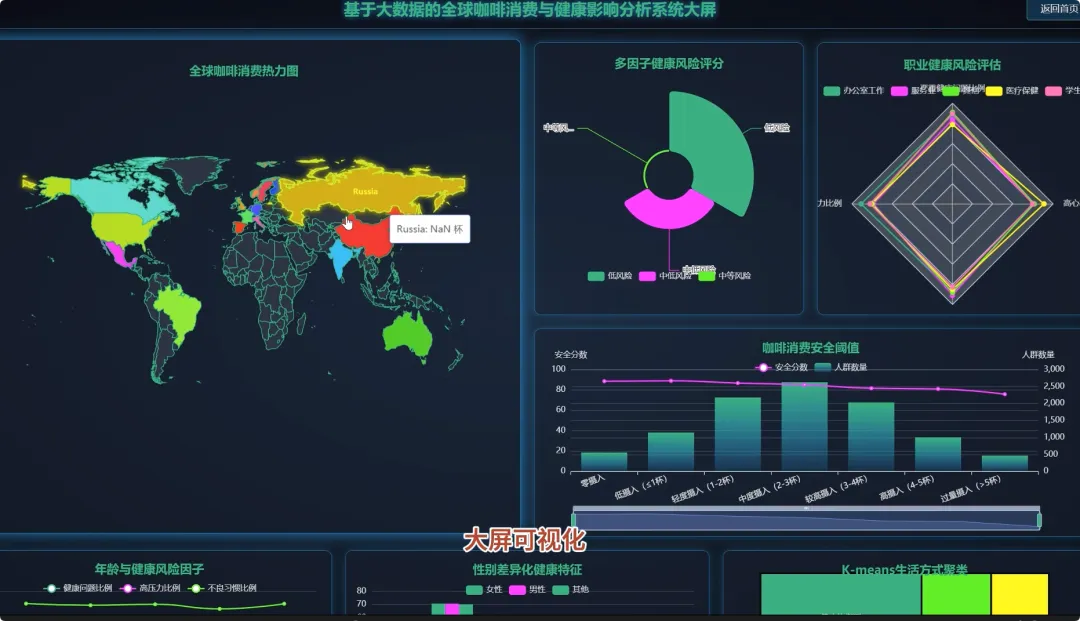
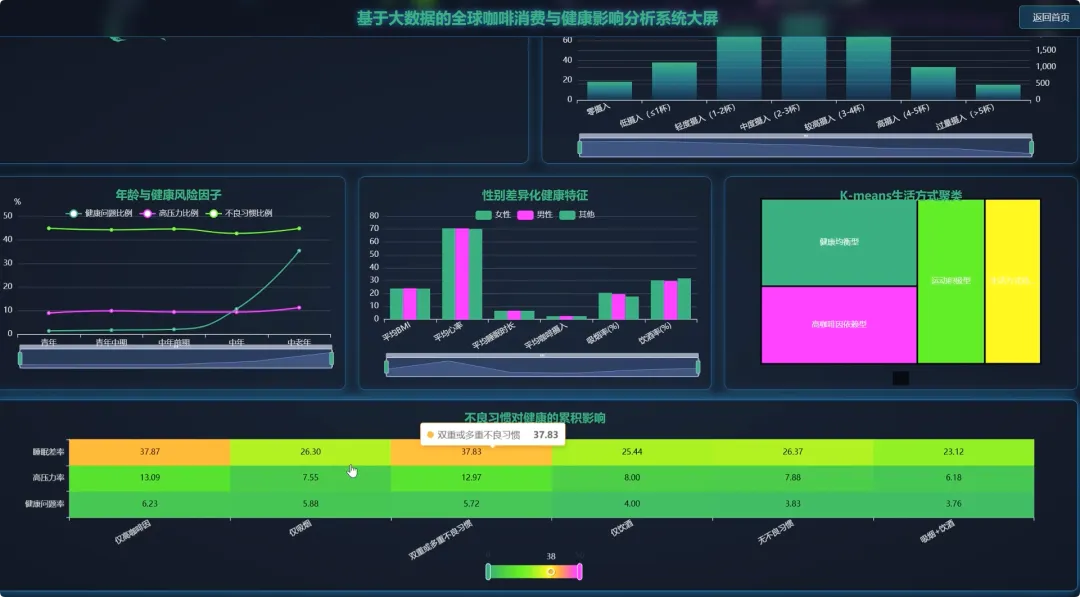
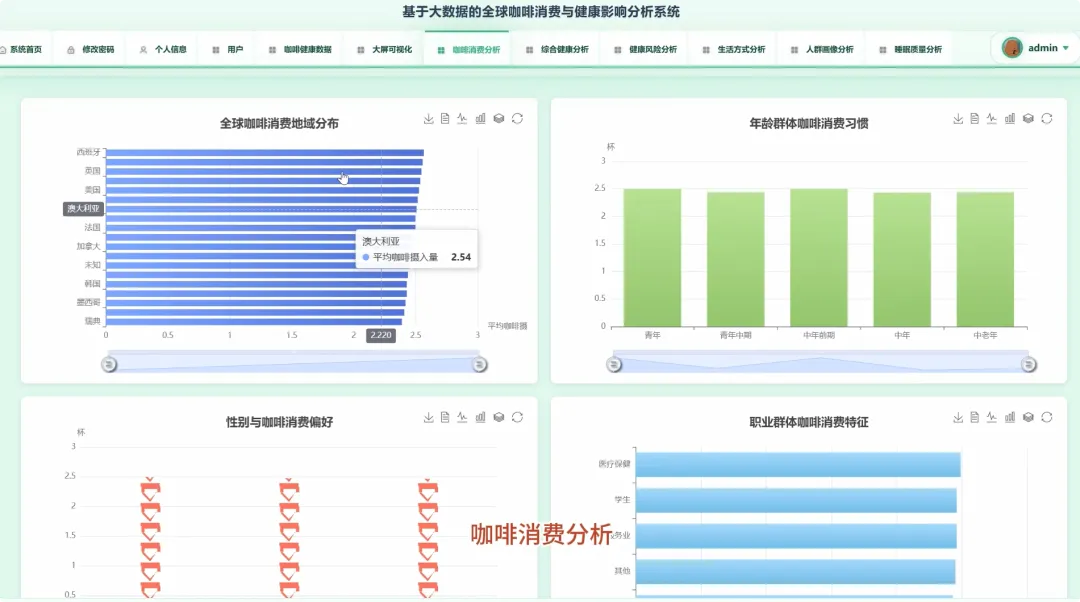
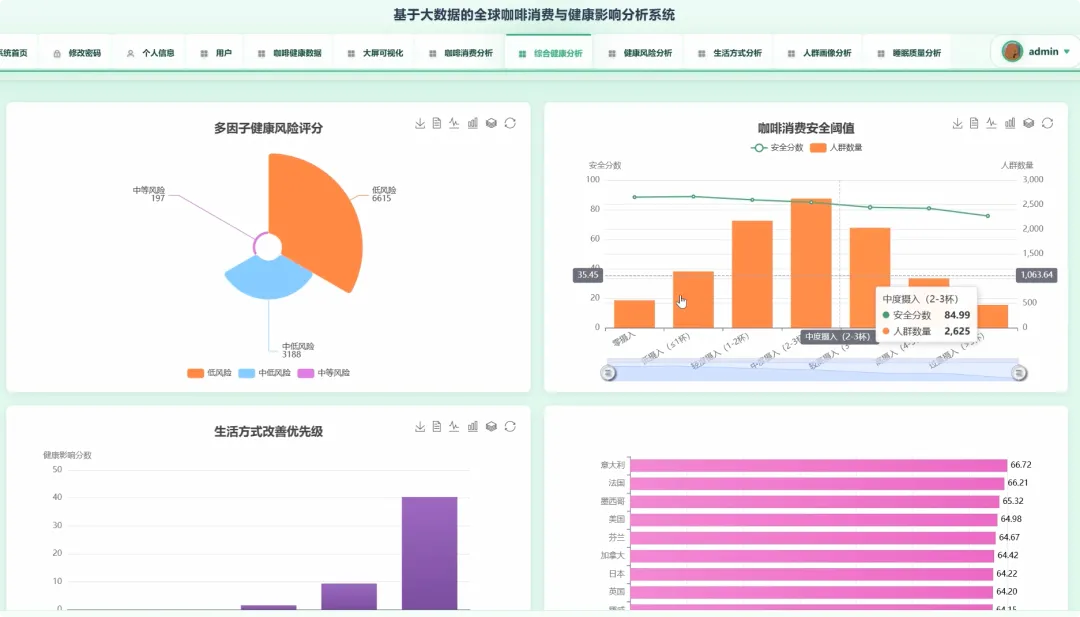
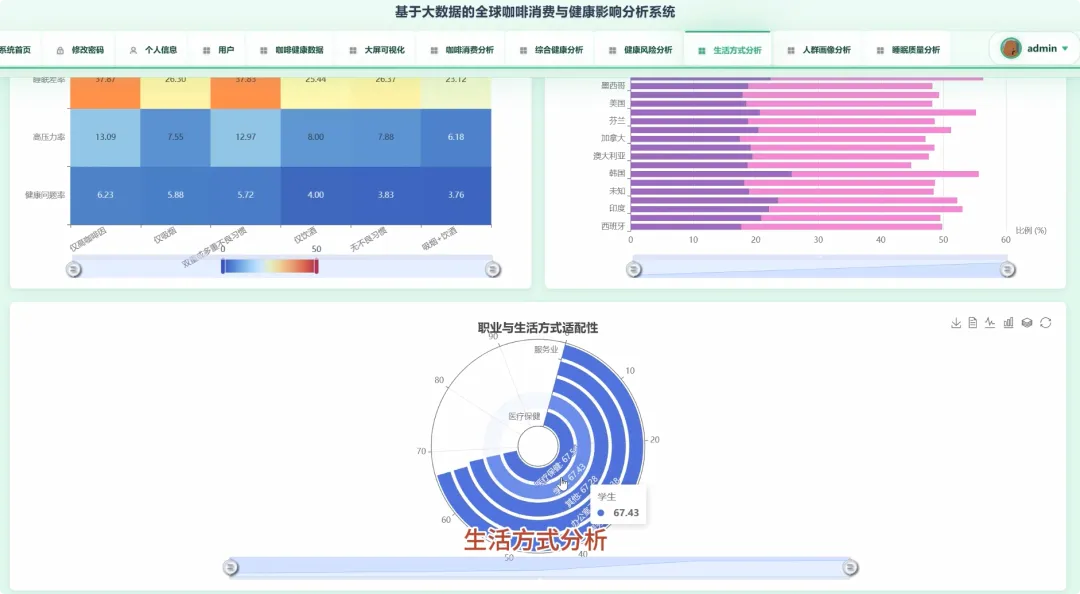
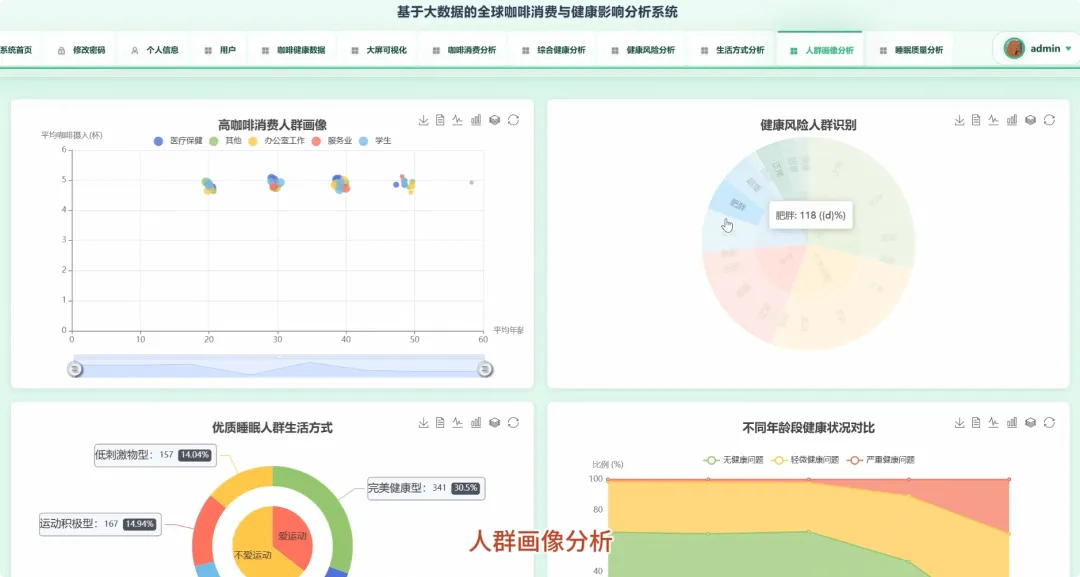
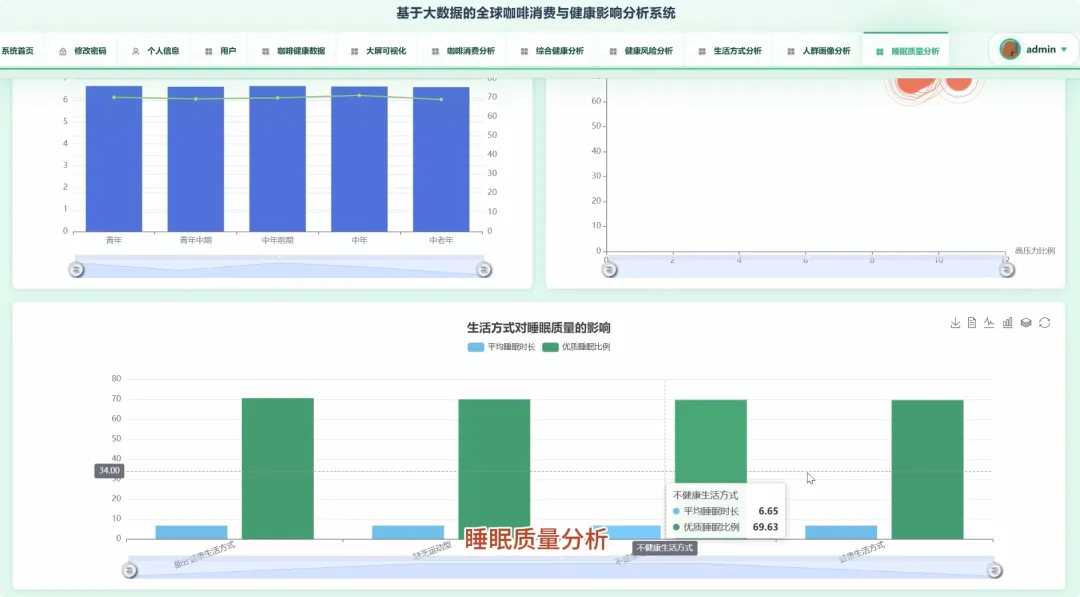
from pyspark.sql import SparkSessionfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.clustering import KMeansdef analyze_caffeine_sleep_impact(spark, df): df.createOrReplaceTempView("health_data") result_df = spark.sql(""" SELECT CASE WHEN Caffeine_mg < 50 THEN '低咖啡因摄入(<50mg)' WHEN Caffeine_mg BETWEEN 