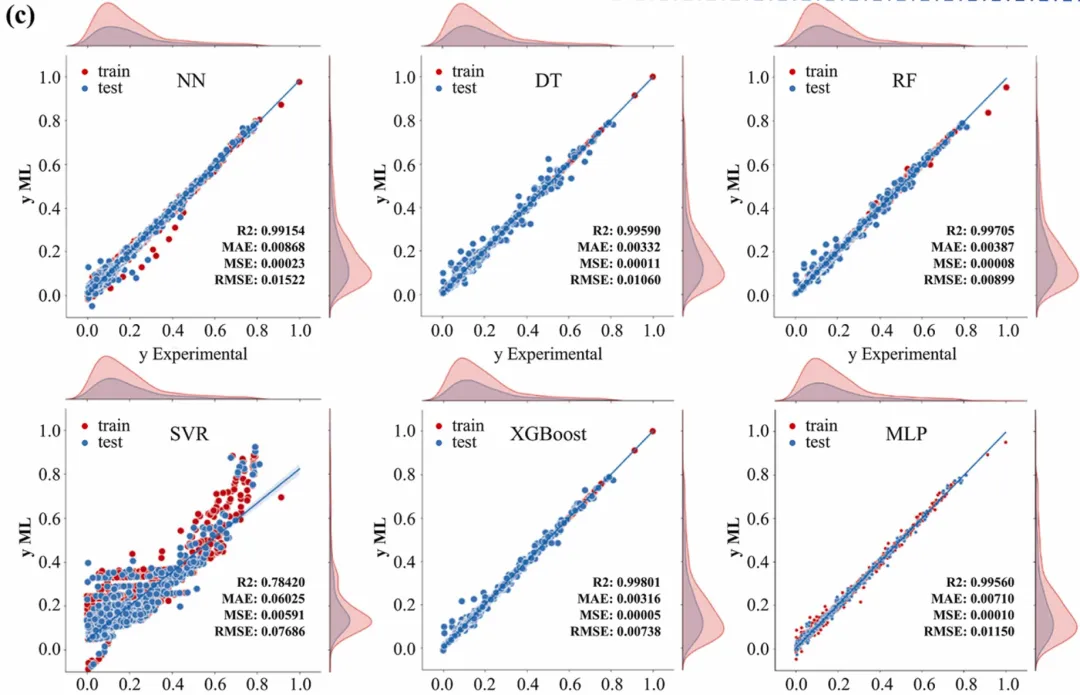
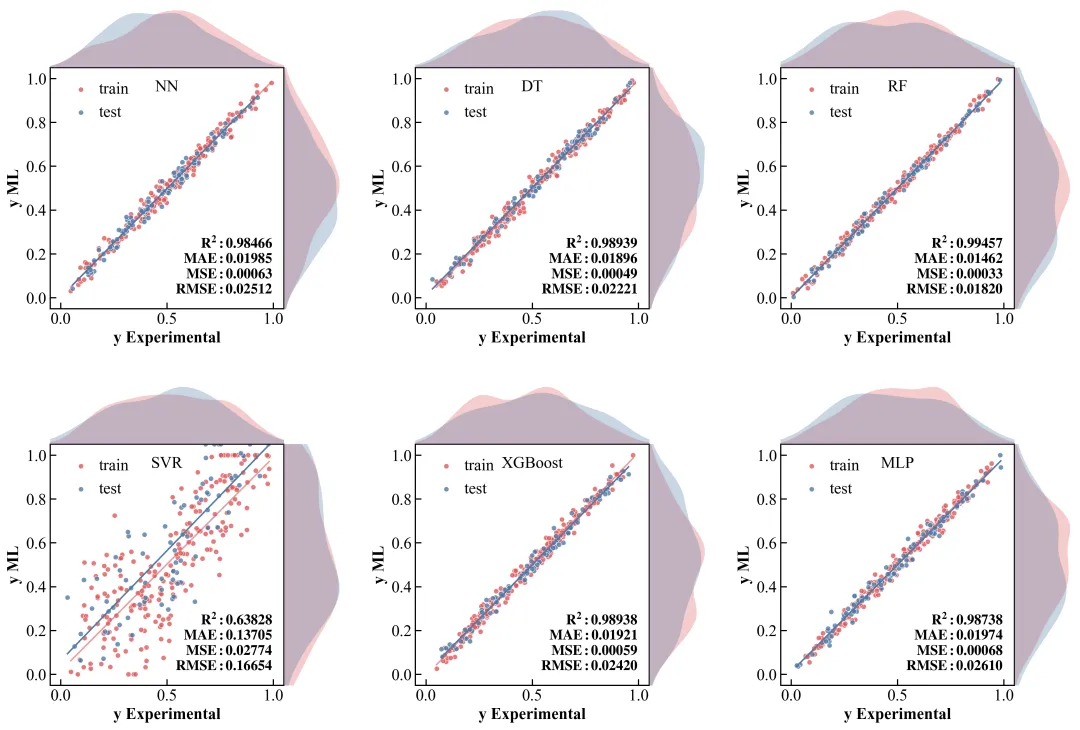
做机器学习或者回归分析的朋友,对“预测值 vs 真实值”的散点图(Parity Plot)一定不陌生。最基础的做法就是画个散点,打个 $y=x$ 的对角线,完事。
但当你把这图放进论文里,审稿人可能会皱眉:点都堆在一起,我怎么看出数据的分布偏态?样本是集中在低值区还是高值区?单纯的 $R^2$ 很高,是不是因为几个离群点拉高的?
这时候,我们就需要引入“边缘分布(Marginal Distribution)”。
看看今天我们要复刻的这张顶刊原图:它不仅仅是一个散点图,它在 X 轴和 Y 轴的边缘,巧妙地嵌入了数据的密度分布曲线(KDE)。这就像给数据做了一次“全身CT”——中间看关联,两边看分布。更妙的是,它在一个版面内整齐排列了 6 个模型的对比(NN, DT, RF, SVR, XGBoost, MLP),并把评估指标(MAE, MSE, RMSE, R2)像铭牌一样刻在图里。
今天,我们就用 Python 拆解这张图。很多人用 Seaborn 的 jointplot 画单张图很溜,但要把 6 张 jointplot 拼在一起就报错。别急,今天我要带你用 Matplotlib 的 GridSpec 手术刀,把这个复杂布局彻底解构,让你的模型评估图瞬间拥有“顶刊气质”。
这张图的结构非常有意思,它采用了 2行 × 3列 的大布局,但每个子图内部又是一个 “三合一” 的微型系统。
主图层 (Main Scatter):位于中心,展示 $y{ML}$ (预测) 与 $y{Experimental}$ (实验) 的关系。这是视觉重心。
对角线 (Identity Line):那条 $y=x$ 的蓝线。它是“完美预测”的基准线。点越贴近线,模型越准。
边缘图层 (Marginal Plots):
指标铭牌 (Metrics Box):右下角的文字块。这不是随便写的,而是对其了位置,使用了等宽字体或精确排版,让 R2、MAE 等指标一目了然。
🍰 核心技巧 (The Trick)
这里的技术难点在于布局的嵌套。
普通的 plt.subplots(2, 3) 只能给你 6 个格子。但我们需要在每个格子里,再“抠”出顶部和右侧的空间给边缘图。
