多线程编程中,你以为加了锁就安全了吗?
- 2026-06-24 12:53:39
在多核CPU时代,开发者常面临一个反直觉的现象:正确使用了锁机制,但性能却不升反降。这背后的元凶往往不是锁本身,而是隐藏在硬件层面的缓存一致性问题和伪共享效应。本文将深入剖析CPU缓存一致性原理、伪共享问题的形成机制,以及通过Padding对齐技术解决性能瓶颈的实战方法,并通过真实案例展示性能下降10倍以上的现象及其根源。
如果你的目标是把技术水平拉起来,也想在简历上增加一些真正能说得出口的内容,可以趁这段时间做几个C++ 实战项目。既能把底层功底练扎实,也能让春招、考研复试、社招面试里遇到的技术问题更从容,有需要的朋友可以移步文末查看训练营相关介绍。
一、CPU缓存一致性原理剖析
1.1 缓存一致性的核心挑战
现代多核处理器系统中,每个CPU核心通常配备独立的L1缓存(数据缓存D-Cache和指令缓存I-Cache),部分共享L2或L3缓存,最后通过共享内存控制器访问主存。这种设计虽然提升了访问局部性,但也引入了缓存一致性问题:当多个核心缓存同一物理地址的数据时,若其中一个核心修改其本地副本,其他核心持有的副本将不再准确。
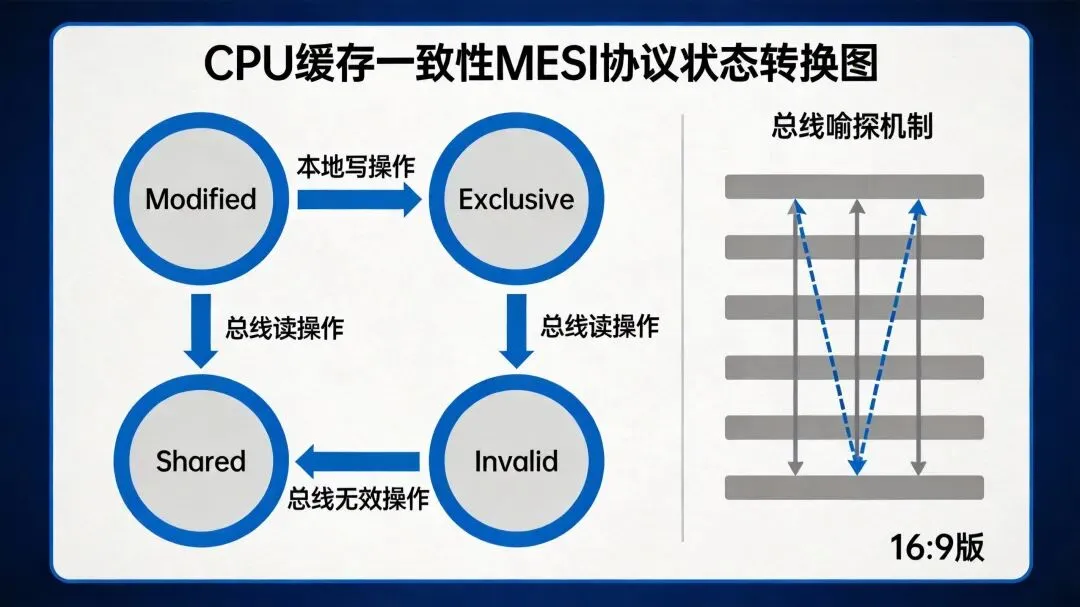
1.2 MESI协议详解
MESI协议(Modified-Exclusive-Shared-Invalid)是目前最经典的基于总线嗅探(Snooping)的缓存一致性协议。其名称来源于缓存行的四种状态:
四种状态定义
| M | ||||
| E | ||||
| S | ||||
| I |
MESI协议的核心机制
总线嗅探(Bus Snooping)是MESI协议的核心工作机制。每个CPU的缓存控制器不仅响应自身核心的请求,还会持续监听系统总线上其他缓存发出的操作通知。一旦监听到相关事件,缓存控制器就会根据规则更新自身对应缓存行的状态。
关键消息类型:
Read:需要读取数据的CPU发出,包含目标内存地址 Read Response:对Read消息的回复,提供所请求的数据 Invalidate:准备修改数据的CPU发出,使其他缓存中的所有副本失效 Invalidate Acknowledge:对Invalidate消息的确认 Read Invalidate:Read和Invalidate的组合消息,一次原子性事务 Writeback:将处于M状态的脏数据写回内存
1.3 MESI协议在多线程环境下的影响
在多线程程序中,当多个线程同时访问共享数据时,MESI协议会产生显著的性能开销:
缓存行无效化(Invalidation):当一个核心对共享数据执行写操作时,必须广播Invalidate消息,迫使其他核心将对应缓存行标记为Invalid。这个过程需要等待所有其他核心的确认,增加了延迟。
