
一、功能概述
本代码用于对多变量连续型数据进行分布特征展示、变量间相关关系分析及统计显著性检验。程序以 Excel 文件作为数据输入,自动读取其中的全部变量,并将分析结果整合为一幅由两个面板组成的组合图。
左侧面板用于展示各变量的数据分布特征。每个变量分别绘制水平小提琴图,并在小提琴图上叠加原始样本散点、四分位区间和中位数位置。该部分能够同时反映变量的数据集中趋势、离散程度、分布形态、局部密度和异常值情况。
右侧面板采用成对关系矩阵形式展示不同变量之间的统计关系。矩阵对角线展示各变量的直方图和核密度曲线,矩阵下三角展示两两变量之间的散点关系,矩阵上三角展示 Pearson 相关系数、显著性水平及相关性颜色编码。通过这种组合方式,可以在同一幅图中完成单变量分布分析和双变量相关关系分析。
代码运行后会自动生成 PNG 和 PDF 两种格式的图片。其中,PNG 文件适合插入 Word 文档、演示文稿和普通论文排版;PDF 文件具有较好的矢量编辑能力,适合在 Adobe Illustrator、Inkscape 等软件中进一步调整。
不同配色效果展示:
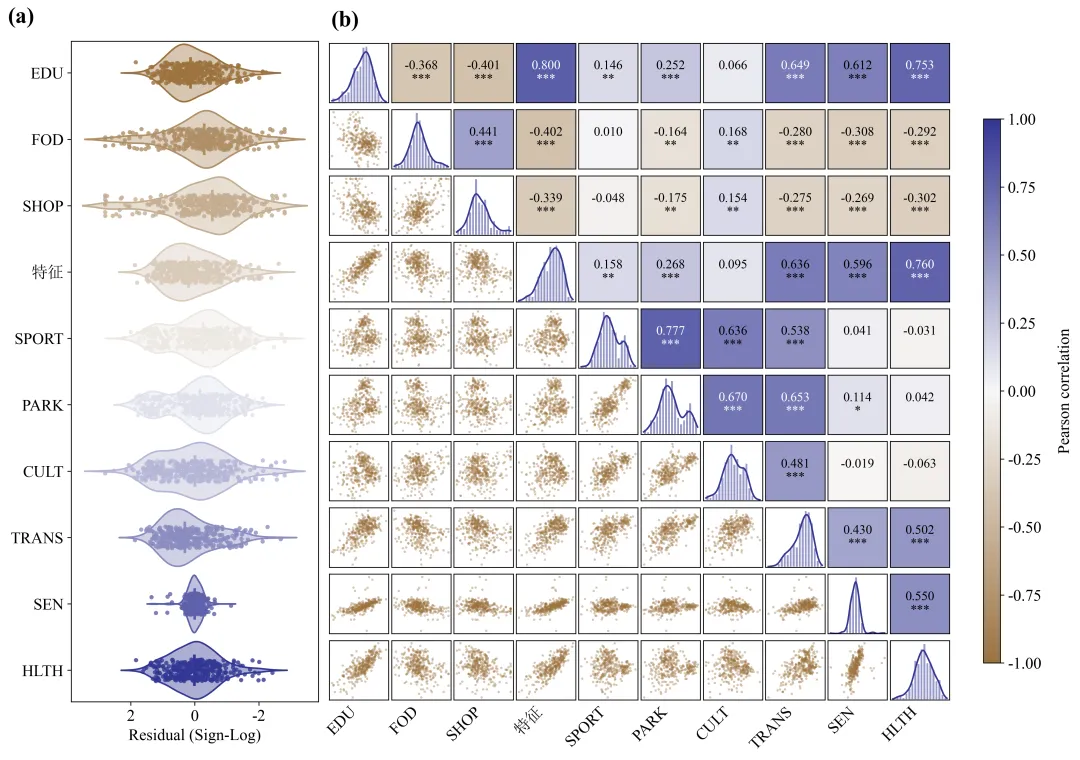
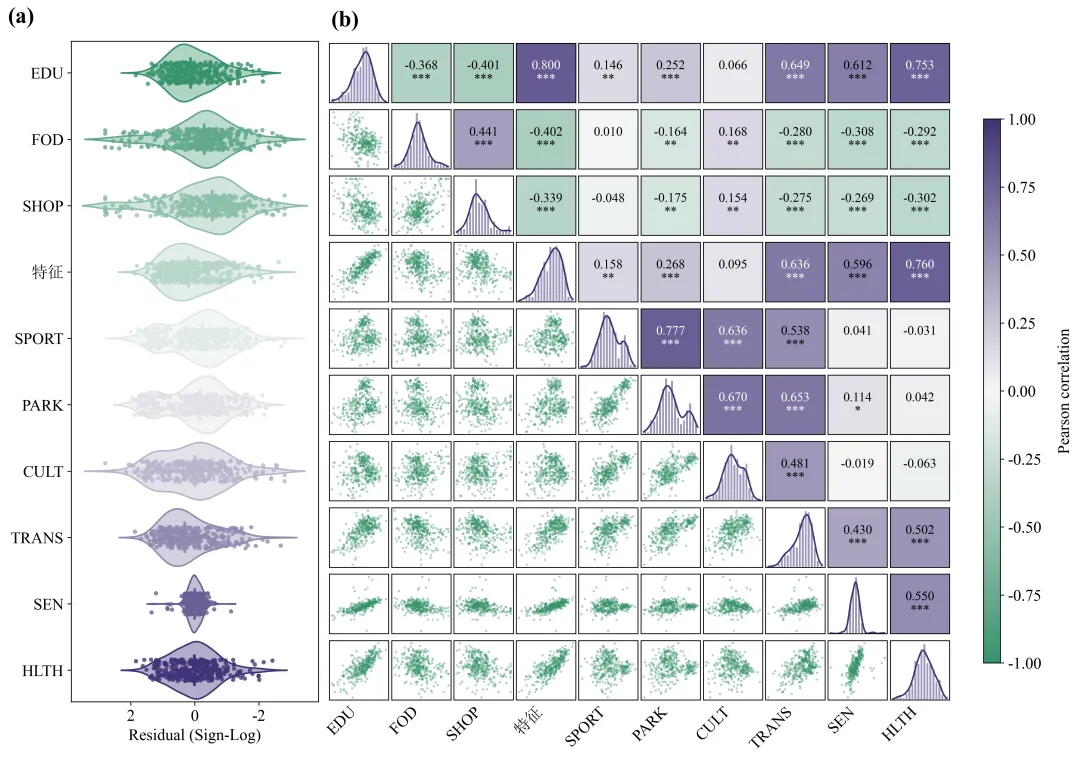
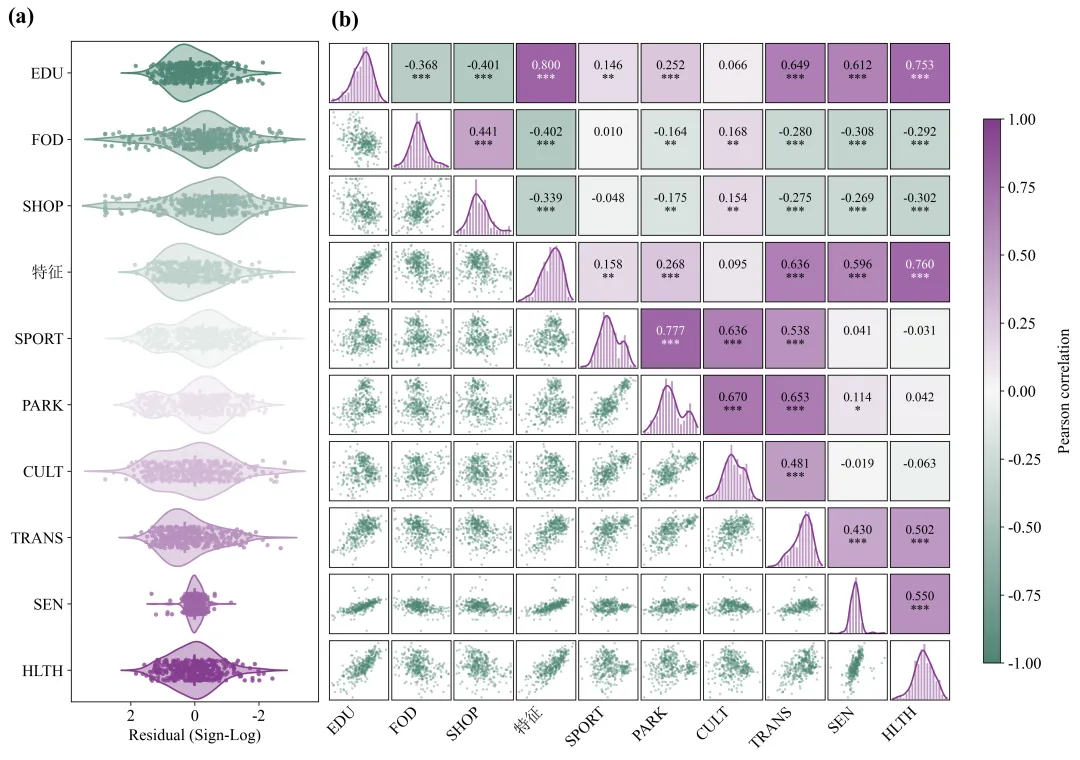
二、运行环境
程序建议在 Jupyter Notebook、JupyterLab、Anaconda 或其他支持 Python 的集成开发环境中运行。为保证代码正常执行,建议使用 Python 3.11以上版本,并确保当前运行环境已经安装数据处理、统计分析、Excel 读取和图形绘制所需的依赖库。
本代码主要使用 pandas 读取和处理 Excel 数据,使用 NumPy 进行数值计算,使用 Matplotlib 和 Seaborn 完成图形绘制,使用 SciPy 计算 Pearson 相关系数和显著性水平,使用 openpyxl 支持 Excel 文件读取。
首次运行代码时,可以先执行批量依赖库安装代码。该代码会自动检查当前 Python 环境中是否存在所需库,并安装缺失的第三方库。安装完成后,建议重新启动 Jupyter 内核,再依次运行全部代码单元格,以避免新安装的库未被当前环境识别。
如果用户采用 Anaconda 环境,应确认 Jupyter Notebook 所调用的 Python 内核与安装依赖库时使用的 Python 环境一致。若依赖库已经安装但运行时仍提示无法导入,通常是由于终端环境与 Notebook 内核不一致造成的。
三、输入数据准备
程序默认读取 Excel 格式的数据文件。输入文件名称在参数配置区的 INPUT_EXCEL 中设置。默认文件名为“示范数据.xlsx”。
在运行程序之前,应将 Excel 文件放置在代码文件(.ipynb和.py格式)所在的同一文件夹中。如果 Excel 文件位于其他位置,则需要在 INPUT_EXCEL 中填写完整文件路径。Windows 系统下建议使用原始字符串形式的文件路径,或者将路径中的反斜杠替换为正斜杠,以避免路径转义问题。
