Python模块化从入门到精通(2)
- 2026-07-03 23:47:11
import的背后你深入研究过吗(核心部分)
和函数用来实现代码复用一样,Python 模块化开发目的也是实现代码解耦、提高可维护性和复用性。实现方法是将代码拆分为独立、可复用的模块,通过模块的导入与导出来实现代码解耦、可维护性和复用性。其底层逻辑是基于 Python 的模块搜索路径和命名空间机制,从基础的单文件模块到复杂的包结构,形成了一套完整的模块化体系。
上一篇讨论模块化开发基础部分,<Python模块化从入门到精通(1)> 包括:模块的基础概念、模块导入、导出的几种方式、包的概念,以及如何规划包。本篇讨论 import 的核心细节,也许不是你理解的import、模块的搜索路径、Python如何临时操作环境变量。以及以Pandas为例看看import的过程
五、import 详解
理解 import 模块的完整执行过程,是 Python 程序员从“初级”向“中高级”跨越的核心标志之一。这背后不仅是掌握一个语法的细节,更是对 Python 解释器运行机制、命名空间、工程化思维的深度理解,也是区分“会用 Python 写脚本”和“能设计可维护的 Python 项目”的关键分水岭。
5.1 为什么说这是“初级 到 中高级”的核心标志?
5.1.1 初级程序员 vs 中高级程序员对 import 的认知差异
5.1.2 理解 import 背后,你真正掌握的核心能力
import 的执行过程看似是“一个语法的细节”,实则串联了 Python 最核心的底层机制,而这些正是高级程序员必须吃透的:
• 命名空间与作用域:理解模块是独立的命名空间,能区分“模块命名空间”“全局命名空间”“局部命名空间”的边界,避免变量/函数名冲突; • 解释器运行机制:掌握“代码编译 → 执行”的流程(模块顶层代码的执行时机、函数/类对象的创建逻辑),理解 Python 是“解释型但有字节码缓存”的特性; • 工程化思维:从“单文件脚本”升级到“模块化包结构”,能按功能拆分模块、控制接口暴露、解决循环依赖,这是开发大型项目的基础; • 问题排查能力:面对 ModuleNotFoundError、循环导入、导入后变量未定义等问题,能从“模块加载流程”出发定位根因,而非靠“猜”。 • 深入理解 import:这不是进阶的唯一标志,但却是“必经之路”。Python 从初级到高级的跨越,还有其他标志(如理解装饰器/生成器的底层、掌握并发编程、性能优化、设计模式等),但理解 import 的执行过程是最基础也最核心的一步——因为模块化是所有大型项目的基石,而 import 是模块化的核心语法,连模块加载的底层逻辑都不懂,就无法设计健壮的项目结构。
5.2 那 import 模块到底做了什么?
当 import 模块 触发模块加载时,“初始化”的核心是逐行执行模块文件的顶层代码,并将执行结果存入模块对象的命名空间(__dict__)。具体包含以下所有动作:
module 类型),为后续初始化预留命名空间 | ||
