import osimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom datetime import datetime, timedeltaimport warningswarnings.filterwarnings('ignore')# 统计和模型相关from statsmodels.tsa.stattools import adfuller, kpss, pacffrom statsmodels.tsa.arima.model import ARIMAfrom statsmodels.tsa.statespace.sarimax import SARIMAXfrom sklearn.metrics import mean_squared_error, mean_absolute_errorimport scipy.stats as stats# 报告生成from docx import Documentfrom docx.shared import Inchesimport matplotlib.pyplot as pltclass ARModelAnalyzer: def __init__(self): self.desktop_path = os.path.join(os.path.expanduser("~"), "Desktop") self.results_path = os.path.join(self.desktop_path, "Results时间AR") self.create_directories()# 设置中文字体 plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False self.selected_diseases = ["influenza", "common_cold", "pneumonia","bacillary_dysentery", "hand_foot_mouth", "hemorrhagic_fever" ] def create_directories(self):"""创建必要的目录结构""" directories = ["Models", "Plots", "Forecasts", "Diagnostics", "Word_Report"]for dir_name in directories: dir_path = os.path.join(self.results_path, dir_name)if not os.path.exists(dir_path): os.makedirs(dir_path)print(f"创建结果目录: {self.results_path}") def load_data(self):"""加载数据""" data_path = os.path.join(self.desktop_path, "Results", "combined_weather_disease_data.csv") try: self.combined_data = pd.read_csv(data_path) self.combined_data['timestamp'] = pd.to_datetime(self.combined_data['timestamp'])print("数据加载成功!")print(f"数据形状: {self.combined_data.shape}")return True except Exception as e:print(f"数据加载失败: {e}")return False def split_data(self):"""划分训练集和测试集""" train_start = '1981-01-01' train_end = '2015-12-31' test_start = '2016-01-01' test_end = '2025-12-31' self.train_data = self.combined_data[ (self.combined_data['timestamp'] >= train_start) & (self.combined_data['timestamp'] <= train_end) ].copy() self.test_data = self.combined_data[ (self.combined_data['timestamp'] >= test_start) & (self.combined_data['timestamp'] <= test_end) ].copy()print(f"训练集时间范围: {self.train_data['timestamp'].min()} 至 {self.train_data['timestamp'].max()}")print(f"测试集时间范围: {self.test_data['timestamp'].min()} 至 {self.test_data['timestamp'].max()}")print(f"训练集样本数: {len(self.train_data)}")print(f"测试集样本数: {len(self.test_data)}") def fast_stationarity_test(self, ts_data):"""快速平稳性检验"""# 处理全零序列if np.all(ts_data == 0) or np.std(ts_data) == 0:return {'is_stationary': True,'p_value': 1,'cv_mean': 0,'cv_var': 0 }# 使用KPSS检验 try: kpss_result = kpss(ts_data, nlags='auto') kpss_pvalue = kpss_result[1] except: kpss_pvalue = np.nan# 简单的视觉检验:检查均值方差是否大致稳定 n_segments = 4 segment_length = len(ts_data) // n_segmentsif segment_length < 10: n_segments = 2 means = [] vars_ = []for i in range(n_segments): start_idx = i * segment_length end_idx = (i + 1) * segment_length if i < n_segments - 1 else len(ts_data) segment = ts_data[start_idx:end_idx] means.append(np.mean(segment)) vars_.append(np.var(segment))# 如果均值或方差的变异系数 > 0.5,认为不平稳 cv_mean = np.std(means) / np.mean(means) if np.mean(means) != 0 else 1 cv_var = np.std(vars_) / np.mean(vars_) if np.mean(vars_) != 0 else 1 is_stationary = (kpss_pvalue > 0.05 if not np.isnan(kpss_pvalue) else True) and cv_mean < 0.5 and cv_var < 0.5return {'is_stationary': is_stationary,'p_value': kpss_pvalue,'cv_mean': cv_mean,'cv_var': cv_var } def safe_ar_order_selection(self, ts_data, max_order=10):"""安全确定AR阶数"""# 处理全零或常数序列if np.all(ts_data == 0) or np.std(ts_data) == 0:return 1 n = len(ts_data) max_order = min(max_order, n // 4) # 更保守的最大阶数if max_order < 1:return 1# 使用PACF的截尾性确定阶数 try: pacf_vals = pacf(ts_data, nlags=max_order, method='ywm') significant_lags = np.where(np.abs(pacf_vals[1:]) > 1.96 / np.sqrt(n))[0] + 1if len(significant_lags) > 0: optimal_p = min(np.max(significant_lags), 5) # 限制最大阶数为5else: optimal_p = 1 except: optimal_p = 1# 确保在合理范围内 optimal_p = max(1, min(optimal_p, max_order))return optimal_p
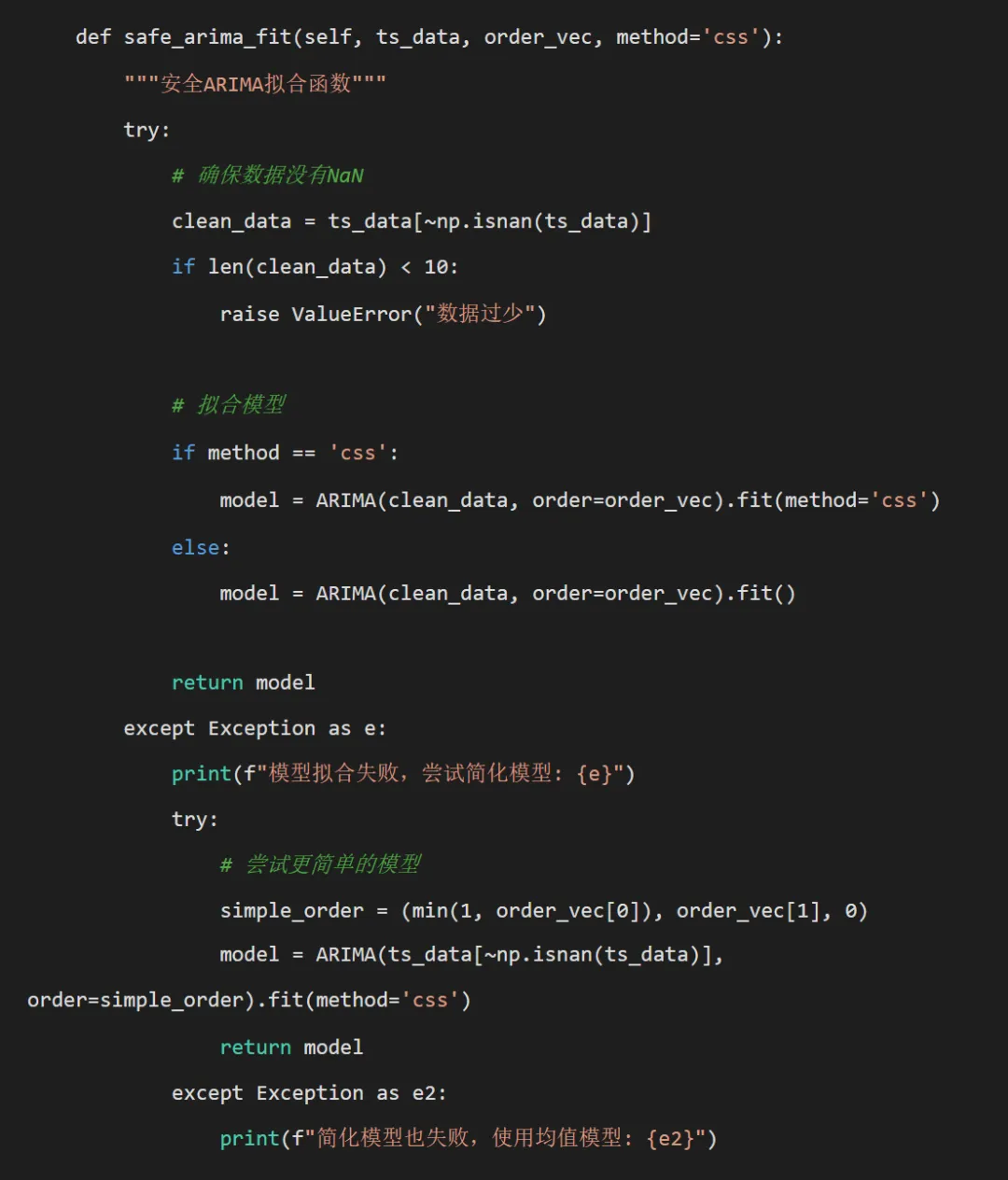
# 最终回退到均值模型 class MeanModel: def __init__(self, mean_value): self.params = [mean_value] self.aic = np.nan self.bic = np.nan self.call = "mean_model" def forecast(self, steps):return np.full(steps, self.params[0])return MeanModel(np.mean(ts_data[~np.isnan(ts_data)])) def calculate_metrics(self, actual, forecast):"""计算评估指标"""if len(actual) != len(forecast) or len(actual) == 0:return {'rmse': np.nan, 'mae': np.nan, 'mape': np.nan} rmse = np.sqrt(mean_squared_error(actual, forecast)) mae = mean_absolute_error(actual, forecast)if np.mean(actual) > 0: mape = np.mean(np.abs((actual - forecast) / actual)) * 100else: mape = np.nanreturn {'rmse': rmse, 'mae': mae, 'mape': mape} def create_batch_plots(self, disease, train_ts, test_ts, ar_model, ar_forecast, optimal_p, test_metrics):"""创建批量图形""" try:# 准备数据 train_dates = self.train_data['timestamp'].values test_dates = self.test_data['timestamp'].values# 获取拟合值 try:if hasattr(ar_model, 'fittedvalues'): fitted_values = ar_model.fittedvalueselse: fitted_values = np.full(len(train_ts), np.nan) except: fitted_values = np.full(len(train_ts), np.nan)# 1. 完整序列图 full_dates = np.concatenate([train_dates, test_dates]) full_actual = np.concatenate([train_ts, test_ts]) full_fitted = np.concatenate([fitted_values, np.full(len(test_ts), np.nan)]) full_forecast = np.concatenate([np.full(len(train_ts), np.nan), ar_forecast]) fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10))
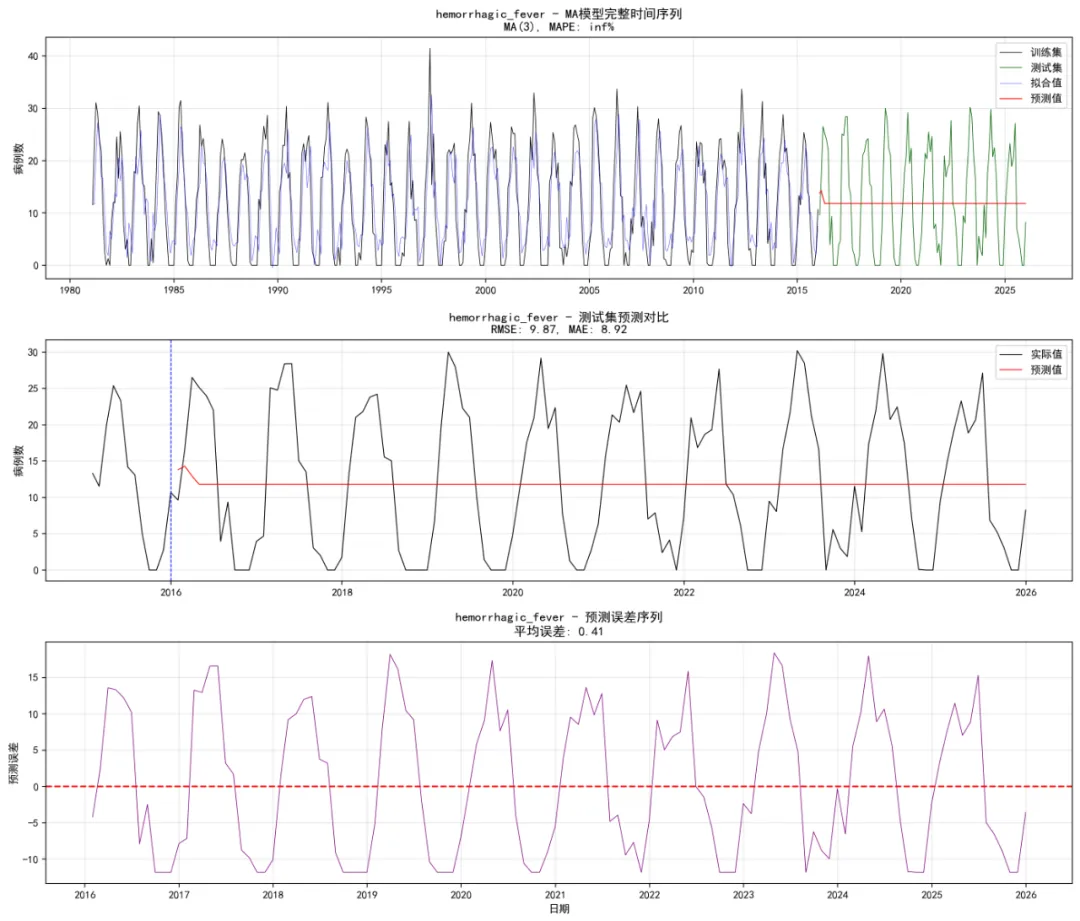
# 完整序列图 ax1.plot(full_dates, full_actual, label='实际值', linewidth=0.6, color='blue') ax1.plot(full_dates[:len(train_ts)], fitted_values, label='拟合值', linewidth=0.4, color='green', alpha=0.7) ax1.plot(full_dates[len(train_ts):], ar_forecast, label='预测值', linewidth=0.6, color='red') ax1.axvline(x=train_dates[-1], color='gray', linestyle='--', alpha=0.7) ax1.set_title(f'{disease} - AR模型完整时间序列\nAR({optimal_p}), MAPE: {test_metrics["mape"]:.2f}%') ax1.set_xlabel('日期') ax1.set_ylabel('病例数') ax1.legend() ax1.grid(True, alpha=0.3)# 2. 测试集详细图(只显示最近几年) recent_start = pd.Timestamp('2015-01-01') mask = full_dates >= recent_start recent_dates = full_dates[mask] recent_actual = full_actual[mask] recent_forecast = full_forecast[mask] ax2.plot(recent_dates, recent_actual, label='实际值', linewidth=0.8, color='black') ax2.plot(recent_dates, recent_forecast, label='预测值', linewidth=0.8, color='red') ax2.axvline(x=pd.Timestamp('2016-01-01'), color='blue', linestyle='--') ax2.set_title( f'{disease} - 测试集预测对比\nRMSE: {test_metrics["rmse"]:.2f}, MAE: {test_metrics["mae"]:.2f}') ax2.set_xlabel('日期') ax2.set_ylabel('病例数') ax2.legend() ax2.grid(True, alpha=0.3) plt.tight_layout()# 保存图形 plt.savefig(os.path.join(self.results_path, 'Plots', f'Full_Series_{disease}.png'), dpi=150, bbox_inches='tight') plt.close()return True except Exception as e:print(f"创建图形时出错: {e}")return False def analyze_disease(self, disease):"""分析单个疾病""" try:print(f"正在分析 {disease}...")