缓存行状态切换:频繁的读写操作会导致缓存行在不同状态间频繁切换,触发大量的总线事务,消耗带宽。
总线风暴(Bus Storm):在高并发场景下,大量的Invalidate消息和确认响应会占用总线带宽,导致系统整体性能下降。
二、伪共享问题深度解析
2.1 伪共享的形成原因
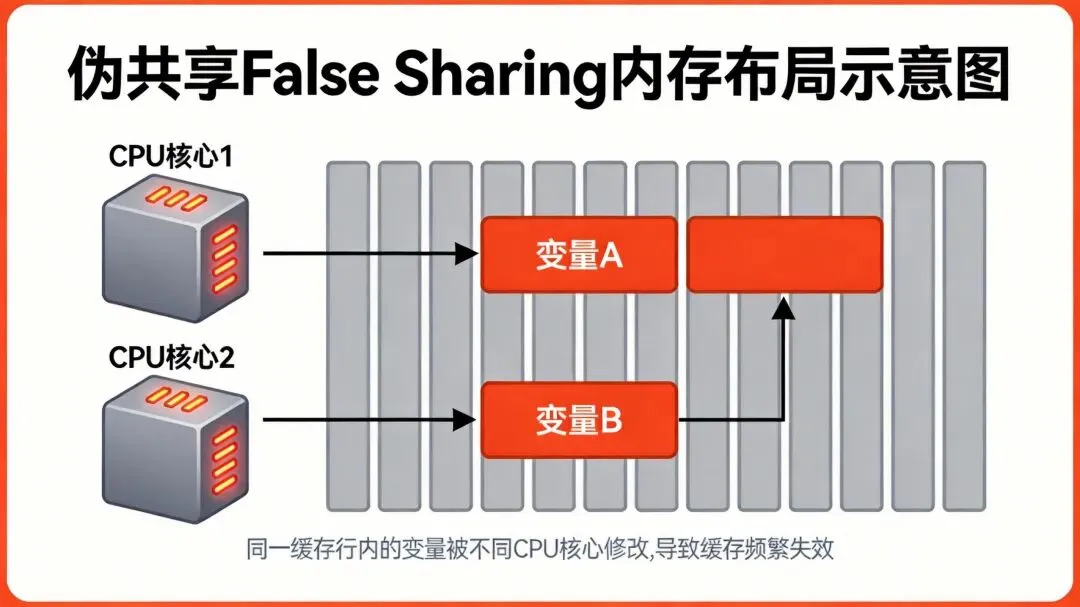
伪共享(False Sharing)是一种会导致性能下降的使用模式,最常见于现代多处理器CPU缓存中。当不同线程频繁修改同一缓存行(Cache Line)中的独立变量时,由于CPU缓存一致性协议(如MESI)会强制同步整个缓存行,导致线程间无实际数据竞争的逻辑变量被迫触发缓存行无效化,引发频繁的内存访问和性能下降。
缓存行(Cache Line)是CPU缓存管理的最小单位,通常为64字节。这意味着当CPU访问某个内存地址时,会自动加载该地址所在的整个64字节缓存行到缓存中。
2.2 伪共享对性能的隐蔽影响
典型场景示例
structCounter {volatileint a; // 被Core 0频繁修改volatileint b; // 被Core 1频繁修改}; // a 和 b 可能位于同一缓存行在这个例子中,变量a和b在逻辑上完全独立,但由于它们在内存中连续存放,很可能位于同一个64字节的缓存行中。当Core 0频繁修改a时,会触发以下连锁反应:
Core 0获取缓存行的Exclusive权限,修改后标记为Modified状态 Core 1尝试读取 b,发现缓存行已失效Core 1必须从主存重新加载整个缓存行,并等待Core 0写回数据 两个核心实际上互相阻塞,即使它们操作的是完全不同的变量
内存布局图
性能影响数据:
在实际测试中,伪共享问题导致的性能下降非常显著:
未优化场景:4个线程操作同一缓存行中的不同计数器,耗时约3709ms 优化后场景:通过填充使各计数器位于不同缓存行,耗时降至473ms 性能提升:约7.8倍
2.3 伪共享的典型场景
高并发计数器数组:多个线程更新各自独立的计数器元素,但相邻元素落在同一缓存行 并发队列元数据:头尾指针未对齐填充,频繁更新引发刷新风暴 环形缓冲区(Ring Buffer):生产者与消费者指针靠近,易落入同一缓存行 锁分离结构:多个细粒度锁紧邻存储 线程本地统计信息聚合:全局统计数组未隔离,造成跨核污染 ArrayBlockingQueue: takeIndex、putIndex、count三个变量很容易放到一个缓存行中
三、Padding对齐优化技术
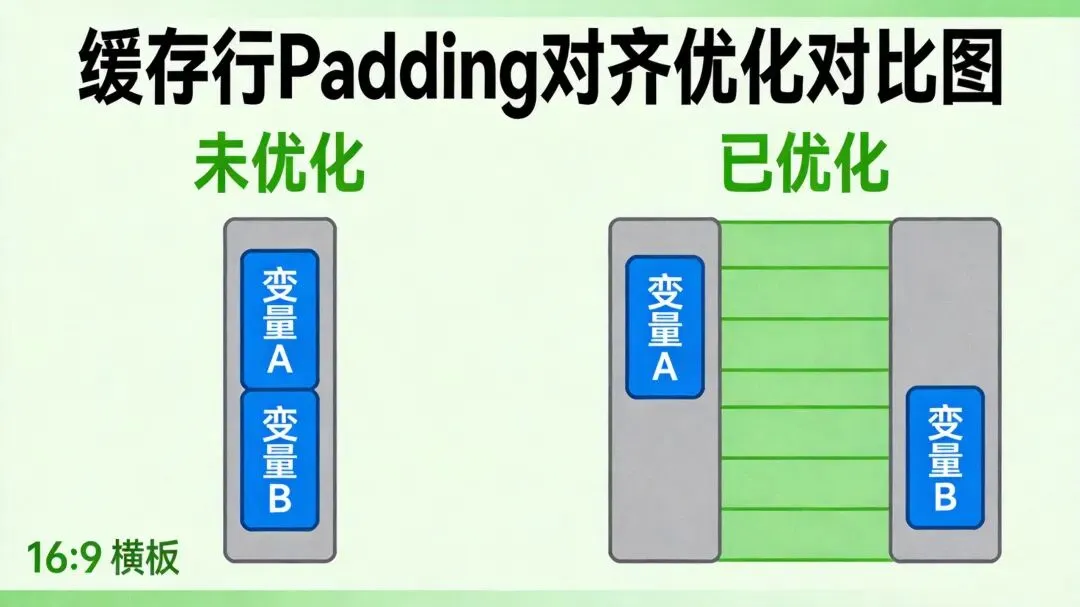