VERSION = "1.0")会存入模块对象的 __dict__ | ||
def 函数名() 语句时,创建函数对象并绑定到模块命名空间 | ||
class 类名() 语句时,创建类对象(本质是 type 的实例)并绑定到模块命名空间 | ||
关键结论:函数/类/全局变量的创建,不是解释器“额外做”的动作,而是执行
def/class/变量赋值这些顶层代码时,自然产生的结果。
5.2.1 直观示例:拆解模块初始化的每一步
创建 demo_module.py 模块文件,包含各类顶层代码:
# demo_module.py - 包含多种顶层代码print("--[顶层代码]开始执行模块初始化--") # 顶层打印语句# 1. 全局变量(顶层赋值语句)MODULE_VAR = 100GLOBAL_LIST = [1, 2, 3]# 2. 函数对象(顶层def语句)def demo_func():print("函数内部代码(初始化时不执行)")return MODULE_VAR# 3. 类对象(顶层class语句)class DemoClass:# 类体中的代码也是“类的顶层代码”,初始化时执行 CLASS_VAR = MODULE_VAR * 2print(f"[类顶层代码] DemoClass的CLASS_VAR初始化:{CLASS_VAR}")def __init__(self):self.instance_var = "实例变量"# 4. 顶层循环/条件判断(会执行)for i in range(2):print(f"[顶层循环],执行第{i+1}次,GLOBAL_LIST={GLOBAL_LIST}")print("--[顶层代码] 模块初始化完成--")当执行 import demo_module 时,模块初始化的具体过程(按顺序):
1. 创建空模块对象:解释器生成 <module 'demo_module' from 'xxx/demo_module.py'>,此时模块的 __dict__为空;2. 执行顶层打印:输出 --[顶层代码]开始执行模块初始化--; 3. 全局变量赋值: • 执行 MODULE_VAR = 100, 模块对象的 MODULE_VAR 被赋值为 100; • 执行 GLOBAL_LIST = [1,2,3],模块对象的 GLOBAL_LIST 被赋值为列表对象; 4. 创建函数对象:执行 def demo_func() → 创建函数对象,绑定到模块的 demo_func 属性(函数内部的代码不执行,仅定义); 5. 创建类对象:执行 class DemoClass: → 进入类体执行:
• 执行 CLASS_VAR = MODULE_VAR * 2 → 类对象的 CLASS_VAR 被赋值为 200; • 执行类内的 print → 输出 [类顶层代码] DemoClass的CLASS_VAR初始化:200; • 类体执行完成 → 类对象 DemoClass 被绑定到模块的 DemoClass 属性;
6. 执行顶层循环:
• 循环 2 次,依次输出:[顶层循环】执行第1次,GLOBAL_LIST=[1,2,3][顶层循环】执行第2次,GLOBAL_LIST=[1,2,3]
7. 执行最后一行打印:输出 --[顶层代码】模块初始化完成]--; 8. 初始化结束:模块对象的 __dict__中已包含MODULE_VAR、demo_func、DemoClass等所有顶层定义的成员。
5.2.3 容易混淆的关键细节(修正/补充)
1. “执行代码”≠“执行函数/方法内部代码”: • 模块初始化时,仅执行「顶层代码」(函数/类定义外的代码、类体中的代码); • 函数内部的代码(如 demo_func里的print)、类的方法内部代码(如__init__),只有在调用时才执行,初始化阶段仅“定义”不“执行”。2. 初始化仅执行一次: • 多次 import demo_module不会重复初始化,只会复用已创建的模块对象;• 若需重新初始化,需用 importlib.reload(demo_module)(会重新执行所有顶层代码,覆盖原有对象)。3. __name__与if __name__ == "__main__":前面已经讨论过了,再了解一遍:• 模块初始化时, __name__会被赋值为模块名(如demo_module);• 因此 if __name__ == "__main__":代码块不会执行(仅直接运行模块时执行),这也是“模块复用代码”和“模块独立运行代码”的隔离方式。
5.2.4 多层次包的内部 import
这个话题会更一次加深,模块是 隔离命名空间的这个细节。进一步理解上面嵌套包的导入方式。我们用最简单易懂的例子来理解这个概念:
依然是上面定义过的包结构:
my_project/├── main.py└── my_package/ # 父包 ├── __init__.py ├── core.py ├── utils.py └── sub_package/ # 子包(嵌套在my_package内) ├── __init__.py └── helper.py # 子包内的模块一步步实现如何把 helper.py 模块中的函数定义为 my_package 模块中的函数:
逐层暴露 helper.py 中的函数到顶层 my_package 中,同时了解暴露后 my_package 的
__dict__结构。下面将分步骤实现逐层暴露,并详细解析__dict__的组成。
首先我们给相关文件补充具体代码,方便后续逐层暴露操作:
# my_package/sub_package/helper.py(定义要暴露的函数):# helper.pydefprint_info(msg):"""子包模块中的目标函数,需要逐层暴露到my_package"""returnf" test {msg}"# 模块内私有函数(仅作对比,不暴露)def_private_helper():return"私有辅助函数"初始状态下
my_package/sub_package/__init__.py和my_package/__init__.py为空,后续逐步修改。