50 AND 150 THEN '中咖啡因摄入(50-150mg)' WHEN Caffeine_mg > 150 THEN '高咖啡因摄入(>150mg)' END AS caffeine_level, COUNT(*) AS user_count, AVG(Sleep_Hours) AS avg_sleep_hours, AVG(Sleep_Quality) AS avg_sleep_quality FROM health_data WHERE Caffeine_mg IS NOT NULL AND Sleep_Hours IS NOT NULL AND Sleep_Quality IS NOT NULL GROUP BY caffeine_level ORDER BY avg_sleep_hours DESC """) result_df.show()def lifestyle_clustering_analysis(spark, df): feature_cols = ["Coffee_Intake", "Physical_Activity_Hours", "Sleep_Hours", "Caffeine_mg"] assembler = VectorAssembler(inputCols=feature_cols, outputCol="features") feature_data = assembler.transform(df.na.drop(subset=feature_cols)) kmeans = KMeans(k=4, seed=1, featuresCol="features", predictionCol="cluster") model = kmeans.fit(feature_data) clustered_data = model.transform(feature_data) cluster_centers = model.clusterCenters() print("聚类中心点坐标:") for i, center in enumerate(cluster_centers): print(f"Cluster {i}: {center}") clustered_data.select("Age", "Gender", "Occupation", "cluster").show(20)def high_coffee_consumer_profile(spark, df): high_coffee_threshold = 4.0 high_coffee_df = df.filter(df.Coffee_Intake > high_coffee_threshold) high_coffee_df.createOrReplaceTempView("high_coffee_users") profile_df = spark.sql(""" SELECT COUNT(*) AS total_users, AVG(Age) AS avg_age, COUNT(CASE WHEN Gender = 'Male' THEN 1 END) / COUNT(*) AS male_ratio, COUNT(CASE WHEN Gender = 'Female' THEN 1 END) / COUNT(*) AS female_ratio, AVG(BMI) AS avg_bmi, AVG(Stress_Level) AS avg_stress_level, AVG(Sleep_Quality) AS avg_sleep_quality FROM high_coffee_users WHERE Age IS NOT NULL AND Gender IS NOT NULL AND BMI IS NOT NULL """) profile_df.show() occupation_dist = high_coffee_df.groupBy("Occupation").count().orderBy("count", ascending=False) occupation_dist.show(10)