在使用 Linux 作为应用服务器时,若想要查看应用服务器的进程的 CPU 使用率,观察应用的 CPU 使用率是否是并发的限制条件
top 命令是最熟悉、最基础的查看进程对资源占用情况的命令
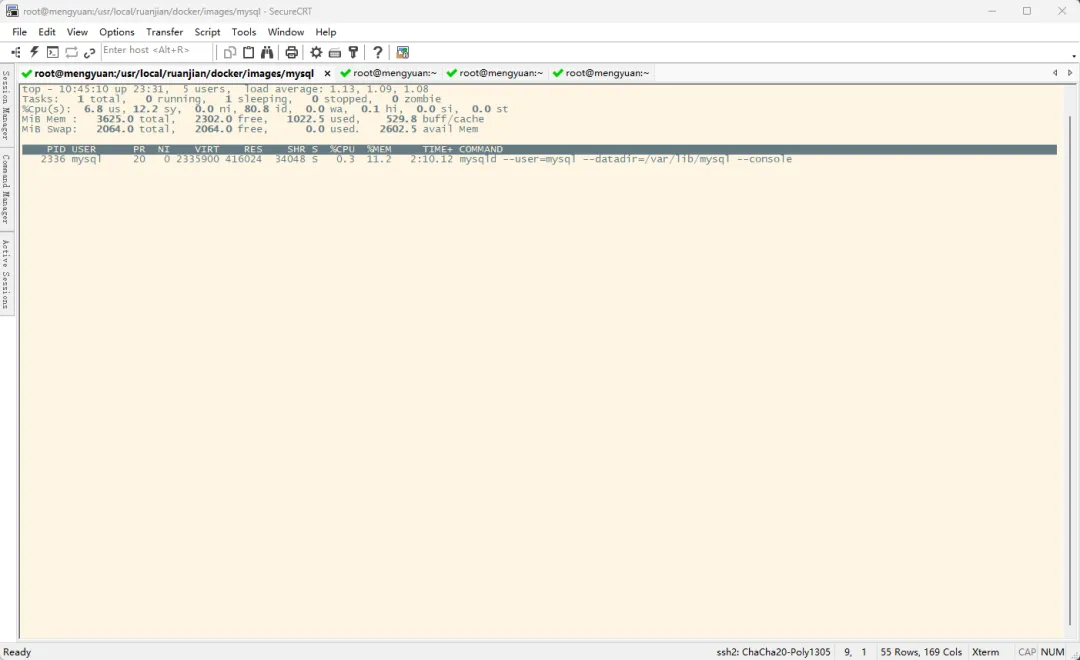
## 参数解析## -p 2336:仅展示PID为2336的进程信息## -c:展示COMMAND的值时,不展示进程名称,而是展示启动进程的启动命令top -p 2336 -c
top 命令被大众熟悉,起手简单
top 命令会采集 CPU 资源信息、内存资源信息、进程信息等大量信息,底层需要读取的文件多、还需要维护状态,属于重量级操作,在初始化时会占用大量 CPU 资源
top 命令对进程 CPU 使用率的第一次采样数据是不准确的:top 命令在获取进程 CPU 使用率时,底层是通过读取 /proc/进程PID/stat 文件内容来计算的。但是这个文件是系统自身维护的,记录的是进程自启动以来的 CPU 信息,所以只有在 3 秒刷新后的第二次采样结果才是正确的
由于 top 命令会采集大量信息,属于重量级操作,在初始化时会占用大量 CPU。这种特性对应用服务产生影响相对较大,不适于进行实时监控、日志采集等的高频场景,但是现场排查问题还是很适合的,毕竟操作非常简单、获取到的信息量又大
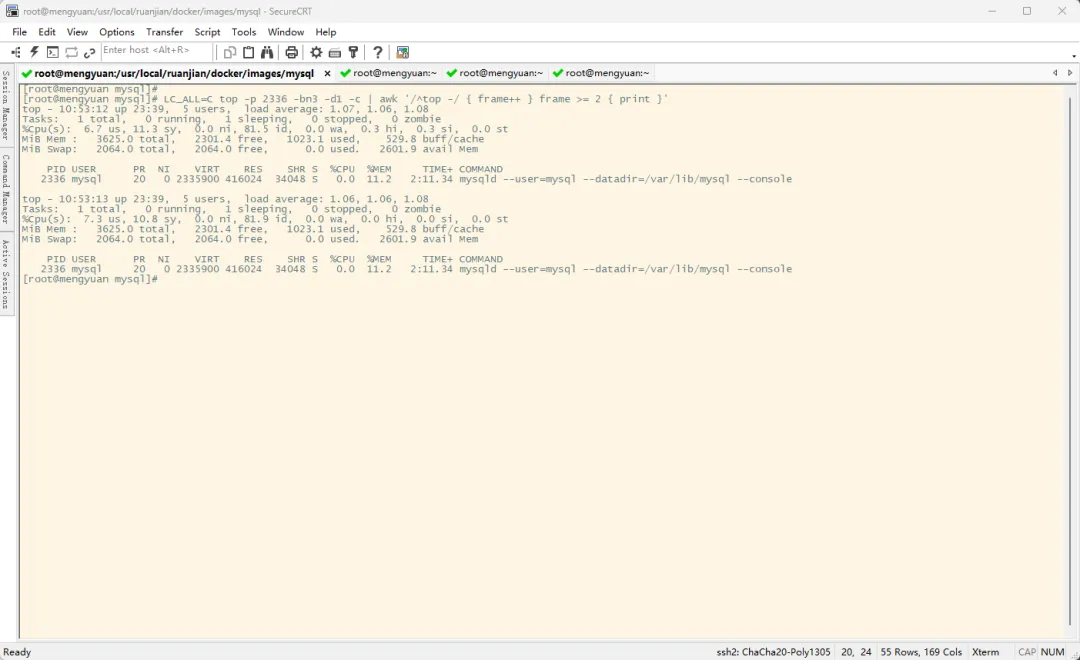
在 top 命令的基础上加参数、加计算,过滤掉第一次结果,仅获取第二次开始的进程信息
