假如我們有一個文本,部分內容如下
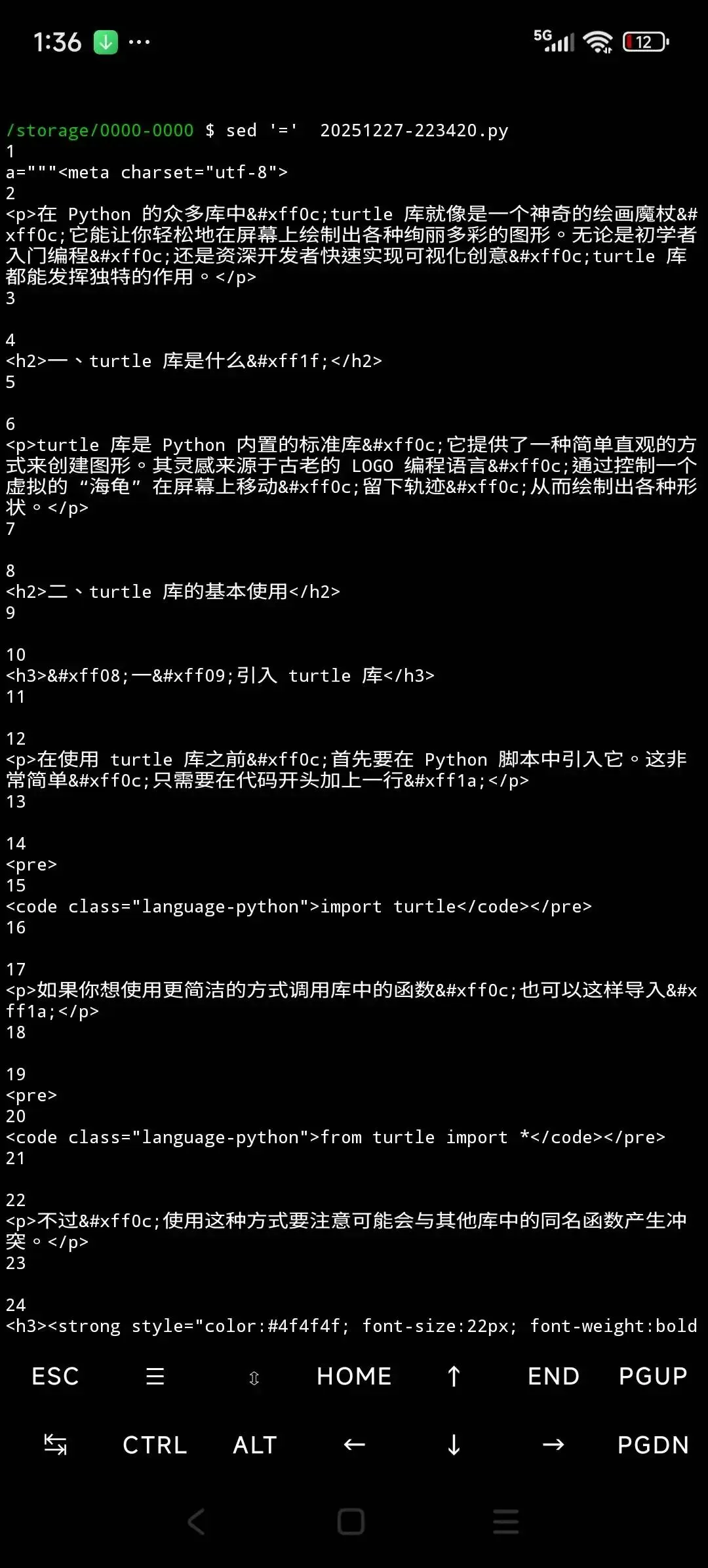
經過分析,發現其內容概述的標簽是<h2></h2>。
在正則表達式中,我們這樣寫:
re.findall('<h2>.*?</h2>',a)。
在bf4中,我是這樣寫的
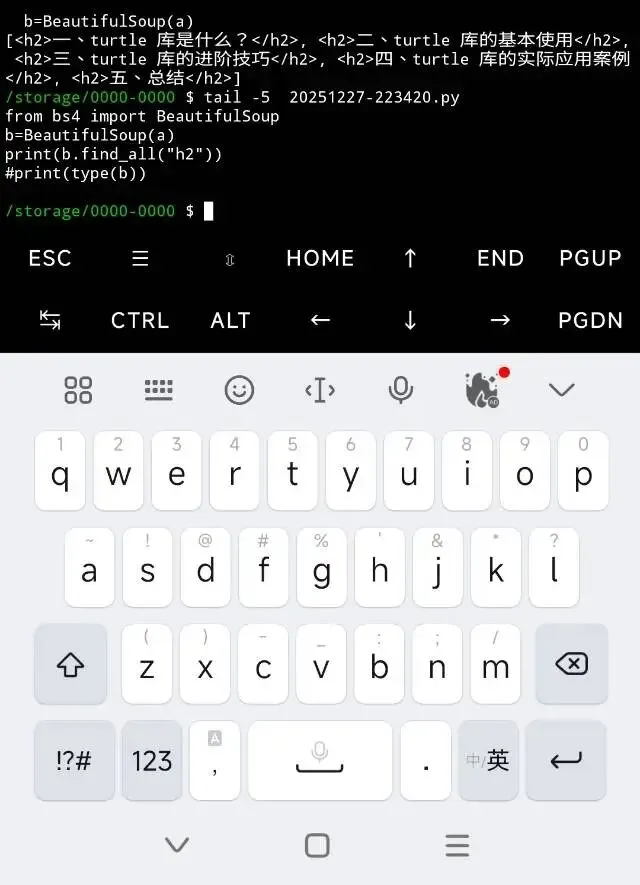
但如果標簽中內容如果比較簡單,用re正則還能湊合。
