别再只会写Prompt了!揭秘让AI Agent"自我进化"的终极架构,这才是未来的玩法大家好,我是方进。
最近圈子里有个现象很有意思:大家都在聊Agent(智能体),但绝大多数人还停留在"写个超级复杂的Prompt(提示词)"这个阶段。
懂行的朋友都知道,Prompt虽然好用,但它有个致命的天花板——它是静态的。你写得再花哨,它也只是一张"说明书",AI并不会因为读了这张说明书就变得更聪明,它只是在机械地执行。
真正的Agent,是需要"自我进化"的。
前两天我深扒了一篇关于构建自进化AI Agent训练架构(链接见文末)的硬核文章,看得我直拍大腿。这篇文章直接掀了"提示词工程"的桌子,告诉我们:想要Agent真正像人一样思考和协作,你得给它一套完整的训练架构,而不是几句咒语。
今天,我就把这套复杂的架构拆解开,用咱们都能听懂的大白话,聊聊这个让AI从"提线木偶"变成"独立特工"的秘密武器。
为什么Prompt不够用了?
想象一下,你雇了一个员工。
- • Prompt模式:你每天早上给他一张纸条,写着"先做A,再做B,如果遇到C就做D"。他做完了,明天你还得写。他不会因为今天做错了而被扣工资,也不会因为做好了而得到奖励,更不会总结经验。
- • Agent训练模式:你把他扔进职场(环境),告诉他目标(KPI),让他自己去试。做对了给奖金(Reward),做错了挨顿骂(Penalty)。一个月后,他成了职场老油条。
这就是区别。传统Agent依赖静态提示词,而真正的自进化Agent依赖动态训练系统。
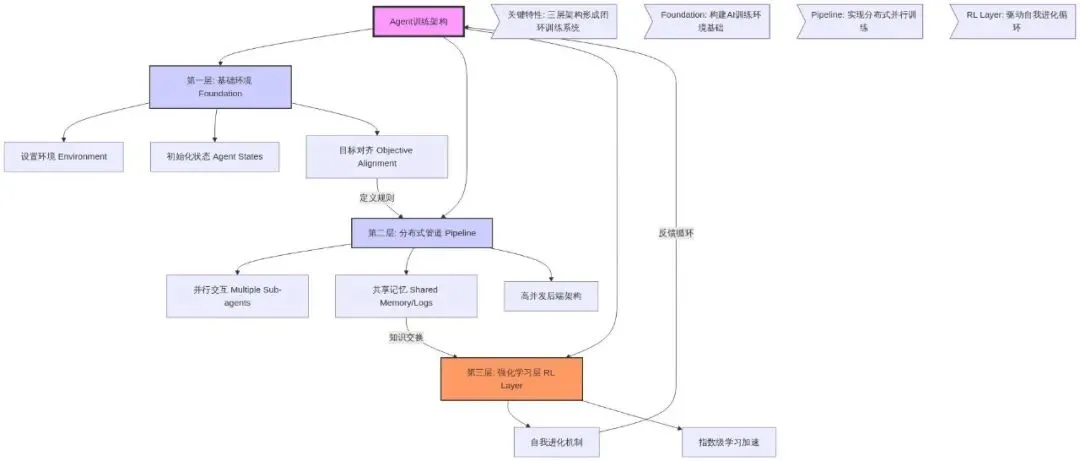
原文提出的核心观点是:一个能够自我进化的Agent,需要三个层次的能力支撑——感知环境、高效处理、持续学习。这不是叠加三个模块那么简单,而是要让它们形成一个闭环的进化飞轮。
第一层:环境层(Environment Layer)—— Agent的"感知神经"
这是整个架构的地基,也是最容易被忽略的一层。
原文强调了一个关键概念:环境不仅是数据的来源,更是Agent学习的"训练场"。
这一层需要定义三个核心要素:
- • 状态空间(State Space):Agent能"看到"什么?比如一个客服Agent,它的状态空间包括用户的问题、历史对话、用户情绪标签等。状态空间定义得越精准,Agent的感知能力就越强。
- • 动作空间(Action Space):Agent能"做"什么?是直接回复、转接人工、还是查询知识库?动作空间决定了Agent的行为边界。
- • 奖励函数(Reward Function):这才是精髓!它定义了什么是"好",什么是"坏"。一个设计拙劣的奖励函数,会让Agent学会"投机取巧"——比如你奖励它"快速回复",它可能学会敷衍了事;你奖励它"用户满意度",它才会真正去解决问题。
原文中有个重要洞见:大多数Agent项目失败,不是因为模型不够好,而是因为环境设计不够好。 你给Agent一个模糊的状态空间、一个有漏洞的奖励函数,它学到的只会是"钻空子"的能力。
第二层:管道层(Pipeline Layer)—— Agent的"高速公路"
当Agent需要处理海量数据、同时执行多个任务时,单线程的处理方式就会成为瓶颈。
原文提出了分布式训练管道的概念,核心思想是:把Agent的学习过程拆解成多个并行的"流水线",让不同的学习任务同时进行。
这里有几个关键技术点:
- • 经验回放(Experience Replay):Agent不只是学习当前的经验,还会把过去的经验存起来反复"回味"。这就像一个棋手,赛后会反复复盘自己的对局,从中发现新的策略。
- • 分布式采样:多个Agent副本同时在不同的环境中探索,然后把学到的经验汇总到一起。这大加速了学习效率。
- • 异步更新:Agent不需要等所有数据收集完才更新策略,而是边收集边学习,形成持续优化的循环。
为什么这一层重要? 因为在真实场景中,Agent面对的是复杂、多变、高频的任务流。没有高效的管道支撑,再强的模型也会被"堵在路上"。
第三层:RL层(Reinforcement Learning Layer)—— 进化的核心引擎