步骤 1:第一层暴露(helper.py → sub_package 子包)修改 my_package/sub_package/__init__.py,通过相对导入将 helper.py 的 print_info 函数导入到 sub_package 子包的命名空间中,实现 helper.py 函数向 sub_package 的暴露:
# my_package/sub_package/__init__.py# 相对导入:从当前子包的helper模块导入print_info函数# . 表示当前包(sub_package),实现 helper.py → sub_package 的暴露from .helper import print_info# 可选:若需要批量控制sub_package的导出,可添加__all____all__ = ["print_info"] # 指定 from sub_package import * 时导出的成员此时,print_info 已成为 sub_package 子包的公开成员,外部可通过 from my_package.sub_package import print_info 直接导入。
步骤 2:第二层暴露(sub_package 子包 → my_package 父包)修改 my_package/__init__.py,同样通过相对导入,将 sub_package 中已暴露的 print_info 函数导入到 my_package 顶层父包的命名空间中,完成逐层暴露的最后一步:
# my_package/__init__.py# 相对导入:从当前父包的sub_package子包导入print_info函数# . 表示当前包(my_package),实现 sub_package → my_package 的暴露from .sub_package import print_info# 可选:控制my_package的批量导出__all__ = ["print_info"] # 指定 from my_package import * 时导出的成员# 可选:my_package的其他内置属性(如版本号,仅作演示)__version__ = "1.0.0"至此,逐层暴露完成!外部无需关注深层的 sub_package 和 helper.py,可直接从顶层 my_package 导入 print_info 函数:
# main.py 测试导入from my_package import print_info# 正常调用,验证暴露成功result = print_info("直接访问底层的print_info")print(result)此时,my_package 模块的 __dict__ 结构解析
Python 中,包(my_package)本质是一个模块(其载体是 __init__.py 文件),包的 __dict__ 就是其 __init__.py 模块的命名空间字典,存储了包的所有公开属性、导入的成员、内置特殊属性等。
