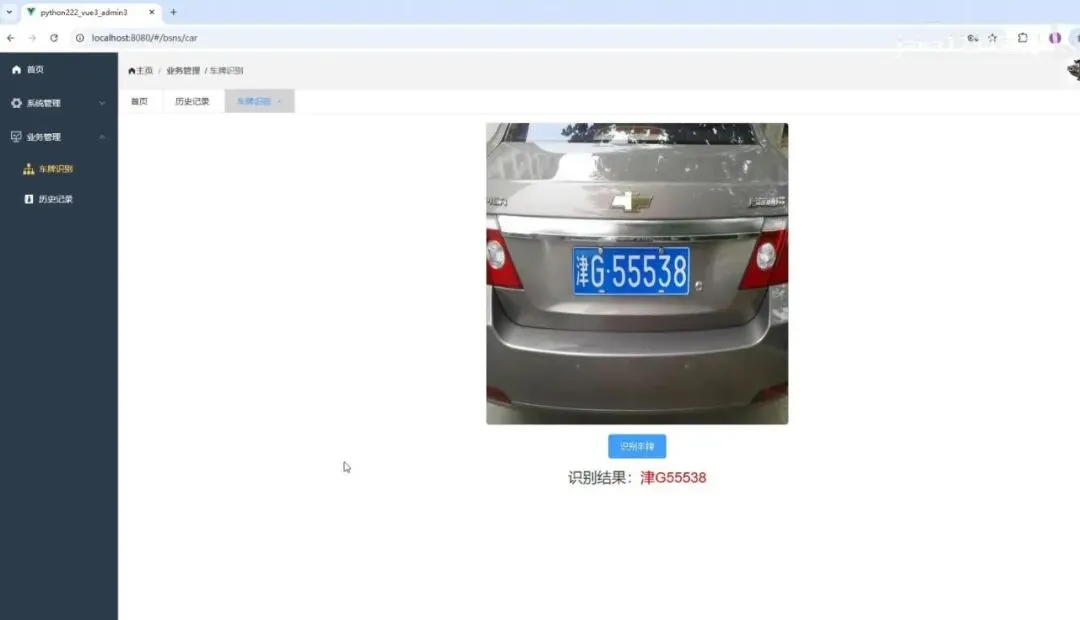
大家好,我是python222_锋哥,最近更新基于Python深度学习的车辆车牌识别系统(PyTorch2卷积神经网络CNN+OpenCV4实现)视频教程系列课程,感谢大家支持。
B站连载更新地址:
https://www.bilibili.com/video/BV1BdUnBLE6N/
本课程采用主流的Python技术栈实现,分两套系统讲解,一套是专门讲PyTorch2卷积神经网络CNN训练模型,识别车牌,当然实现过程中还用到OpenCV实现图像格式转换,裁剪,大小缩放等。另外一套是基于前面Django+Vue通用权限系统基础上(https://www.bilibili.com/video/BV19spseGE9Y/),加了车辆识别业务模型,Mysql8数据库,Django后端,Vue前端,后端集成训练好的模型,实现车牌识别。
1,图像预处理
首先我们要对提供的车牌图像进行图片预处理,处理目的是得到图像里的车牌具体矩阵位置,方便后面的工序。
我们使用opencv对图像进行处理,我们这边首先要进行图像灰度化;
然后进行均值模糊;
以及通过sobel算子处理,对模糊图像进行边缘检测;
接下来,我们获取HSV色彩空间,因为车牌不是黄色的,就是蓝色的,我们根据颜色来判断车牌;通过mix混合图像,得到车牌矩阵位置;
我们再进行二值化,不是0就是255
最后对二值图像进行闭运算,可以填充可能的断裂并去除小的物体。
新建lprs_main.py。
importosimportcv2importnumpyasnp# 车牌字符char_table = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K','L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '川', '鄂', '赣', '甘', '贵','桂', '黑', '沪', '冀', '津', '京', '吉', '辽', '鲁', '蒙', '闽', '宁', '青', '琼', '陕', '苏', '晋','皖', '湘', '新', '豫', '渝', '粤', '云', '藏', '浙']# 图像预处理defpre_process(orig_img):gray_img = cv2.cvtColor(orig_img, cv2.COLOR_BGR2GRAY) # BGR色彩空间转换为灰度图像cv2.imwrite('process_img/gray_img.jpg', gray_img) # 保存灰度图blur_img = cv2.blur(gray_img, (3, 3)) # 对灰度图像进行均值模糊,使用3*3的内核来减少图像噪声cv2.imwrite('process_img/blur_img.jpg', blur_img) # 保存模糊图# 对模糊图进行sobel算子处理 对模糊图像进行边缘检测处理# 参数1, 0表示只计算x方向梯度,不计算y方向梯度# ksize=3表示使用3×3的卷积核进行计算# cv2.CV_16S表示输出图像的深度为16位有符号整数sobel_img = cv2.Sobel(blur_img, cv2.CV_16S, 1, 0, ksize=3)sobel_img = cv2.convertScaleAbs(sobel_img) # 转换为8位图像cv2.imwrite('process_img/sobel_img.jpg', sobel_img) # 保存sobel图hsv_img = cv2.cvtColor(orig_img, cv2.COLOR_BGR2HSV) # 获取图像的HSV色彩空间h, s, v = hsv_img[:, :, 0], hsv_img[:, :, 1], hsv_img[:, :, 2]# 黄色色调区间[26,34],蓝色色调区间:[100,124]blue_img = (((h>26) & (h<34)) | ((h>100) & (h<124))) & (s>70) & (v>70)blue_img = blue_img.astype('float32')cv2.imwrite('process_img/hsv.jpg', blue_img)mix_img = np.multiply(sobel_img, blue_img) # 混合图像cv2.imwrite('process_img/mix.jpg', mix_img)mix_img = mix_img.astype(np.uint8) # 转换为uint8ret, binary_img = cv2.threshold(mix_img, 0, 255, cv2.THRESH_BINARY|cv2.THRESH_OTSU) # 二值化cv2.imwrite('process_img/binary.jpg', binary_img)kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (21, 5)) # 定义一个结构元素 尺寸为21×5close_img = cv2.morphologyEx(binary_img, cv2.MORPH_CLOSE, kernel) # 对二值图像进行闭运算,可以填充可能的断裂并去除小的物体cv2.imwrite('process_img/close.jpg', close_img)returnclose_imgdeflist_all_files(root):files = []list = os.listdir(root) # 