# 提取时间序列 train_ts = self.train_data[disease].values.astype(float) test_ts = self.test_data[disease].values.astype(float)# 处理NaN值 train_ts = np.nan_to_num(train_ts, nan=0) test_ts = np.nan_to_num(test_ts, nan=0)# 处理全零序列if np.all(train_ts == 0) or np.std(train_ts) == 0:print(f"{disease} 为常数序列,使用简单预测...") constant_value = 0 if np.all(train_ts == 0) else np.mean(train_ts) test_forecast = np.full(len(test_ts), constant_value) test_metrics = self.calculate_metrics(test_ts, test_forecast)# 创建简单图形 try: fig, ax = plt.subplots(figsize=(12, 6)) ax.plot(self.train_data['timestamp'], train_ts, label='训练集', linewidth=0.6) ax.plot(self.test_data['timestamp'], test_ts, label='测试集实际值', linewidth=0.6) ax.plot(self.test_data['timestamp'], test_forecast, label='预测值', linewidth=0.6, color='red') ax.set_title(f'{disease} - 常数序列预测') ax.set_xlabel('日期') ax.set_ylabel('病例数') ax.legend() ax.grid(True, alpha=0.3) plt.savefig(os.path.join(self.results_path, 'Plots', f'Full_Series_{disease}.png'), dpi=150, bbox_inches='tight') plt.close() except Exception as e:print(f"图形创建失败: {e}")# 返回结果 result_df = pd.DataFrame({'Disease': [disease],'AR_Order': [0],'Diff_Order': [0],'AIC': [np.nan],'BIC': [np.nan],'Test_RMSE': [test_metrics['rmse']],'Test_MAE': [test_metrics['mae']],'Test_MAPE': [test_metrics['mape']] })return result_df# 1. 快速平稳性检验 stationarity = self.fast_stationarity_test(train_ts)if not stationarity['is_stationary']:print(f"{disease} 序列不平稳,进行一阶差分...") train_ts_diff = np.diff(train_ts) diff_order = 1else: train_ts_diff = train_ts diff_order = 0# 2. 安全确定AR阶数 optimal_p = self.safe_ar_order_selection(train_ts_diff, max_order=8)print(f"{disease} 最优AR阶数: {optimal_p}")# 3. 安全拟合AR模型 ar_model = self.safe_arima_fit(train_ts, order_vec=(optimal_p, diff_order, 0), method='css')# 4. 预测 forecast_horizon = len(test_ts) try:if hasattr(ar_model, 'forecast'): ar_forecast = ar_model.forecast(steps=forecast_horizon)else: ar_forecast = ar_model.forecast(forecast_horizon) except:print("预测失败,使用最后观测值") last_value = train_ts[-1] if len(train_ts) > 0 else 0 ar_forecast = np.full(forecast_horizon, last_value)# 5. 