在完成上述逐层暴露后,我们通过代码获取 my_package 的 __dict__:
# main.pyimport my_package# 打印my_package的__dict__print("my_package 的 __dict__ 内容:")for key, value in my_package.__dict__.items():print(f"{key}: {value}")此时会看到很多信息,__name__、__file__等,先不去关心这些,感兴趣的可以自行延伸阅读。还会看到 print_info,<function print_info at 0x...> 这个从包最下层 helper.py 中导出的函数对象。print_info 实际仍定义在 helper.py 中,my_package 和 sub_package 的 print_info 只是指向该函数的别名。
__dict__ 是其 模块的命名空间字典,包含 <内置特殊属性>,我们利用包的 __init__.py 实现导入提升,完善模块的命名空间,本质是创建函数引用,而非移动函数本身。
总结(捋一遍 import)import 语句创建并初始化模块对象的过程:
1. 检查模块是否已加载(是否在 sys.modules 缓存),没有则创建空的模块对象( module实例)继续下面的流程;2. 查找模块的文件路径(sys.path 搜索),定位到包的入口 3. 逐行执行模块的顶层代码(所有不在函数/方法内部的代码); 4. 顶层代码执行的结果: • 全局变量完成赋值(存入模块对象); • def语句执行 → 创建函数对象(存入模块对象);• class语句执行 → 先执行类体代码,再创建类对象(存入模块对象);• 其他顶层代码(print、循环、import 等)按顺序执行; 5. 模块对象初始化完成,存入 sys.modules中缓存供后续复用。6. 绑定到当前命名空间
六、模块的搜索路径是如何确定的?
Python 模块搜索路径的确定规则,这是 Python 能够成功导入模块/包的核心基础。下面将从搜索路径的载体、核心组成(确定方式)、搜索顺序、修改方法及注意事项展开详细讨论:
6.1 模块搜索路径的载体 sys.path
Python 的模块搜索路径存储在 sys 模块的 sys.path 属性中,该属性是一个字符串列表,列表中的每个元素都是一个「目录路径」,Python 解释器会在这些目录中查找需要导入的模块/包。
验证方式
# 任意Python脚本或交互式终端中执行import sys# 打印模块搜索路径列表print("Python模块搜索路径(sys.path):")for index, path inenumerate(sys.path):print(f"{index + 1}. {path}")运行后会输出一系列目录路径,这些就是 Python 解释器的模块搜索路径,模块的搜索过程就是在这些目录中依次查找的过程。
6.2 模块搜索路径的顺序
6.2.1 优先级最高:当前执行脚本的所在目录