如果多層的標簽,re就顯得不哪麼友好。這個時候bs4的強大就發揮作用了。
下面我就用幾個常用的方法來做演示。
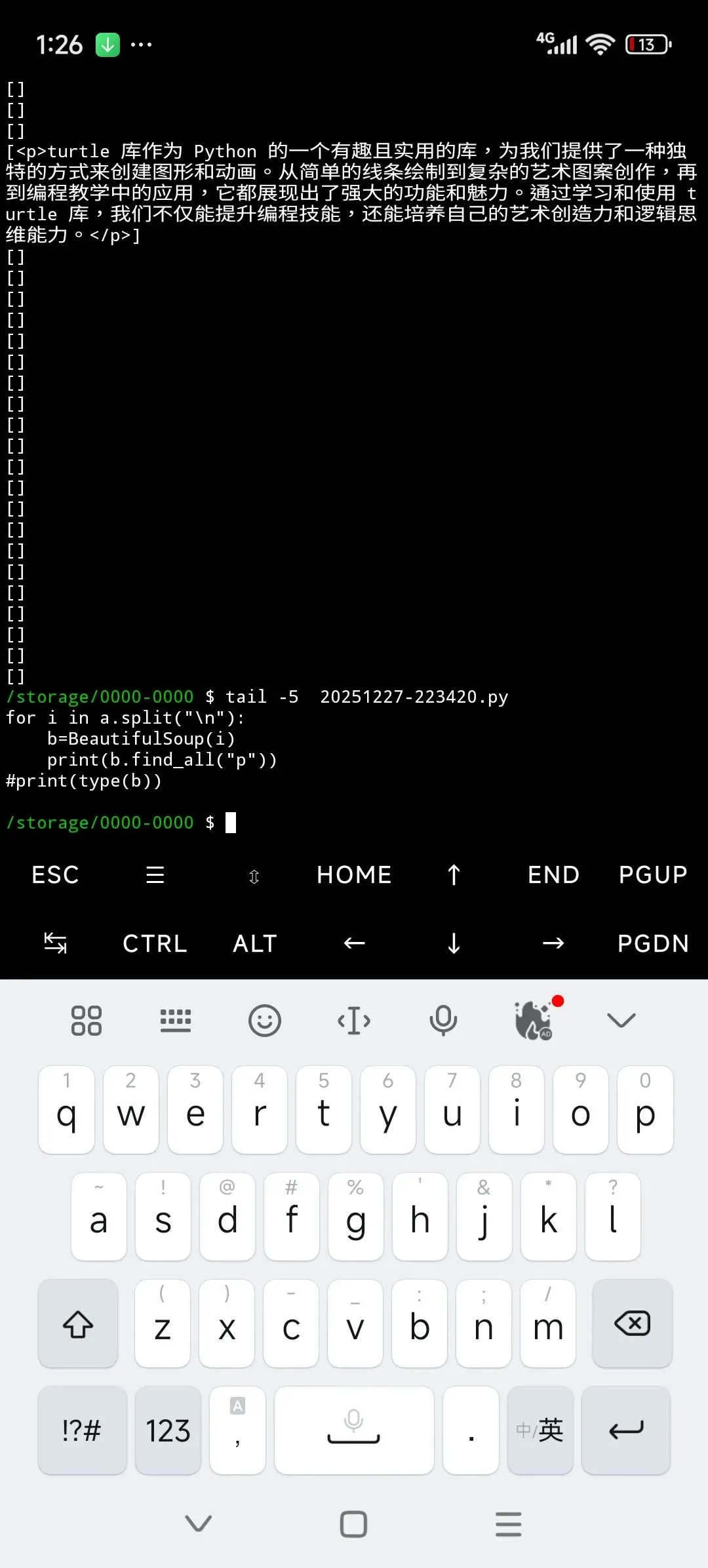
獲取p標簽
string用法