Excel 数据应满足以下基本要求。
第一行必须为变量名称,第二行开始为具体样本数据。每一行代表一个观测样本,每一列代表一个待分析变量。程序会自动读取 Excel 文件中的全部列,因此不需要在代码中逐一填写变量名称。所有参与分析的列原则上都应为数值型变量。程序需要对每一列数据计算分位数、绘制密度分布并进行 Pearson 相关分析。如果数据中包含文本、日期、分类名称或编号等非数值型内容,可能导致计算错误。因此,在导入数据前,应删除不参与分析的样本编号、名称、分类标签和备注列,或者在代码中预先指定需要分析的数值列。
变量名称不宜过长。虽然程序设置了根据字体大小和最长变量名称自动调整左右面板间距的机制,但过长的变量名称仍可能压缩左侧小提琴图的绘图区,或者导致底部标签重叠。论文绘图时建议采用简洁、规范且具有明确含义的变量缩写,并在论文正文或图注中解释缩写含义。
程序执行数据读取后,会使用 dropna 删除包含缺失值的整行数据。也就是说,只要某一个样本在任意变量上存在缺失值,该样本就不会进入后续绘图和相关分析。因此,在正式分析前应检查缺失值比例,并根据研究设计确定采用删除、插补或其他缺失值处理方式。如果数据缺失较多,直接删除完整行可能明显减少有效样本量,并影响相关系数和显著性检验结果。
四、数据适用条件
本代码主要适用于连续型或近似连续型数值变量。Pearson 相关分析主要反映两个变量之间的线性相关方向和线性关联强度。因此,在解释结果前,应结合下三角散点图观察变量关系是否近似线性。
如果两个变量之间存在明显曲线关系、分组结构、极端异常值或严重偏态,仅依据 Pearson 相关系数可能无法完整反映变量关系。此时可以根据研究需要补充 Spearman 等级相关分析、非参数检验或稳健相关分析。
当某一变量所有样本取值完全相同,或者变量方差接近于零时,Pearson 相关系数无法正常计算。正式运行代码前,应检查是否存在常数列、无变化变量或几乎无变化变量,并将这些变量从分析数据中删除。对于具有明确分类属性的变量,例如研究区域、处理组别、性别类型或等级编码,不建议直接将其作为连续变量进行 Pearson 相关分析。即使分类变量以数字形式编码,也不意味着这些数字具有连续测量意义。此类变量应根据研究目的采用适合的分类数据分析方法。
五、依赖库导入说明
代码开头统一导入运行所需的第三方库和 Python 标准库。
pandas 用于读取 Excel 文件、存储数据表并完成缺失值删除、列名提取和分位数计算。
Matplotlib 用于创建总画布、划分子图网格、设置字体和坐标轴、添加颜色条以及保存图片。
Seaborn 用于绘制小提琴图、抖动散点图、直方图和核密度曲线。
NumPy 用于数值计算,并保留与其他绘图或扩展分析功能的兼容性。
SciPy 中的 pearsonr 用于计算变量之间的 Pearson 相关系数和对应的显著性检验结果。
os 模块用于检查输入文件是否存在。当输入路径填写错误或文件不在指定位置时,程序会停止运行并给出文件未找到提示。
