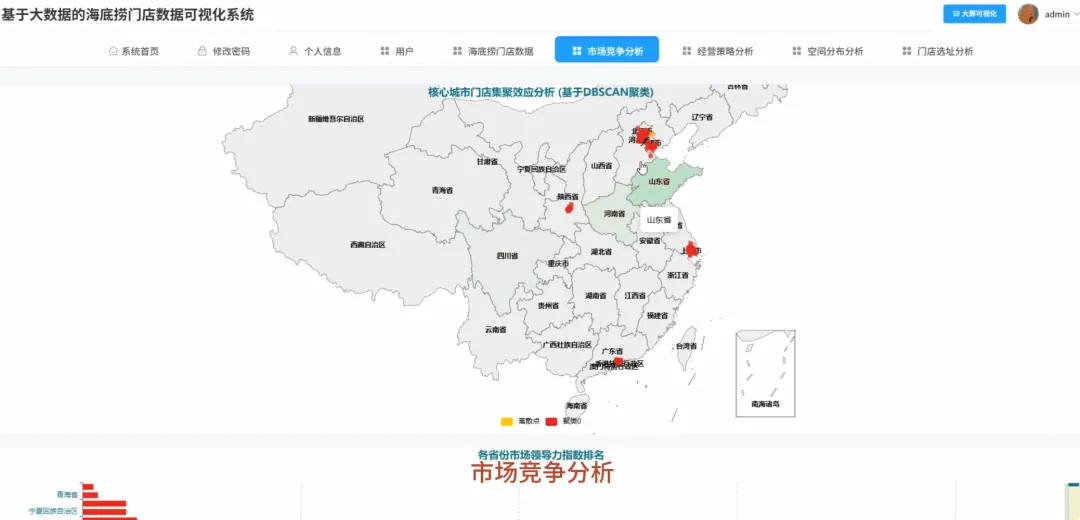
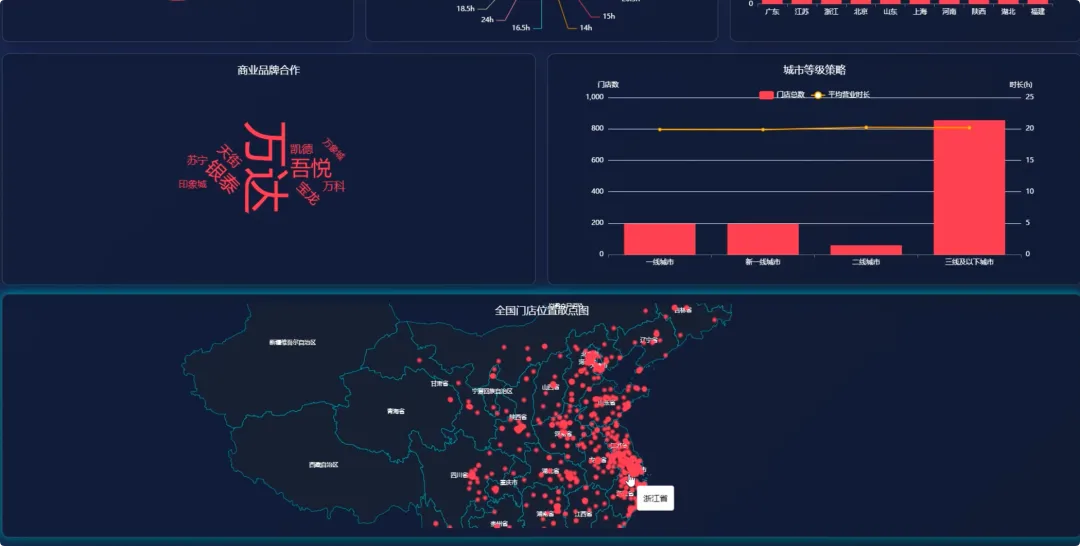
# 核心功能代码汇总from pyspark.sql import SparkSessionfrom pyspark.sql.functions import col, count, when, litfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.clustering import DBSCANfrom pyspark.sql.types import StringType# 初始化SparkSessionspark = SparkSession.builder.appName("HaiDiLaoAnalysis").getOrCreate()# 假设df_spark是从HDFS或本地加载的门店数据DataFrame# df_spark = spark.read.csv("hdfs://path/to/haidilao_stores.csv", header=True, inferSchema=True)# 功能1: 全国各省份门店数量分布统计def analyze_store_distribution_by_province(df): # 按省份分组,计算每个省份的门店数量 province_counts = df.groupBy("province").agg(count("store_name").alias("store_count")) # 按门店数量降序排序 sorted_province_counts = province_counts.orderBy(col("store_count").desc()) # 转换为Python列表以供Django视图使用 result = sorted_province_counts.collect() # 模拟Django视图返回数据 return [{"province": row['province'], "count": row['store_count']} for row in result]# 功能2: 核心城市内门店集聚效应分析 (DBSCAN聚类算法)def analyze_clustering_with_dbscan(df, city_name): # 筛选指定城市的数据 city_df = df.filter(col("city") == city_name).select(col("latitude"), col("longitude")) # 将经纬度特征合并为一个向量 assembler = VectorAssembler(inputCols=["latitude", "longitude"], outputCol="features") city_df_with_features = assembler.transform(city_df) # 创建并配置DBSCAN模型 dbscan = DBSCAN(eps=0.01, minPts=2, featuresCol="features", predictionCol="cluster") # 训练模型并进行聚类 model = dbscan.fit(city_df_with_features) clustered_df = model.transform(city_df_with_features) # 提取坐标和聚类标签 result = clustered_df.select("latitude", "longitude", "cluster").collect() # 模拟Django视图返回数据 return [{"lat": row['latitude'], "lng": row['longitude'], "cluster": row['cluster']} for row in result]# 功能3: 门店命名与商业地产品牌关联度def analyze_mall_association(df): # 定义要查找的商业地产品牌关键词 keywords = ["万达", "万象城", "吾悦", "银泰", "大悦城", "龙湖"] # 使用when-otherwise链来标记门店关联的品牌 df_with_brand = df.withColumn("associated_brand", when(col("store_name").contains(keywords[0]), lit(keywords[0])) .when(col("store_name").contains(keywords[1]), lit(keywords[1])) .when(col("store_name").contains(keywords[2]), lit(keywords[2])) .when(col("store_name").contains(keywords[3]), lit(keywords[3])) .when(col("store_name").contains(keywords[4]), lit(keywords[4])) .when(col("store_name").contains(keywords[5]), lit(keywords[5])) .otherwise(lit("其他或无")) ) # 按关联品牌分组并计数 brand_counts = df_with_brand.groupBy("associated_brand").agg(count("store_name").alias("store_count")) # 只筛选出有关联品牌的记录 associated_brands_df = brand_counts.filter(col("associated_brand") != "其他或无") result = associated_brands_df.orderBy(col("store_count").desc()).collect() # 模拟Django视图返回数据 return [{"brand": row['associated_brand'], "count": row['store_count']} for row in result]






















 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