获取根目录下的所有文件名foriinrange(len(list)):element = os.path.join(root, list[i]) # 获取文件路径ifos.path.isfile(element): # 判断是否是文件files.append(element)elifos.path.isdir(element): # 递归判断子目录files.extend(list_all_files(element))returnfilesif__name__ == '__main__':car_plate_w, car_plate_h = 136, 36# 车牌宽高char_w, char_h = 20, 20# 字符宽高char_model_path = "char.pth"test_images_root = 'images/test/'# 测试图片路径files = list_all_files(test_images_root)files.sort()forfileinfiles:img = cv2.imread(file) # 读取图片pre_process(img)2,车牌矩阵定位
前面我们做了图像预处理,接下来可以进行车牌矩阵定位:
defverify_scale(rotate_rect):returnTruedefimg_transform(rotate_rect, orig_img):returnNonedeflocate_carPlate(orig_img, pred_img):carPlate_list = [] # 车牌列表temp1_orig_img = orig_img.copy() # 拷贝图片 调试用temp2_orig_img = orig_img.copy() # 拷贝图片 调试用# 从二值图像中查找轮廓的函数# cv2.RETR_EXTERNAL参数表示只检索最外层轮廓,# cv2.CHAIN_APPROX_SIMPLE参数表示压缩轮廓的水平、垂直和对角线部分,只保留端点。# 函数返回轮廓列表contours和层级信息heriachy,用于后续的车牌定位处理。contours, hierarchy = cv2.findContours(pred_img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)fori, contourinenumerate(contours):""" 这段代码的功能是在调试图像上绘制检测到的轮廓。具体来说: cv2.drawContours()函数用于在temp1_orig_img图像上绘制轮廓 contours是要绘制的轮廓点集 i表示当前绘制第几个轮廓 (0, 255, 255)是绘制的颜色(青色) 2是线条粗细度 这样可以可视化显示所有检测到的车牌候选区域轮廓,便于调试观察。 """cv2.drawContours(temp1_orig_img, contours, i, (0, 255, 255), 2)""" 获取当前轮廓的最小外接矩形,cv2.minAreaRect()函数会计算能够完全包围轮廓的最小面积矩形, 并返回一个包含矩形中心点坐标、宽度高度和旋转角度的元组, 用于后续的车牌定位和矫正处理。 """rotate_rect = cv2.minAreaRect(contour)# 根据矩形面积大小和长宽比判断是否是车牌ifverify_scale(rotate_rect):# 裁剪车牌并且位置矫正car_plate = img_transform(rotate_rect, temp2_orig_img)cv2.imwrite('process_img/transform_img.jpg', car_plate)# 调整尺寸为后面CNN车牌识别做准备car_plate = cv2.resize(car_plate, (car_plate_w, car_plate_h))cv2.imwrite('process_img/resize_img.jpg', car_plate)carPlate_list.append(car_plate)returncarPlate_listif__name__ == '__main__':car_plate_w, car_plate_h = 136, 36# 车牌宽高char_w, char_h = 20, 20# 字符宽高char_model_path = "char.pth"test_images_root = 'images/test/'# 测试图片路径files = list_all_files(test_images_root)files.sort()forfileinfiles:img = cv2.imread(file) # 读取图片pred_img = pre_process(img) # 预处理图片locate_carPlate(img, pred_img) # 车牌定位3,验证检测到的矩阵是否符合车牌尺寸比例和面积特征
我们根据识别的矩阵,我们通过矩形尺寸比例和面积特征,来检测是否是车牌矩形。