Matplotlib 中的颜色和图形集合模块用于构建自定义渐变色、控制小提琴图透明度、边框颜色及多边形显示属性。
六、输入输出路径设置
程序参数配置区中的 INPUT_EXCEL 用于指定输入数据文件。
OUTPUT_PNG 用于设置 PNG 图片的保存名称。
OUTPUT_PDF 用于设置 PDF 图片的保存名称。
建议根据研究内容修改输出文件名。例如,可以使用“变量相关性与分布特征图.png”或“Pearson_correlation_distribution.pdf”等具有明确含义的名称。如果只填写文件名而不填写完整路径,生成的图片会保存在当前 Notebook 所在文件夹中。如果需要将结果保存到指定文件夹,可以在文件名之前增加输出目录。使用指定目录时,应提前确认该文件夹已经存在,否则保存图片时可能出现路径错误。
每次运行程序时,如果输出目录中已经存在同名图片,程序会直接覆盖原有文件。因此,在修改绘图参数或处理不同数据集时,建议同步修改输出文件名,避免重要结果被覆盖。
七、画布与分辨率设置
FIG_DPI 用于设置输出图片的分辨率。程序默认设置为 300 DPI,能够满足多数期刊的图片清晰度要求。如果要求更高分辨率,可以将其提高至 600 DPI。但分辨率越高,PNG 文件体积越大,保存所需时间也可能增加。PDF 文件主要保存为矢量格式,其文字和线条通常不会因放大而明显失真。FIG_WIDTH 和 FIG_HEIGHT 分别控制整幅图的宽度和高度,单位为英寸。默认画布尺寸适用于变量数量较少或中等的情况。当变量数量增加时,右侧成对关系矩阵中的单个格子会逐渐缩小,相关系数文字和变量标签可能变得拥挤。当分析变量较多时,可以适当增大画布宽度和高度,也可以减少全局字体大小、相关系数字体大小和底部标签旋转角度。由于右侧矩阵的子图数量会随着变量数量迅速增加,不建议在同一幅图中放置过多变量。变量数量过多时,应根据研究主题将变量划分为若干组分别绘制。
八、字体设置
程序默认将英文优先设置为 Times New Roman,将中文回退设置为宋体。该设置符合多数中文博士论文中英文和中文混排的基本要求。FONT_FAMILY 用于设置全局字体族。GLOBAL_FONT_SIZE 用于设置全局基础字号。变量标签、坐标轴标题和颜色条标题均会受到该参数影响。程序关闭了负号的 Unicode 显示限制,以避免中文字体环境下负号显示为方框。同时,将 PDF 和 PS 文件的字体类型设置为可编辑形式,便于后期在矢量图形软件中修改文字。如果运行后出现中文乱码,通常说明当前操作系统未安装宋体,或者 Matplotlib 未正确识别字体。Windows 系统通常自带宋体;Linux 或部分服务器环境可能需要安装中文字体,或者将 SimSun 修改为当前系统已经安装的中文字体名称。如果出现“找不到 Times New Roman”提示,可以安装相应字体,或将英文主字体改为其他可用字体。字体替换不会影响统计计算,只影响图形显示效果。
九、绘图解读