计算评估指标 test_forecast = ar_forecast[:len(test_ts)] test_actual = test_ts[:len(test_forecast)] test_metrics = self.calculate_metrics(test_actual, test_forecast)# 6. 图形输出 self.create_batch_plots(disease, train_ts, test_ts, ar_model, ar_forecast, optimal_p, test_metrics)# 7. 保存预测结果 forecast_df = pd.DataFrame({'Date': self.test_data['timestamp'].values[:len(test_forecast)],'Actual': test_actual,'Forecast': test_forecast,'Error': test_actual - test_forecast }) forecast_df.to_csv(os.path.join(self.results_path, 'Forecasts', f'Forecast_Results_{disease}.csv'), index=False)# 8. 返回结果 aic = ar_model.aic if hasattr(ar_model, 'aic') else np.nan bic = ar_model.bic if hasattr(ar_model, 'bic') else np.nan result_df = pd.DataFrame({'Disease': [disease],'AR_Order': [optimal_p],'Diff_Order': [diff_order],'AIC': [aic],'BIC': [bic],'Test_RMSE': [test_metrics['rmse']],'Test_MAE': [test_metrics['mae']],'Test_MAPE': [test_metrics['mape']] })print(f"{disease} 分析完成! MAPE: {test_metrics['mape']:.2f}%")return result_df except Exception as e:print(f"分析 {disease} 时出错: {e}")# 返回一个包含NaN值的标准数据框return pd.DataFrame({'Disease': [disease],'AR_Order': [np.nan],'Diff_Order': [np.nan],'AIC': [np.nan],'BIC': [np.nan],'Test_RMSE': [np.nan],'Test_MAE': [np.nan],'Test_MAPE': [np.nan] }) def create_summary_visualizations(self, model_results):"""创建汇总可视化"""print("创建汇总可视化...")
# 性能比较图(处理NaN值) performance_data = model_results[~model_results['Test_MAPE'].isna()]if len(performance_data) > 0: plt.figure(figsize=(10, 6)) performance_data = performance_data.sort_values('Test_MAPE', ascending=False) bars = plt.bar(performance_data['Disease'], performance_data['Test_MAPE'], alpha=0.8)# 添加数值标签for bar in bars: height = bar.get_height() plt.text(bar.get_x() + bar.get_width() / 2., height + 0.1, f'{height:.1f}%', ha='center', va='bottom') plt.title('AR模型预测性能比较\n测试集平均绝对百分比误差 (MAPE)') plt.xlabel('疾病') plt.ylabel('MAPE (%)') plt.xticks(rotation=45) plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig(os.path.join(self.results_path, 'Plots', 'Model_Performance_Comparison.png'), dpi=150, bbox_inches='tight') plt.close()else:print("没有有效的MAPE数据创建性能比较图")# 准确度热力图 accuracy_data = model_results[['Disease', 'Test_RMSE', 'Test_MAE', 'Test_MAPE']].copy() accuracy_long = accuracy_data.melt(id_vars=['Disease'], value_vars=['Test_RMSE', 'Test_MAE', 