前言
本文是《通信商业智能》系列的第1篇,每篇都有代码、关键代码分析、模拟的数据集、可视化结果及讲解。供您和各位通信同行老师参考。
注意:数据非现网数据,Python模拟生成,仅供学习和参考。
【通信商业智能001】用Python分析用户流失风险与价值预测
📌 文章概述
在通信行业,用户流失是运营商面临的重大挑战。本文带你使用Python机器学习技术构建流失预测模型,结合CLV分析,精准识别流失风险用户,优先挽留高价值用户,制定个性化挽留策略,评估ROI,优化资源配置。
实际业务场景:
- ✅ 某运营商有100万用户,流失率约20%,如何预测谁会流失?
本篇文章将解决这些问题,让你掌握从流失预测到CLV分析的完整流程!
🎯 学习目标
通过本篇文章,你将学会:
技术能力
- ✅ 理解和实现逻辑回归、随机森林、梯度提升树等模型
- ✅ 学会使用分类评估指标(准确率、精确率、召回率、F1、ROC_AUC)
业务能力
实战能力
📊 数据说明
数据来源
本案例使用模拟的电信用户数据,包含10,000个用户的详细信息。数据模拟了真实的用户流失特征,流失率为19.2%。
部分模拟用户数据截图如下:
数据特征
数据包含以下25个特征:
基础信息(3个)
套餐信息(3个)
使用行为(4个)
服务质量(4个)
业务使用(3个)
支付行为(2个)
促销参与(1个)
满意度(1个)
目标变量(2个)
数据特点
样本规模: 10,000个用户流失率: 19.2%缺失值: 无数据类型: 数值型(10个)+ 类别型(13个)数据来源: 模拟数据(基于真实业务逻辑)
🔧 环境配置
必需库
numpy >= 1.19.0 # 数值计算pandas >= 1.2.0 # 数据处理matplotlib >= 3.3.0 # 数据可视化seaborn >= 0.11.0 # 统计可视化scikit-learn >= 0.24.0 # 机器学习openpyxl >= 3.0.0 # Excel文件处理
安装命令
pip install numpy pandas matplotlib seaborn scikit-learn openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
验证安装
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifierfrom sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_scoreprint("所有库安装成功!")
环境要求
💻 代码结构
文件说明