该图由变量分布图和Pearson相关性矩阵两部分组成。其中,图(a)采用小提琴图结合原始样本散点的方式,展示不同变量残差的分布形态;图(b)采用对角线分布图、下三角散点图和上三角相关性热图相结合的方式,综合呈现各变量的单变量分布特征及变量之间的两两线性相关关系。
这种组合图能够同时反映变量的中心位置、离散程度、概率密度、异常值、变量间线性关系方向、相关强度和统计显著性。与单独使用相关系数矩阵相比,该图保留了原始样本分布和散点结构,有助于判断相关系数是否受到异常值、非线性关系或样本异质性的影响。
图(a)中各元素的含义及通用解读方法
1.纵坐标变量名称
图(a)的纵坐标依次列出了EDU、FOD、SHOP、特征、SPORT、PARK、CULT、TRANS、SEN和HLTH等变量。每一行对应一个变量,变量排列顺序与图(b)相关性矩阵中的行列顺序一致,因此可以在两个面板之间进行对应分析。
2.横坐标
图(a)的横坐标为经过符号对数处理后的残差,即“Residual(Sign-Log)”。该坐标反映不同变量残差的方向和相对大小。横坐标中的零值表示模型预测值与实际观测值较为接近;正值和负值分别表示两个方向的偏离。由于图中横坐标从左至右按照正值、零值和负值排列,与常规数轴方向相反,因此在解释残差方向时需要特别注意,不能仅根据图形左右位置判断残差正负。符号对数转换通常用于压缩极端残差的数值范围,使正、负残差均能够在同一坐标轴上清晰显示。转换后的数值更适合比较残差的相对分布,但不再直接对应原始残差的绝对量级。
3. 小提琴图外轮廓
每个变量对应的小提琴形状表示残差的核密度分布。小提琴图在某一位置越宽,说明该范围内的样本越集中;图形越窄,说明该范围内的样本数量越少。如果小提琴图在零值附近最宽,说明多数样本残差集中在零附近,模型整体偏差相对较小。如果小提琴图明显偏向某一侧,则可能表明残差存在系统性偏移。如果图形出现两个或多个明显的宽峰,则可能说明样本内部存在不同群体或不同作用机制。小提琴图两端的长尾反映少量较大残差。尾部越长,说明该变量可能存在偏离主体分布较远的样本。需要结合原始散点判断这些样本是连续变化形成的长尾,还是少量孤立的异常值。
4.原始样本散点
叠加在小提琴图上的圆点代表各个观测样本。散点经过轻微的纵向抖动处理,以减少相同或相近数值之间的重叠。散点能够补充核密度图的平滑信息,使样本量、聚集程度和极端观测更加直观。散点集中在零值附近表示大多数样本误差较小;散点向两侧大范围延伸表示残差波动较大;少量散点明显远离主体样本,则提示可能存在异常观测或特殊样本。
5.中心线和主要分布区间
小提琴图内部的横向线段表示数据的主要分布区间,中间的短竖线表示中位数位置。中位数接近零说明变量残差在整体上没有明显的方向性偏差。主要分布区间越长,说明该变量残差的离散程度越大;区间越短,说明多数样本残差较为集中。需要注意,残差分布集中并不必然表示模型在该变量上的预测性能最好,还应结合残差的原始尺度、评价指标和研究对象的实际含义进行判断。
6.小提琴图颜色
图(a)中的颜色由橙色逐渐过渡到紫色,主要用于区分不同变量并与图(b)的整体配色保持一致。小提琴图的颜色本身不代表相关性的正负或强弱,因此不能将图(a)中的橙色直接解释为负相关,也不能将紫色直接解释为正相关。
