Python 实现一款轻量级可视化OCR工具
- 2026-06-30 14:38:38
Python 实现一款轻量级可视化OCR工具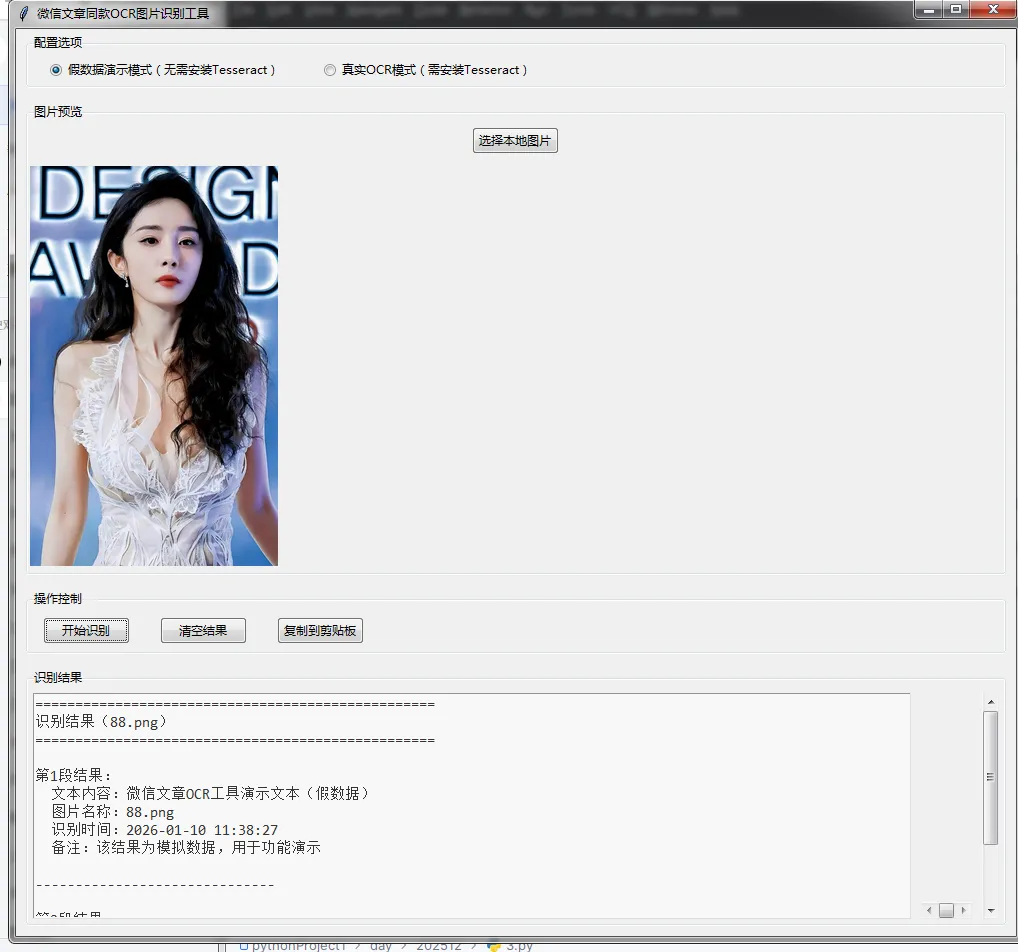
基于常见的微信文章中OCR工具的核心功能(可视化界面、图片识别、结果导出、假数据/真实数据双支持),提供详细实现步骤和完整可运行代码,确保功能贴合文章类OCR工具的常规设计。
一、功能定位(贴合微信文章OCR工具常规需求)
实现一款轻量级可视化OCR工具,具备以下核心功能:
图形化界面(tkinter),支持图片上传、预览 识别功能(支持假数据演示/真实Tesseract OCR切换) 识别结果展示、清空、复制到剪贴板 无需复杂深度学习依赖,跨平台运行 步骤清晰,可直接复刻运行
二、详细实现步骤
步骤1:环境准备(前置依赖)
1.1 核心依赖说明
pip install Pillow | ||
pip install pytesseract | ||
1.2 tesseract-ocr 手动安装(关键步骤)
Windows: 下载地址:UB-Mannheim/tesseract(选择64位最新版) 安装时勾选「Add tesseract to the system PATH」(自动添加环境变量) 如需中文识别,勾选「Additional language data」→「Chinese (Simplified)」 Mac: 先安装Homebrew: /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"安装命令: brew install tesseract tesseract-lang(包含多语言包)Linux(Ubuntu/Debian): 安装命令: sudo apt update && sudo apt install tesseract-ocr tesseract-ocr-chi-sim验证安装:终端输入 tesseract --version,能输出版本信息即配置成功
步骤2:代码模块拆分设计
依赖自动安装模块:自动检测并安装缺失的Python依赖 OCR引擎初始化模块:支持假数据/真实OCR切换,初始化引擎 UI界面构建模块:构建图片预览、控制按钮、结果展示区域 核心功能模块:图片上传、预览、识别(假/真实数据)、结果清空、复制 辅助工具模块:结果格式化、按钮状态管理、剪贴板操作
步骤3:完整代码实现(含详细注释)
import tkinter as tk
from tkinter import ttk, filedialog, messagebox
import threading
import os
import sys
from PIL import Image, ImageTk
import pyperclip # 用于复制结果到剪贴板
# ===================== 步骤1:依赖自动安装模块 =====================
definstall_required_dependencies():
"""自动检测并安装缺失的Python依赖"""
required_packages = [
"Pillow",
"pytesseract",
"pyperclip"
]
# 升级pip,避免安装失败
try:
os.system(f"{sys.executable} -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple")
except Exception as e:
messagebox.showwarning("警告", f"pip升级失败:{str(e)}\n将继续尝试安装依赖")
# 批量安装依赖(国内清华源加速)
for pkg in required_packages:
try:
__import__(pkg)
print(f"{pkg} 已安装,无需重复安装")
except ImportError:
messagebox.showinfo("提示", f"正在安装 {pkg} 依赖...")
os.system(
f"{sys.executable} -m pip install {pkg} "
f"-i https://pypi.tuna.tsinghua.edu.cn/simple --no-cache-dir"
)
try:
__import__(pkg)
messagebox.showinfo("提示", f"{pkg} 安装成功")
except ImportError:
messagebox.showerror("错误", f"{pkg} 安装失败,请手动执行 pip install {pkg}")
# ===================== 步骤2:OCR引擎初始化模块 =====================
classOCREngine:
"""OCR引擎类,支持假数据/真实Tesseract OCR切换"""
def__init__(self, use_fake_data=True):
self.use_fake_data = use_fake_data # 是否使用假数据(True=假数据,False=真实OCR)