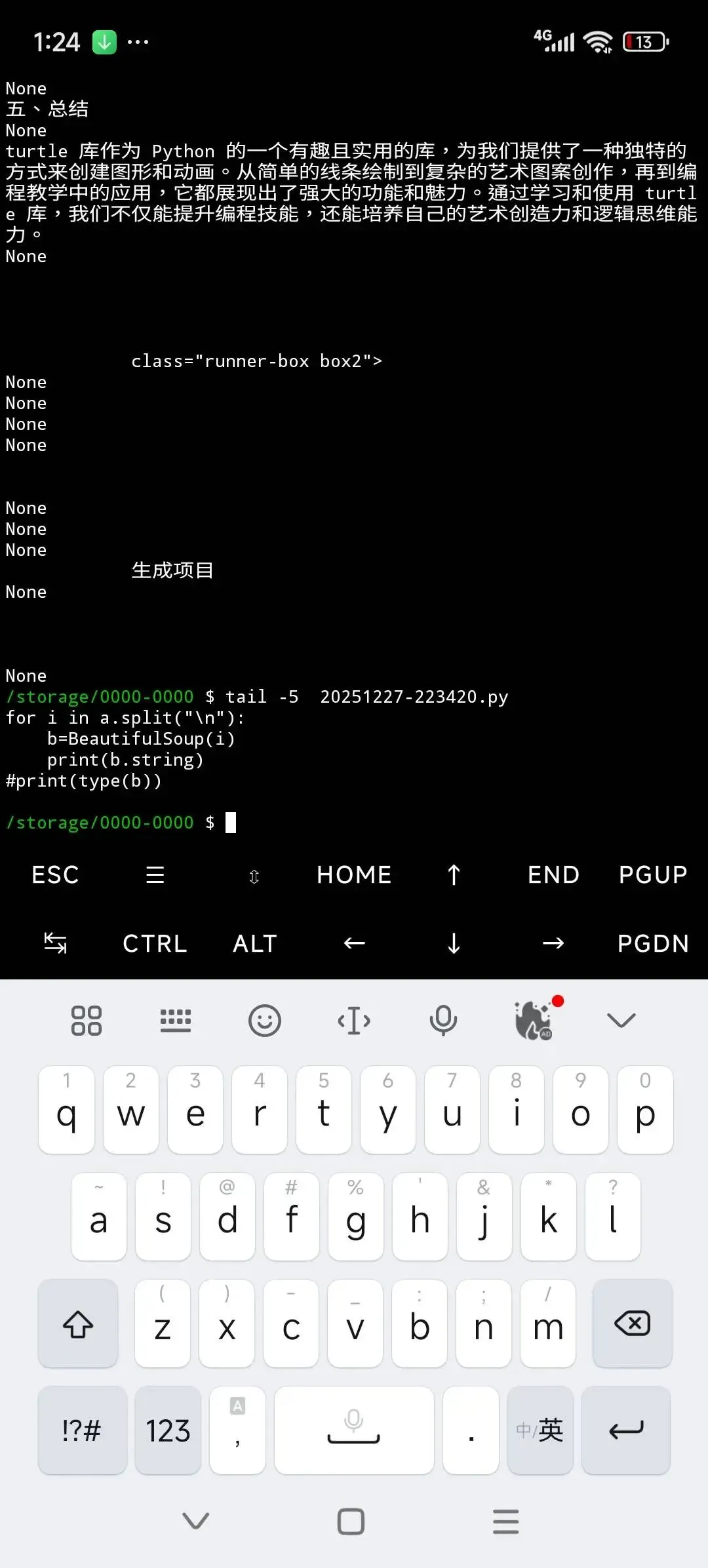
text用法
text用法1
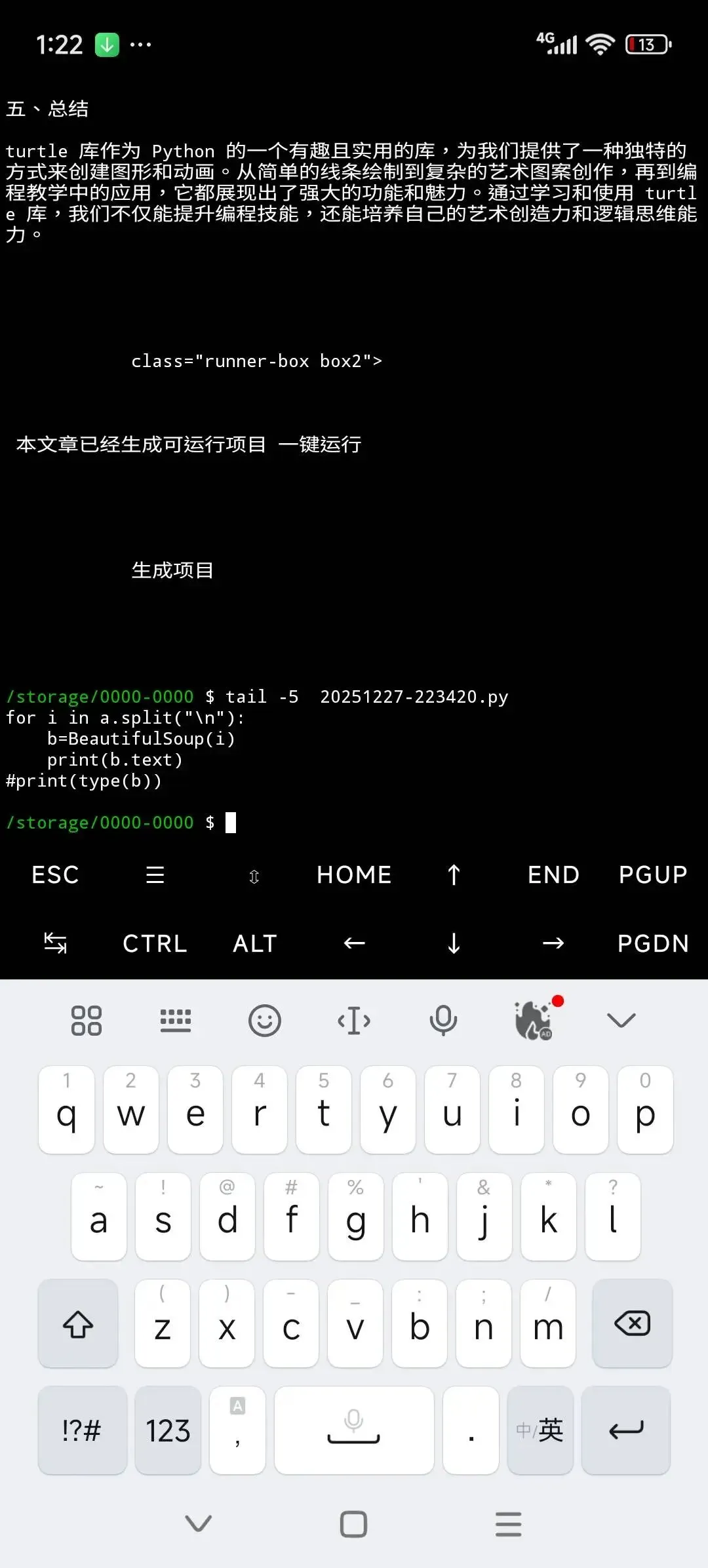
text用法2