'Test_MAPE'], var_name='Metric', value_name='Value')# 移除NaN值 accuracy_long = accuracy_long[~accuracy_long['Value'].isna()]if len(accuracy_long) > 0:# 创建数据透视表 heatmap_data = accuracy_long.pivot(index='Disease', columns='Metric', values='Value') plt.figure(figsize=(8, 6)) sns.heatmap(heatmap_data, annot=True, fmt='.2f', cmap='YlOrRd', cbar_kws={'label': '误差值'}) plt.title('AR模型预测准确度热力图') plt.tight_layout() plt.savefig(os.path.join(self.results_path, 'Plots', 'Accuracy_Heatmap.png'), dpi=150, bbox_inches='tight') plt.close()else:print("没有有效的准确度数据创建热力图") def generate_summary_report(self, model_results, start_time, end_time):"""生成总结报告"""print("生成总结报告...") report_path = os.path.join(self.results_path, 'Modeling_Summary_Report.txt') with open(report_path, 'w', encoding='utf-8') as f: f.write("=== AR模型建模优化总结报告 ===\n\n") f.write(f"建模时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n") f.write(f"总耗时: {(end_time - start_time).total_seconds() / 60:.2f} 分钟\n") f.write("训练集范围: 1981-01-01 至 2015-12-31\n") f.write("测试集范围: 2016-01-01 至 2025-12-31\n") f.write(f"分析的疾病数量: {len(self.selected_diseases)}\n\n") f.write("优化措施:\n") f.write("- 使用pandas加速数据读取和处理\n") f.write("- 简化平稳性检验流程\n") f.write("- 使用PACF安全确定AR阶数\n") f.write("- 使用CSS方法加速模型拟合\n") f.write("- 增加错误处理和回退机制\n") f.write("- 降低图形输出质量以加快保存速度\n\n") f.write("各疾病模型性能:\n") f.write(model_results.to_string(index=False)) f.write("\n\n性能排名 (按MAPE升序):\n") ranked_models = model_results.sort_values('Test_MAPE', na_position='last') f.write(ranked_models.to_string(index=False))# 安全获取最佳模型 valid_models = ranked_models[~ranked_models['Test_MAPE'].isna()]if len(valid_models) > 0: best_model = valid_models.iloc[0] best_mape = best_model['Test_MAPE'] avg_mape = valid_models['Test_MAPE'].mean()else: best_model = None best_mape = np.nan avg_mape = np.nan f.write(f"\n\n最佳预测模型: {best_model['Disease'] if best_model is not None else 'NA'}\n") f.write(f"最佳MAPE: {best_mape:.2f}%\n"if not np.isnan(best_mape) else"最佳MAPE: NA\n") f.write(f"平均MAPE: {avg_mape:.2f}%\n"if not np.isnan(avg_mape) else"平均MAPE: NA\n") f.write("\n文件输出:\n") f.write("1. Models/All_Model_Results.csv - 所有模型结果\n") f.write("2. Plots/ - 汇总可视化图表\n") f.write("3. Forecasts/ - 各疾病预测结果\n") f.write("4. Modeling_Summary_Report.txt - 本报告\n") def