构建嵌入式 Linux 系统的第一步是进行系统架构设计。除非你要搭建的系统非常简单,或者你拥有丰富的经验,否则这一步难度不小。因此,你可能会先购买一些参考硬件,测试其能否满足你的需求(包括硬件和软件层面),然后以此为基础进行自己的设计开发。
需要注意的是,许多设计师在进行系统架构设计时,过于注重参考平台的硬件外设选择,而没有在早期阶段投入足够时间考虑软件因素。例如,一款 500 MHz 的 Cortex-A5 处理器虽然支持并行摄像头传感器接口,但这并不意味着你能在其上以 30 fps 的帧率运行自定义的 SegNet 图像前向传播算法;本文中提到的许多带有双以太网 MAC 控制器的器件,即便运行一个简单的 Web 应用也可能力不从心。
确定软件框架的系统需求往往并不直观。比如,在 Qt 5 中开发一款支持多点触控的涂鸦应用,其资源占用量实际上远低于运行一个基于现代技术栈、采用即时编译(JIT)语言编写的简单 Web 应用后端服务器。许多熟悉传统 Linux 服务器/桌面开发的开发者会想当然地认为,只需将 .NET Core Web 应用放到根文件系统(rootfs)中即可万事大吉,结果却发现系统内存完全耗尽、应用启动时间超过 5 分钟,或者发现 Node.js 根本无法在他们所依赖的 ARM9 处理器上编译。
我的最佳建议是:尽量在目标硬件上运行你打算使用的软件,并尽可能全面地测试其性能。以下是一些入门指南:
- • 低速 ARM9 内核:适用于采用 C/C++ 编写的简单无界面(headless)设备。你可以在这类处理器上运行基本的、无动画的低分辨率触控 linuxfb 应用,但混合渲染及其他高级 2D 图形技术会显著拖慢系统运行速度。虽然也能运行非常简单的 Python 脚本,但根据我的测试,在一款 300 MHz 的 ARM9 处理器上,即便是一个“Hello, World!”级别的 Flask 应用,从启动到成功向浏览器返回网页也需要 38 秒。显然,Python 文件编译后运行速度会大幅提升,但应尽可能使用轻量级 HTTP 服务器提供静态内容。此外,Node.js 和 .NET Core 均无法在这类架构上编译。这类处理器通常从大容量 SPI 闪存芯片启动,这也限制了可选择的软件框架范围。
- • 中端 500-1000 MHz Cortex-A 系列:能更好地支持解释型/即时编译型语言,但需确保配备充足的内存——128 MB 是最低配置要求。这类系统可以流畅运行直接基于帧缓冲(framebuffer)的简单 C/C++ 触控图形用户界面(GUI),但如果需要进行大量 SVG 渲染、缩放(pinch/zoom)手势操作及其他画布(canvas)相关处理,可能会出现性能瓶颈。
- • 多核 1 GHz 以上 Cortex-A 系列(256 MB 及以上内存):开始支持类桌面/服务器级别的部署。借助大容量 eMMC 存储(4 GB 及以上)、良好的 2D 图形加速(部分型号支持 3D 加速),你可以使用原生 C/C++ 编程开发复杂的交互式触控屏应用;如果应用足够简单且内存充足,也可以采用基于 HTML/JS/CSS 的渲染引擎。如果要构建联网设备,若你更倾向于使用 Node.js、.NET Core 或 Python 而非 C/C++,开发核心功能基本不会遇到障碍。
树莓派(Raspberry Pi)的适用性
我知道很多人——尤其是爱好者,甚至包括专业工程师——看到这里可能会想:“我一直用树莓派开发板进行嵌入式 Linux 开发,为什么还要读这篇文章?” 表面上看,树莓派单板计算机与本文提到的一些器件有相似之处:它们都能运行 Linux、连接显示器、支持网络功能,并且提供 USB、GPIO、I2C 和 SPI 接口。