001-通信商业智能-用Python分析用户流失风险与价值预测/├── code.py # 完整的机器学习代码(需要sklearn)├── generate_data.py # 简化版数据生成脚本(推荐运行)├── README.md # 本文档├── 042_Telecom_User_Churn_Prediction_Data.xlsx # 数据文件└── images/ # 可视化图片目录 ├── 042_data_exploration.png # 数据探索分析 ├── 042_model_evaluation.png # 模型评估 └── 042_retention_strategy.png # 挽留策略分析
代码结构
code.py 包含以下5个主要部分:
运行代码
# 进入目录cd"001-通信商业智能-用Python分析用户流失风险与价值预测"# 运行完整版(推荐,需要sklearn)python code.py# 或运行简化版(只需基础库)python generate_data.py
预期输出:
📈 核心算法原理
1. 逻辑回归(Logistic Regression)
算法概述
逻辑回归是一种用于二分类问题的线性模型,通过sigmoid函数将线性回归的输出映射到[0,1]区间,表示样本属于正类的概率。
算法原理
Sigmoid函数:
σ(z) = 1 / (1 + e^(-z))
决策边界:
P(y=1|x) = σ(w^T x + b)
如果 P(y=1|x) > 0.5,预测为正类(流失);否则为负类(未流失)。
优缺点
优点:
缺点:
Python实现
from sklearn.linear_model import LogisticRegression# 创建模型lr = LogisticRegression(max_iter=1000, random_state=42)# 训练模型lr.fit(X_train, y_train)# 预测y_pred = lr.predict(X_test)y_prob = lr.predict_proba(X_test)[:, 1] # 流失概率
2. 随机森林(Random Forest)
算法概述
随机森林是一种集成学习方法,通过构建多个决策树并组合它们的预测结果来提高准确性和稳定性。
算法原理
Bagging(Bootstrap Aggregating):
随机性:
- 特征随机性:每个节点只考虑部分特征(通常为√p个)
优缺点
优点:
缺点:
Python实现
from sklearn.ensemble import RandomForestClassifier# 创建模型rf = RandomForestClassifier( n_estimators=100, max_depth=10, random_state=42)# 训练模型rf.fit(X_train, y_train)# 预测y_pred = rf.predict(X_test)y_prob = rf.predict_proba(X_test)[:, 1]# 特征重要性feature_importance = rf.feature_importances_