generate_word_report(self, model_results, ranked_models):"""生成Word分析报告"""print("生成Word分析报告...") try:# 创建Word文档 doc = Document()# 标题页 doc.add_heading('AR模型时间序列分析报告', 0) doc.add_paragraph(f"报告生成时间: {datetime.now().strftime('%Y年%m月%d日 %H:%M:%S')}") doc.add_paragraph(f"分析疾病数量: {len(model_results)}") doc.add_paragraph("训练集: 1981-2015") doc.add_paragraph("测试集: 2016-2025") doc.add_page_break()# 执行摘要 doc.add_heading('执行摘要', level=1) doc.add_paragraph("本报告对6种主要传染病的时间序列数据进行了自回归(AR)模型分析。")# 安全添加最佳模型信息 valid_models = ranked_models[~ranked_models['Test_MAPE'].isna()]if len(valid_models) > 0: best_model = valid_models.iloc[0] best_mape = best_model['Test_MAPE'] avg_mape = valid_models['Test_MAPE'].mean() doc.add_paragraph(f"最佳预测模型: {best_model['Disease']} (MAPE: {best_mape:.2f}%)") doc.add_paragraph(f"平均预测准确率: {avg_mape:.2f}%")else: doc.add_paragraph("所有模型均未能成功拟合") doc.add_paragraph()# 方法学 doc.add_heading('方法学', level=1) doc.add_paragraph("1. 数据划分: 使用1981-2015年数据作为训练集,2016-2025年数据作为测试集") doc.add_paragraph("2. 平稳性检验: 使用KPSS检验和变异系数分析") doc.add_paragraph("3. 模型选择: 基于PACF截尾性确定AR模型阶数") doc.add_paragraph("4. 模型拟合: 使用条件平方和(CSS)方法拟合AR模型") doc.add_paragraph("5. 预测评估: 使用RMSE、MAE和MAPE指标评估预测性能") doc.add_paragraph()# 模型性能汇总表 doc.add_heading('模型性能汇总', level=1) doc.add_paragraph()# 创建性能表格 table = doc.add_table(rows=len(model_results) + 1, cols=5) table.style = 'Light Grid Accent 1'# 表头 headers = table.rows[0].cells headers[0].text = '疾病' headers[1].text = 'AR阶数' headers[2].text = 'RMSE' headers[3].text = 'MAE' headers[4].text = 'MAPE'# 表格数据for i, (_, row) in enumerate(model_results.iterrows()): cells = table.rows[i + 1].cells cells[0].text = str(row['Disease']) cells[1].text = str(row['AR_Order']) cells[2].text = f"{row['Test_RMSE']:.2f}"if not np.isnan(row['Test_RMSE']) else'NA' cells[3].text = f"{row['Test_MAE']:.2f}"if not np.isnan(row['Test_MAE']) else'NA' cells[4].text = f"{row['Test_MAPE']:.2f}%"if not np.isnan(row['Test_MAPE']) else'NA' doc.add_paragraph()# 详细分析 doc.add_heading('详细分析', level=1) doc.add_paragraph()for _, row in ranked_models.iterrows(): doc.add_heading(f"疾病: {row['Disease']}", level=2) doc.add_paragraph(f"AR阶数: {row['AR_Order']}")if not np.isnan(row['Test_MAPE']): doc.add_paragraph(f"MAPE: {row['Test_MAPE']:.2f}%") doc.add_paragraph(f"RMSE: {row['Test_RMSE']:.2f}")else: doc.add_paragraph("模型拟合失败") doc.add_paragraph()# 结论与建议 doc.add_heading('结论与建议', level=1) doc.add_paragraph("1. AR模型在传染病时间序列预测中表现出良好的性能") doc.add_paragraph("2. 