## 参数解析## LC_ALL=C:强制使用C语言环境,确保程序输出的格式是英文且可预测## top:命令## -p 2336:仅展示PID为2336的进程信息## -b:top命令的参数,表示非交互式## -n3:top命令的参数,表示执行2次采样输出结果后退出## -d1:top命令的参数,表示采样之间的间隔时间,单位为秒## -c:展示COMMAND的值时,不展示进程名称,而是展示启动进程的启动命令## awk '/^top -/ { frame++ } frame >= 2 { print }'## awk:系统自带的一个强大的文本处理工具,专门用于按行分析、提取和处理结构化文本数据## 命令格式:awk '模式 {动作}'## 模式:对哪些行执行操作,可省略## 动作:对匹配行做什么## 命令结果:对匹配行将以空格进行分割,以格式 $num 可以获取到每一个分割部分,num从1开始## /^top -/:匹配以 top - 开头的行## { frame++ }:每匹配到一行时,对变量frame的值加一## frame >= 2 { print }:当变量frame的值大于等于2时,打印从匹配行开始的后续所有行LC_ALL=C top -p 2336 -bn3 -d1 -c | awk '/^top -/ { frame++ } frame >= 2 { print }'
top 命令会采集 CPU 资源信息、内存资源信息、进程信息等大量信息,底层需要读取的文件多、还需要维护状态,属于重量级操作,在初始化时会占用大量 CPU 资源
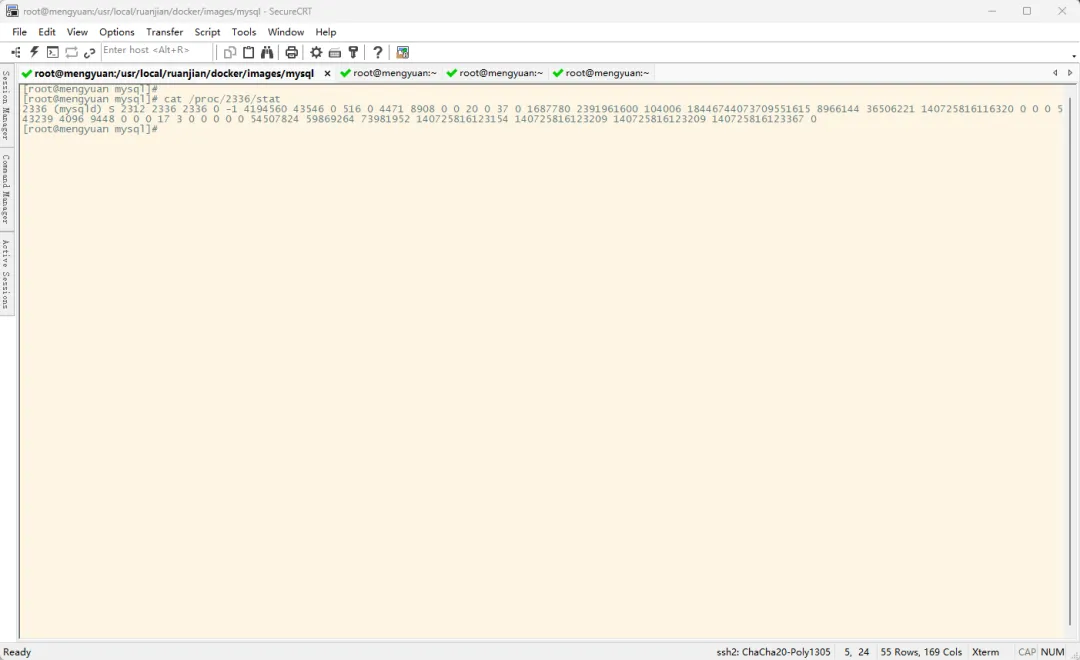
前面讲了 top 命令,该命令底层是通过获取 /proc/进程PID/stat 文件内容来计算 CPU 使用率的,那么 /proc/进程PID/stat 文件是什么呢
/proc/进程PID/stat 文件是每个进程的内核级统计信息文件,包含 CPU 时间、状态、内存等。超级管理员可以访问所有用户拥有的进程的这些文件,但是普通用户只能访问自身拥有的进程的对应的文件