这就好比装修房子,普通做法是把房间隔成 6 间卧室;而高级做法是,在每间卧室里,还要再隔出一个衣帽间和一个独立卫浴。
解决方案:我们将使用 Matplotlib 的 GridSpec 或者 axes_grid1 工具包来实现这种“房中房”的精细布局。
🎨 配色 (Palette)
论文原图
Step 1: 全局配置
“高手画图,都是先立规矩。” 我们先设置全局字体和样式,并生成 6 组模拟回归数据。
import matplotlib.pyplot as pltimport matplotlib.font_manager as fmimport warnings# 全局关闭非关键警告,保证绘图输出整洁,看着清爽warnings.filterwarnings('ignore')# --- 顶刊风格内核锁定 (Journal Aesthetics) ---# 字体设置:优先使用 Times New Roman,这是 SCI 的标配plt.rcParams['font.family'] = ['Times New Roman', 'Arial', 'SimHei']plt.rcParams['mathtext.fontset'] = 'stix' # 公式字体使用 STIX (类似 LaTeX)# 基础字号与线条定义:线条要粗,字要大,这就是“高级感”的来源plt.rcParams['font.size'] = 16 # 默认字号plt.rcParams['axes.linewidth'] = 1.5 # 坐标轴线宽 (Bold)plt.rcParams['lines.linewidth'] = 2.0 # 数据线宽plt.rcParams['xtick.direction'] = 'in' # 刻度朝内,更紧凑plt.rcParams['ytick.direction'] = 'in'plt.rcParams['savefig.bbox'] = 'tight' # 自动切除白边plt.rcParams['savefig.dpi'] = 600 # 印刷级分辨率
Step 2: 核心绘图函数的构建
这是最关键的一步。我们不直接写 6 次代码,而是封装一个 plot_joint_panel 函数。这个函数负责在一个给定的“大格子”里,画出主图和两个边缘图。
