#从零开始构建轻量级Python爬虫框架:异步并发实战指南>技术栈:asyncio、aiohttp、Redis、MySQL##📖 前言
在数据采集的世界里,效率就是生命。传统的同步爬虫在面对大规模数据采集时往往力不从心,而本文将带你深入了解一个**生产级轻量级异步爬虫框架**的完整设计与实现。###框架核心特性
- ✅ 双模式执行:批量执行(历史采集)+ 定时执行(增量采集)
- ✅ 高并发+分布式:异步协程 + Redis队列,支持多机部署
- ✅ 灵活入库:支持单表/多表、批量/逐条、自动去重
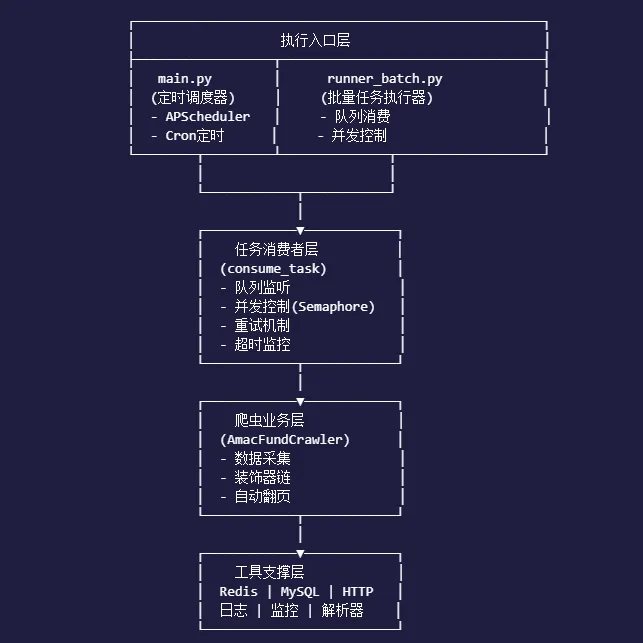
##🎯 框架架构总览
###四层架构设计
本框架采用分层解耦的设计理念,从上到下分为四层:
runner_batch.py:批量执行器,用于历史采集
- 装饰器链:@async_request → @parse_response → @save_into_mysql
##🚀 核心特性一:双模式执行
###模式1:runner_batch.py(批量执行-历史采集)
**核心代码**(runner_batch.py:185-218):async def main(): # 1. 初始化Redis连接池 await RedisManager.initialize() RedisManager.start_daemon() # 2. 初始化MySQL连接池 mysql_manager = MySQLManager(MYSQL_CONF) await mysql_manager.init_pool() # 3. 启动资源监控(后台任务) monitor_task = asyncio.create_task( monitor.monitor_process_resources(interval=5) ) # 4. 创建消费者协程 consumers = [] for t in TASKS: workers = t.get("workers", 1) for i in range(workers): consumers.append(consume_task(...)) # 5. 并发执行所有消费者 await asyncio.gather(*consumers)
**任务配置**(runner_batch.py:176-182):TASKS = [ { "key": "amacfund:fund_detail", "func": amac_fund_crawler.get_fund_detail, "log": "基金详情", "field": "fund_id", "workers": 20, # 20个并发协程 "limit": 20, # 信号量限制 "need_paging": False }]
###模式2:main.py(定时调度-增量采集)
async def main(): scheduler = AsyncIOScheduler() # 添加定时任务(每天7:00执行) scheduler.add_job( run_task, CronTrigger(hour=7, minute=0), id='amacfund_crawler', name='基金数据采集' ) scheduler.start() await asyncio.Event().wait()
# 每天7:00CronTrigger(hour=7, minute=0)# 每小时CronTrigger(minute=0)# 每5分钟CronTrigger(minute='*/5')# 工作日9:00CronTrigger(day_of_week='mon-fri', hour=9, minute=0)
###两种模式对比
|特性|runner_batch.py|main.py||---------|----------------|---------|
|执行方式|立即执行,队列消费完退出|定时执行,持续运行||启动命令|`python runner_batch.py`|`python main.py`||典型用例|采集过去10年基金数据|每天采集昨日新增|---
##🔥 核心特性二:高并发+分布式+断点续采
###1. 异步高并发
**核心机制**:asyncio协程 + Semaphore信号量**代码实现**(runner_batch.py:103-106):async with sem: # 信号量控制并发 result = await asyncio.wait_for( crawler_func(**params), timeout=timeout )
**并发控制**(runner_batch.py:44-45):if task_key not in task_locks: task_locks[task_key] = asyncio.Semaphore(limit)
-配置`workers=20, limit=20`:20个协程并发执行-配置`workers=50, limit=20`:50个协程轮流使用20个并发槽位###2. 分布式部署
机器1 (runner_batch.py) ──┐ ├──→ Redis队列 ←──→ MySQL机器2 (runner_batch.py) ──┤ │机器3 (runner_batch.py) ──┘
# 机器1python runner_batch.py# 机器2python runner_batch.py# 机器3python runner_batch.py```
###3. 断点续采
**优雅退出**(runner_batch.py:153-170):async def shutdown(): stop_flag = True # 未完成任务放回队列 for task_key, record in running_tasks: await RedisManager.lpush(retry_key, record) # 关闭数据库连接 mysql_manager.mysql.close() await mysql_manager.mysql.wait_closed()
**重试机制**(runner_batch.py:100-122):# 重试3次,指数退避for attempt inrange(max_retries): try: result = await crawler_func(**params) break except Exception as e: if attempt < max_retries: await asyncio.sleep(retry_delay * attempt)# 失败后放入重试队列if attempt >= max_retries: await RedisManager.lpush(retry_key, json.dumps(params))
**队列超时监控**(runner_batch.py:57-70):# 2小时无新任务,自动停止if time_since_last_activity > QUEUE_TIMEOUT: task_stop_flags[task_key] = True break
##📊 核心特性三:资源监控
**实时监控**(monitor.py:30-82):async def monitor_process_resources(interval=5): process = psutil.Process(os.getpid()) while True: # 内存使用 memory_mb = process.memory_info().rss / 1024 / 1024 # CPU使用率 cpu_usage = (current_cpu_time - last_cpu_time) / (current_time - last_time) * 100 # 线程数 num_threads = process.num_threads() logging.info(f"{timestamp} | 内存:{memory_mb:.2f}MB | CPU:{cpu_usage:.1f}% | 线程:{num_threads}") await asyncio.sleep(interval)
14:23:15 | 内存:156.32MB | CPU:28.5% | 线程:25