3.1 Padding对齐的原理
Padding对齐的核心思想是确保热点变量独占缓存行,通过在变量前后插入填充字节,使多个变量在内存布局上保持足够的距离,避免它们共享同一个缓存行。
技术实现:
在C++中,可以使用多种方法实现Padding对齐:
方法1:手动填充(Manual Padding)
structPaddedCounter {volatileint64_t value;char padding[64 - sizeof(int64_t)]; // 填充至64字节};方法2:使用alignas关键字(C++11起)
#include<atomic>struct alignas(64) AlignedCounter {std::atomic<int64_t> value;}; // 强制整个结构体按64字节对齐方法3:使用C++17的std::hardware_destructive_interference_size
#include<new>struct alignas(std::hardware_destructive_interference_size) Counter {std::atomic<int> value;};3.2 Padding对齐的效果验证
通过实际测试可以验证Padding对齐的显著效果:
测试场景: 4个线程分别对4个独立计数器执行1亿次自增操作
| 7.8倍 | ||
| 19倍 | ||
| 16.9倍 |
3.3 Padding对齐的注意事项
内存开销:Padding对齐会增加内存占用,需要权衡性能与资源 缓存行大小差异:不同CPU的缓存行大小可能不同(通常是64字节,但也可能是128字节),需要根据实际平台调整 编译器优化:某些编译器可能会优化掉看似无用的填充字节,需要确保填充字段被实际保留
四、反直觉性能案例分析
4.1 真实案例:全局锁与伪共享的双重打击
案例背景:
某游戏服务器开发团队实现了一个高并发内存池,使用全局互斥锁(std::mutex)保护内存分配和释放操作。团队预期随着线程数增加,性能应该线性提升,但实际测试结果显示:**线程数从1增加到4,吞吐量反而下降了40%**。
测试环境:
CPU:Intel i7-9700K(8核16线程,Windows 10) 线程数:4 每线程操作次数:10000次分配和释放 内存块大小:1024字节
性能数据:
4.2 根因分析
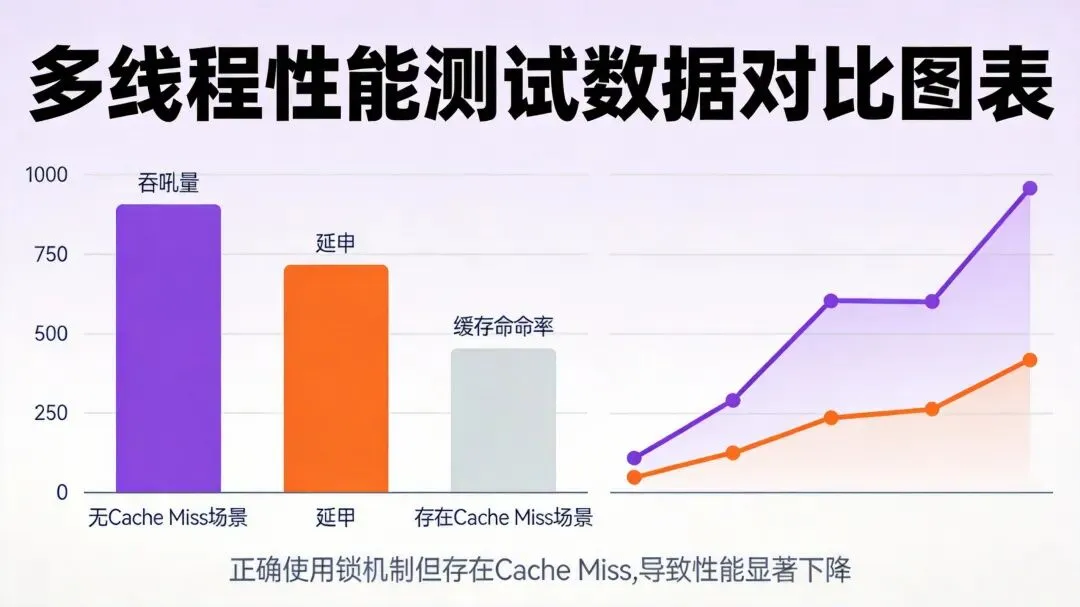
经过深入的性能分析,团队发现了两个主要的性能瓶颈:
锁竞争开销:全局锁的单点瓶颈导致所有线程串行化执行,锁竞争消耗了约70%的CPU时间(线程数为4时)