客观来讲,树莓派 4 上搭载的 BCM2711 处理器性能十分强劲,单论处理器性能,轻松超越本文评测的所有器件。但深入分析会发现:该处理器具备视频解码和图形加速功能,却没有任何 ADC(模数转换)输入接口;内置 HDMI 发射器,可驱动双 4K 显示器,但仅提供两个 PWM(脉冲宽度调制)通道。这款处理器是专为智能电视和机顶盒量身定制的,并非通用型嵌入式 Linux 应用处理器,因此通常并不适合嵌入式 Linux 开发工作。
它可能适用于你的某个特定项目,但大概率并非最优选择;在设计初期强行使用树莓派会过度限制系统设计的灵活性。诚然,对于上述短板,总有一些变通方案——比如使用 I2C 接口的 PWM 芯片、SPI 接口的 ADC,或带 HDMI 接收器的 LCD 模块——但这些方案需要额外的硬件支持,会增加系统功耗、体积和成本。如果你只是制作一个原型样品,且不关心这些因素,那么树莓派可能是一个不错的选择;但如果是为量产产品进行原型开发,建议在做出最终决定前全面考察各类器件。
外设相关说明
本文的核心是介绍如何让嵌入式应用处理器启动 Linux 系统,而非构建完整的嵌入式系统。如果你的嵌入式设计计划集成蓝牙、WiFi、以太网、TFT 触控屏、音频、摄像头或低功耗射频收发器等功能,那么你需要额外关注这些外设的相关技术。
如果你来自微控制器(MCU)领域,在这些方面需要补充大量知识,因为嵌入式 Linux 系统中的接口(甚至架构设计思路)与 MCU 有很大差异。例如,虽然单芯片 WiFi/BT(蓝牙)微控制器很常见,但极少有应用处理器集成 WiFi/BT 功能,因此通常需要使用外部 SDIO 或 USB 接口的芯片组;SPI 接口的 ILI9341 TFT 显示屏通常会被并行 RGB 或 MIPI 接口的型号替代;而不再是使用 MCU 的 12 位 DAC 输出音频信号,而是需要将 I2S 音频编解码器与处理器连接。

硬件开发流程
处理器厂商非常鼓励客户在参考设计的基础上进行修改和复用。我认为大多数专业工程师最关心的是让第一版(Rev A)硬件能够成功启动,而非急于进行优化,因此我看到很多定制化 Linux 开发板都是直接借鉴现成的评估套件(EVK)设计而成。
但根据项目复杂度不同,这种做法可能会变得非常不合理。如果你的项目需要评估套件配备的大容量内存,且设计中使用的并行显示接口、摄像头接口、音频编解码器和网络接口等与评估套件一致,那么以评估套件为基础进行少量修改是合理的。然而,如果你的项目只是一个简单的物联网网关,却因为参考设计使用了 10 层 PCB 堆叠,就盲目照搬,这绝不能体现出设计的创新性。
人们往往忽略了一个事实:评估套件的生产批量远大于原型硬件。我经常需要向缺乏经验的项目经理解释,为什么一款批量采购价仅为 56 美元的评估套件,制作 5 个原型板却需要花费近 4000 美元。
你可能会发现,花费额外时间优化设计、简化 PCB 堆叠、减少物料清单(BOM)成本,或者完全从零开始设计,是更值得的选择。本文评测中使用的所有开发板,我仅用几天时间就完成了设计,并且通过低成本的加热板、热风枪或电烙铁,在几小时内就能完成手工焊接(PCB 采用嘉立创(JLC)的廉价 4 层板)。只要设计中没有大量冗余电路,即便包含焊接人工成本,一轮原型制作的费用也很难超过几百美元。
如果你只是打算复制参考设计文件,那么一些细节问题可能并不重要。但如果要基于这些器件从零开始设计开发板,你会发现与微控制器设计有很大差异。

