还在为Linux系统故障焦头烂额?掌握这些命令,让你从“不知所措”到“游刃有余”!
一、开篇:运维工程师的“听诊器”与“手术刀”
想象一下:凌晨三点,服务器突然报警,网站访问缓慢。作为运维工程师,你该怎么办?就像医生需要听诊器和手术刀一样,Linux运维也需要一套得心应手的命令工具。今天,我将为你系统梳理Linux系统监控和故障排查的核心命令,从日志分析到性能监控,从网络诊断到进程管理,让你在面对各种系统问题时都能胸有成竹。二、🔍 日志分析篇:读懂系统的“日记本”
日志是系统运行的“黑匣子”,记录了系统的一举一动。不同的日志文件就像是不同主题的日记本:2.1 日志家族一览表
2.2 查看日志的三种“姿势”
姿势一:快速翻阅 - cat和less
# 查看简短日志(比如启动日志)cat /var/log/boot.log# 查看长日志,支持翻页、搜索(强烈推荐!)less /var/log/messages
💡 小技巧:在less视图中,按/键可以搜索关键词,按q退出。姿势二:只看尾巴 - tail
# 查看最后100行tail -n 100 /var/log/messages# 实时监控新日志(故障排查神器!)tail -f /var/log/secure
📖 真实场景:当有用户反映登录失败时,打开终端输入tail -f /var/log/secure,然后让用户再试一次,你就能实时看到登录失败的详细原因!姿势三:谁登录过 - last
# 查看所有登录记录last# 查看指定文件(默认就是/var/log/wtmp)last -f /var/log/wtmp
zhangsan pts/0 192.168.1.100 Mon Jun 10 09:30 still logged inlisi tty1 Mon Jun 10 08:15 - 08:30 (00:15)
三、💻 系统信息篇:全面了解你的“机器”
3.1 基础信息:一眼看穿系统底细
# 一键获取系统核心信息uname -a# 输出示例:Linux server01 3.10.0-1160.el7.x86_64 #1 SMP x86_64 x86_64 GNU/Linux# 解读:系统类型 主机名 内核版本 编译信息 架构 处理器类型 操作系统# 查看操作系统具体版本cat /etc/redhat-release # CentOS/RHELcat /etc/os-release # 通用方法
3.2 硬件信息:认识你的硬件配置
# CPU信息查询(重点看几个关键指标)cat /proc/cpuinfo | grep -E "model name|cpu cores"# 输出示例:# model name : Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz# cpu cores : 14# 查看内存信息cat /proc/meminfo | grep -E "MemTotal|MemFree|MemAvailable"# 查看所有硬件设备lspci # PCI设备(显卡、网卡等)lsusb # USB设备lsblk # 块设备(磁盘)
🎯 实用脚本:创建一个快速系统检查脚本system_check.sh:#!/bin/bashecho "====== 系统概览 ======"hostnamectlecho ""echo "====== CPU信息 ======"lscpu | grep -E "Model name|CPU\(s\)|Thread|Core"echo ""echo "====== 内存信息 ======"free -h
四、📊 资源监控篇:实时掌握系统健康状态
4.1 内存监控:别让内存成为瓶颈
total used free shared buff/cache availableMem: 62G 5.8G 1.2G 1.1G 55G 54GSwap: 4.0G 0B 4.0G
⚠️ 常见误区:不要看到free值小就紧张,Linux会充分利用内存做缓存,available才是真正可用的。4.2 磁盘空间:预防存储危机
#!/bin/bashTHRESHOLD=80 # 阈值设为80%df -h | grep -v "Filesystem" | while read linedo USE=$(echo $line | awk '{print $5}' | cut -d'%' -f1) if [ $USE -gt $THRESHOLD ]; then echo "警告: $line" fidone