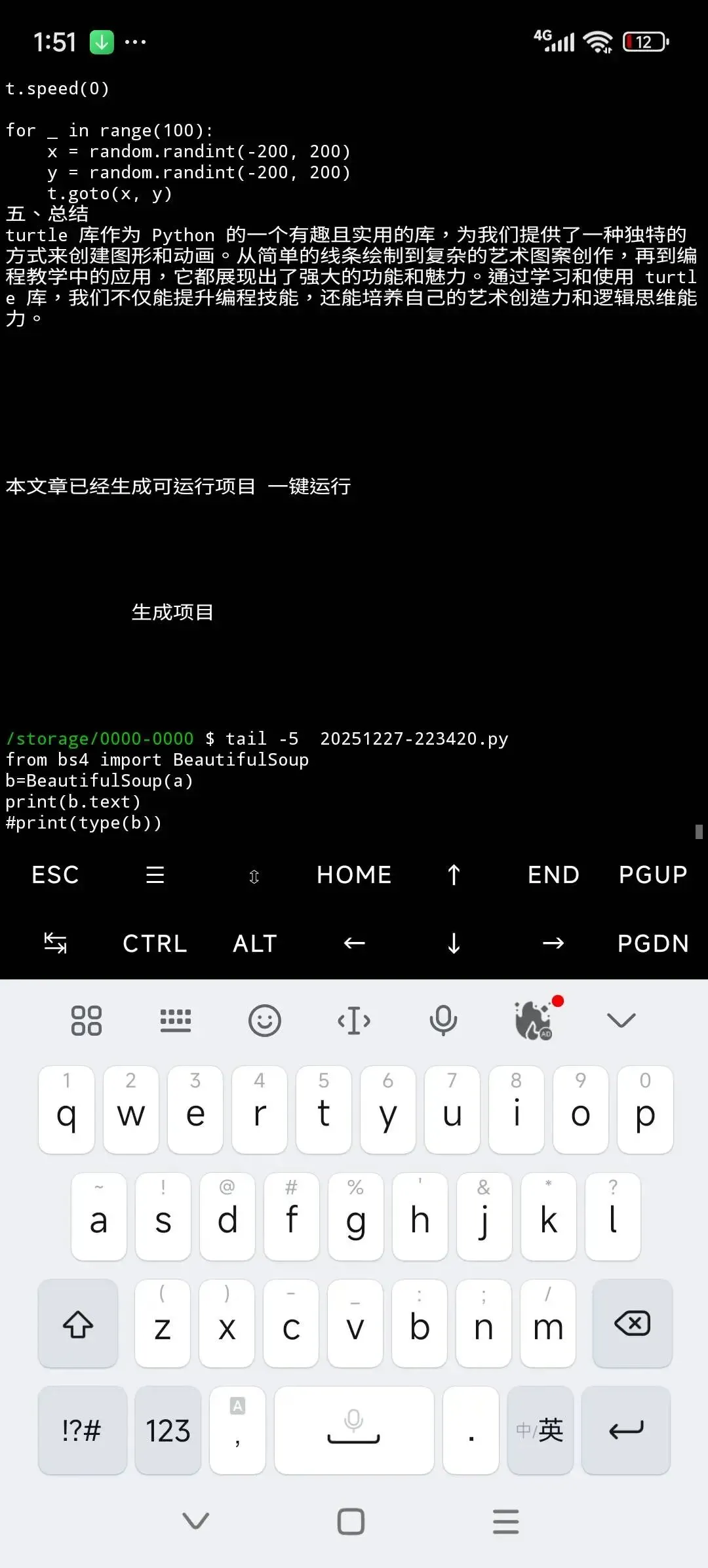
get_text用法
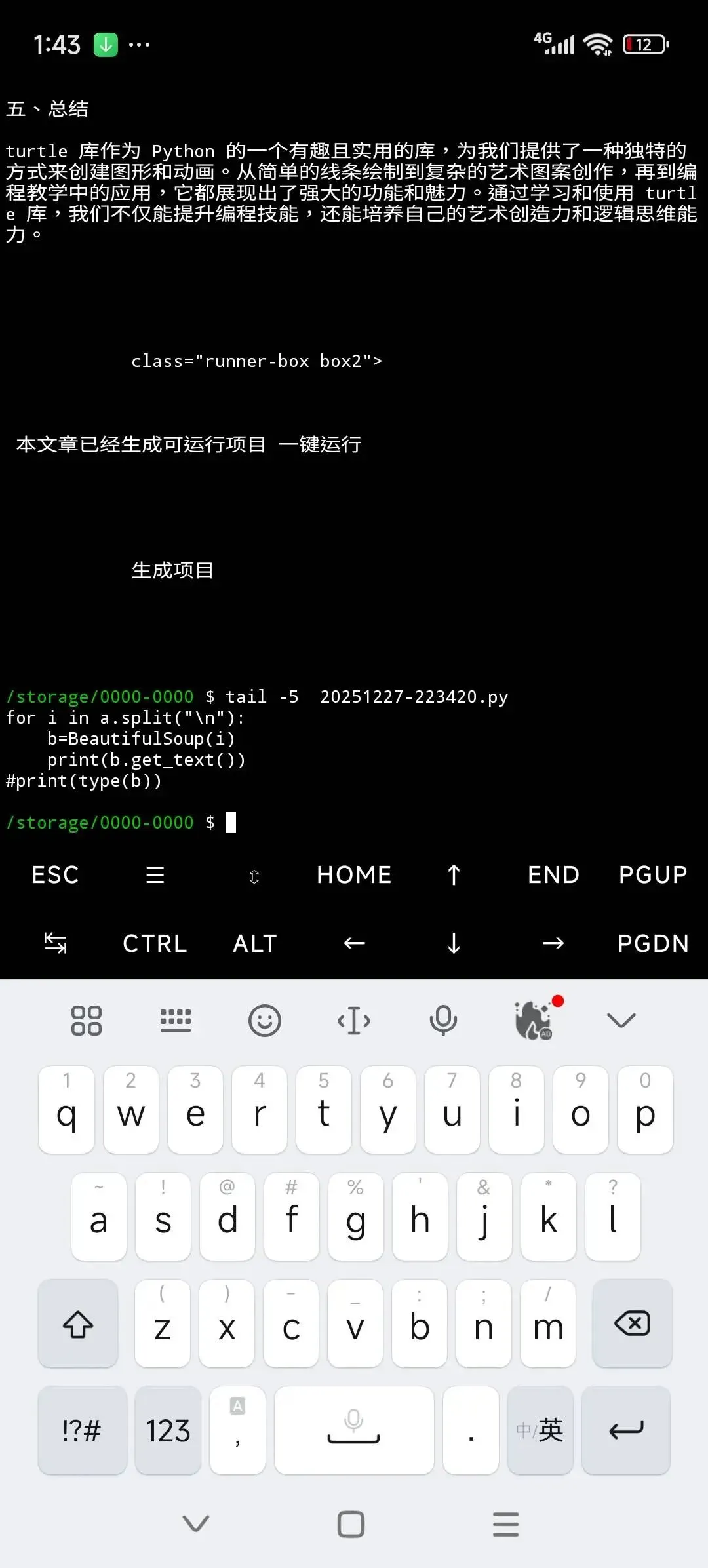
get_text用法2。
註意strip參數。
以上就是bf4中我常用的凡個方法。和re比,bf4寫的代碼少,logic簡單
,不過分支多,全面掌握要多下工夫。
bs4寫的少,不代表寫的容易。
各位大佬在用的時候要多加分辯,避免因拼寫不正確,參數不完整,而犯低級錯誤,有漏網之魚。