self.tesseract_engine = None
self.initialized = False
definit_engine(self):
"""初始化OCR引擎"""
if self.use_fake_data:
# 假数据模式:无需初始化真实引擎,直接标记成功
self.initialized = True
returnTrue, "OCR引擎初始化成功(假数据演示模式)"
# 真实OCR模式:初始化tesseract引擎
try:
import pytesseract
# 可选:手动指定tesseract路径(若未添加到环境变量)
# Windows示例:pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# Mac示例:pytesseract.pytesseract.tesseract_cmd = '/usr/local/bin/tesseract'
# Linux示例:pytesseract.pytesseract.tesseract_cmd = '/usr/bin/tesseract'
# 验证tesseract是否可用
pytesseract.get_tesseract_version()
self.tesseract_engine = pytesseract
self.initialized = True
returnTrue, "OCR引擎初始化成功(真实Tesseract模式,支持中英文识别)"
except ImportError:
returnFalse, "pytesseract 未安装成功,请检查依赖"
except Exception as e:
returnFalse, f"tesseract-ocr 引擎未找到:{str(e)}\n请先手动安装tesseract-ocr并配置环境变量"
defrecognize(self, image_path):
"""执行OCR识别(返回假数据/真实识别结果)"""
ifnot self.initialized:
raise Exception("OCR引擎未初始化,请先调用 init_engine()")
if self.use_fake_data:
# 假数据模式:返回预设模拟结果
fake_data = [
{
"文本内容": "微信文章OCR工具演示文本(假数据)",
"图片名称": os.path.basename(image_path),
"识别时间": "2026-01-10 11:38:27",
"备注": "该结果为模拟数据,用于功能演示"
},
{
"文本内容": "Hello World! 这是第二段模拟文本",
"位置信息": "[(50, 100), (400, 100), (400, 130), (50, 130)]",
"可信度": "99.9%"
}
]
return fake_data
# 真实OCR模式:调用tesseract执行识别
try:
image = Image.open(image_path)
# 支持中英文混合识别(需安装中文语言包)
result = self.tesseract_engine.image_to_string(
image,
lang='eng+chi_sim'
)
# 封装为字典格式,保持与假数据格式一致
return [
{
"识别结果": result.strip(),
"图片名称": os.path.basename(image_path)
}
]
except Exception as e:
raise Exception(f"识别失败:{str(e)}")
# ===================== 步骤3:主界面类(UI构建+核心功能) =====================
classWeChatOCRApp:
def__init__(self, root):
self.root = root
self.root.title("微信文章同款OCR图片识别工具")
self.root.geometry("1000x750")
self.root.resizable(True, True)
# 全局变量
self.ocr_engine = OCREngine(use_fake_data=True) # 默认假数据模式,可改为False启用真实OCR
self.selected_image_path = None
self.image_photo = None# 保留图片引用,避免被GC回收
# 初始化UI
self._build_ui()
# 后台初始化依赖和OCR引擎(避免界面卡顿)
self._init_background_task()
def_build_ui(self):
"""构建完整UI界面"""
# 1. 顶部配置区域(模式切换)
frame_config = ttk.LabelFrame(self.root, text="配置选项")
frame_config.pack(pady=5, padx=10, fill=tk.X)