图(b)中各元素的含义及通用解读方法
1.行列变量
图(b)的横轴和纵轴均为相同的一组变量。矩阵中的每一个格子表示对应行变量与列变量之间的关系。矩阵具有对称性,同一变量组合在上三角和下三角表示的是同一组数据,但采用了不同的可视化形式。上三角用于展示统计结果,下三角用于展示原始散点结构,从而避免重复绘图并提高信息密度。
2.对角线直方图
矩阵对角线上的直方图表示每个变量自身的频数或密度分布。柱体反映样本在不同数值区间内的集中程度。如果直方图近似钟形且左右相对对称,说明变量分布接近单峰对称分布;如果一侧尾部明显较长,则说明变量存在偏态;如果出现两个明显峰值,则可能表明样本中存在不同亚组。
3.对角线核密度曲线
直方图上方叠加的平滑曲线为核密度曲线,用于更加连续地描述变量分布。曲线峰值较高且范围较窄,说明样本高度集中;曲线较平缓且分布范围较宽,说明变量离散程度较大;曲线存在多个局部峰值,则可能提示变量分布具有多峰性或群体异质性。
4.下三角散点图
矩阵下三角区域展示任意两个变量之间的原始样本散点。每一个点表示同一个样本在两个变量上的取值组合。当散点整体由左下方向右上方排列时,通常表示两个变量具有正向关系;当散点由左上方向右下方排列时,通常表示负向关系;当散点呈近似圆形或无明显方向时,说明线性相关性较弱。散点越集中于一条倾斜直线附近,线性相关程度通常越强;散点越分散,线性关系越弱。如果散点呈弧形、扇形或分层结构,则说明变量之间可能存在非线性关系、异方差或群体差异,此时不能仅依靠Pearson相关系数进行解释。
5.上三角相关系数
矩阵上三角区域中的数值为Pearson相关系数。正值表示两个变量同向变化,负值表示两个变量反向变化。相关系数的绝对值越接近1,说明线性相关程度越强;越接近0,说明线性相关程度越弱。通常可以将绝对值低于0.3的关系视为弱相关,0.3至0.5视为中等相关,0.5至0.7视为较强相关,高于0.7视为强相关。但具体划分标准应结合学科特点、样本量和实际研究意义确定,不能机械套用。
6.显著性星号
相关系数下方的星号表示统计显著性水平。按照常见设置,一个星号通常表示达到0.05显著性水平,两个星号表示达到0.01显著性水平,三个星号表示达到0.001显著性水平。没有星号表示该变量组合未达到预先设定的显著性水平。显著性结果与样本量密切相关,样本量较大时,较弱的相关关系也可能达到统计显著。因此,论文中应同时关注相关系数的大小和显著性,不能仅以星号数量判断变量关系的重要性。
7.单元格背景颜色
上三角单元格背景颜色根据相关系数进行映射。橙色表示负相关,紫色表示正相关,接近白色表示相关系数接近零。颜色越深,说明相关系数的绝对值越大;颜色越浅,说明相关关系越弱。颜色只能用于快速识别相关方向和相对强弱,精确判断仍应以单元格中的相关系数数值为准。
8.颜色条
右侧颜色条给出了颜色与Pearson相关系数之间的对应关系。颜色条范围从负相关端过渡到零相关,再过渡到正相关端。该颜色条使不同变量组合的相关方向和强度能够快速比较。图中最深的橙色代表较强负相关,最深的紫色代表较强正相关,浅色区域表示弱相关或无明显线性相关。