# # 验证检测到的矩阵区域是否符合车牌的尺寸比例和面积特征defverify_scale(rotate_rect):error = 0.4# error为车牌允许的宽高比误差aspect = 4# 4.7272 # aspect为期望的车牌宽高比,计算车牌的最小和最大面积。这些值用于过滤掉不符合车牌尺寸的矩形min_area = 10* (10*aspect)max_area = 150* (150*aspect)# 计算车牌区域的宽高比的最小值和最大值,考虑到了误差范围min_aspect = aspect* (1-error)max_aspect = aspect* (1+error)# 宽或高为0,不满足矩形直接返回Falseifrotate_rect[1][0] == 0orrotate_rect[1][1] == 0:returnFalse# 计算旋转矩形r = rotate_rect[1][0] /rotate_rect[1][1]r = max(r, 1/r)area = rotate_rect[1][0] *rotate_rect[1][1] # 计算旋转矩形的面积ifarea>min_areaandarea<max_areaandr>min_aspectandr<max_aspect:returnTruereturnFalse
运行结果:
车牌坐标: ((313.5, 237.5), (255.0, 77.0), 0.0)车牌坐标: ((401.5, 590.5), (71.0, 225.0), 90.0)车牌坐标: ((658.30126953125, 182.3743438720703), (189.67578125, 53.47734832763672), 69.87654876708984)车牌坐标: ((257.0, 175.5), (174.0, 41.0), 0.0)车牌坐标: ((228.74288940429688, 81.48967742919922), (39.02401351928711, 144.0416717529297), 89.20427703857422)车牌坐标: ((463.8109130859375, 338.7987976074219), (37.1049919128418, 124.45632934570312), 83.6598129272461)车牌坐标: ((407.3741455078125, 437.90704345703125), (214.31515502929688, 61.04008102416992), 4.717602252960205)
4,裁剪和矫正车牌
前面我们得到验证后的矩阵车牌,然后我们需要从图像中裁剪出车牌。根据旋转角度我们需要进行计算,如果有旋转,我们必须先进行矫正后再裁剪。
# 将检测到的车牌区域从原始图像中正确的裁剪出来,并进行必要的变换以满足后续处理的需求,如车牌矫正和大小调整defimg_Transform(car_rect, image):img_h, img_w = image.shape[:2] # 获取图片的宽高rect_w, rect_h = car_rect[1][0], car_rect[1][1] # 获取车牌的宽和高angle = car_rect[2] # 获取车牌的旋转角度return_flag = Falseifcar_rect[2] == 0.0: # 旋转角度为0return_flag = Trueifcar_rect[2] == 90.0andrect_w<rect_h: # 旋转角度为90 并且 宽高比小于1rect_w, rect_h = rect_h, rect_wreturn_flag = Trueifreturn_flag:""" 从原始图像中裁剪出车牌区域。具体来说: 使用car_rect[0]作为车牌中心点坐标; 根据车牌的宽度rect_w和高度rect_h,计算上下左右边界; 从原图image中截取以该中心点为中心、指定宽高的矩形区域作为车牌图像car_img。 """car_img = image[int(car_rect[0][1] -rect_h/2):int(car_rect[0][1] +rect_h/2),int(car_rect[0][0] -rect_w/2):int(car_rect[0][0] +rect_w/2)]returncar_img# 将车牌从图片中切割出来""" 1. 使用`cv2.boxPoints`获取旋转矩形的四个顶点坐标。 2. 初始化四个变量分别用于记录最左、最下、最高和最右的点。 3. 遍历四个顶点,根据坐标更新这四个变量,从而确定矩形的边界点,为后续仿射变换做准备。 """car_rect = (car_rect[0], (rect_w, rect_h), angle) # 创建旋转矩阵box = cv2.boxPoints(car_rect) # 调用函数获取矩形边框的四个点heigth_point = right_point = [0, 0] # 定义变量保存矩形边框的右上顶点left_point = low_point = [car_rect[0][0], car_rect[0][1]] # 定义变量保存矩形边框的左下顶点forpointinbox:ifleft_point[0] >point[0]:left_point = pointiflow_point[1] >point[1]:low_point = pointifheigth_point[1] <point[1]:heigth_point = pointifright_point[0] <point[0]:right_point = point""" 这段代码用于根据车牌的旋转角度,对图像进行仿射变换以矫正车牌区域。具体步骤如下: 1. 判断角度正负:通过比较左点和右点的纵坐标判断车牌是正角度还是负角度倾斜。 2. 构造目标点:根据倾斜方向调整右上角或左下角点的位置,使车牌变为水平。 3. 生成变换矩阵:使用`cv2.getAffineTransform`计算三点之间的仿射变换矩阵。 4. 执行仿射变换:利用`cv2.warpAffine`将图像展开并裁剪出矫正后的车牌区域。 最终返回的是经过旋转矫正后的车牌图像。 """ifleft_point[1] <= right_point[1]: # 正角度new_right_point = [right_point[0], heigth_point[1]]pts1 = np.float32([left_point, heigth_point, right_point])pts2 = np.float32([left_point, heigth_point, new_right_point]) # 字符只是高度需要改变M = cv2.getAffineTransform(pts1, pts2)dst = cv2.warpAffine(image, M, (round(img_w*2), round(img_h*2)))car_img = dst[int(left_point[1]):int(heigth_point[1]), int(left_point[0]):int(new_right_point[0])]elifleft_point[1] >right_point[1]: # 负角度new_left_point = [left_point[0], heigth_point[1]]pts1 = np.float32([left_point, heigth_point, right_point])pts2 = np.float32([new_left_point, heigth_point, right_point]) # 字符只是高度需要改变M = cv2.getAffineTransform(pts1, pts2)dst = cv2.warpAffine(image, M, (round(img_w*2), round(img_h*2)))car_img = dst[int(right_point[1]):int(heigth_point[1]), int(new_left_point[0]):int(right_point[0])]returncar_img
运行项目测试下,可以得到矫正和裁剪后的车牌。
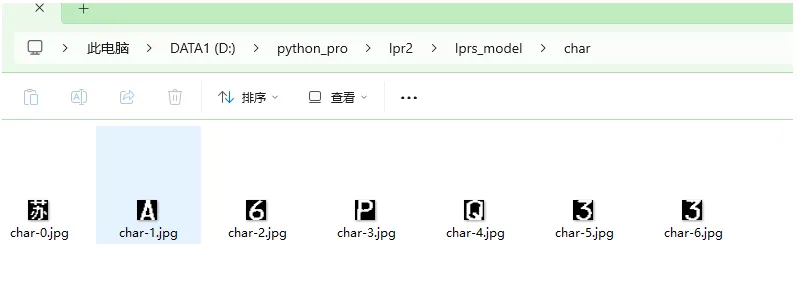
5,切割车牌矩阵获取车牌字符
前面代码我们从图像中截取了车牌矩阵,现在我们来切割车牌字符。
# 左右切割defhorizontal_cut_chars(plate):""" 该函数用于对车牌图像进行水平切割,提取字符区域。主要步骤包括: 1. 计算每列像素点总和; 2. 根据阈值判断字符区域起止位置; 3. 限制字符宽度范围以过滤无效区域; 4. 返回符合条件的字符区域坐标列表。 """char_addr_list = []area_left, area_right, char_left, char_right = 0, 0, 0, 0img_w = plate.shape[1]# 获取车牌每列边缘像素点个数defgetColSum(img, col):sum = 0foriinrange(img.shape[0]):sum += round(img[i, col] /255)returnsum;sum = 0forcolinrange(img_w):sum += getColSum(plate, col)# 每列边缘像素点必须超过均值的60%才能判断属于字符区域col_limit = 0# round(0.6*sum/img_w)# 每个字符宽度也进行限制charWid_limit = [round(img_w/12), round(img_w/5)]is_char_flag = Falseforiinrange(img_w):colValue = getColSum(plate, i)ifcolValue>col_limit:ifis_char_flag == False:area_right = round((i+char_right) /2)area_width = area_right-area_leftchar_width = char_right-char_leftif (area_width>charWid_limit[0]) and (area_width<charWid_limit[1]):char_addr_list.append((area_left, area_right, char_width))char_left = iarea_left = round((char_left+char_right) /2)is_char_flag = Trueelse:ifis_char_flag == True:char_right = i-1is_char_flag = False# 手动结束最后未完成的字符分割ifarea_right<char_left:area_right, char_right = img_w, img_warea_width = area_right-area_leftchar_width = char_right-char_leftif (area_width>charWid_limit[0]) and (area_width<charWid_limit[1]):char_addr_list.append((area_left, area_right, char_width))returnchar_addr_list# 获取字符defget_chars(car_plate):img_h, img_w = car_plate.shape[:2]h_proj_list = [] # 水平投影长度列表h_temp_len, v_temp_len = 0, 0h_startIndex, h_end_index = 0, 0# 水平投影记索引h_proj_limit = [0.2, 0.8] # 车牌在水平方向得轮廓长度少于20%或多余80%过滤掉char_imgs = []""" 这段代码用于对二值化车牌图像进行水平投影分析。 