这里我们使用 GridSpecFromSubplotSpec,这是在子图里再分格子的神器。
def plot_joint_panel(fig, outer_grid, model_name, y_train, pred_train, y_test, pred_test): """ 在指定的 outer_grid 区域内,绘制散点+边缘密度图 """ # 1. 在当前的大格子里,再切分出 3 个小格子:中间主图,上面边缘,右边边缘 # width_ratios 和 height_ratios 决定了边缘图的相对大小 (这里是 4:1) gs_inner = gridspec.GridSpecFromSubplotSpec( 2, 2, subplot_spec=outer_grid, width_ratios=[4, 1], height_ratios=[1, 4], wspace=0.05, hspace=0.05 # 紧凑布局 ) # 2. 创建三个 Axes ax_main = fig.add_subplot(gs_inner[1, 0]) # 主散点图 ax_top = fig.add_subplot(gs_inner[0, 0], sharex=ax_main) # 顶部 X 分布 ax_right = fig.add_subplot(gs_inner[1, 1], sharey=ax_main) # 右侧 Y 分布 # 3. 绘制主散点图 (Main Scatter) # 训练集:红色,圆形 ax_main.scatter(y_train, pred_train, c='#d62728', s=15, alpha=0.7, label='train', edgecolor='w', linewidth=0.3) # 测试集:蓝色,圆形 ax_main.scatter(y_test, pred_test, c='#1f77b4', s=15, alpha=0.7, label='test', edgecolor='w', linewidth=0.3) # 添加对角线 (Identity Line) ax_main.plot([0, 1], [0, 1], color='gray', linestyle='--', alpha=0.6, linewidth=1, zorder=0) # 4. 