❝凌晨一点,线上报警:agent 在相同输入下结果飘了。
我本能地打开仓库,跟读 handler、看 retry、查异常链路。
20 分钟后意识到一个事实:代码没问题,但行为在漂。
真正的答案不在 commit 里,而在那次运行的 trace 里。
- AI agent:代码只是脚手架,决策发生在模型运行时
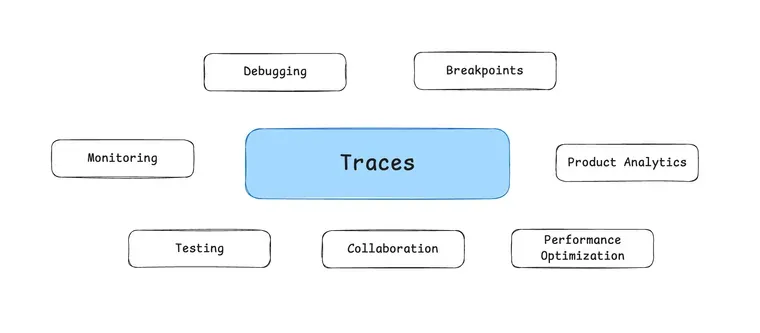
- 调试/测试/优化/监控/协作,都需要围绕 trace 进行
- 没有 observability 的 agent 等于黑盒飞行
为什么代码不再记录 agent 行为?
传统软件里,一个请求怎么走基本可推理:
输入 → 校验 → 路由 → 业务逻辑 → 输出。
相同输入 + 相同代码 = 相同路径。
但 AI agent 的代码通常长这样:
agent = Agent(
model="gpt-4",
tools=[search_tool, analysis_tool, visualization_tool],
system_prompt="You are a helpful data analyst..."
)
result = agent.run(user_query)
这段代码只定义了“能用什么”,但没有定义“怎么用”。
真正的决策逻辑在模型里运行时才产生:
这些都不在代码里,而在当次执行的推理链里。
结论:源码不再是行为的唯一来源。
Trace 是 AI Agent 的“运行说明书”
Trace 就是一次执行的全量轨迹,包括:
这意味着:
你过去围绕代码做的工作,现在要围绕 trace 来做。
关键变化:工程实践从“读代码”迁移到“读 trace”
1) Debugging → Trace Analysis
传统 debug:打开代码找 bug。
AI debug:打开 trace 找推理偏移。
典型问题不是“代码错了”,而是:
这些只有 trace 能证据化。
2) 断点不在代码里,而在推理状态里
你不能给模型推理下断点,但可以“还原状态”。
做法是:
这就是“推理级调试”。
3) 测试从“单次回归”变成“持续 eval”
传统软件测试:
AI agent 测试:
因为模型是非确定性的,你需要在线持续评估。
4) 性能优化从“代码热点”转向“决策热点”
传统软件优化:
AI agent 优化:
这些全部存在于 trace。
5) 监控从“系统健康”迁移到“决策质量”
Agent 可以 0 报错运行,但答案依旧烂。
你要监控质量,不只是 uptime。
核心指标:
这些都只能通过 trace 得到。
结论:源码退位,trace 上位
你仍然需要代码,但它只是脚手架。
真正决定产品行为的,是模型在运行时生成的决策链。
trace 才是这条链的“证据”。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
