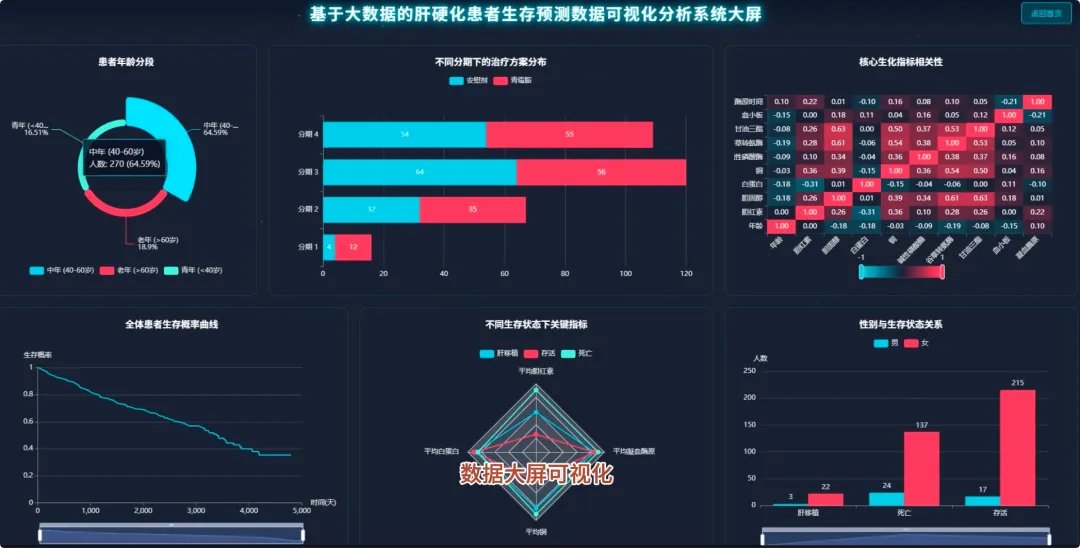
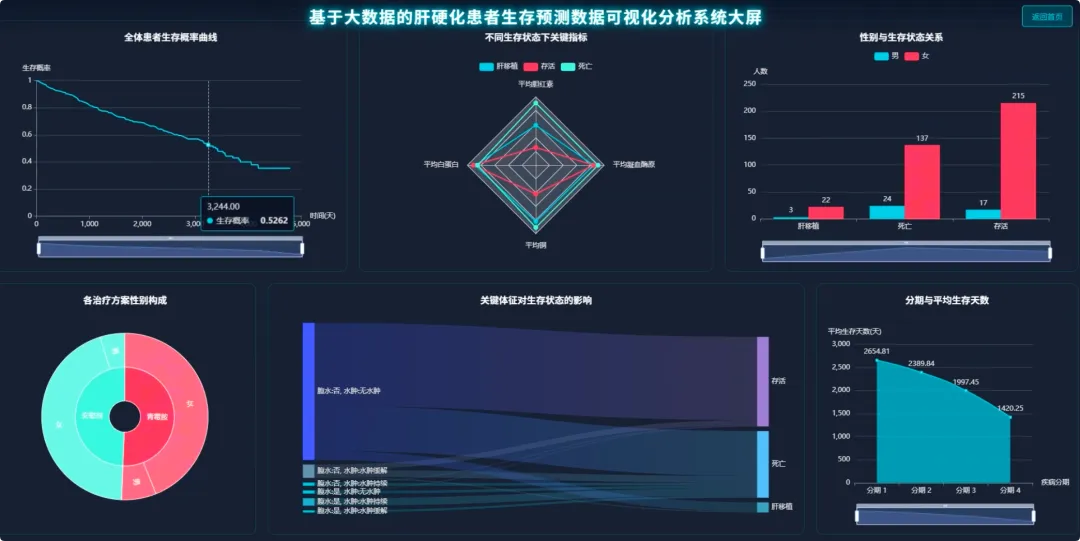
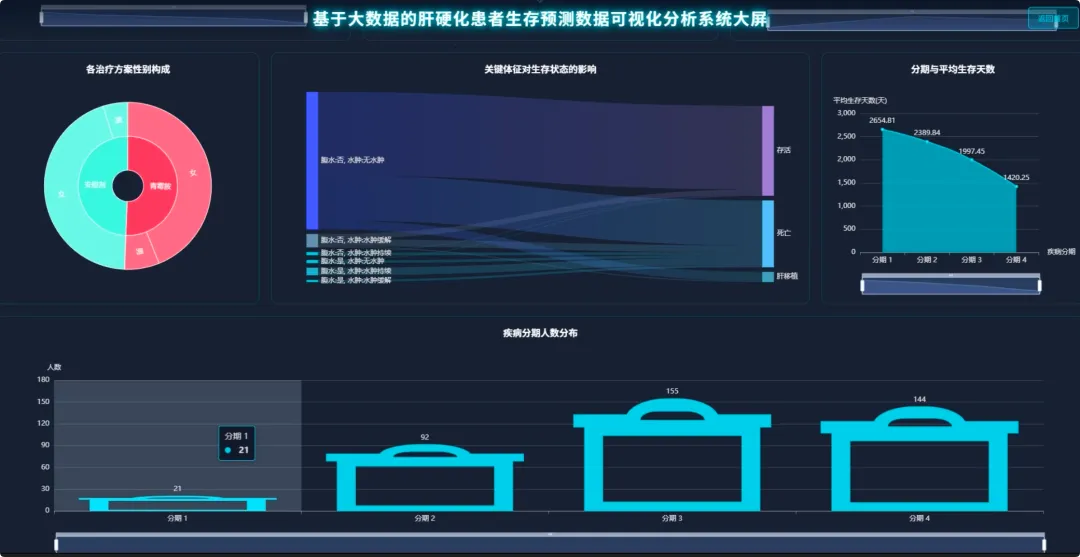
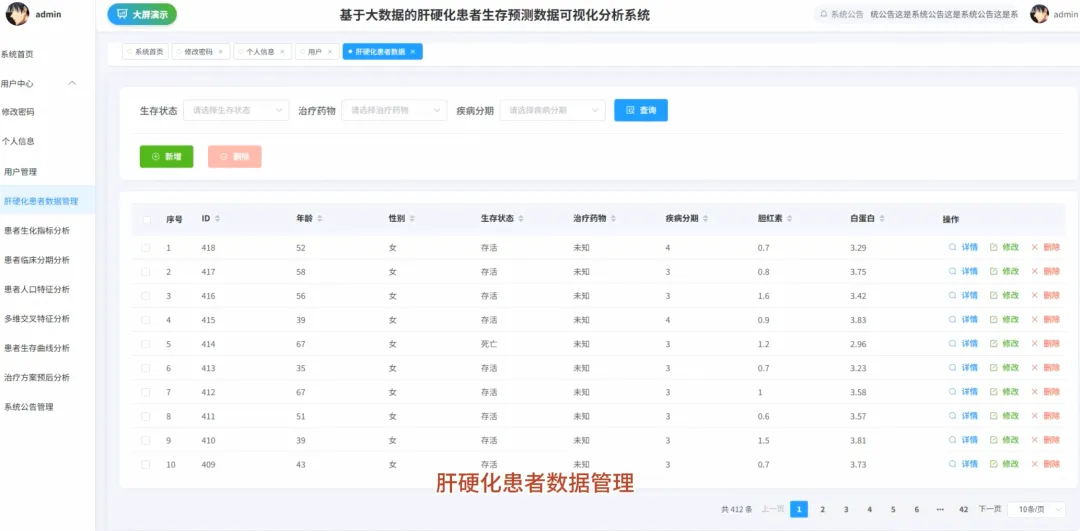
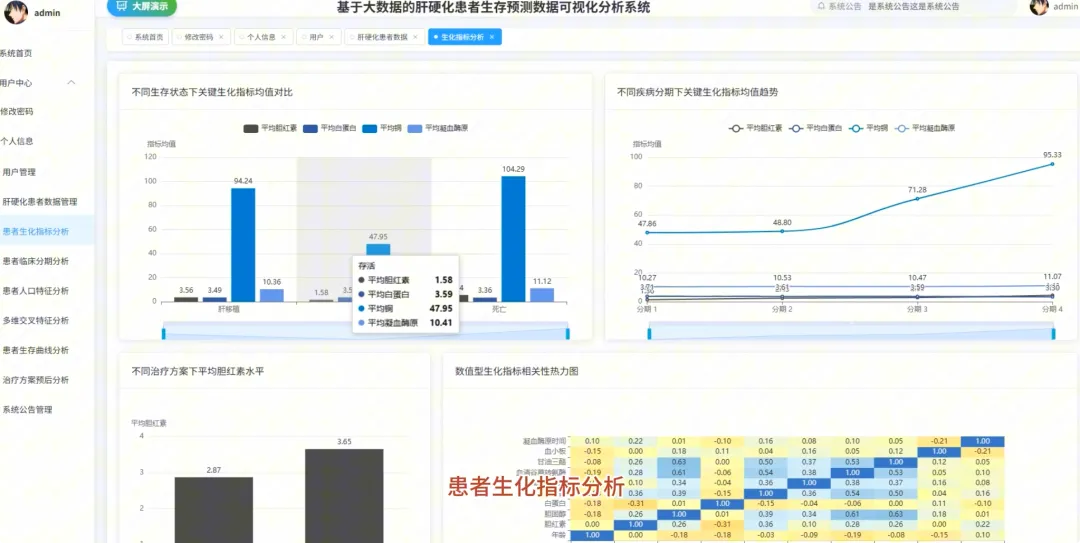
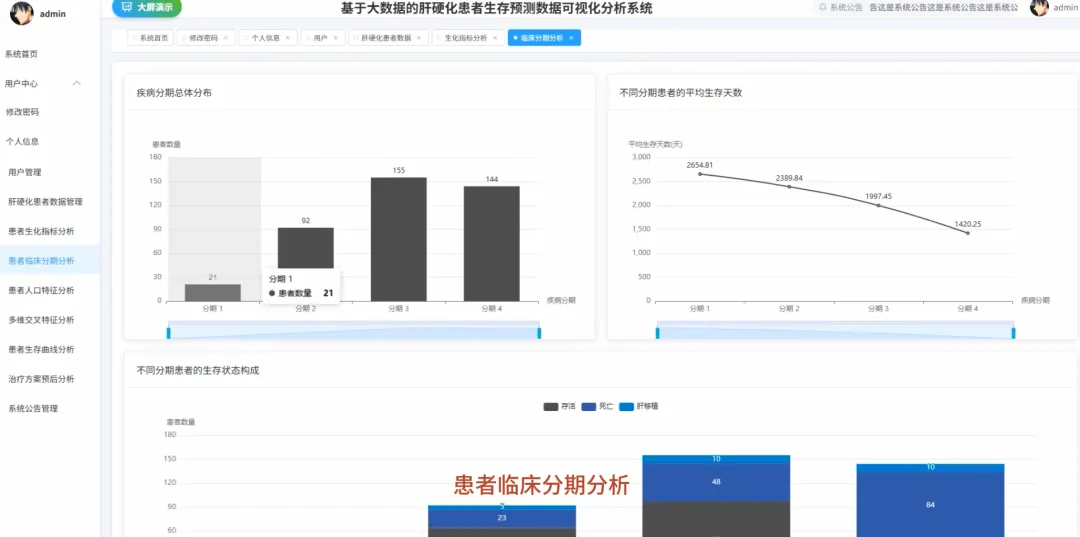
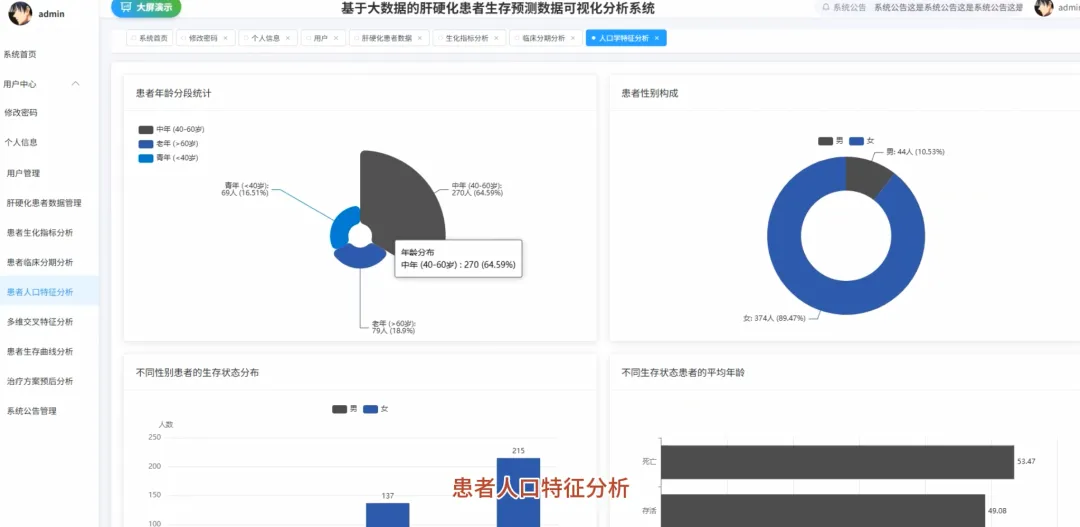
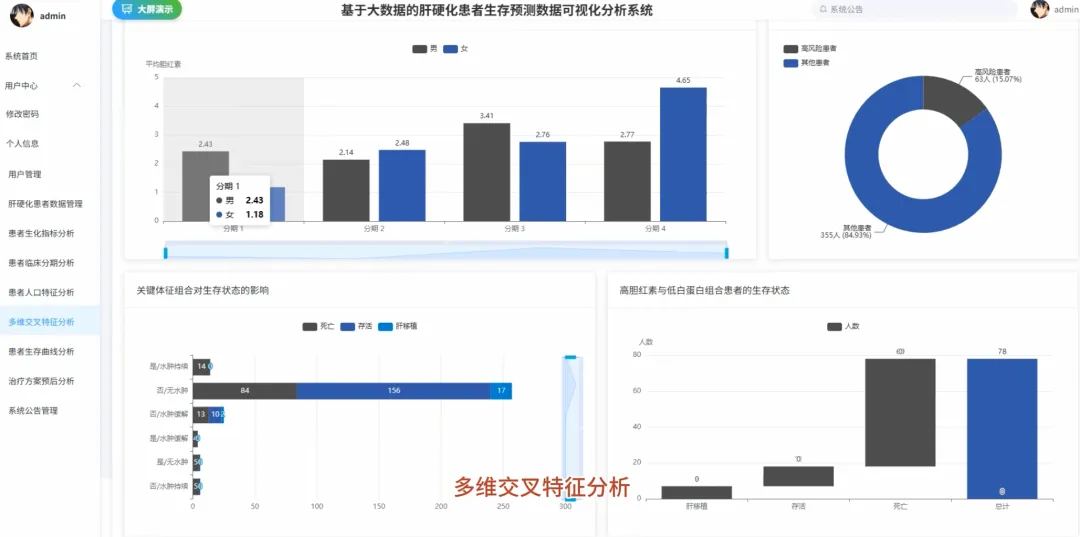
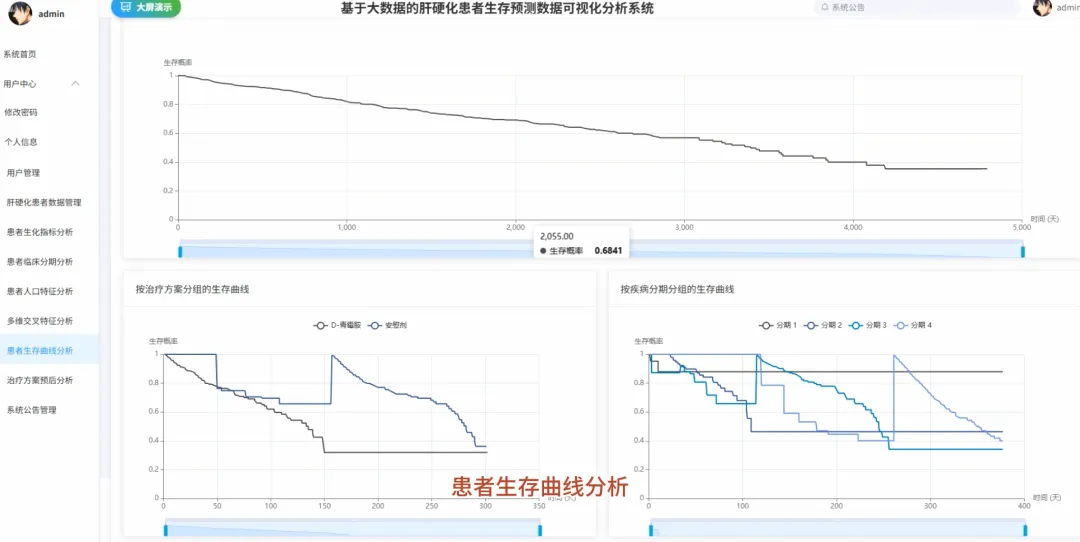
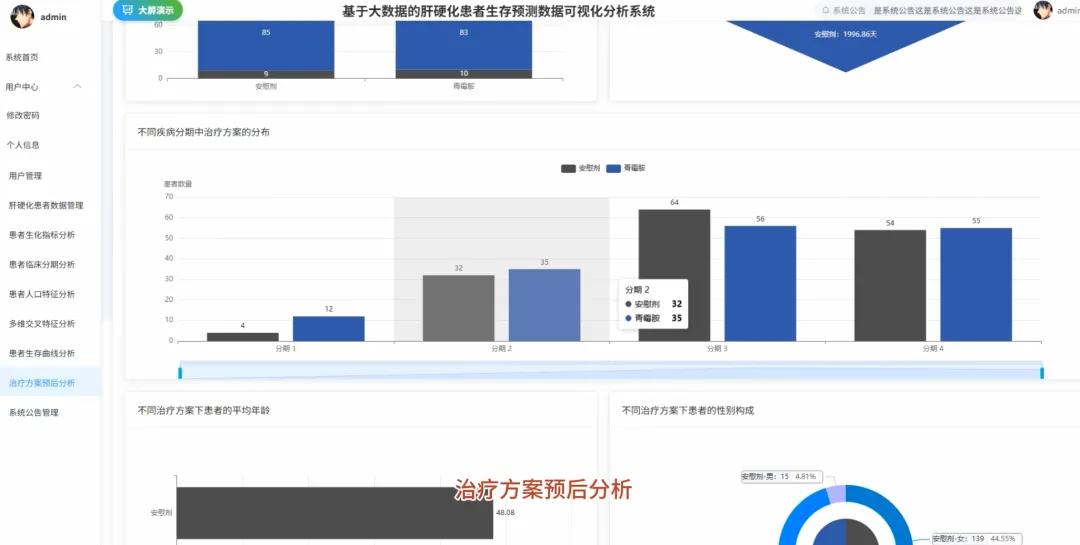