当你通过 python 脚本名.py 命令执行某个 Python 脚本时,该脚本所在的目录会被自动加入 sys.path 的首位(索引 0),成为优先级最高的搜索路径。
6.2.2 优先级第二:环境变量 PYTHONPATH 配置的目录
PYTHONPATH 是 Python 专属的环境变量,用于手动指定自定义模块的搜索目录。Python 解释器启动时,会自动将 PYTHONPATH 中配置的所有目录按顺序加入 sys.path(位于当前执行脚本目录之后)。临时有效,终端关闭后失效
• 查看方式: • Linux/Mac:终端执行 echo $PYTHONPATH • Windows:命令提示符执行 echo %PYTHONPATH% • 设置方式: • Linux/Mac:export PYTHONPATH=/自定义目录1:/自定义目录2:$PYTHONPATH • Windows:set PYTHONPATH=\自定义目录1;\自定义目录2;%PYTHONPATH% • 用途:当自定义模块不在当前执行脚本目录时,可通过 PYTHONPATH 指定其路径,避免手动修改 sys.path。
6.2.3 优先级第三:Python 标准库目录
Python 安装目录下的「标准库目录」会被自动加入 sys.path,该目录存放着 Python 内置模块(如 sys、os、math、datetime 等),无需用户手动配置。特性:该目录的优先级低于 PYTHONPATH,确保用户自定义模块不会被标准库模块覆盖。
6.2.4 优先级最低:第三方库目录 site-packages
site-packages 目录是 Python 存放第三方库(通过 pip install 安装的库,如 numpy、pandas、requests 等)的默认目录,Python 解释器会自动将其加入 sys.path 的末尾。特性:优先级最低,避免第三方库覆盖用户自定义模块和标准库模块。
七、python 操作环境变量
在 Shell 中,export用于设置环境变量并让子进程继承,Python 中没有export关键字,需通过os模块操作环境变量:
1. 设置环境变量
import os# 方式1:直接赋值(临时有效,仅当前Python进程)os.environ["MY_ENV_VAR"] = "hello_python"# 方式2:Windows系统下(兼容方式,不推荐跨平台使用)# os.putenv("MY_ENV_VAR", "hello_python")2. 读取环境变量
import os# 方式1:直接读取(推荐,不存在时返回None)my_env = os.environ.get("MY_ENV_VAR")print(my_env) # 输出:hello_python# 方式2:通过key读取(不存在时报错)# my_env = os.environ["MY_ENV_VAR"]注意
• Python 中设置的环境变量仅在当前 Python 进程及其子进程中有效,进程退出后失效,无法像 Shell 的 export那样修改系统全局环境变量。• 若需永久设置环境变量,需通过操作系统本身的配置(如 Linux 的~/.bashrc、Windows 的系统环境变量设置)。