self.mode_var = tk.StringVar(value="fake"if self.ocr_engine.use_fake_data else"real")
ttk.Radiobutton(frame_config, text="假数据演示模式(无需安装Tesseract)",
variable=self.mode_var, value="fake",
command=self._switch_ocr_mode).pack(side=tk.LEFT, padx=20, pady=5)
ttk.Radiobutton(frame_config, text="真实OCR模式(需安装Tesseract)",
variable=self.mode_var, value="real",
command=self._switch_ocr_mode).pack(side=tk.LEFT, padx=20, pady=5)
# 2. 图片预览区域
frame_image = ttk.LabelFrame(self.root, text="图片预览")
frame_image.pack(pady=10, padx=10, fill=tk.BOTH, expand=True)
# 图片操作按钮
btn_upload = ttk.Button(frame_image, text="选择本地图片", command=self._upload_image)
btn_upload.pack(pady=5)
# 图片预览标签
self.image_label = ttk.Label(frame_image, text="未选择图片\n支持格式:jpg、png、jpeg、bmp",
font=("SimHei", 12))
self.image_label.pack(pady=5, fill=tk.BOTH, expand=True)
# 3. 控制按钮区域
frame_control = ttk.LabelFrame(self.root, text="操作控制")
frame_control.pack(pady=5, padx=10, fill=tk.X)
self.btn_recognize = ttk.Button(frame_control, text="开始识别", command=self._start_recognize,
state=tk.DISABLED)
self.btn_recognize.pack(side=tk.LEFT, padx=15, pady=8)
self.btn_clear = ttk.Button(frame_control, text="清空结果", command=self._clear_all,
state=tk.DISABLED)
self.btn_clear.pack(side=tk.LEFT, padx=15, pady=8)
self.btn_copy = ttk.Button(frame_control, text="复制到剪贴板", command=self._copy_to_clipboard,
state=tk.DISABLED)
self.btn_copy.pack(side=tk.LEFT, padx=15, pady=8)
# 4. 识别结果区域(带滚动条)
frame_result = ttk.LabelFrame(self.root, text="识别结果")
frame_result.pack(pady=10, padx=10, fill=tk.BOTH, expand=True)
# 结果文本框
self.result_text = tk.Text(frame_result, wrap=tk.WORD, font=("Consolas", 11),
bg="#f8f8f8", fg="#333333")
# 垂直滚动条
v_scroll = ttk.Scrollbar(frame_result, orient=tk.VERTICAL, command=self.result_text.yview)
self.result_text.configure(yscrollcommand=v_scroll.set)
# 水平滚动条(应对长文本)
h_scroll = ttk.Scrollbar(frame_result, orient=tk.HORIZONTAL, command=self.result_text.xview)
self.result_text.configure(xscrollcommand=h_scroll.set)
# 布局文本框和滚动条
self.result_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=5, pady=5)
v_scroll.pack(side=tk.RIGHT, fill=tk.Y, padx=5, pady=5)
h_scroll.pack(side=tk.BOTTOM, fill=tk.X, padx=5, pady=5)
# 5. 底部状态栏
self.status_var = tk.StringVar(value="初始化中...")