它统计每一行的白色像素数量,记录连续有效投影段,并根据比例过滤掉过短或过长的投影区域, 最终提取出最可能包含字符的水平区域。 """# 将二值化的车牌水平投影到Y轴,计算投影后的连续长度,连续投影长度可能不止一段h_count = [0foriinrange(img_h)]forrowinrange(img_h):temp_cnt = 0forcolinrange(img_w):ifcar_plate[row, col] == 255:temp_cnt += 1h_count[row] = temp_cntiftemp_cnt/img_w<h_proj_limit[0] ortemp_cnt/img_w>h_proj_limit[1]:ifh_temp_len!= 0:h_end_index = row-1h_proj_list.append((h_startIndex, h_end_index))h_temp_len = 0continueiftemp_cnt>0:ifh_temp_len == 0:h_startIndex = rowh_temp_len = 1else:h_temp_len += 1else:ifh_temp_len>0:h_end_index = row-1h_proj_list.append((h_startIndex, h_end_index))h_temp_len = 0# 手动结束最后得水平投影长度累加ifh_temp_len!= 0:h_end_index = img_h-1h_proj_list.append((h_startIndex, h_end_index))""" 这段代码的功能是: 1. 遍历水平投影列表,找出最长的有效投影段(即字符区域)。 2. 若该投影段高度不足图像总高度的50%,则认为未检测到有效车牌字符,直接返回空结果。 3. 否则,截取该区域作为车牌主体部分,并调用[horizontal_cut_chars]函数进一步横向切割出每个字符的边界。 4. 根据字符边界从原图中提取每个字符图像,缩放到统一尺寸后加入结果列表返回。 """h_maxIndex, h_maxHeight = 0, 0fori, (start, end) inenumerate(h_proj_list):ifh_maxHeight< (end-start):h_maxHeight = (end-start)h_maxIndex = iifh_maxHeight/img_h<0.5:returnchar_imgschars_top, chars_bottom = h_proj_list[h_maxIndex][0], h_proj_list[h_maxIndex][1]plates = car_plate[chars_top:chars_bottom+1, :]cv2.imwrite('process_img/plate.jpg', plates)char_addr_list = horizontal_cut_chars(plates)fori, addrinenumerate(char_addr_list):char_img = car_plate[chars_top:chars_bottom+1, addr[0]:addr[1]]char_img = cv2.resize(char_img, (char_w, char_h))char_imgs.append(char_img)returnchar_imgsdefextract_char(car_plate):gray_plate = cv2.cvtColor(car_plate, cv2.COLOR_BGR2GRAY) # 转为灰度图ret, binary_plate = cv2.threshold(gray_plate, 0, 255, cv2.THRESH_BINARY|cv2.THRESH_OTSU) # 二值化cv2.imwrite('process_img/binary_plate.jpg', gray_plate)print(binary_plate)returnget_chars(binary_plate)if__name__ == '__main__':car_plate_w, car_plate_h = 136, 36# 车牌宽高char_w, char_h = 20, 20# 字符宽高char_model_path = "char.pth"test_images_root = 'images/test/'# 测试图片路径files = list_all_files(test_images_root)files.sort()forfileinfiles:img = cv2.imread(file) # 读取图片pred_img = pre_process(img) # 预处理图片car_plate_list = locate_carPlate(img, pred_img) # 车牌定位iflen(car_plate_list) == 0:continueelse:car_plate = car_plate_list[0] # 获取车牌char_img_list = extract_char(car_plate) # 获取车牌字符foridinrange(len(char_img_list)):img_name = 'char/char-'+str(id) +'.jpg'cv2.imwrite(img_name, char_img_list[id])运行后,能得到切割后的字符