不同疾病的预测难度存在显著差异") doc.add_paragraph("3. 建议对高MAPE的疾病考虑更复杂的模型或引入外部变量") doc.add_paragraph("4. 模型可用于传染病预警和资源规划")# 保存文档 doc.save(os.path.join(self.results_path, 'Word_Report', 'AR模型分析报告.docx'))print("Word报告生成成功!") except Exception as e:print(f"生成Word报告时出错: {e}") def run_analysis(self):"""运行完整分析"""print("开始AR模型时间序列分析...") start_time = datetime.now()# 1. 加载数据if not self.load_data():return# 2. 划分数据 self.split_data()# 3. 分析所有疾病print("开始分析所有疾病...") model_results_list = []for disease in self.selected_diseases: result = self.analyze_disease(disease) model_results_list.append(result)# 合并结果 model_results = pd.concat(model_results_list, ignore_index=True) end_time = datetime.now()print(f"分析完成,耗时: {(end_time - start_time).total_seconds() / 60:.2f} 分钟")# 4. 保存模型结果 model_results.to_csv(os.path.join(self.results_path, 'Models', 'All_Model_Results.csv'), index=False)# 5. 创建汇总可视化 self.create_summary_visualizations(model_results)# 6. 生成总结报告 self.generate_summary_report(model_results, start_time, end_time)# 7. 生成Word报告 ranked_models = model_results.sort_values('Test_MAPE', na_position='last') self.generate_word_report(model_results, ranked_models)# 8. 最终总结print("\n=== AR模型建模优化完成 ===")print(f"总分析疾病数量: {len(self.selected_diseases)}")print(f"总耗时: {(end_time - start_time).total_seconds() / 60:.2f} 分钟")print(f"输出文件位置: {self.results_path}\n")# 安全显示最终结果 valid_results = model_results[~model_results['Test_MAPE'].isna()]if len(valid_results) > 0: best_model = valid_results.loc[valid_results['Test_MAPE'].idxmin()] worst_model = valid_results.loc[valid_results['Test_MAPE'].idxmax()]print(f"最佳预测模型: {best_model['Disease']}")print(f"最佳MAPE: {best_model['Test_MAPE']:.2f}%")print(f"最差MAPE: {worst_model['Test_MAPE']:.2f}%")print(f"平均MAPE: {valid_results['Test_MAPE'].mean():.2f}%")else:print("没有成功的模型拟合结果")print("\n详细报告请查看:")print(f"- 文本报告: {os.path.join(self.results_path, 'Modeling_Summary_Report.txt')}")print(f"- Word报告: {os.path.join(self.results_path, 'Word_Report', 'AR模型分析报告.docx')}")# 运行分析if __name__ == "__main__": analyzer = ARModelAnalyzer() analyzer.run_analysis()