德州仪器(TI)AM335x(左图)采用的是全阵列排布的 0.8mm 间距焊球;瑞芯微(Rockchip)RK3308(右图)则采用 0.65mm 间距焊球,且对焊球阵列进行了选择性去球处理
BGA 封装
本文评测的大多数器件采用球栅阵列(BGA)封装,因此有必要简要说明相关设计要点。BGA 封装让经验不足的工程师在布局和原型焊接阶段感到紧张。不出所料,一些经验丰富的工程师会刻意设置门槛,劝阻经验不足的同行使用 BGA 器件,但实际上,我认为 BGA 封装比高引脚数超细间距四方扁平封装(QFP)更容易设计——而 QFP 通常是 BGA 之外的唯一选择。
本文评测中主流的 0.8mm 引脚间距 BGA,其间距足够宽松,允许在两个相邻焊球之间布一条走线,并且可以在 4 个焊球组成的网格中心放置过孔,相邻过孔之间的空间也足以容纳一条走线。如左图所示:蓝色(底层)最内侧的信号通过蓝色层最外侧信号的逃逸过孔之间的间隙,实现从 BGA 封装的引出。
通常,采用这种策略可以引出 0.8mm 间距 BGA 的 4 排信号:BGA 的前两排信号可从元件面引出,后两排信号则需从第二层引出。如果需要引出更多排信号,则需要增加 PCB 层数。集成电路(IC)设计师非常清楚这一点:如果一款 IC 是为 4 层板(两层信号层、两层电源层)设计的,那么只有最外层的 4 排焊球会用于 I/O 信号传输。如果需要引出更多信号,他们会选择性地去掉封装外侧的部分焊球——去掉一个焊球可以腾出容纳 3-4 个信号的空间。
对于 0.65mm 间距 BGA(右图),虽然仍能(勉强)在 4 个焊球之间放置过孔,但相邻过孔之间的空间不足以让信号走线通过——间距实在太小。这就是为什么几乎所有 0.65mm 间距 BGA 都必须在封装外侧进行选择性去球设计。右图中的信号逃逸策略显得杂乱无章——因为还存在其他约束条件(差分对、随机电源网络、信号最终目的地等),这些因素往往会影响逃逸方案的有序性。我认为 BGA 封装最大的不便之处在于:如果需要引出大量信号,去耦电容通常只能放在 PCB 底层;但如果增加 PCB 层数,也可以将去耦电容挤到顶层(许多焊盘式系统级模块(SOM)就是这样设计的)。
带有 BGA 器件的 PCB 手工焊接其实非常简单。由于 0.8mm 间距 BGA 的引脚间距较宽,放置精度要求不高,我焊接的开发板从未出现过短路问题。这与 0.4mm 间距(甚至 0.5mm 间距)的 QFP 封装形成鲜明对比——QFP 封装由于钢网对准精度问题,经常会出现轻微短路。我焊接 0.65mm 间距 BGA 也没有遇到过问题,但需要更加小心谨慎。
实际焊接时,如果你有电热炉(我推荐美膳雅(Cuisineart)的产品),可以采用加热板焊接 BGA 器件。我虽然有回流焊炉,但在本次评测中一次也没使用——而是先加热板加热 PCB 顶层,翻转后涂覆焊膏,在背面放置无源器件,然后用热风枪加热焊接。个人而言,我不会用热风枪焊接 BGA 或其他大型器件,但很多人经常这样做。加热板焊接的优点是,在回流焊过程中可以调整位置偏移的器件。如果 BGA 器件没有自动对齐,我也会轻轻敲击使其对齐。
多电压域
微控制器几乎普遍采用单一固定电压供电(内部可能会进行降压调节),而大多数微处理器至少需要三个外部稳压器提供的电压域:I/O 电压(通常为 3.3V)、内核电压(通常为 1.0-1.2V)和内存电压(根据内存技术而定——DDR3L 为 1.35V,传统 DDR3 为 1.5V,DDR2 为 1.8V,DDR 为 2.5V)。通常还会有额外的模拟电源域,一些高性能器件可能需要 6 个或更多不同的供电电压。