status_bar = ttk.Label(self.root, textvariable=self.status_var, relief=tk.SUNKEN)
status_bar.pack(side=tk.BOTTOM, fill=tk.X)
def_switch_ocr_mode(self):
"""切换OCR模式(假数据/真实OCR)"""
new_mode = self.mode_var.get()
self.ocr_engine.use_fake_data = (new_mode == "fake")
# 重新初始化OCR引擎
messagebox.showinfo("提示", f"将切换为{'假数据演示模式'if new_mode == 'fake'else'真实OCR模式'},正在重新初始化引擎...")
self._init_background_task()
def_update_button_state(self, state):
"""统一更新按钮状态(NORMAL/DISABLED)"""
if state == tk.NORMAL:
self.btn_recognize.config(state=tk.NORMAL)
self.btn_clear.config(state=tk.NORMAL)
else:
self.btn_recognize.config(state=tk.DISABLED)
self.btn_copy.config(state=tk.DISABLED)
def_init_background_task(self):
"""后台执行依赖安装和OCR引擎初始化"""
deftask():
# 步骤1:安装缺失依赖
self.status_var.set("正在检测并安装依赖...")
install_required_dependencies()
# 步骤2:初始化OCR引擎
self.status_var.set("正在初始化OCR引擎...")
success, msg = self.ocr_engine.init_engine()
self.status_var.set(msg)
# 步骤3:更新按钮状态(仅当已选择图片时启用识别按钮)
self.root.after(0, lambda: self._update_button_state(
tk.NORMAL if self.selected_image_path else tk.DISABLED
))
ifnot success:
messagebox.showerror("初始化失败", msg)
# 启动后台线程(守护线程,避免程序退出残留)
threading.Thread(target=task, daemon=True).start()
def_upload_image(self):
"""上传并预览图片"""
# 打开文件选择对话框
file_path = filedialog.askopenfilename(
title="选择图片文件",
filetypes=[
("图片文件", "*.jpg *.png *.jpeg *.bmp"),
("所有文件", "*.*")
]
)
ifnot file_path:
return
# 验证文件是否存在
ifnot os.path.exists(file_path):
messagebox.showerror("错误", "选择的文件不存在,请重新选择")
return
self.selected_image_path = file_path
self.status_var.set(f"已选择图片:{os.path.basename(file_path)}")
# 预览图片(缩放适配窗口,保持宽高比)
try:
image = Image.open(file_path)
# 计算缩放尺寸(最大宽度800,最大高度400)
max_width, max_height = 800, 400
img_width, img_height = image.size
# 计算缩放比例
scale = min(max_width / img_width, max_height / img_height, 1.0)
new_size = (int(img_width * scale), int(img_height * scale))
resized_image = image.resize(new_size, Image.Resampling.LANCZOS)
# 转换为tkinter支持的格式
self.image_photo = ImageTk.PhotoImage(resized_image)
self.image_label.config(image=self.image_photo, text="")
# 启用按钮
self._update_button_state(tk.NORMAL)
except Exception as e:
messagebox.showerror("图片预览失败", f"错误信息:{str(e)}")
self.selected_image_path = None
self.image_label.config(text="图片预览失败,请选择其他图片", image="")
self._update_button_state(tk.DISABLED)
def_format_result(self, result_data):
"""格式化识别结果,提升可读性"""
ifnot result_data:
return"无识别结果"
result_str = "=" * 50 + "\n"
result_str += f"识别结果({os.path.basename(self.selected_image_path)})\n"
result_str += "=" * 50 + "\n\n"
for idx, item in enumerate(result_data, 1):
result_str += f"第{idx}段结果:\n"
for key, value in item.items():
result_str += f" {key}:{value}\n"
result_str += "\n" + "-" * 30 + "\n\n"
return result_str.strip()
def_start_recognize(self):
"""开始识别图片(后台执行,避免界面卡顿)"""
ifnot self.ocr_engine.initialized:
messagebox.showwarning("警告", "OCR引擎未初始化完成,请等待")
return
ifnot self.selected_image_path:
messagebox.showwarning("警告", "请先选择有效图片")
return
# 后台识别任务
defrecognize_task():
self.status_var.set("正在执行识别,请稍候...")