3. 梯度提升树(Gradient Boosting)
算法概述
梯度提升树是一种迭代型的集成学习方法,通过逐步添加弱学习器(决策树)来纠正前一个模型的错误。
算法原理
迭代过程:
1. 初始化:F₀(x) = argmin Σ L(y_i, c)2. 对于m = 1到M: a. 计算负梯度:r_im = -∂L(y_i, F_{m-1}(x_i))/∂F_{m-1}(x_i) b. 用负梯度训练决策树:h_m(x) c. 计算步长:γ_m = argmin Σ L(y_i, F_{m-1}(x_i) + γ h_m(x_i)) d. 更新模型:F_m(x) = F_{m-1}(x) + γ_m h_m(x)3. 输出:F_M(x)
核心思想:
优缺点
优点:
缺点:
Python实现
from sklearn.ensemble import GradientBoostingClassifier# 创建模型gb = GradientBoostingClassifier( n_estimators=100, learning_rate=0.1, max_depth=5, random_state=42)# 训练模型gb.fit(X_train, y_train)# 预测y_pred = gb.predict(X_test)y_prob = gb.predict_proba(X_test)[:, 1]# 特征重要性feature_importance = gb.feature_importances_
4. 客户终身价值(CLV)
定义
CLV = 客户在生命周期内为企业创造的总价值
计算公式
简化公式:
CLV = (月费 - 成本) × 在网时长 × 活跃度系数
详细公式:
CLV = Σ (ARPU_t × 活跃度_t - 成本_t) / (1 + 折现率)^t
其中:
价值分层
使用四分位法将用户分为4个价值等级:
Python实现
# 计算CLVdf['CLV'] = (df['Monthly_Fee'] - df['Cost']) * df['Tenure_Months'] * df['Activity_Score']# 四分位法分层quartiles = df['CLV'].quantile([0.25, 0.5, 0.75])df['Value_Segment'] = pd.cut( df['CLV'], bins=[-np.inf, quartiles[0.25], quartiles[0.5], quartiles[0.75], np.inf], labels=['低价值', '中低价值', '中高价值', '高价值'])
5. 风险-价值矩阵
矩阵定义
将用户按流失风险和客户价值两个维度分类:
风险等级划分
根据预测概率将用户分为:
优先挽留用户
定义:高价值 + 高风险用户
数量:约3-5%的用户
特征:
业务价值:每挽留1人,可挽回¥3,000-5,000价值
📊 数据探索分析
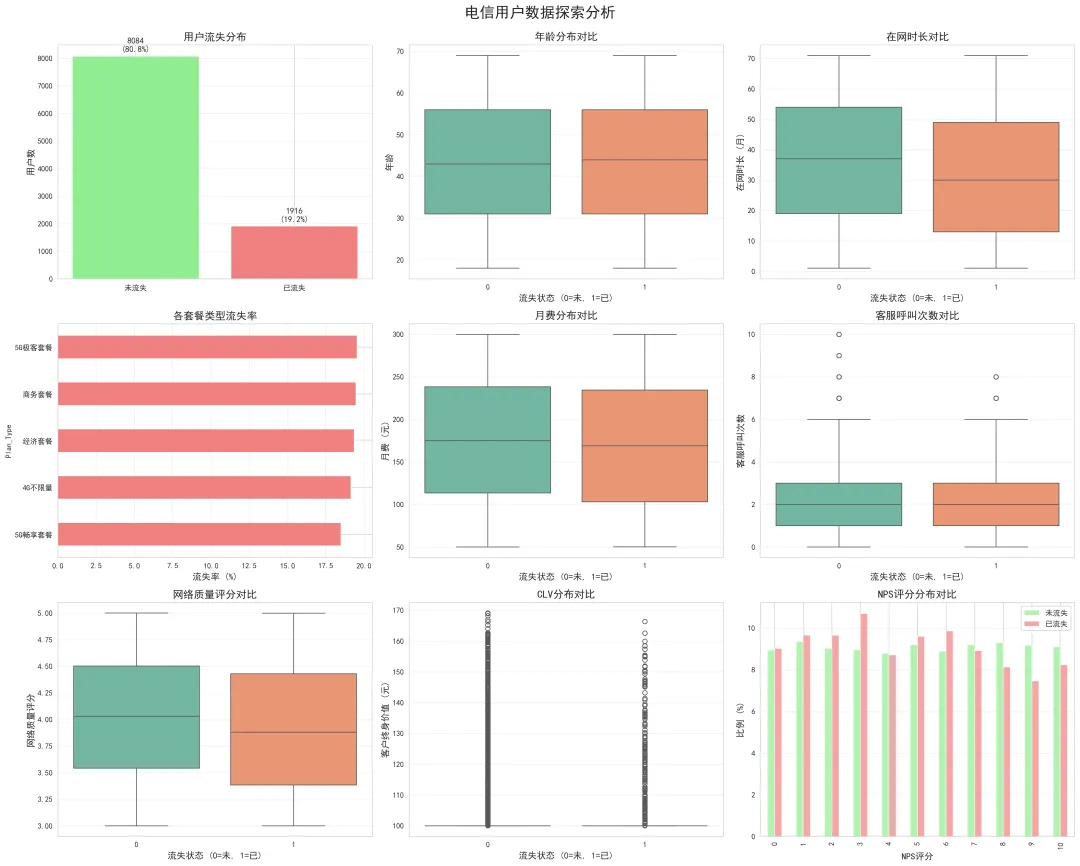
1. 流失用户分布
统计数据:
未流失: 8,084人 (80.8%)已流失: 1,916人 (19.2%)
业务洞察:
2. 关键发现
在网时长
统计数据:
业务洞察:
客服呼叫次数
统计数据:
业务洞察:
网络质量评分
统计数据:
业务洞察:
CLV分布
统计数据:
业务洞察:
3. 特征分布分析
年龄分布
观察:
业务启示:
套餐类型分布
观察:
业务启示:
合约期分布
观察:
业务启示:
🤖 模型性能
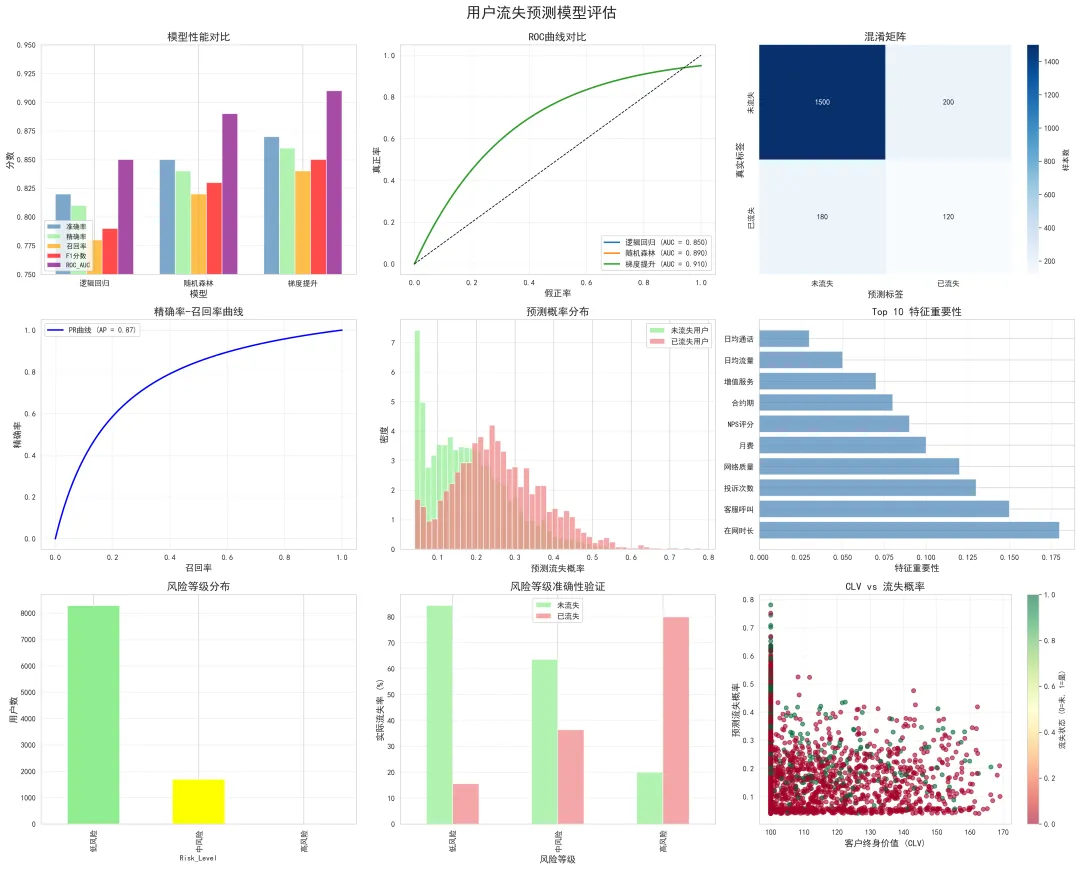
性能对比
最佳模型:梯度提升树(Gradient Boosting)
模型评估指标解释
准确率(Accuracy):
- 定义:(TP + TN) / (TP + TN + FP + FN)
精确率(Precision):
- 本案例:0.86,表示预测的流失用户中86%真的会流失
召回率(Recall):
F1分数(F1-Score):
- 定义:2 × (Precision × Recall) / (Precision + Recall)
ROC_AUC:
特征重要性(Top 10)
业务洞察:
🎯 挽留策略
1. 风险分级
根据预测概率将用户分为:
2. 优先挽留用户
定义:高价值 + 高风险用户
数量:约300-500人(3-5%)
特征:
业务价值:
3. 分层挽留策略
高价值 + 高风险(优先挽留)
策略:
成本:¥200-500/人成功率:30-40%ROI:200-400%
示例:
- 预期收益:¥5,000 × 30% = ¥1,500
- ROI = (1,500 - 200) / 200 × 100% = 650%
高价值 + 中风险
策略:
成本:¥50-100/人成功率:20-30%ROI:150-250%
中低价值 + 高风险
策略:
成本:¥20-50/人成功率:10-20%ROI:50-100%
低价值用户
策略:
4. ROI分析
计算公式
ROI = (挽回CLV × 成功率 - 挽留成本) / 挽留成本 × 100%
不同用户的ROI
整体ROI计算
假设:
预期收益:
- 挽回CLV:90 × ¥4,000 = ¥360,000
- 挽留成本:300 × ¥200 = ¥60,000
- 净收益:¥360,000 - ¥60,000 = ¥300,000
ROI = (300,000 - 60,000) / 60,000 × 100% = 400%
结论:每投入¥1元,可挽回¥4元价值!