4.3 系统负载:了解系统的“忙碌程度”
# 查看系统负载uptime# 输出示例:09:30:00 up 30 days, 15:20, 3 users, load average: 0.5, 1.2, 0.8
# 查看CPU核心数nproc# 或grep -c 'processor' /proc/cpuinfo
五、🌐 网络诊断篇:快速定位网络问题
5.1 网络接口信息
# 查看所有网络接口ifconfig# 或(新版推荐)ip addr show# 只看某个接口ifconfig eth0ip addr show eth0
5.2 端口与连接监控
# 查看所有监听端口(最常用!)netstat -lntp# 查看所有已建立连接netstat -antp# 统计各种连接状态netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
5.3 路由与防火墙
# 查看路由表route -n# 或ip route show# 查看防火墙规则(CentOS 7之前)iptables -L -n# 查看防火墙规则(CentOS 7+)firewall-cmd --list-all
六、⚡ 进程管理篇:掌控系统运行的每个任务
6.1 进程查看的两种方式
方式一:静态查看 - ps
# 查看所有进程(完整格式)ps -ef# 查看指定用户的进程ps -u root -o pid,user,%cpu,%mem,cmd# 按CPU使用率排序ps aux --sort=-%cpu | head -10# 按内存使用排序ps aux --sort=-%mem | head -10
方式二:动态监控 - top
6.2 用户与权限
# 查看当前登录用户w# 输出示例:# 09:30:00 up 30 days, 15:20, 3 users, load average: 0.5, 1.2, 0.8# USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT# zhangsan pts/0 192.168.1.100 09:15 5.00s 0.05s 0.00s sshd: zhangsan [priv]# 查看用户登录历史last | head -20# 查看用户ID信息id zhangsan# 输出:uid=1000(zhangsan) gid=1000(zhangsan) groups=1000(zhangsan),10(wheel)
七、🔧 服务与计划任务篇:系统自动化管理
7.1 服务管理
# 查看所有服务状态(systemd系统)systemctl list-units --type=service# 查看服务是否开机启动systemctl is-enabled sshd# 查看服务运行状态systemctl status sshd
7.2 定时任务管理
# 查看当前用户的定时任务crontab -l# 编辑定时任务crontab -e
* * * * * 命令分 时 日 月 周0-59 0-23 1-31 1-12 0-7(0和7都代表周日)
# 每天凌晨2点备份0 2 * * * /opt/scripts/backup.sh# 每周一早上5点清理日志0 5 * * 1 /opt/scripts/clean_logs.sh# 每5分钟检查一次服务*/5 * * * * /opt/scripts/check_service.sh
八、🚨 实战演练:从报警到解决的全流程
场景:网站响应缓慢故障排查
第一步:快速健康检查(30秒)
#!/bin/bashecho "1. 系统负载:"uptimeecho -e "\n2. 内存使用:"free -hecho -e "\n3. 磁盘空间:"df -hT | grep -E "(文件系统|/dev/sd)"echo -e "\n4. TOP 5进程:"ps aux --sort=-%cpu | head -6
第二步:深入问题定位