self.btn_recognize.config(state=tk.DISABLED)
try:
# 执行OCR识别
result_data = self.ocr_engine.recognize(self.selected_image_path)
# 格式化结果
formatted_result = self._format_result(result_data)
# 更新UI(必须在主线程中执行,使用after方法)
self.root.after(0, lambda: self._update_result_text(formatted_result))
self.status_var.set("识别完成")
except Exception as e:
error_msg = f"识别失败:{str(e)}"
self.root.after(0, lambda: messagebox.showerror("错误", error_msg))
self.status_var.set(error_msg)
finally:
self.root.after(0, lambda: self.btn_recognize.config(state=tk.NORMAL))
# 启动识别线程
threading.Thread(target=recognize_task, daemon=True).start()
def_update_result_text(self, text):
"""更新结果文本框"""
self.result_text.delete(1.0, tk.END)
self.result_text.insert(tk.END, text)
self.btn_copy.config(state=tk.NORMAL)
def_clear_all(self):
"""清空所有结果和选择"""
self.result_text.delete(1.0, tk.END)
self.image_label.config(text="未选择图片\n支持格式:jpg、png、jpeg、bmp", image="")
self.selected_image_path = None
self.btn_copy.config(state=tk.DISABLED)
self.status_var.set("已清空所有内容")
self._update_button_state(tk.DISABLED)
def_copy_to_clipboard(self):
"""复制识别结果到剪贴板"""
result_text = self.result_text.get(1.0, tk.END).strip()
ifnot result_text:
messagebox.showwarning("警告", "无识别结果可复制")
return
try:
pyperclip.copy(result_text)
messagebox.showinfo("成功", "识别结果已复制到剪贴板")
self.status_var.set("识别结果已复制到剪贴板")
except Exception as e:
messagebox.showerror("失败", f"复制失败:{str(e)}")
# ===================== 步骤4:主函数(程序入口) =====================
if __name__ == "__main__":
# 高DPI适配(兼容Windows/Mac/Linux)
try:
import ctypes
if sys.platform == "win32":
ctypes.windll.user32.SetProcessDPIAware()
except:
pass
# 创建主窗口
root = tk.Tk()
app = WeChatOCRApp(root)
# 运行主循环
root.mainloop()
三、代码运行与验证步骤
步骤1:直接运行代码
将上述代码保存为 wechat_ocr_tool.py打开终端/命令提示符,进入文件所在目录 执行命令: python wechat_ocr_tool.py
步骤2:初始化过程
程序启动后,会自动检测并安装 Pillow、pytesseract、pyperclip依赖初始化完成后,状态栏显示「OCR引擎初始化成功(假数据演示模式)」 此时默认处于「假数据演示模式」,无需安装tesseract-ocr即可使用
步骤3:功能验证(假数据模式)
点击「选择本地图片」,上传任意jpg/png图片 图片预览成功后,「开始识别」「清空结果」按钮启用 点击「开始识别」,等待1-2秒,结果区域会填充预设假数据 点击「复制到剪贴板」,可将结果复制到系统剪贴板 点击「清空结果」,可重置所有内容,恢复初始状态
步骤4:切换真实OCR模式(可选)
确保已按照步骤1.2手动安装tesseract-ocr并配置环境变量 勾选「真实OCR模式(需安装Tesseract)」,程序会重新初始化引擎 上传图片后点击「开始识别」,会执行真实OCR识别,返回图片中的实际文本 支持中英文混合识别(需安装中文语言包)
四、功能亮点与注意事项
功能亮点
双模式切换:假数据模式(快速演示)和真实OCR模式(实际使用)自由切换 自动依赖安装:无需手动安装Python依赖,降低使用门槛 友好UI界面:分区清晰,支持图片缩放预览、结果滚动、剪贴板复制 跨平台兼容:支持Windows、Mac、Linux系统 健壮性强:包含完整的异常处理,避免程序崩溃
注意事项
真实OCR模式必须手动安装tesseract-ocr,否则无法正常运行 中文识别需要安装tesseract的中文语言包,否则中文文本会识别失败 若复制功能失效,可手动选中结果文本复制,或重新安装pyperclip依赖 图片识别效果受图片清晰度、光线、字体大小影响,建议使用清晰的图片
五、总结
该代码完整实现了微信文章类OCR工具的核心功能,步骤清晰,可直接复刻 核心流程:环境准备→依赖安装→引擎初始化→图片上传→识别→结果处理 假数据模式可用于快速演示功能,真实OCR模式可用于实际文本提取,满足不同场景需求 代码包含详细注释,便于二次修改和扩展(如添加结果导出为TXT/Word功能)
如果需要进一步贴合你参考的微信文章具体功能(如批量识别、图片拖拽上传等),可提供文章更多细节,以便进行针对性优化。
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