from pyspark.sql import SparkSession, functions as Fspark = SparkSession.builder.appName("CirrhosisAnalysis").getOrCreate()# 核心功能1:按治疗方案分组的Kaplan-Meier生存曲线数据准备def kaplan_meier_data_by_drug(): df = spark.read.csv("cirrhosis_processed.csv", header=True, inferSchema=True) # 将生存状态转换为事件指示器(1表示事件发生,如死亡;0表示删失) df_km = df.withColumn("Event", F.when(df["Status"] == "D", 1).otherwise(0)) # 按药物分组,计算每个时间点的生存人数和事件发生人数 km_data = df_km.groupBy("Drug", "N_Days").agg( F.sum("Event").alias("Events"), F.count("*").alias("At_Risk") ).orderBy("Drug", "N_Days") # 计算生存概率,这里简化处理,实际KM曲线需要更复杂的窗口函数计算累积生存率 # 返回数据供前端绘制曲线 return km_data.collect()# 核心功能2:不同疾病分期下,男女患者的平均胆红素水平对比def bilirubin_by_stage_sex(): df = spark.read.csv("cirrhosis_processed.csv", header=True, inferSchema=True) # 按疾病分期和性别分组,计算胆红素的平均值 result = df.groupBy("Stage", "Sex").agg( F.round(F.avg("Bilirubin"), 2).alias("Avg_Bilirubin") ).orderBy("Stage", "Sex") # 将结果转换为前端易于处理的格式,例如按分期为键,性别为值的字典 collected_data = result.collect() return collected_data# 核心功能3:关键生化指标在不同生存状态下的均值对比分析def biochem_by_status(): df = spark.read.csv("cirrhosis_processed.csv", header=True, inferSchema=True) # 筛选出生存状态为死亡(D)和存活(C)的患者 filtered_df = df.filter((df["Status"] == "D") | (df["Status"] == "C")) # 按生存状态分组,计算多个关键生化指标的平均值 biochem_avg = filtered_df.groupBy("Status").agg( F.round(F.avg("Bilirubin"), 2).alias("Avg_Bilirubin"), F.round(F.avg("Albumin"), 2).alias("Avg_Albumin"), F.round(F.avg("Copper"), 2).alias("Avg_Copper"), F.round(F.avg("Prothrombin"), 2).alias("Avg_Prothrombin") ).orderBy("Status") # 返回聚合后的结果,用于前端图表展示 return biochem_avg.collect()