这是整个架构的"灵魂",也是让Agent真正实现自我进化的关键。
原文深入讨论了两种训练范式的本质区别:
1. SFT(监督微调)的局限性
SFT的逻辑是"老师教什么,学生学什么"。它适合让Agent快速掌握基础能力,但有一个致命问题:SFT只能教会Agent"模仿",不能教会它"思考"。
举个例子:你用100万条优秀客服对话训练一个Agent,它确实能学会标准话术。但当遇到训练数据里没有的新问题时,它就抓瞎了——因为它从来没学过"如何应对未知情况"。
2. PPO(近端策略优化)的进化魔法
PPO是一种强化学习算法,它的核心思想是:让Agent在"探索新策略"和"保持稳定"之间找到平衡。
原文用一个公式解释了这一点(别怕,我翻译成人话):
Agent每次更新策略时,不能步子迈得太大。因为走得太远可能"翻车"(策略崩溃),走得太小又学不到新东西。PPO通过一个"信任区域"机制,确保每次更新都在安全范围内。这意味着什么? PPO让Agent拥有了"在失败中学习"的能力。它不再需要每一步都做对,而是通过大量试错找到最优路径。
3. 奖励模型(Reward Model)的隐藏力量
这是原文中最精彩的部分之一。
在RLHF(基于人类反馈的强化学习)中,奖励不是人工定义的规则,而是由另一个模型来预测的。这个奖励模型本身也需要训练,它的任务是学会"像人类一样判断什么是好的输出"。
原文指出:奖励模型的质量,直接决定了Agent进化的天花板。 如果奖励模型本身有偏见或错误,Agent学到的策略也会"跑偏"。
这就是为什么OpenAI、Anthropic等公司在RLHF上投入巨资——它们在训练的不仅是Agent,还有Agent的"教练"。
三层架构如何形成"进化飞轮"?
把三层放在一起看,你会发现它们形成了一个精妙的闭环:
这就是"自进化"的真正含义:Agent不再依赖人类不断投喂新的提示词,而是通过与环境的交互自主提升能力。
 图片来源:01Editor流程图
图片来源:01Editor流程图一个现实案例:代码Agent的进化之路
为了让这套架构更直观,我来描述一个代码生成Agent的进化过程:
阶段一:SFT打基础 用大量优质代码样本训练Agent,让它学会基本语法、常见模式、代码规范。这时的Agent就像一个刚入职的初级程序员,会写代码,但写得不一定好。
阶段二:环境中试错 把Agent放进一个代码执行环境。它写的代码如果能通过测试用例,就得到正向奖励;如果报错或性能太差,就得到负向奖励。
阶段三:PPO优化 Agent开始发现一些"规律":原来用这种数据结构更快,原来这种写法更不容易出错。它的策略在不断优化。
阶段四:奖励模型升级 引入更复杂的奖励维度:代码不仅要能跑,还要可读性好、可维护性强。奖励模型学会了区分"能用的代码"和"优雅的代码"。
阶段五:持续进化 Agent在真实项目中不断接受新的挑战,每一次成功和失败都成为它的养分。半年后,它的代码质量已经超过了当初训练它的数据。
这就是自进化的力量。
总结与思考:从"提示词工匠"到"架构设计师"
看完这套架构,你应该能感受到:真正的Agent开发,远不止写几句Prompt那么简单。
原文的核心洞见可以归纳为三点:
- • 环境设计比模型选择更重要:一个精心设计的训练环境和奖励函数,比换一个更大的模型更能提升Agent能力。
- • 进化需要闭环:感知、行动、反馈、优化必须形成完整的循环,任何一个环节断裂,进化就会停止。
- • 奖励模型是隐藏的关键:它决定了Agent优化的方向。训练Agent的同时,也要训练一个优秀的"教练"。
对于我们普通开发者或AI爱好者来说,这意味着什么?
意味着思维方式需要升级。不要只盯着Prompt技巧,而要思考:
- • 它的"奖励"是什么?这个奖励会不会让它学到歪门邪道?
别让你的Agent只做一个听话的执行者,要让它成为一个会思考的进化者。
这才是Agent开发的终极形态。
我是方进,我们在AI进化的路上,下期见。
参考:
《构建自进化AI Agent训练架构》
https://medium.com/@fareedkhandev/c87a4e316b22?sk=efa423ebd17300e14d6731d169b4c24c