#!/bin/bash# 检查是否传入了PID参数if [ $# -ne 1 ] || ! [[ $1 =~ ^[0-9]+$ ]]; then echo "请传入正确格式的PID" >&2 exit 1fi# 传入的进程IDPID=$1# 采样间隔,设置为1秒INTERVAL=1# 检查 /proc/$PID/stat 是否存在if [ ! -f "/proc/$PID/stat" ]; then echo "进程不存在" >&2 exit 1fi# 第一次采样if stat_line=$(cat "/proc/$PID/stat" 2>/dev/null); then # 将变量的内容按照预定的IFS的值进行分割 set -- $stat_line # 记录用户态CPU时间、内核态CPU时间的总和,若某一个位置没有则默认为0 cpu1=$((${14:-0} + ${15:-0}))else echo "错误:无法读取 /proc/$PID/stat 文件内容(第一次采样)" >&2 exit 1fi# 睡眠sleep "$INTERVAL"# 第二次采样if stat_line=$(cat "/proc/$PID/stat" 2>/dev/null); then # 将变量的内容按照预定的IFS的值进行分割 set -- $stat_line # 记录用户态CPU时间、内核态CPU时间的总和,若某一个位置没有则默认为0 cpu2=$((${14:-0} + ${15:-0}))else echo "错误:无法读取 /proc/$PID/stat 文件内容(第二次采样)" >&2 exit 1fi# 计算两次记录值之间的差值delta=$((cpu2 - cpu1))if [ $delta -lt 0 ]; then delta=0fi# 获取进程名称cmd=""# 1. 