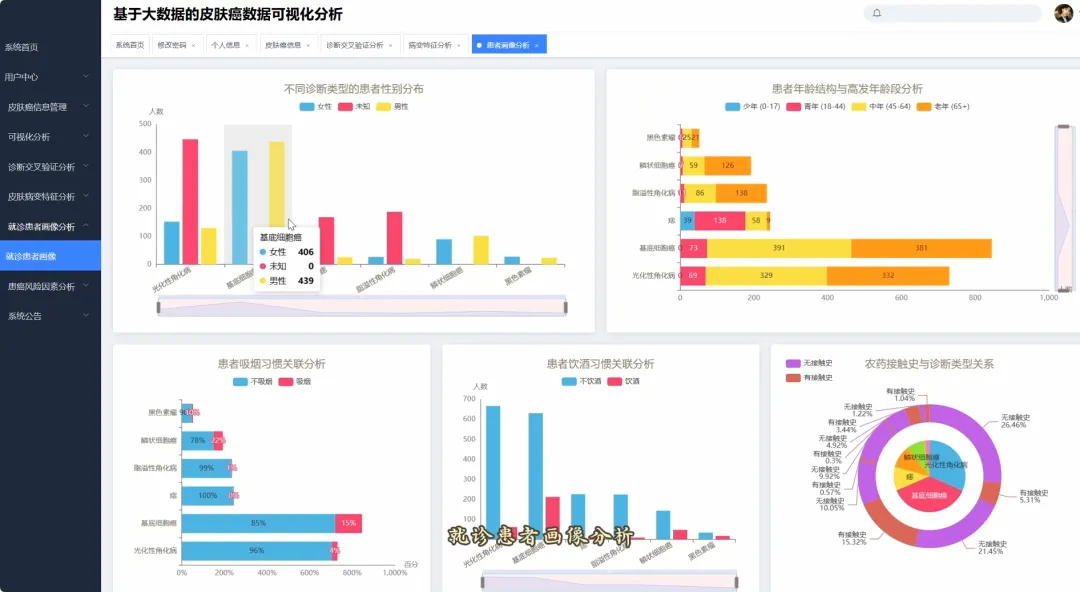
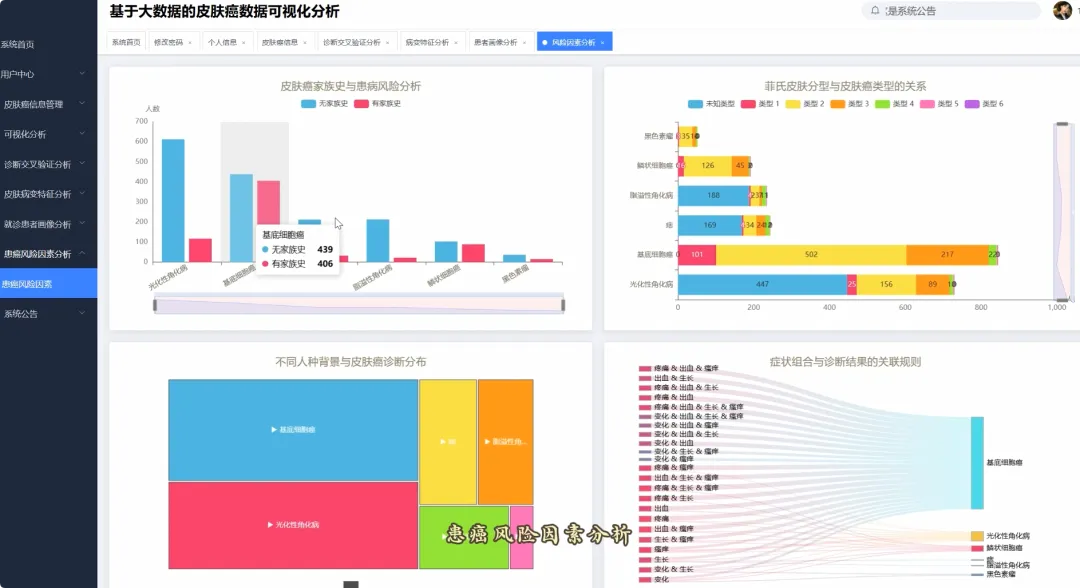
from pyspark.sql import SparkSession, functions as Fspark = SparkSession.builder.appName("SkinCancerAnalysis").getOrCreate()def analyze_age_distribution(df): age_bins = [0, 20, 40, 60, 80, 100] age_labels = ["<20", "20-39", "40-59", "60-79", "80+"] df_with_age_group = df.withColumn("age_group", F.when(df.age < 20, age_labels[0]).when((df.age >= 20) & (df.age < 40), age_labels[1]).when((df.age >= 40) & (df.age < 60), age_labels[2]).when((df.age >= 60) & (df.age < 80), age_labels[3]).otherwise(age_labels[4])) result_df = df_with_age_group.groupBy("age_group", "diagnostic").count().orderBy("age_group", "diagnostic") pd_result = result_df.toPandas() return pd_resultdef analyze_symptom_frequency(df): symptom_cols = ["itch", "grew", "hurt", "changed", "bleed", "elevation"] agg_exprs = [F.sum(col).alias(col) for col in symptom_cols] result_df = df.groupBy("diagnostic").agg(*agg_exprs) total_counts = df.groupBy("diagnostic").count().toPandas() pd_result = result_df.toPandas() for index, row in total_counts.iterrows(): diag = row['diagnostic'] total = row['count'] for col in symptom_cols: pd_result.loc[pd_result['diagnostic'] == diag, col] = (pd_result.loc[pd_result['diagnostic'] == diag, col] / total) * 100 return pd_resultdef apriori_mining(df, min_support=0.2): malignant_df = df.filter(df.diagnostic.isin(['MEL', 'BCC', 'SCC'])) symptom_cols = ["itch", "grew", "hurt", "changed", "bleed", "elevation"] transactions = malignant_df.select(symptom_cols).rdd.map(lambda row: [col for col in symptom_cols if row[col] == 1]).collect() from collections import defaultdict item_counts = defaultdict(int) for transaction in transactions: for item in transaction: item_counts[frozenset([item])] += 1 num_transactions = len(transactions) frequent_items = {item: count for item, count in item_counts.items() if (count / num_transactions) >= min_support} rules = [] for itemset in frequent_items: if len(itemset) > 1: for subset in [frozenset(s) for s in itemset]: if subset != itemset: antecedent = subset consequent = itemset - antecedent antecedent_support = frequent_items.get(antecedent, 0) / num_transactions rule_support = frequent_items[itemset] / num_transactions if antecedent_support > 0: confidence = rule_support / antecedent_support if confidence >= 0.5: rules.append((list(antecedent), list(consequent), rule_support, confidence)) return rules