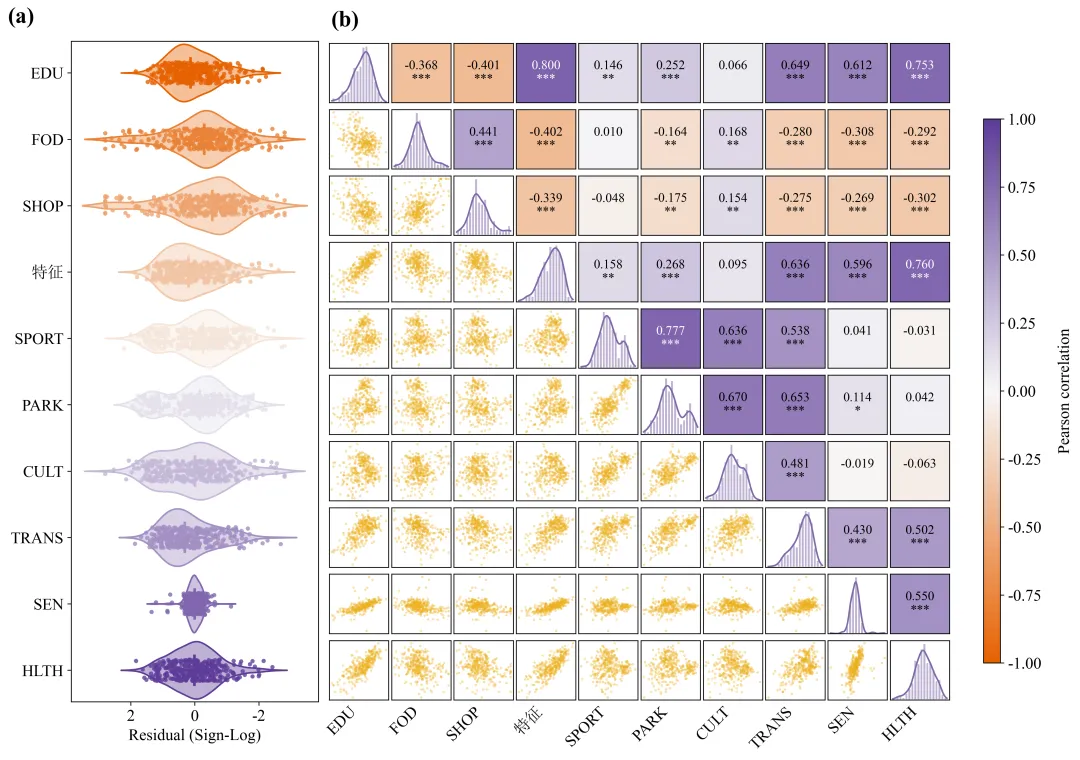
结果解读:
综合变量分布和相关性分析结果可以看出,各变量残差总体围绕零值分布,未表现出明显的整体方向性偏差,但不同变量的残差离散程度存在一定差异。其中,SEN残差分布最为集中,FOD、SHOP、CULT和HLTH的残差波动相对明显,SPORT和PARK的分布则呈现一定的局部多峰或肩峰特征,提示样本内部可能存在异质性。Pearson相关性分析表明,研究变量之间形成了较为清晰的关联结构。EDU、“特征”、TRANS、SEN和HLTH之间总体呈显著正相关,其中EDU与“特征”、“特征”与HLTH以及EDU与HLTH的相关程度较高。SPORT、PARK、CULT和TRANS之间也形成较为稳定的正相关关系,其中SPORT与PARK的相关性最强。FOD与SHOP之间呈显著正相关,但二者与EDU、“特征”、TRANS、SEN和HLTH总体呈负相关。TRANS同时与多个变量群保持显著联系,表明其可能是不同指标体系之间的重要关联变量。
整体而言,该图不仅揭示了各变量的分布特征,也反映了变量之间较为明显的群组化相关结构。但相关性仅表示变量之间的统计关联,不能直接证明因果关系。后续研究仍需结合理论机制、回归模型、因果识别方法或结构方程模型,对变量之间的作用路径及影响机制进行进一步验证。
十、操作流程
本流程面向第一次在电脑上运行 Python 科研绘图代码的用户,内容覆盖 Python 安装、编辑器安装、项目文件夹建立、虚拟环境配置、依赖库安装、Notebook 运行、输出文件检查和常见问题处理。该流程以 Windows 系统为主,同时提供 macOS 和 Linux 的替代命令。
本代码的输入为 Excel 表格,输出为两类图形文件。代码运行后会生成高分辨率 PNG 图像和 PDF 图像,适合用于论文、报告和后期排版。
(1)左侧面板用于展示各变量取值或残差的分布形态,包括小提琴图、散点、四分位线和中位数线。
(2)右侧面板用于展示各变量之间的两两关系,包括对角线分布图、下三角散点图、上三角 Spearman 相关系数和显著性标记。
(3)代码已经将参数配置区和核心执行区分开。一般情况下,只需要修改输入文件名、输出文件名、画布大小、字体和颜色参数,不建议随意修改核心执行逻辑。
1.安装 Python
(1)Windows 系统安装步骤
进入 Python 官方下载页面,下载适合 Windows 的稳定版安装程序。
运行安装程序。安装界面底部通常会出现“Add Python to PATH”选项,建议勾选。该选项用于让系统终端能够直接识别 Python 命令。
点击“Install Now”或根据需要选择自定义安装。普通用户直接使用默认安装即可。
安装完成后,打开“命令提示符”或 PowerShell,检查 Python 是否安装成功。
python --version
pip --version