# 找出占用CPU最高的进程top -b -n 1 | head -20# 查看该进程的详细信息ps -p [PID] -o pid,ppid,user,%cpu,%mem,cmd,lstart# lsof命令,若没有yum -y install lsof# 查看该进程打开的文件lsof -p [PID]
# 查看内存使用详情cat /proc/meminfo# 查看哪些进程占用内存多ps aux --sort=-%mem | head -10# 查看内存泄漏迹象dmesg | grep -i "out of memory"
# 安装iostat(如果还没有)# yum install sysstat 或 apt-get install sysstat# 查看磁盘IOiostat -x 1 5# 安装iotop(如果没有)# yum -y install iotop 或 apt-get -y install iotop# 查看哪个进程IO高iotop
第三步:网络连接排查
# 查看Web服务端口状态netstat -lntp | grep :80netstat -lntp | grep :443# 查看当前连接数netstat -ant | grep :80 | wc -l# 查看连接来源netstat -ant | grep :80 | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nr
第四步:日志分析
# 实时查看应用日志tail -f /var/log/nginx/access.logtail -f /var/log/nginx/error.log# 搜索错误关键词grep -i "error\|fail\|timeout" /var/log/messages | tail -20# 按时间筛选日志sed -n '/Jun 10 09:00:00/,/Jun 10 09:30:00/p' /var/log/messages
九、🎯 高效工作流:运维高手的习惯
9.1 创建个人命令手册
# 创建命令速查文件cat > ~/cheatsheet.md << 'EOF'# Linux命令速查手册## 快速系统检查alias syscheck='uptime; free -h; df -h; ps aux --sort=-%cpu | head -10'## 网络诊断alias netcheck='netstat -lntp; ss -s'## 日志查看alias logweb='tail -f /var/log/nginx/access.log'alias logsys='tail -f /var/log/messages'EOF
9.2 编写常用检查脚本
#!/bin/bash# 文件名:quick_check.sh# 快速系统健康检查echo "======================"echo "系统健康检查报告"echo "生成时间: $(date)"echo "======================"check_disk() { echo "【磁盘空间检查】" df -h | grep -v "tmpfs\|devtmpfs" echo ""}check_memory() { echo "【内存使用检查】" free -h echo ""}check_load() { echo "【系统负载检查】" uptime echo ""}check_service() { echo "【关键服务检查】" for service in sshd nginx mysqld do if systemctl is-active $service >/dev/null 2>&1; then echo "✓ $service 运行正常" else echo "✗ $service 服务异常!" fi done echo ""}# 执行所有检查check_diskcheck_memorycheck_loadcheck_service
十、📚 总结与进阶
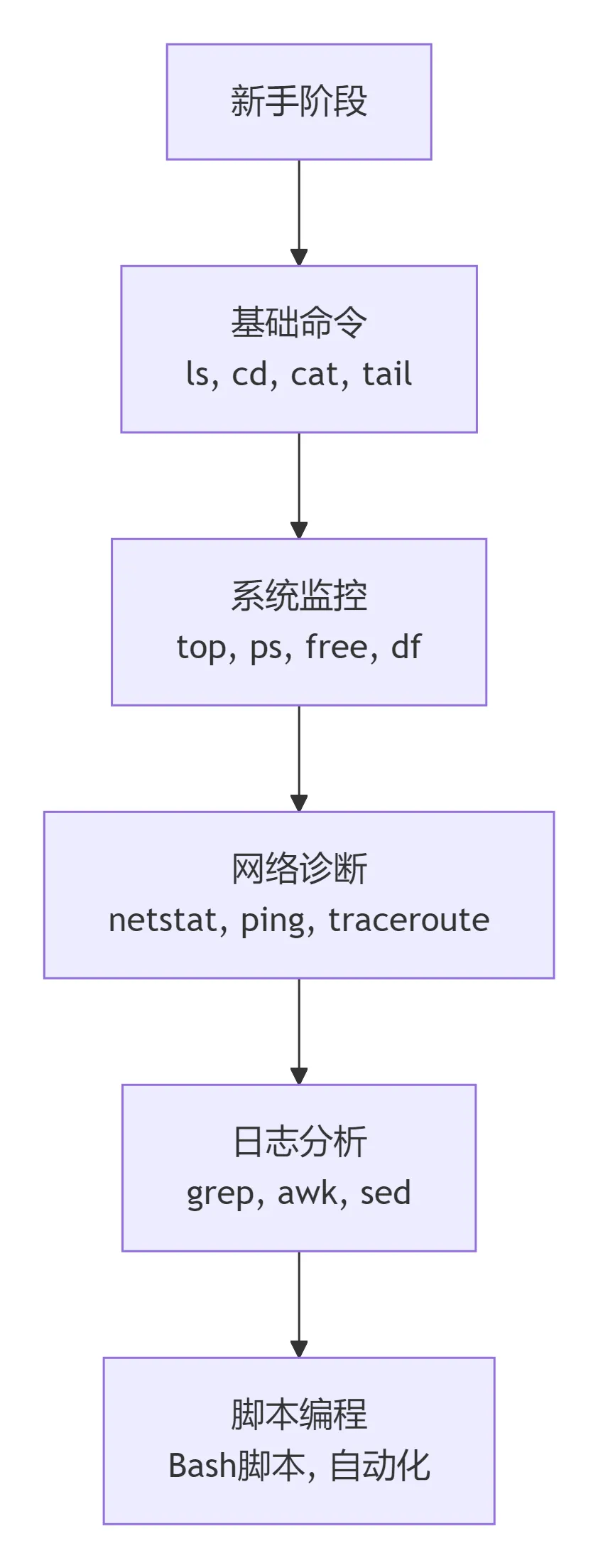
10.1 命令学习路径图
10.2 推荐学习资源
在线练习:https://overthewire.org/wargames/bandit/
命令大全:https://explainshell.com/
速查手册:https://linuxcommand.org/
10.3 最后的建议
动手实践:在自己的虚拟机或云服务器上多练习
理解原理:知道命令背后发生了什么
善用帮助:man 命令和命令 --help是最好的老师
记录总结:遇到问题及时记录解决方案
记住:真正的运维高手不是记住所有命令的人,而是知道在什么场景下使用什么命令的人。
你遇到过最棘手的Linux问题是什么?
有哪些你特别喜欢的”神器”命令?
在学习Linux运维过程中有什么心得?
在评论区分享你的经验,让我们一起进步!如果觉得这篇文章有帮助,欢迎点赞收藏转发~