虽然许多入门级器件可以通过几个分立的低压差稳压器(LDO)或 DC/DC 转换器供电,但部分器件对电源时序有严格要求。此外,为了最大限度降低功耗,许多器件建议采用动态电压调节(DVS)技术——当 CPU 处于空闲状态并降低时钟频率时,自动降低内核电压。
这两个因素促使设计师采用 I2C 接口的电源管理集成电路(PMIC)——这类芯片专为特定处理器的电压和时序要求设计,输出电压可动态调整。这些芯片可能集成 4 个或更多 DC/DC 转换器,以及多个 LDO。许多 PMIC 还包含多个直流输入接口和内置锂离子电池充电功能。加上部分 PMIC 所需的大型电感、电容和多个精密电阻,这些额外电路会大幅增加物料清单(BOM)成本和 PCB 面积。
无论选择哪种稳压器,这些器件的功耗波动都很大,因此你需要具备基本的电源分配网络(PDN)设计能力,以确保在器件需要时能提供足够的电流。虽然仅需让系统启动无需进行任何仿真或验证,但如果设计存在边际问题,后续可能会出现电磁兼容性(EMC)问题——而这些问题在使用简单微控制器时通常不会出现。
非易失性存储
目前常用的微处理器均未内置闪存,因此需要为微处理器(MPU)连接存储设备,用于存储代码和持久化数据。如果你使用过那些未购买闪存知识产权(IP)的无晶圆厂公司的器件,可能已经习惯了焊接 SPI NOR 闪存芯片、烧录十六进制文件,然后即可投入使用。但在使用微处理器时,需要考虑更多存储相关的决策。
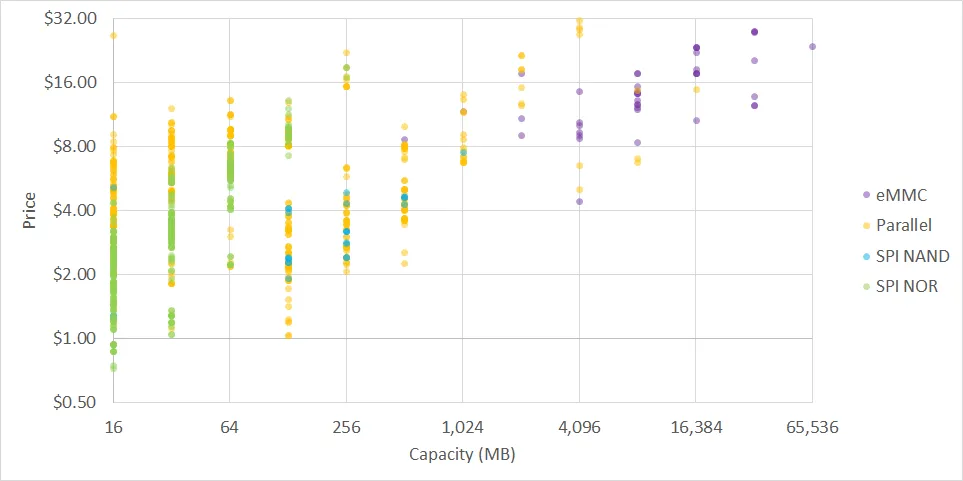
如图,得捷电子(Digi-Key)提供的容量从16MB到64GB的存储器报价,按存储技术类型进行颜色编码区分。
大多数微处理器支持从 SPI NOR 闪存、SPI NAND 闪存、并行闪存或 MMC(用于 eMMC 或 MicroSD 卡)启动。由于存储架构不同,NOR 闪存的读取速度比 NAND 闪存快,但写入速度更慢。SPI NOR 闪存广泛用于存储容量不超过 16 MB 的小型系统,超过该容量后,SPI NAND 闪存和并行接口的 NOR/NAND 闪存性价比更高。并行接口的 NOR 闪存曾经是嵌入式 Linux 设备的主流启动介质,但现在应用越来越少——尽管其价格有时仅为 SPI 闪存的一半。我认为其不受欢迎的唯一原因是,没有人愿意为并行内存浪费大量 I/O 引脚。
存储容量超过 1 GB 时,MMC 是目前的主流技术。对于开发工作,MicroSD 卡的优势尤为明显——小批量采购时,其每千兆字节成本通常低于其他存储介质,且无需通过 MPU 的 USB 引导程序即可轻松读写数据;这也是我在本文评测的几乎所有平台上都选择 MicroSD 卡作为启动介质的原因。在量产阶段,可以轻松切换到 eMMC——粗略来说,eMMC 就是焊接在 PCB 上的 MicroSD 卡。
启动流程
在并行接口闪存一统天下的时代,并不需要引导 ROM(boot ROM):与 SPI 或 MMC 不同,这些设备拥有地址线和数据线,可以轻松实现内存映射;事实上,早期处理器复位后会直接从并行闪存中执行代码。
但现在情况已经改变:现代应用处理器内置引导 ROM 代码,用于初始化 SPI、并行或 SDIO 接口,将闪存中的部分数据加载到 RAM 中,然后开始执行。实际上,一些引导 ROM 功能非常强大,甚至可以加载 MMC 设备文件系统中的文件。基于这类器件设计嵌入式硬件时,你必须密切关注引导 ROM 的配置方式。