如果电脑中同时存在多个 Python 版本,Windows 系统也可以使用以下命令检查 Python 启动器。
py --version
py -0p
如果上述命令能够显示 Python 版本号和 pip 版本号,说明 Python 基础安装成功。
(2)macOS 或 Linux 系统检查方式
macOS 和 Linux 可能自带 Python,但科研绘图建议使用独立安装或虚拟环境管理。可以先在终端中运行以下命令检查。
python3 --version
python3 -m pip --version
如果系统提示找不到 Python 或 pip,需要根据系统安装方式重新安装 Python。
2.安装 Python 编辑器
(1)推荐方案:Visual Studio Code
Visual Studio Code 体积较轻,适合运行本代码对应的 Notebook 文件。其官方 Python 扩展支持代码补全、解释器选择、调试和多环境切换;Jupyter 扩展支持直接打开和运行 .ipynb 文件。
步骤1:进入 Visual Studio Code 官方网站并下载安装程序。
步骤2:安装完成后启动 Visual Studio Code。
步骤3:打开左侧扩展面板,搜索并安装 Python 扩展。
步骤4:继续搜索并安装 Jupyter 扩展。
步骤5:打开项目文件夹后,使用命令面板选择当前虚拟环境对应的 Python 解释器。
Ctrl + Shift + P
Python: Select Interpreter
选择解释器时,应选择项目文件夹内虚拟环境对应的 Python。Windows 下通常显示为类似以下路径。
.venv\Scripts\python.exe
(2)备选方案:PyCharm
PyCharm 适合需要完整项目管理、运行配置和调试功能的用户。若使用 PyCharm,应在新建项目时选择本项目的虚拟环境,或在设置中手动指定解释器。
步骤1:安装 PyCharm。
步骤2:打开项目文件夹。
步骤3:进入项目设置中的 Python Interpreter。
步骤4:选择现有虚拟环境,路径指向项目文件夹内的 .venv。
步骤5:确认解释器后,在终端或运行配置中执行代码。
(3)浏览器方案:Jupyter Notebook
如果不想使用 VS Code 或 PyCharm,也可以直接在浏览器中运行 Notebook。该方法适合只需要运行代码、不需要复杂项目管理的用户。
jupyter notebook
命令执行后,浏览器会自动打开本地 Notebook 页面。用户在页面中进入项目文件夹,打开 .ipynb 文件并逐单元运行即可。
3.建立项目文件夹
为了避免路径混乱,建议将代码文件、Excel 数据文件和输出结果放在同一个项目文件夹内。不要将代码放在桌面随机位置,也不要将输入 Excel 文件放在其他路径后再使用相对路径读取。其中,.ipynb 和.py文件为代码文件;Excel 文件为输入数据;PNG 和 PDF 文件为代码运行后的输出结果。第一次运行前,输出文件可以不存在,代码会在运行完成后自动生成。