伪共享问题:内存池管理结构中的多个热点字段(如
free_count、used_count、mutex对象等)位于同一个缓存行中,不同线程频繁修改这些字段时,导致大量的缓存行无效化
具体表现:
L1 Cache Miss率从单线程的5%飙升至8线程的48% 总线流量从单线程的1.2GB/s增加至8线程的9.7GB/s 上下文切换频率显著增加
4.3 优化方案与效果
团队采用了分层优化策略:
优化1:分桶锁设计
将内存池划分为16个独立桶,每个桶使用单独的锁:
constint NUM_SHARDS = 16;std::array<std::mutex, NUM_SHARDS> shard_mutexes;std::array<std::atomic<int>, NUM_SHARDS> shard_counters;intget_shard(int key){ return key % NUM_SHARDS; }voidsafe_increment(int key){auto idx = get_shard(key);std::lock_guard<std::mutex> lock(shard_mutexes[idx]); shard_counters[idx]++;}效果: 锁竞争概率从100%降至约6.25%,吞吐量提升至约1,300,000 ops/sec
优化2:缓存行对齐
对热点数据结构应用Padding对齐:
struct alignas(64) PaddedCounter {std::atomic<int> free_count;char padding1[64 - sizeof(std::atomic<int>)];std::atomic<int> used_count;char padding2[64 - sizeof(std::atomic<int>)];};效果: L3 Cache Miss率从32%降至18%,总线流量从6.1GB/s降至3.4GB/s
综合优化效果
| 3.9倍 |
4.4 另一个真实案例:Java ConcurrentHashMap的性能陷阱
JDK 8的ConcurrentHashMap在并发线程数超过16时,性能反而开始下降。测试数据显示:
根本原因:
锁竞争加剧:多个线程访问同一桶的锁 CAS失败重试频繁 扩容操作频繁触发 CPU缓存失效(Cache Line Miss):Node数组紧密排列导致伪共享 伪共享问题:不同线程操作位于同一缓存行的不同变量
五、最佳实践与优化建议
5.1 识别伪共享问题的方法
性能分析工具:
Linux Perf:使用 perf c2c命令检测缓存行竞争Intel VTune:专业的性能分析工具,可检测伪共享 Valgrind Cachegrind:模拟缓存行为,识别潜在问题
