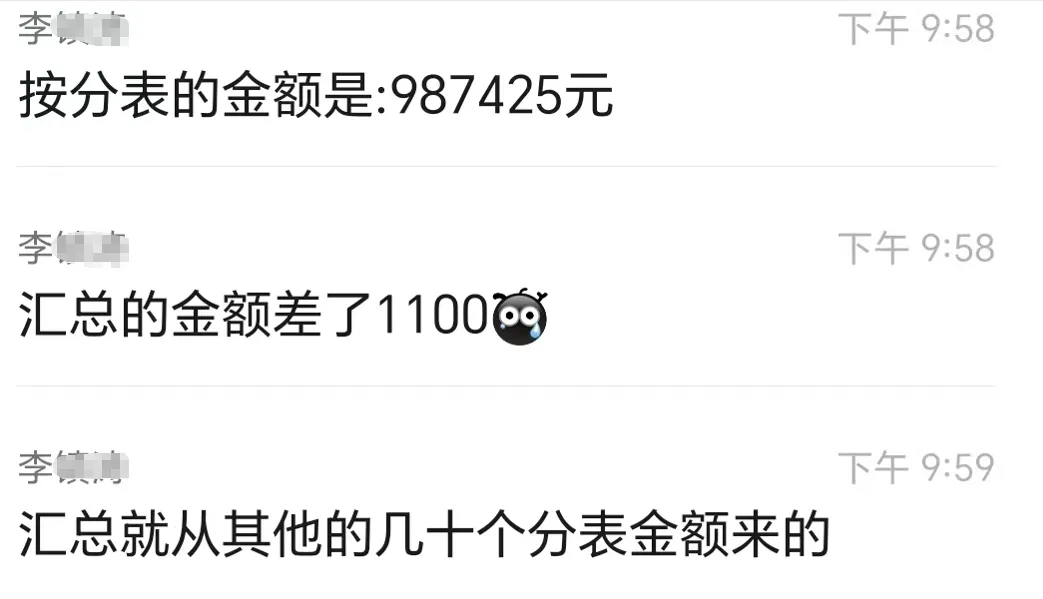
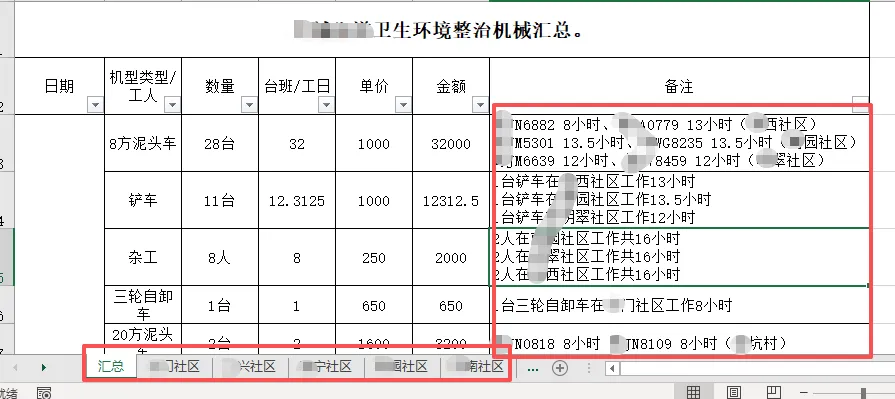
作为工程人员/财务人员,你是否也有过对不账的崩溃瞬间:月末核对工程量,面对着几十张分表和一张汇总表,看着密密麻麻的数字,翻来覆去鼓捣了半天,眼睛都看花了,算了一遍又一遍,可就是对不上,哪个单位、哪笔数据有错,问题到底出在哪,一点头绪也没有。最近就收到了网友的一个问题:他在对账时,当月的工作量和各单位上报的分表数据工作量始终对不上。31个单位上报的分表金额合计为987425元,总表的总金额合计986325元,两者相差了1100元,手工核对了大半天也没有找出来,反复算了好几遍就是不知道问题出在了哪,问我有没有好的办法。这种分表与总表对不上账的难题,我之前也遇到过好几次,每次都要翻来覆去折腾半天,或者一个小数点、一个加减号,或者某处多了或少了一个数字,真有点大海捞针、雾里看花的感觉。说白了,大致有几个老大难的问题:首先是表格太多。Excel表格里除了汇总表,还有几十张各单位的分表,光打开切换就得费不少时间;其次是数据格式乱七八糟:有的有单位(比如28台),有的没有单位(如28)。总表的日期列还是个合并单元格,无法直接求和;最令人头疼还是无法快速直接定位问题。逐行比对计算易遗漏,出错后难以快速定位问题表格,越弄越乱,越乱越容易疲劳、出错。靠人工硬扛死磕肯定不是办法,我曾经也想过,有没有自动化处理的方法,今天就依此为例,把Python自动化解决方案分享给大家,让你避开那些踩过的坑。import pandas as pdimport reimport timedef extract_num(txt, is_TF=False): txt=str(txt) if is_TF: pattern=r"-?\d+(\.\d+)?" else: pattern=r"-?\d+" if match := re.search(pattern,txt): if is_TF: return float(match.group(0)) else: return int(match.group(0)) return 0.0 if is_TF else 0def re_danwei(txt): txt=str(txt) t_list=[] for t in txt.split("\n"): if match:=re.search(r"在(.*(社区|村))|[\((](.*(社区|村))", t): if "在" in t: word=match.group(1) else: word=match.group(3) t_list.append(word) return "\n".join(t_list)s_t=time.time()input_path=r'E:\机械汇总2025-10.09-2025-10.31.xlsx'output_path=r'E:\机械汇总_差异.xlsx'dfs=pd.read_excel(input_path, sheet_name=None, header=1)# 分表处理data=[]for name, df in dfs.items(): if name !="汇总": df_fen= df.dropna(subset="机型类型/工人").copy() df_fen["日期"]=df_fen["日期"].ffill() df_fen["日期"]=pd.to_datetime(df_fen["日期"], errors='coerce').dt.date df_fen["数量"]=df_fen["数量"].apply(extract_num) df_fen["金额"]=df_fen["金额"].apply(extract_num, is_TF=True) df_fen["工作表"]=name data.append(df_fen)df_f= pd.concat(data, ignore_index=True)df_pivot=pd.pivot_table(df_f, index=["日期", "机型类型/工人"], values=["数量", "金额", "工作表"], aggfunc={"数量": "sum", "金额": "sum", "工作表": lambda