一些微处理器的启动策略较为简单,会按照指定顺序尝试所有可能的闪存接口;而另一些则具有极其复杂(或者说“灵活”?)的启动选项,必须通过一次性可编程(OTP)熔丝或 GPIO 引导引脚进行配置。需要说明的是,这里所说的并非仅需处理 1-2 个信号:部分器件有超过 30 个不同的引导信号,必须通过上拉或下拉配置才能确保器件正常启动。
控制台 UART
与基于微控制器(MCU)的设计不同,在嵌入式 Linux 系统中,控制台 UART 是必不可少的。Linux 的整个跟踪架构都基于向控制台输出日志信息,U-Boot 引导程序也是如此。
这并不意味着不需要 JTAG/SWD 接口——尤其是在开发初期调试引导程序时(否则只能依赖 printf() 函数进行调试)。但需要说明的是,如果你在嵌入式 Linux 开发板上不得不使用 J-Link 调试器,那很可能意味着开发过程遇到了大麻烦。虽然可以为微处理器连接调试器,但与调试微控制器相比,正确配置所有调试环境极其繁琐。当代码从静态随机存取存储器(SRAM)转移到主动态随机存取存储器(DRAM)时,你需要重新定位符号表。此外,还经常需要调整其他寄存器(例如强制 CPU 退出 Thumb 模式)。更重要的是,我发现一些 U-Boot 移植版本会重新配置 JTAG 引脚(要么是为了实现替代功能,要么是为了节省功耗),部分器件的 JTAG 链非常复杂,需要使用该接口中不太常用的引脚和功能。另外,由于系统首先执行底层引导 ROM,JTAG 适配器也可能会干扰这一过程。
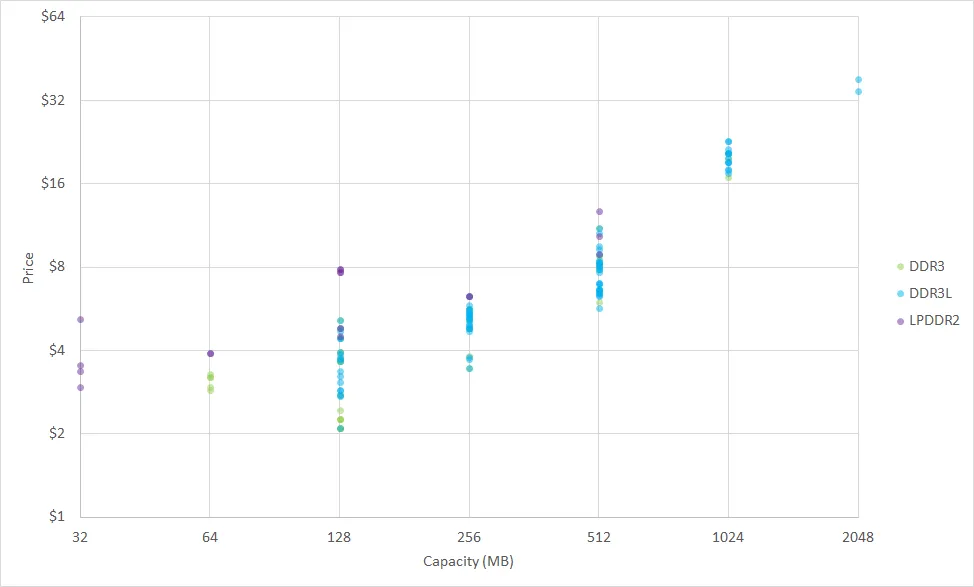
如图,得捷电子(Digi-Key)的最新价格趋势显示,512MB DDR3/DDR3L存储器的性价比最高,而单芯片1GB和2GB规格的价格则要高出30%。
DDR 布线复杂性的误区与“技术壁垒”
如果你在互联网上搜索 DDR 内存总线布线相关内容,会发现很多人询问布线方法,却遭到所谓“专家”的劝退——他们声称内存布线极其复杂,需要至少 6 层 PCB 堆叠、超高精度的长度匹配、受控阻抗,以及价值 20 万美元的专业设备才能确保设计正常工作。
这完全是无稽之谈。总体而言,内存布线最坏情况下也只是略显繁琐。积累一些经验后,布线 16 位宽的单芯片 DDR3 内存总线仅需约 1 小时,因此绝不能称之为无法逾越的挑战。花些时间学习 DDR 布线是值得的——这将为你在系统架构设计时提供极大的灵活性(无需依赖昂贵的系统级模块(SOM)或系统级封装(SiP)器件)。
需要明确的是:我这里所说的并非在 8 层 PCB 上布局 64 位宽、四通道、16 芯片的内存总线。相反,我们关注的是单芯片 16 位宽内存与 CPU 之间的点对点布线。这是本文评测所有器件均采用的布局策略,比多芯片布局简单得多——无需考虑地址总线端接、复杂的 T 型拓扑布线或飞线写入校准(fly-by write-leveling)。借助现代双芯片 DRAM 封装,单个 DDR3L 芯片的容量可达 2 GB。虽然双芯片封装的器件价格稍高,但能大幅简化 PCB 布线。
长度匹配
提到 DDR 布线,大多数人首先想到的是长度匹配。如果使用优质的 PCB 设计软件,设置长度匹配规则和绘制蛇形走线非常简单,大多数设计师都会下意识地对所有相对高速的信号(SDRAM、SDIO、并行 CSI/LCD 等)进行长度匹配。除了增加少量设计时间外,最大限度地预留时序裕量并无坏处,因此这种做法是合理的。
但如果使用劣质设计软件,需要手动导出走线长度表格、手动确定匹配约束,甚至手动绘制蛇形走线,该怎么办?长度匹配到底有多重要?不进行长度匹配是否可行?