绘制边缘密度图 (Marginal KDE) # 顶部 (X轴分布) sns.kdeplot(x=y_train, ax=ax_top, color='#d62728', fill=True, alpha=0.3, linewidth=1) sns.kdeplot(x=y_test, ax=ax_top, color='#1f77b4', fill=True, alpha=0.3, linewidth=1) # 右侧 (Y轴分布) - 注意这里是 y=...,Seaborn 会自动竖着画 sns.kdeplot(y=pred_train, ax=ax_right, color='#d62728', fill=True, alpha=0.3, linewidth=1) sns.kdeplot(y=pred_test, ax=ax_right, color='#1f77b4', fill=True, alpha=0.3, linewidth=1) # 5. 美化与清理 (Cosmetics) # 隐藏边缘图的多余坐标轴 plt.setp(ax_top.get_xticklabels(), visible=False) plt.setp(ax_top.get_yticklabels(), visible=False) plt.setp(ax_right.get_xticklabels(), visible=False) plt.setp(ax_right.get_yticklabels(), visible=False) # 去除边缘图的边框 (Spines),让图看起来更轻盈 for spine in ax_top.spines.values(): spine.set_visible(False) for spine in ax_right.spines.values(): spine.set_visible(False) # 但保留连接处的底边和左边,如果不喜欢也可以全去 ax_top.spines['bottom'].set_visible(True) ax_right.spines['left'].set_visible(True) # 标注模型名称 ax_main.text(0.5, 