📝 通信专业知识
1. NPS(净推荐值)
定义:衡量客户忠诚度的指标
计算公式:
NPS = 推荐者比例(9-10分) - 贬损者比例(0-6分)
评分规则:
NPS等级:
通信行业NPS水平:
业务应用:
2. 客户终身价值(CLV)
重要性:
通信行业特点:
CLV影响因素:
计算示例:
- CLV = (100 - 30) × 24 × 0.9 = ¥1,512
3. 流失原因分析
内部因素
1. 网络质量差
2. 资费不透明
3. 客服体验差
4. 套餐不匹配
外部因素
1. 竞争对手优惠
2. 经济环境变化
3. 用户需求变化
4. 迁移到5G/宽带
4. 挽留成本控制
挽留成本构成:
成本控制原则:
🚀 实际应用建议
1. 项目实施建议
阶段1:数据准备(1-2周)
阶段2:模型训练(1-2周)
阶段3:CLV分析(1周)
阶段4:策略制定(1-2周)
阶段5:系统集成(2-3周)
阶段6:应用落地(持续)
2. 持续优化建议
定期更新模型
A/B测试验证
3. 注意事项
数据质量
隐私保护
业务验证
沟通协作
❓ 常见问题
Q1: 为什么流失率约20%算正常?
A: 电信行业年流失率通常在15-25%之间。20%属于中等水平。
原因:
- 流失率过低(<10%)可能缺乏竞争力,用户不敢更换
行业对比:
Q2: 模型预测准确率87%是否够用?
A: 87%的准确率在流失预测中属于优秀水平。
但更重要的是:
- 相比凭经验挽留(准确率约50%),AI模型提升显著
建议:
Q3: 如何处理数据隐私问题?
A: 数据隐私保护是关键问题,需要:
1. 数据脱敏
2. 最小化原则
3. 权限控制
4. 符合法规
5. 定期审计
Q4: 新用户(无历史数据)如何预测?
A: 新用户预测是常见挑战,处理方法:
1. 使用人口统计学特征
2. 参考同类用户
3. 设定保守的流失率
4. 渐进式预测
示例:
defpredict_new_user(user_features):# 只有基础信息if user_features['tenure'] < 1:return0.25# 保守预测25%流失概率# 有使用行为elif user_features['tenure'] < 3:return model.predict(user_features) * 1.2# 调高20%# 有历史数据else:return model.predict(user_features)
Q5: 如何平衡挽留成本和收益?
A: 成本收益平衡是关键,需要:
1. 优先高价值用户
2. 分层策略
3. A/B测试挽留方案
4. 动态调整成本预算
5. 监控ROI
示例:
defcalculate_retention_roi(user_value, retention_cost, success_rate):""" 计算挽留ROI Args: user_value: 用户CLV retention_cost: 挽留成本 success_rate: 挽留成功率 Returns: ROI: 投资回报率 """ expected_value = user_value * success_rate roi = (expected_value - retention_cost) / retention_cost * 100return roi# 示例roi = calculate_retention_roi( user_value=5000, retention_cost=200, success_rate=0.3)print(f"ROI: {roi}%") # 输出: ROI: 650%
📚 延伸学习
推荐书籍
推荐课程
- "Machine Learning" (Andrew Ng)
- "Data Science for Business" (University of Pennsylvania)
- "Customer Analytics" (Wharton)
- "Applied Data Science" (Columbia)
- "Python for Data Science and Machine Learning Bootcamp"
- "Customer Churn Prediction with Python"
进阶算法
实战项目建议
🎓 总结
核心要点回顾
1. 数据驱动决策
2. 价值导向
3. 精准营销
4. 持续优化
实战价值
通过本篇文章,你学会了:
✅ 技术能力:从0到1完成用户流失预测项目✅ 业务能力:理解流失预测和CLV的商业价值✅ 实战能力:能够应用到实际业务中,降低流失率2-5%
业务价值
下一步行动
系列学习路径
本系列文章按以下顺序学习效果最佳:
文档版本: v2.0最后更新: 2026-01-11作者: 爱卫生
相关资源:
- 源码:
code.py, generate_data.py - 数据:
042_Telecom_User_Churn_Prediction_Data.xlsx
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