本文评测的大多数微处理器最高支持 DDR3-800,其位周期为 1250 ps。低速 DDR3-800 内存在 AC135 电平下的数据建立时间最高可达 165 ps,保持时间为 150 ps,最坏情况下的信号偏移为 200 ps。假设我们使用的微处理器具有相同的规格,则总时序消耗为:处理器信号偏移 200 ps + DRAM 芯片信号偏移 200 ps + 建立时间 165 ps + 保持时间 150 ps = 715 ps。这意味着 PCB 长度不匹配的允许裕量为 535 ps(相当于超过 3500 密耳!)。

i.MX6UL 的修订历史显示,恩智浦(NXP)实际上删除了 DDR 内存控制器的时序参数。
我们对微处理器内存控制器的假设是否有效?谁也无法确定。我遇到的一个问题是,许多应用处理器的 DDR 控制器相关信息模糊不清。以 i.MX 6UL 为例:我发现很多人根据数据手册中的最坏情况时序参数进行计算,结果却发现几乎没有时序裕量。这些官方数据手册中的参数似乎是凭空捏造的——以至于恩智浦干脆删除了数据手册中整个 DDR 相关章节,取而代之的是一个标准说明,告知用户遵循“硬件设计指南”。德州仪器(TI)和意法半导体(ST)的文档中也缺乏内存控制器时序信息,同样建议用户遵循严格的硬件设计规则。(瑞芯微(Rockchip)和全志(Allwinner)甚至没有为其处理器指定任何时序数据或长度匹配指南。)
这些规则有多严格?几乎所有这些公司都建议每个字节组的长度匹配误差控制在 ±25 密耳以内。假设信号传播延迟为 150 ps/cm,则误差仅为 ±3.175 ps——仅占 DDR3-800 位周期(1250 ps)的 0.25%。这简直荒谬至极。试想一下,如果有人告诉你,在搭建 Arduino SPI 传感器实验平台时,必须确保所有面包板导线的长度差不超过半英寸,这就是我们所说的时序裕量要求。
为了验证这一点,我对两个 DDR3-800 设计进行了实证测试——一个进行长度匹配,另一个不进行长度匹配——结果两者性能完全一致。在数千次内存压力测试中,两个设计均未出现任何位错误。当然,这并不意味着该设计能全年无休(24/7/365)运行而不出现任何错误,但这无疑是一个良好的开端。为了验证设计是否处于边际状态,或者是否仅适用于某一款处理器,我将第二个系统的内存控制器超频两倍——让 DDR3-800 控制器以 DDR3-1600 速度运行——结果仍然没有出现任何位错误。事实上,我设计的五款基于分立 SDRAM 的开发板均违反了这些长度匹配指南,但全部通过了内存测试,并且在其他所有测试中均未出现崩溃或死机现象。
我的结论是:如果使用优质 CAD 软件,长度匹配并不复杂,花额外 30 分钟进行长度匹配以最大化时序裕量是值得的。但如果使用劣质 CAD 软件,或者急于制作原型,不必过于纠结——尤其是第一版(Rev A)设计。
**更重要的推论是:**如果设计出现问题,长度匹配很可能是最后需要排查的因素。首先,确保所有引脚连接正确——即使故障表现为间歇性。例如,不小心交换字节通道选通信号/掩码(我曾犯过这样的错误),会导致 8 位操作失败,但不会影响 32 位操作。由于大多数内存访问都是 32 位的,系统可能会表现出“看似正常”的状态。
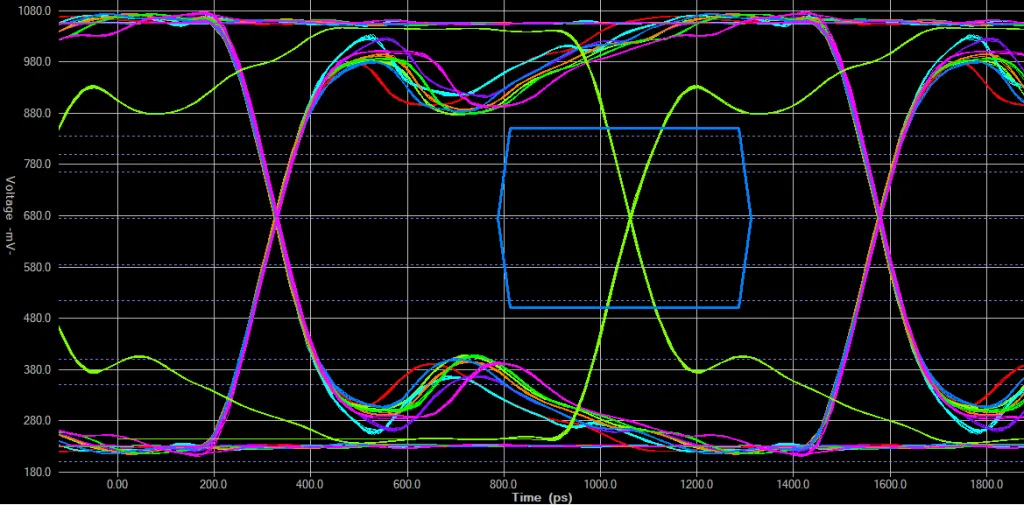