通过「命名约定」和「特殊变量」「标准库」实现对应功能。
最后:学习 Pandas 的导入导出细节
Pandas 是 Python 结构化数据处理与分析的核心库,是每个 python 开发者几乎都要接触到的库。安装 Pandas 就不赘述了,下面 使用 vs code 新建一个 pandas_study.py,只写入一句
import pandas
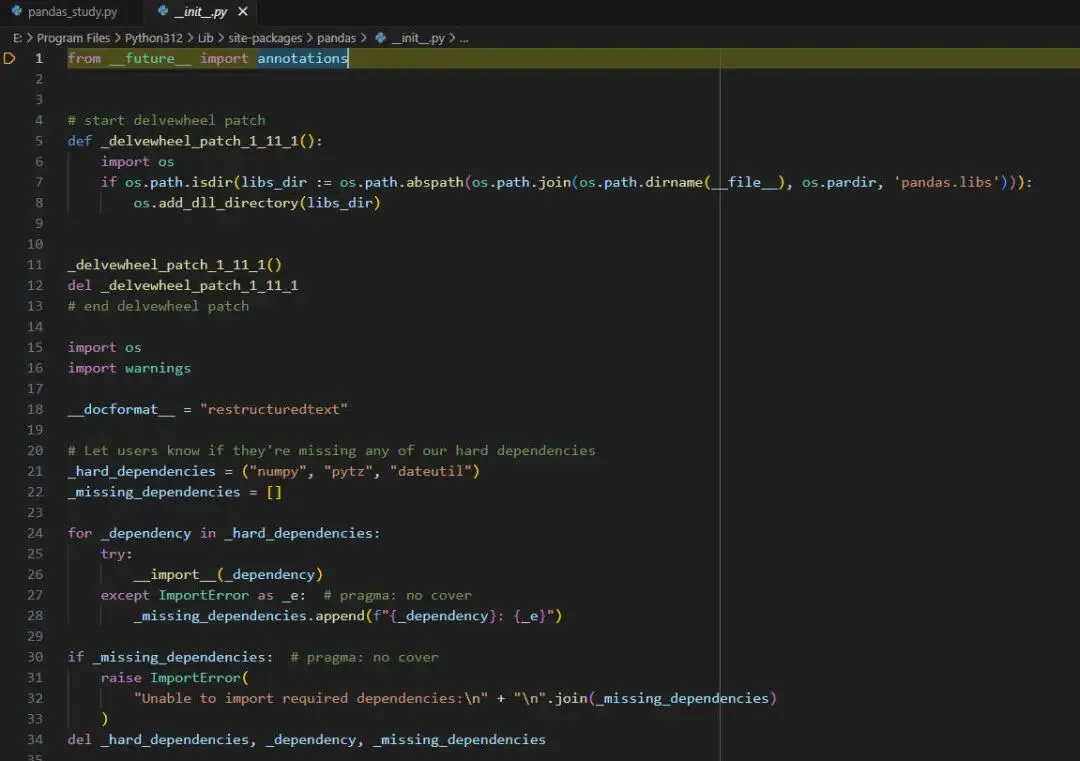
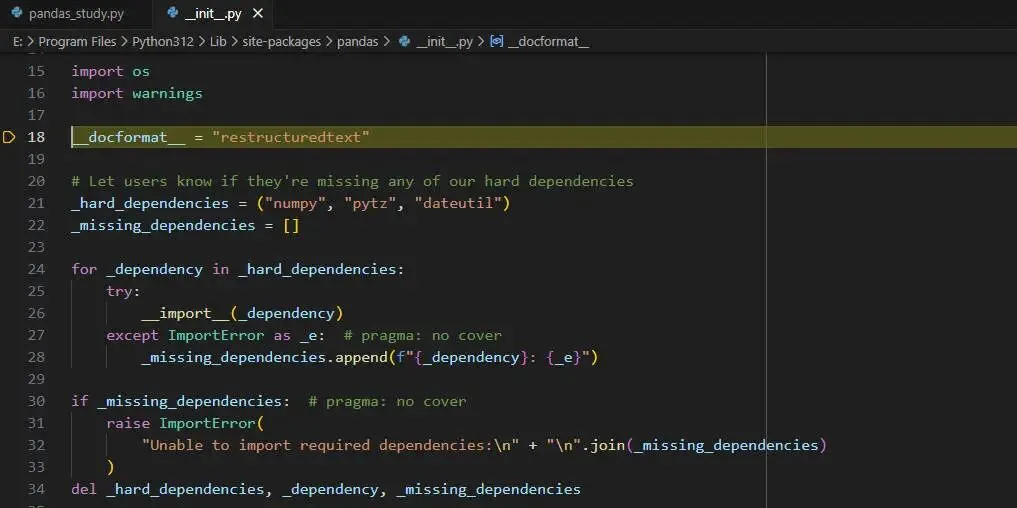
Pandas 初始化阶段的强制依赖检查代码,依赖("numpy", "pytz", "dateutil")3 个库,是 Pandas 能够正常启动的前置保障,用于提前校验核心必需依赖是否安装,避免后续运行时出现隐性错误。检查 Pandas 运行必需的强制依赖库,若存在缺失的强制依赖,主动抛出清晰的 ImportError 异常,执行完毕后清理临时变量,避免污染 Pandas 的模块命名空间,是我们学习工程化编码的好例子。
__import__是动态导入的方法,允许使用变量作为参数来执行,返回值可以赋值给本命名空间中的变量来使用导入的库,此处 pandas 用于检验是否安装这几个依赖库。
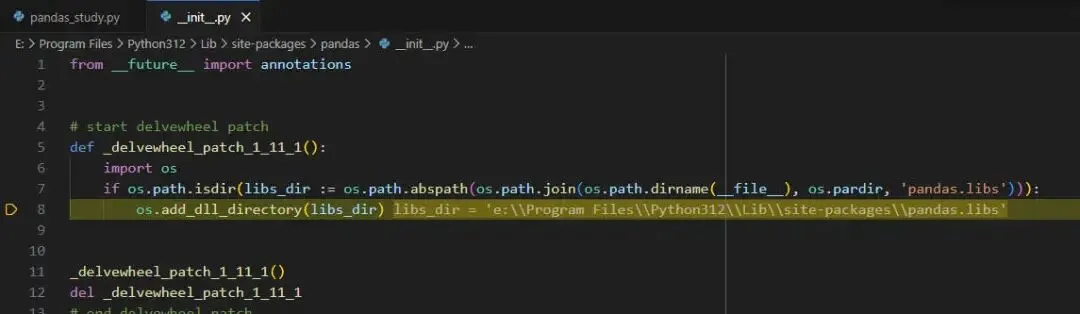
继续运行:
然后 F11 单步进入: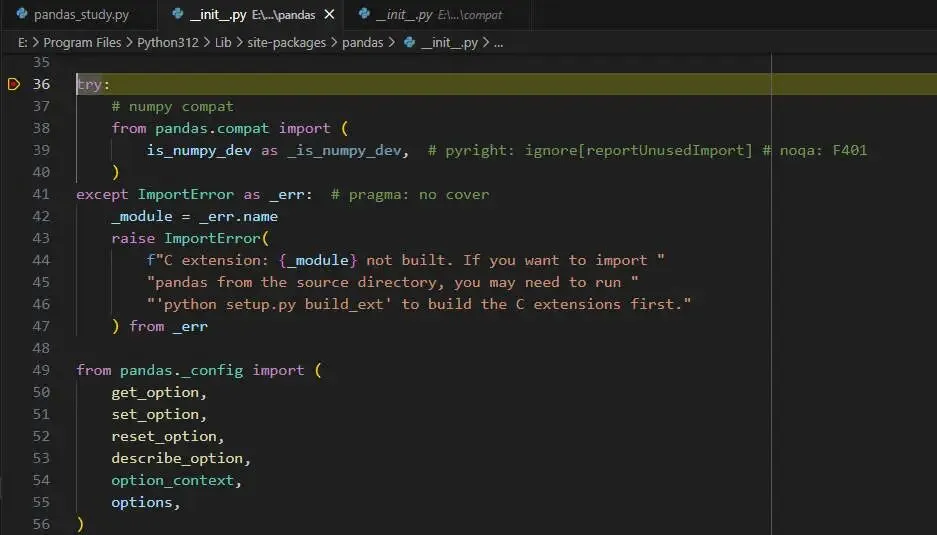
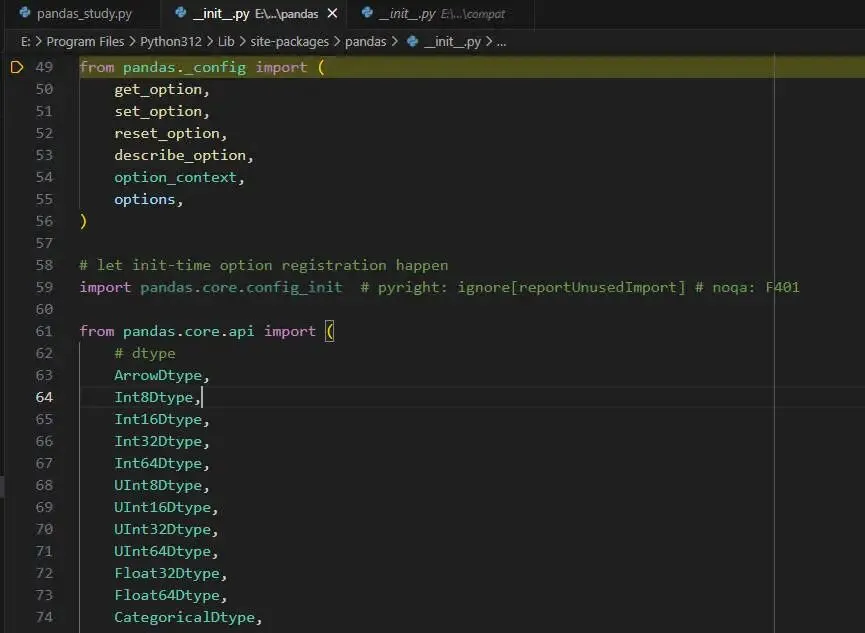
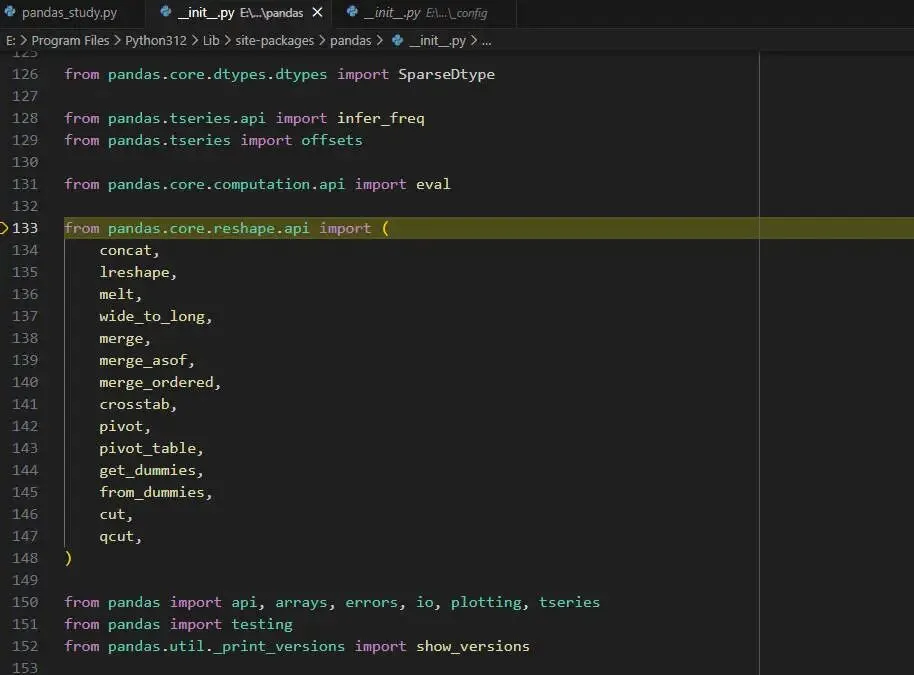
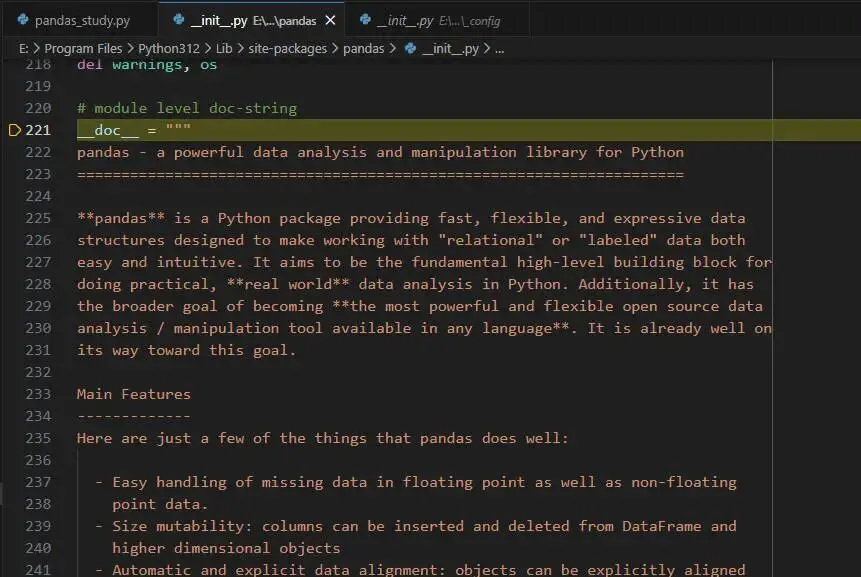
__all__定义 来规范用户使用 from pandas import * 导入的内容。
从学习 Pandas 这种顶级 Python 库我们可以学习模块化设计的一些写法,用来指引自己模块的设计规范。
如果觉着本篇对您有点帮助,可以点一个在看和红心,是对我最大的鼓舞,如果对您有帮助或者篇中内容有纰漏,也请您留言告知。感谢!
到这里,我们 Python入门 系列基本结束了,这里没有夸夸其谈的标题,也没有故意设置悬念而没有实际内容的吸引,只有深入的学习和思考过程,相信通过认真通读本系列的宝宝们,一定有很大的收获,祝大家在Python的海洋里扬帆起航。
往期经典
<Python起源><Python之禅><Python中的变量并不是我们通常理解的变量><Python的基本数据类型><Python的循环结构><Python字符串的前生今世><Python复合数据类型之列表><Python字典从入门到精通>
感谢您的订阅,关注和阅读!为您提供Python的入门和进阶笔记,对Python深入思考剖析,并一步步实践,一起学习进步。