x: "\n".join(x)}, fill_value=0).reset_index()# 总表处理df_z=dfs["汇总"].dropna(subset="机型类型/工人").copy()df_z["日期"]=df_z["日期"].ffill()df_z["日期"]=pd.to_datetime(df_z["日期"], errors='coerce').dt.datedf_z["数量"]=df_z["数量"].apply(extract_num)df_z["金额"]=df_z["金额"].apply(extract_num, is_TF=True)df_z["备注"]=df_z["备注"].apply(re_danwei)# 合并找差df_mer =pd.merge(df_z,df_pivot,on=["日期", "机型类型/工人"],how="outer",suffixes=("_汇总", "_分表"))df_mer["金额差异"]= df_mer["金额_汇总"]-df_mer["金额_分表"]df_mer =df_merged[df_mer["金额差异"] != 0]df_mer.to_excel(output_path, index=False)print(f"共发现 {len(df_mer)} 行差异,用时{time.time()-s_t:.3f}秒")print(f"汇总表金额:{df_z["金额"].sum()}元")print(f"分表总金额:{df_pivot["金额"].sum()}元")print(f"两表差异额:{df_mer["金额差异"].sum()}元")print(f"差异数据已保存至:{output_path}")
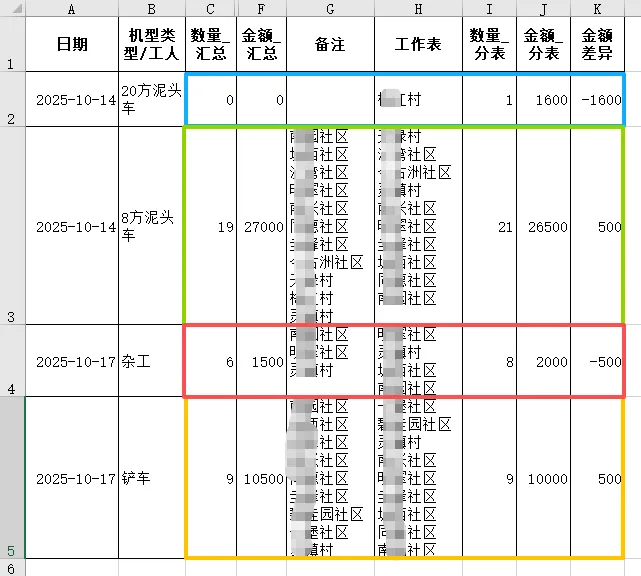
首先我们来看看效果。一键运行这段代码,仅0.5秒显示结果,完成了一个月来总表和分表的工程量核对,差异数据以工作簿形式保存到指定路径下,结果一目了然,真有种众里寻她千百度,蓦然回首,那人却在灯火阑珊处的感觉。其实,这段代码看着复杂,却是和实际对账流程是一致的,每一步都对针对性人工核对的过程来写的:
一、用自定义函数统一数据格式
一个是extract_num(),其作用是用正则表达式提取单元格中的纯数字,解决28和28台数据类型不一致问题。这个函数接收两个参数,第一参数为文本,第二参数是布尔值,默认为False,结果返回整数型或小数型,没有数字则返回0,避免数值型数据和文本型数据的求和报错。
另一个是re_danwei(),其作用是从总表的备注列中提取社区或村的名称,因为分表是按单位命名的,提取出来方便与分表做对比,找出哪个单位的数据不一致。正则表达式包括两情况:一种是提出“在**社区工作”中的单位名称,一种是提取“(**社区)”中的单位名称。
二、总表和分表数据整理过程
1、跳过空行:这一步使用.dropna(subset="机型类型/工人").copy()删除“机型类型/工人”一列为空的行,过滤无效数据行。
2、填充日期。汇总表的日期列是合并单元格,拆分后多为空值,日期列使用.ffill()方法向下填充,方便后续按日期分组。
3、数值提取。这一步通过调用extract_num()把总表和分表的数量和金额两列统一转换为可直接计算的数值类型。
三、对比找差异
1、分表聚合。首先使用pd.pivot_table()把日期和机型类型/工人分组汇总,在这里相当于用代码把所有分表的数据和金额做了求和汇总。
2、表格合并。这里使用了pd.merge()方法的外连接,按照“日期+机型类型/工人”两列,把汇总表和分表汇总结果进行横向合并。使用外连接的目的是保留两个表中的所有数据。
3、对比找差异。这一步通过计算"金额_汇总"和"金额_分表"两列的差,并对差值进行判断,通过df_merged["金额差异"]!=0,找出总表和分表全额不一致的行。
四、保存文件、输出结果
输出的结果包括差异行数、运行耗时、总金额、差异金额、差异文件保存位置等。
说句实话,面对海量数据的核对任务,如果传统人工方式难以满足工作需要,你可以试试这段代码,它一定会把你的双手从重复性劳动中解放出来,还能精准定位每一行差异。