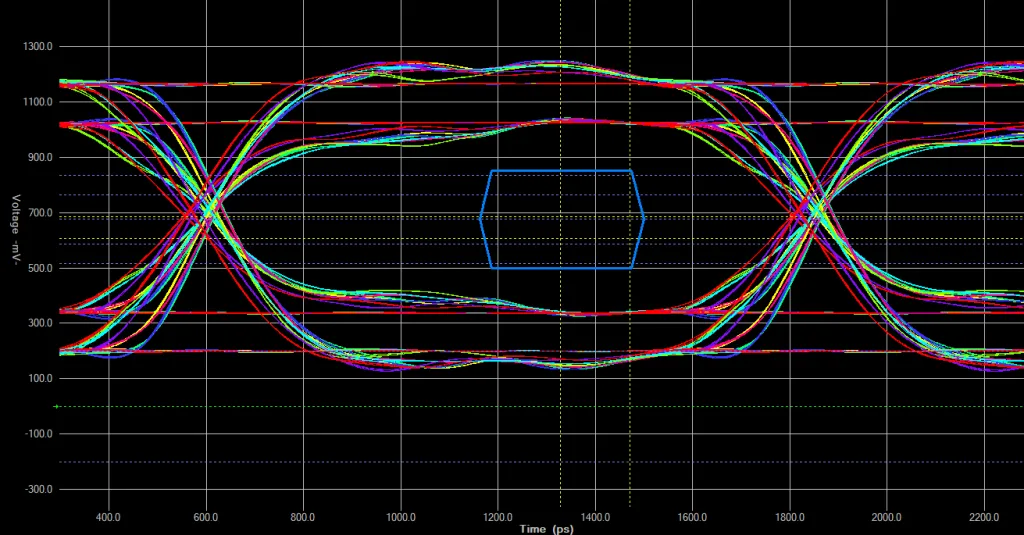
该眼图展示了一组经过严格长度匹配调整的数据,但信号完整性处于临界状态。绿色线条为选通信号,视角取自DRAM芯片的管芯端。蓝色眼图模板代表AC175电平标准下,为DDR3-800运行规格筛选的DDR3L存储器在时钟跳变点附近的建立时间与保持时间要求。
信号完整性
如果设计出现故障(无论是功能故障还是电磁兼容性测试失败),与其纠结于长度匹配,不如首先检查电源分配和信号完整性。我使用 HyperLynx 对采用不同布线策略的多种电路板设计进行了仿真,以说明相关问题。我并非信号完整性(SI)专家,如果你想学习更多实用技术,网上有很多优质资源;理论方面,大家普遍推荐霍华德·约翰逊(Howard Johnson)的《高速数字设计:黑魔法手册》(High Speed Digital Design: A Handbook of Black Magic)和《高速信号传播:高级黑魔法》(High Speed Signal Propagation: Advanced Black Magic),此外,我还推荐亨利·奥特(Henry Ott)的《电磁兼容性工程》(Electromagnetic Compatibility Engineering)。
理想情况下,每个信号的源阻抗、走线阻抗和负载阻抗都应匹配。当走线长度接近信号波长(经验法则是波长的 1/20)时,这一点尤为重要——对于 400 MHz 及以上的 DDR 布局,情况确实如此。
采用合理的 PCB 堆叠(通常使用约 0.1mm 的半固化片,5 密耳宽的走线可实现接近 50 欧姆的阻抗)是解决阻抗问题的第一道防线,通常足以确保系统正常工作,无需进行复杂的仿真/优化。
对于数据组,DDR3 采用片上端接(ODT)技术,内存芯片可配置为 40、60 或 120 欧姆(CPU 通常支持相同或相似的配置),同时配备可调输出阻抗驱动器。ODT 仅在接收端启用,因此根据数据读写方向,ODT 要么在内存芯片上启用,要么在 CPU 上启用。
对于简单的点对点布线,无需过多关注 ODT 设置。如上图眼图所示,CPU 从 DRAM 读取数据时,33 欧姆和 80 欧姆 ODT 端接的差异是可感知的,但两者均完全符合 AC175 电平要求(DDR3 规范中最严格的电压电平标准)。处理器的板级支持包(BSP)会初始化 DRAM 控制器的默认设置,这些设置通常能正常工作。
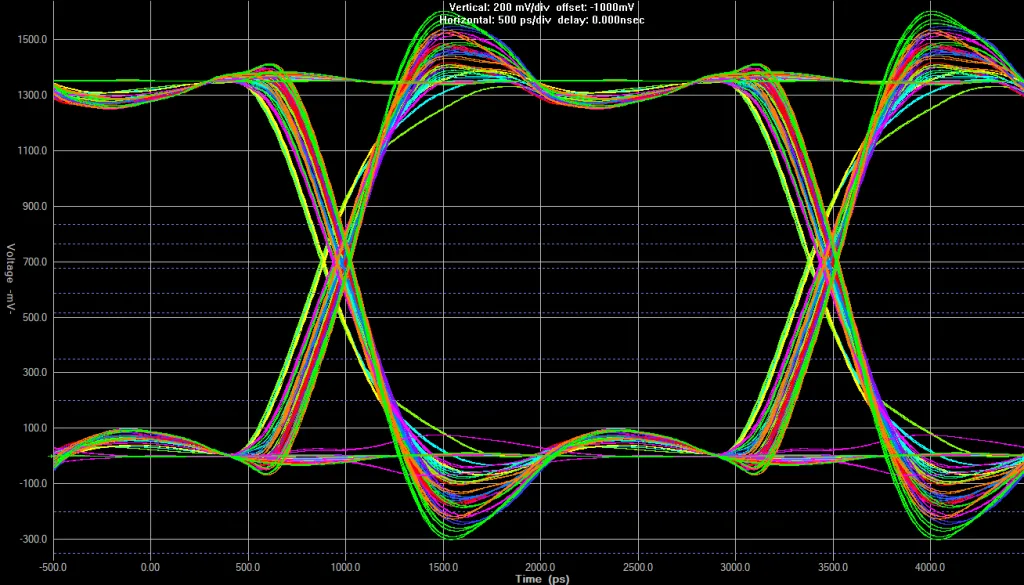
这是一条未端接的地址总线,通过调低转换速率设置及采用80欧姆输出驱动器实现了信号规整。总线存在明显过冲,但幅度未超过DRAM数据手册规定的400毫伏标准。信号间的时序偏移源于近300密耳的长度不匹配。