0.9, model_name, transform=ax_main.transAxes, ha='center', va='top', fontsize=14, fontweight='bold') # 计算并标注指标 (只算 Test 集作为示例) r2 = r2_score(y_test, pred_test) mae = mean_absolute_error(y_test, pred_test) mse = mean_squared_error(y_test, pred_test) rmse = np.sqrt(mse) text_str = f"R2: {r2:.5f}\nMAE: {mae:.5f}\nMSE: {mse:.5f}\nRMSE: {rmse:.5f}" ax_main.text(0.95, 0.05, text_str, transform=ax_main.transAxes, ha='right', va='bottom', fontsize=10, fontweight='bold', bbox=dict(facecolor='white', alpha=0.8, edgecolor='none')) # 设置范围 ax_main.set_xlim(-0.05, 1.05) ax_main.set_ylim(-0.05, 1.05) return ax_main
Step 3: 循环组装与成品输出
有了上面的 plot_joint_panel,剩下的就是遍历 6 个模型,像拼图一样把它们拼起来。
# 创建画布fig = plt.figure(figsize=(15, 10)) # 宽15,高10# 定义外部 GridSpec:2行3列outer_gs = gridspec.GridSpec(2, 3, figure=fig, wspace=0.25, hspace=0.3)# 循环绘制axes_list = []for i, name in enumerate(models): # 获取数据 y_train, pred_train = data_dict[name]['train'] y_test, pred_test = data_dict[name]['test'] # 调用核心函数,传入当前的格子位置 outer_gs[i] ax = plot_joint_panel(fig, outer_gs[i], name, y_train, pred_train, y_test, pred_test) axes_list.append(ax)# 添加统一的图例 (只在第一个图加,或者统一放在外面)# 这里我们手动给第一个图加图例axes_list[0].legend(loc='upper left', frameon=False, handletextpad=0.1)# 添加全局坐标轴标签 (如果不想要每个子图都写 label)# 简单的做法是直接在每个 ax 上设,但为了整洁,我们只在边缘的图设for i, ax in enumerate(axes_list): # 第一列加 Y labelif i % 3 == 0: ax.set_ylabel('y ML (Predicted)', fontsize=12, fontweight='bold') # 最后一行加 X labelif i >= 3: ax.set_xlabel('y Experimental (True)', fontsize=12, fontweight='bold')# 保存图片plt.savefig('Comparison_SOP_Replication.png', dpi=300, bbox_inches='tight')plt.show()print("✅ 复刻完成!图片已保存。")
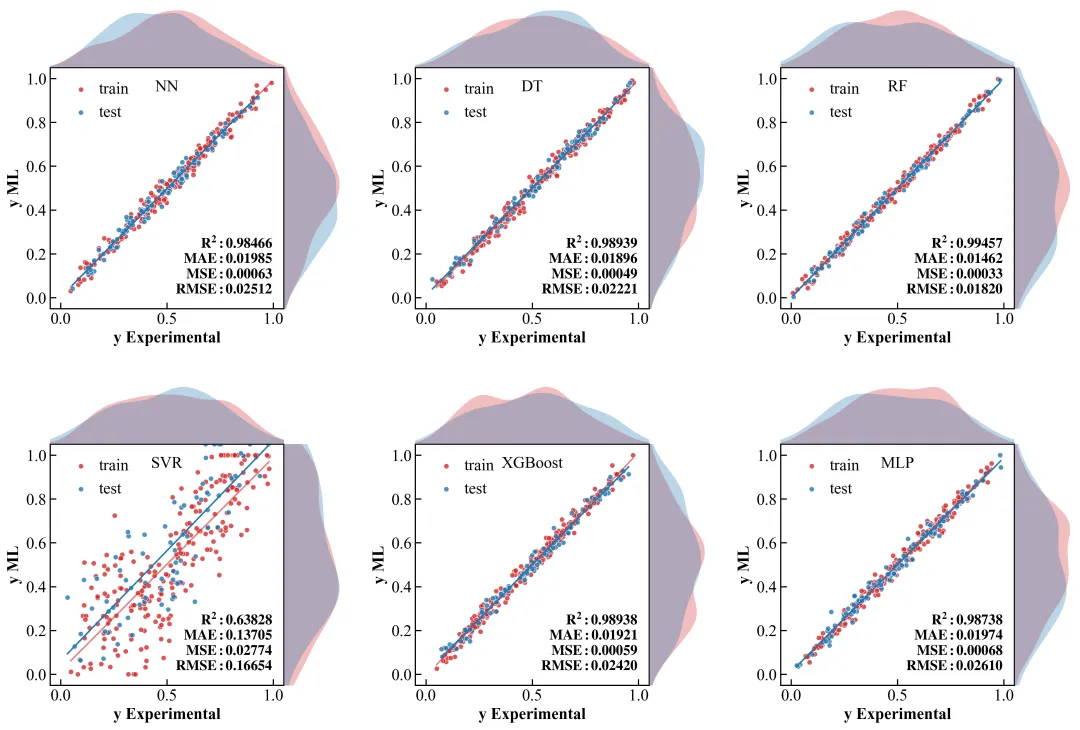
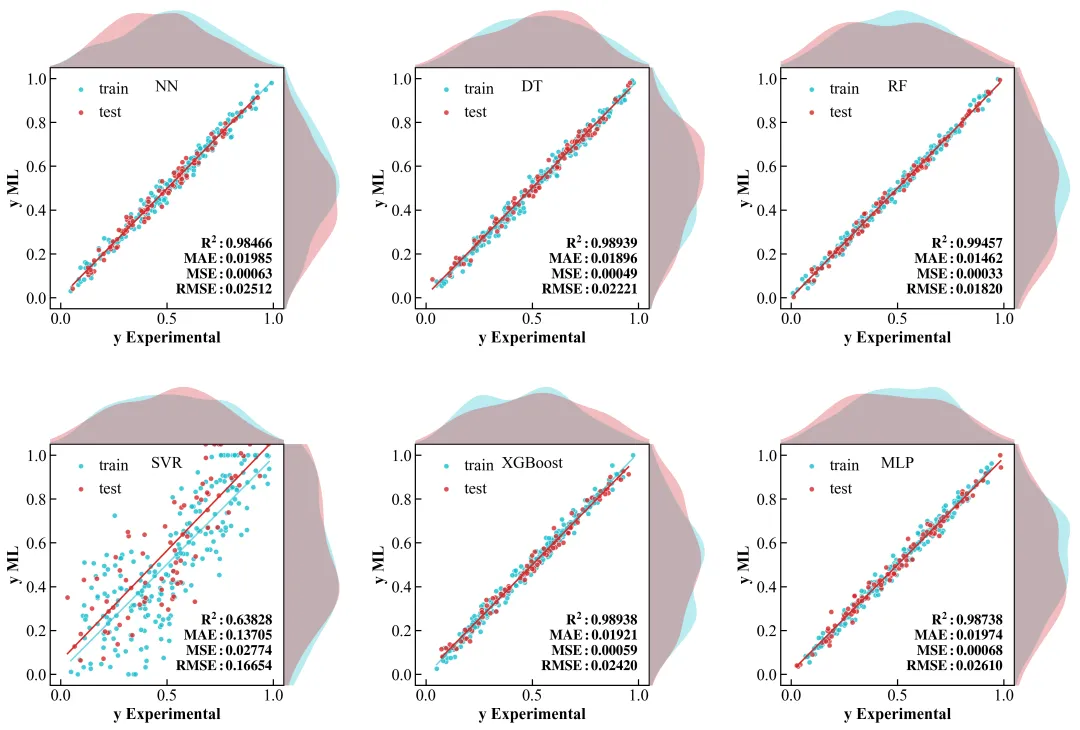
复刻图
运行上述代码,你会得到一张几乎可以乱真的顶刊级复刻图。
记住:工具(Python)只是画笔,逻辑(数据分布+模型验证)才是画魂。这张图之所以好,是因为它诚实地展示了数据在每一维度的样子,而不是试图用一个单纯的 R2 值去粉饰太平。
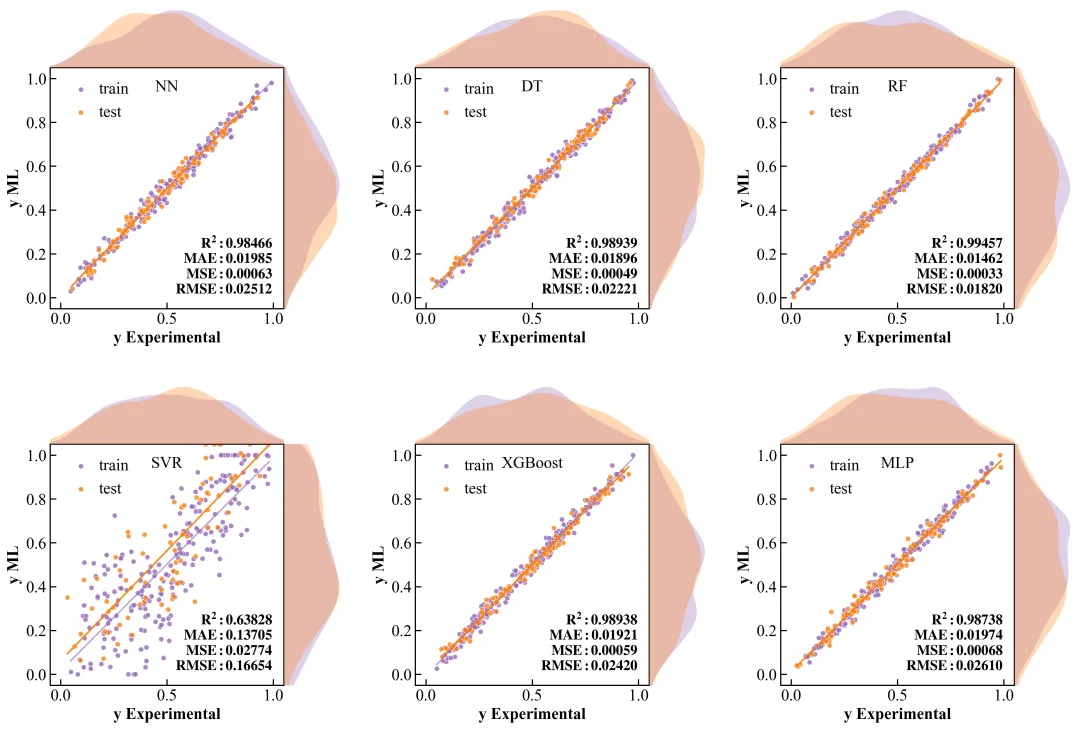
多配色参考
👇 关注公众号【嗡嗡的Python日常】
🚫 关于源码: 本文核心代码为原创定制,暂不免费公开。
✅ 如果你需要:
购买本项目完整源码 + 数据
定制类似的科研绘图
咨询代码运行报错问题
请直接添加号主微信沟通(有偿分享☕️): Wjtaiztt0406