优先获取启动进程的完整命令if [ -f "/proc/$PID/cmdline" ]; then cmd=$(tr '\0' ' ' < "/proc/$PID/cmdline" 2>/dev/null) cmd=$(echo "$cmd" | sed 's/ $//')fi# 2. 若没有获取到启动进程的完整命令,则获取进程名称if [ -z "$cmd" ] && [ -f "/proc/$PID/comm" ]; then cmd=$(cat "/proc/$PID/comm" 2>/dev/null | tr -d '\n')fi# 3. 若没有获取到启动进程的完整命令、也没有获取到进程名称,则直接使用PIDif [ -z "$cmd" ]; then cmd="[$PID]"fi# 根据差值和间隔时间计算平均CPU使用率cpu_pct=$(awk "BEGIN {printf \"%.1f\", $delta / $INTERVAL}")# 格式化输出打印printf "PID:%-8s CPU:%6s%% CMD:%s\n" "$PID" "$cpu_pct" "$cmd"
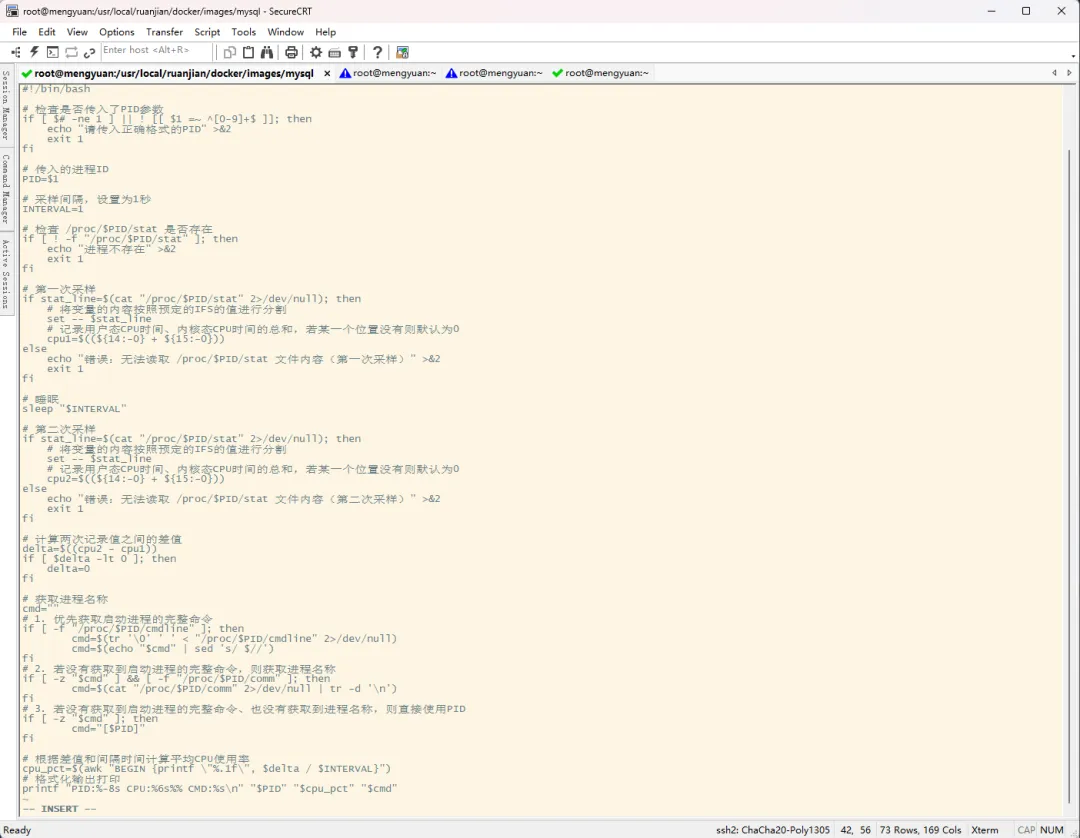
直接从底层文件入手来计算 CPU 使用率,性能高、资源占用少、最灵活
需要自己写脚本,对开发人员、维护人员要求高
现场问题排查使用此种方式不合适、耗时太久,但是非常适用于实时监控、日志采集等高频场景
现场排查问题,推荐使用 top 命令;高效、高频获取 CPU 使用率时,推荐使用命令脚本