DDR3 相关的电磁兼容性(EMC)问题最可能来自地址总线。DDR3 采用单向地址总线(CPU 始终是发送端,内存芯片始终是接收端),且 DDR 内存芯片的这些信号没有片上端接。理论上,应在 DDR 内存芯片附近通过电阻将地址总线端接到 VTT(由 VDDQ/2 派生的电压)。对于带有多个内存芯片的大型飞线总线,通常会在总线最后一个芯片附近放置这些 VTT 端接电阻。这些电阻会吸收从微处理器传播过来的电磁波,减少传输线上的反射——否则所有内存芯片都会将这些反射视为电压波动。对于小型点对点设计,地址总线的长度通常很短,因此无需端接。如果遇到电磁兼容性问题,建议首先考虑软件解决方案,例如使用较慢的转换速率设置或增加输出阻抗以柔化信号。

我们可以通过在信号之间预留足够间距来减少串扰,但对于单芯片DRAM布线而言,这通常并无必要——此类布线长度一般不超过2英寸。
另一个信号完整性问题来源是走线之间的串扰。为了减少串扰,可以在走线之间预留足够的空间——标准经验法则是间距为线宽的三倍(3S)。我似乎在反复强调这一点,但再次说明:除非测试失败,否则不必过于教条,因为单芯片布线的长度通常很短。上图展示了一个未进行长度匹配但走线间距充足的 DDR 总线布线方案。注意下方的眼图显示,与本节第一个眼图相比,该方案的信号完整性要好得多(但代价是时序偏移)。
这是采用3倍线宽间距(3S)布线的存储器总线眼图。在约50欧姆微带线上使用40欧姆输出驱动器时,采用33欧姆和80欧姆片上端接(ODT)的差异如下:两者均完全符合严苛的AC175电平标准,但80欧姆端接存在更明显的过冲和振铃现象,而33欧姆端接则出现了不必要的过阻尼情况。信号中的时序偏移是由最短与最长信号间150密耳的长度差导致的。
引脚交换
由于 DDR 内存并不关心存储位的顺序,因此每个字节通道内的单个位(如果使用写入校准,最低有效位除外)可以随意交换,字节通道本身也可以完全交换。但需要说明的是,由于本文评测的所有器件均设计为与单颗 x16 宽 DDR 芯片配合使用(这类芯片具有行业标准引脚排列),我发现大多数引脚的布局已经非常合理。在开始交换引脚之前,确保没有忽略集成电路设计师预设的明显布局方案。
推荐方案
与其纠结于论坛上的无稽之谈或 HyperLynx 销售人员的夸大其词,对于简单的点对点 DDR 设计,遵循以下建议即可确保无虞:
- 1. 关注 PCB 堆叠:使用 4 层 PCB 堆叠,采用薄半固化片(约 0.1mm)以降低微带线的阻抗——这有助于走线向接收端传输更多能量。内层应分别为完整的地平面和 DDR VDD 电源平面。确保走线下方没有分割。如果追求极致,可以将外层铜皮与这些走线隔开,避免无意中形成共面结构,导致阻抗过低。
- 2. 避免使用多颗 DRAM 芯片:如果增加额外的 DRAM 芯片,必须采用飞线拓扑(需要对所有信号进行端接——非常繁琐)或 T 型拓扑(增加布线复杂性)。坚持使用 16 位宽 SDRAM,如果需要更大容量,可额外花费购买双芯片封装的器件——单颗 x16 宽双列芯片的容量可达 2 GB,足以满足这些 CPU 的所有应用需求。
- 3. 选择高速 RAM 简化布线:尽管本文评测的这些低端处理器的 DDR 速度很少能超过 400-533 MHz,但使用 800 或 933 MHz 的 DDR 芯片可以放宽时序裕量。减小的建立/保持时间使得地址/命令信号的长度匹配几乎完全不必要,减小的信号偏移甚至有助于双向数据总线信号的传输。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