典型症状:
多线程程序性能随核心数增加而下降 线程间无数据依赖但性能异常 缓存命中率低,缓存一致性流量高 高L1/L2 Cache Miss率
5.2 避免伪共享的策略
缓存行对齐:使用
alignas(64)确保热点变量独占缓存行线程本地存储(TLS):使用
thread_local减少跨核竞争数据结构优化:拆分数组/对象,将高频访问的变量分散到不同缓存行
使用高性能容器:如
LongAdder、ConcurrentHashMap,内部已优化缓存行问题架构设计层面:
采用线程本地副本,最后合并结果 在数组设计中引入stride跳跃 利用NUMA感知分配 在Ring Buffer中将生产者/消费者指针置于不同内存页
5.3 锁优化策略
减少锁粒度:从粗粒度锁到细粒度锁 分段锁设计:如ConcurrentHashMap的分段锁 无锁编程:使用原子操作或CAS实现无锁数据结构 读写分离:使用读写锁( std::shared_mutex)
现在很多同学都在参加校招 / 准备社招跳槽,我们上线了 👉C++ 项目实战营,除了系统梳理 C++ 基础与进阶知识,你还可以从项目池中任选C++ 实战项目,从 0 到 1 动手做轮子!导师1v1亲自 review 代码 + 专业辅导答疑

常规的刷题/学习,只能提高代码能力,但面试时,企业更看重你从 0 到 1 做项目、解决实际问题的能力!
而我们的训练营,正是为了这个目标设计的:
项目全流程实战:开发环境、编译脚本、架构设计、框架搭建、代码发布、问题调试、单元测试。 锻炼从需求分析到任务拆解、版本管理的全流程能力 提高你调试能力、定位问题的技巧,掌握更多真实工作中的技能 项目资料齐全:源码 + 注释 + 视频 + 文档一应俱全 导师1v1在线答疑,实打实帮你把项目做好!
感兴趣的同学欢迎后台回复关键词:训练营查看训练营介绍或直接添加vx(chuzi345),快速了解训练营详情!
相信我,这些项目绝对能够让你进步巨大!下面是其中几个项目的说明文档
训练营适用人群:
备战春招和秋招的应届生,科班非科班均可, 工作 3 年以内,想跳槽的社招同学 如果你有以下困扰,欢迎联系我们,我们愿意为你提供帮助和支持 不知道该复习哪些内容,如何开始复习。 对面试考察重点不清楚,复习效率低下。 缺乏有含金量的实战项目经验。 想要提升自己的实战能力,提升做项目及解决问题的能力 对算法题无从下手,缺乏解题思路和常见解题模板。 自控力不足,难以专注于系统复习。 希望获得大厂的内推机会。 独自备战校招社招感到孤单,想要找到学习伙伴。
不适合人群:
缺乏耐心和毅力,急于求成的人 对编程逻辑思维基础薄弱,且不愿努力提升的人 只想快速获得成果而不注重基础学习的人