4.安装代码依赖库
代码运行前,需要安装本代码需要的所有第三方库。
在终端输入:pip install pandas numpy matplotlib seaborn scipy openpyxl jupyter ipykernel
安装完成后,可以运行以下命令检查依赖库是否能够正常导入。
python -c "import pandas, numpy, matplotlib, seaborn, scipy, openpyxl; print('环境配置成功')"
如果终端输出“环境配置成功”,说明基础依赖已经安装完成。
5.准备输入 Excel 数据
本代码通过 pandas 读取 Excel 表格。默认输入文件名为 示范数据.xlsx,因此 Excel 文件应放在项目文件夹中,并且文件名应与代码参数完全一致。
代码读取数据的核心语句如下。
INPUT_EXCEL = "示范数据.xlsx"
df = pd.read_excel(INPUT_EXCEL)
df = df.dropna()
这意味着输入 Excel 需要满足以下要求。
第一行为变量名称,变量名称会直接显示在图形坐标轴和矩阵标签中。
每一列对应一个研究变量,每一行对应一个样本。
用于绘图和相关性分析的列应尽量为数值型数据。
不要在数据区域中使用合并单元格。
不要在表头前方插入空行或说明文字。
如果数据中存在缺失值,代码会通过 dropna 删除包含缺失值的整行样本。缺失较多时,样本量会明显减少。
Excel 中变量列的排列顺序会决定左侧小提琴图的上下顺序,以及右侧矩阵的横纵轴顺序。
建议的数据表格式如下。
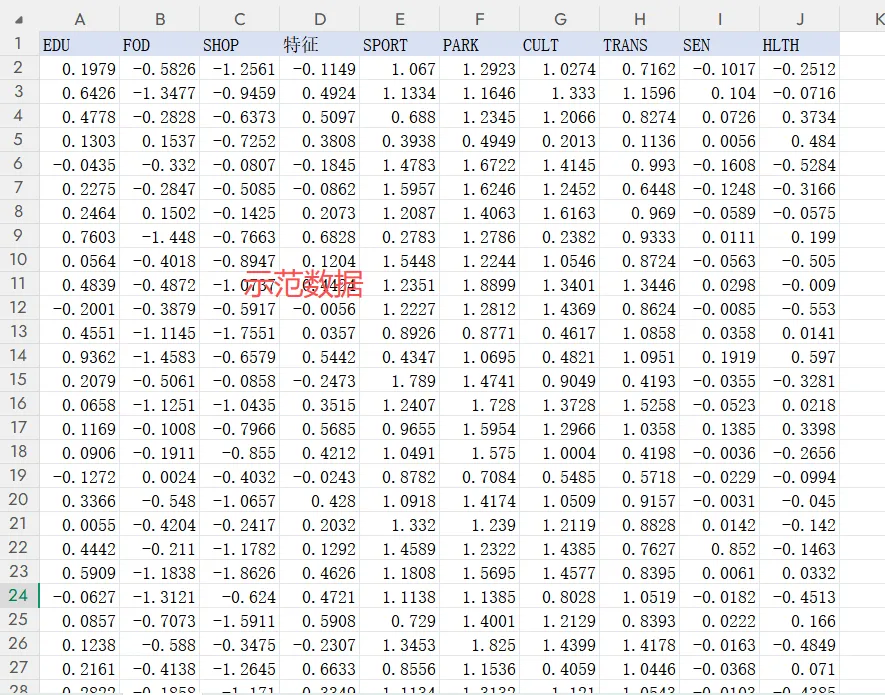
6.VS Code 是本流程推荐的运行方式
操作步骤如下。
步骤1:打开 VS Code。
步骤2:选择“File - Open Folder”,打开项目文件夹。
步骤3:打开 Spearman热图+小提琴图.ipynb 文件。
步骤4:在右上角选择 Notebook Kernel,选择前文注册的 Python (Spearman Violin) 内核。
步骤5:如果没有看到该内核,使用 Python: Select Interpreter 手动选择项目中的 .venv 解释器。
步骤6:确认 Excel 文件已经放在项目文件夹中,且文件名与 INPUT_EXCEL 一致。也可以手动替换Excel表名称。
步骤7:点击 “Run All” 运行全部单元格。
步骤8:等待终端或 Notebook 输出图表保存成功提示。
7.风格调整:

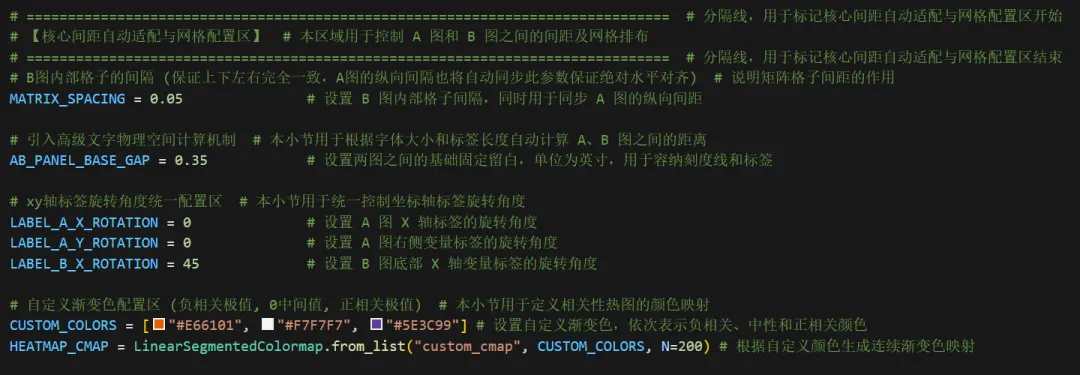
以上内容可以根据自己的需求进行修改编辑。
完整代码获取关注微信公众号“八宝粥的科研日记”
回复“ Pearson皮尔逊热图”即可获得通道
代码运行问题可添加微信咨询:zhouysh001(八宝粥加油)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