14:23:20 | 内存:158.47MB | CPU:31.2% | 线程:25
14:23:25 | 内存:159.81MB | CPU:29.8% | 线程:25
##💾 核心特性四:灵活入库机制
###1. 装饰器设计
**完整装饰器链**(crawler/amac_fund.py:63-79):@save_into_mysql(table_name="fund_info", unique_key="pmid")@parse_response(parse_fund_detail, extra_args=["self", "**kwargs"])@async_request(method="GET", delay=0.1, if_proxy=True)async def get_fund_detail(self, fund_id, **kwargs): url = AMAC_FUND_DETAIL_API.format(fund_id=fund_id) return { "url": url, "headers": {}, "crawler": self }
1. get_fund_detail() 返回请求参数 ↓2. @async_request 发送HTTP请求 ↓3. @parse_response 解析响应数据 ↓4. @save_into_mysql 保存到数据库
###2. 自动去重机制
**实现方式**(mysql_manager.py:186-216):async def _process_single_row(conn, cursor, row): # 1. 检查记录是否存在 check_sql = f"SELECT 1 FROM {table} WHERE {unique_key} = %s" exists = await cursor.fetchone() if exists: # 2. 存在则UPDATE update_sql = f"UPDATE {table} SET ... WHERE {unique_key}=%s" await cursor.execute(update_sql, values) else: # 3. 不存在则INSERT insert_sql = f"INSERT INTO {table} (...) VALUES (...)" await cursor.execute(insert_sql, values)
###3. 降级策略
**批量插入失败时降级为逐条插入**(mysql_manager.py:265-279):# 先尝试批量插入success = await _execute_batch_all()if not success and enable_fallback: # 降级:逐条插入 for row in rows: if not await _execute_single(row): failed_records.append(row)
###4. 失败记录持久化
**保存失败记录到本地**(mysql_manager.py:301-328):async def _save_failed_records(table, failed_records): filename = f"logs/failed_records/{table}_{timestamp}.json" with open(filename, 'w', encoding='utf-8') as f: json.dump({ "table": table, "count": len(failed_records), "records": failed_records }, f, ensure_ascii=False, indent=2)
##🧩 核心特性五:模块解耦
###1. 装饰器职责分离
**@async_request**(utils/http.py:26-108):**@parse_response**(utils/parsers.py:92-165):**@save_into_mysql**(utils/mysql_manager.py:84-158):###2. 解析器独立
**列表页解析**(utils/parsers.py:168-210):async def parse_fund_list(data, crawler, **kwargs): records = data.get('content', []) result = [] for record in records: fund_info = { 'fund_id': record.get("id"), 'fund_name': record.get("fundName"), ... } result.append(fund_info) # 推送详情任务到队列 await crawler.redis.lpush( "amacfund:fund_detail", json.dumps(fund_info) ) return result
**详情页解析**(utils/parsers.py:213-253):async def parse_fund_detail(response, crawler, **kwargs): soup = BeautifulSoup(response, 'html.parser') fund_info = {} rows = soup.select('div.info-body table.table tr') for row in rows: cells = row.find_all('td') title = cells[0].get_text(strip=True) value = cells[1].get_text(strip=True) if title == '基金类型': fund_info['fund_type'] = value ... return fund_info
##📝 核心特性六:完善日志
###1. 结构化日志
logging.info(f"✅ 采集成功 | 基金ID: {fund_id} | 耗时: {elapsed}s")logging.error(f"❌ 采集失败 | 基金ID: {fund_id} | 错误: {error}")logging.warning(f"⏰ 队列超时 | 队列: {task_key} | 超时: {timeout}s")
###2. 日志分级
**配置**(utils/logger_config.py):# INFO级别:正常日志logging.basicConfig(level=logging.INFO)# ERROR级别:错误日志(单独文件)setup_error_logger()
###3. 失败记录
{ "table": "fund_info", "timestamp": "20260212_143025", "count": 5, "records": [ {"fund_id": "123", "fund_name": "xxx"} ]}
##🎯 实战案例:基金数据采集
###完整流程
redis-cli LPUSH amacfund:amac_fund_list '{"page": 0, "page_size": 20}'
消费列表任务 ↓解析列表页(20条基金) ↓推送20个详情任务到队列 ↓20个协程并发消费详情任务 ↓解析详情页 ↓保存到MySQL ↓继续消费下一页
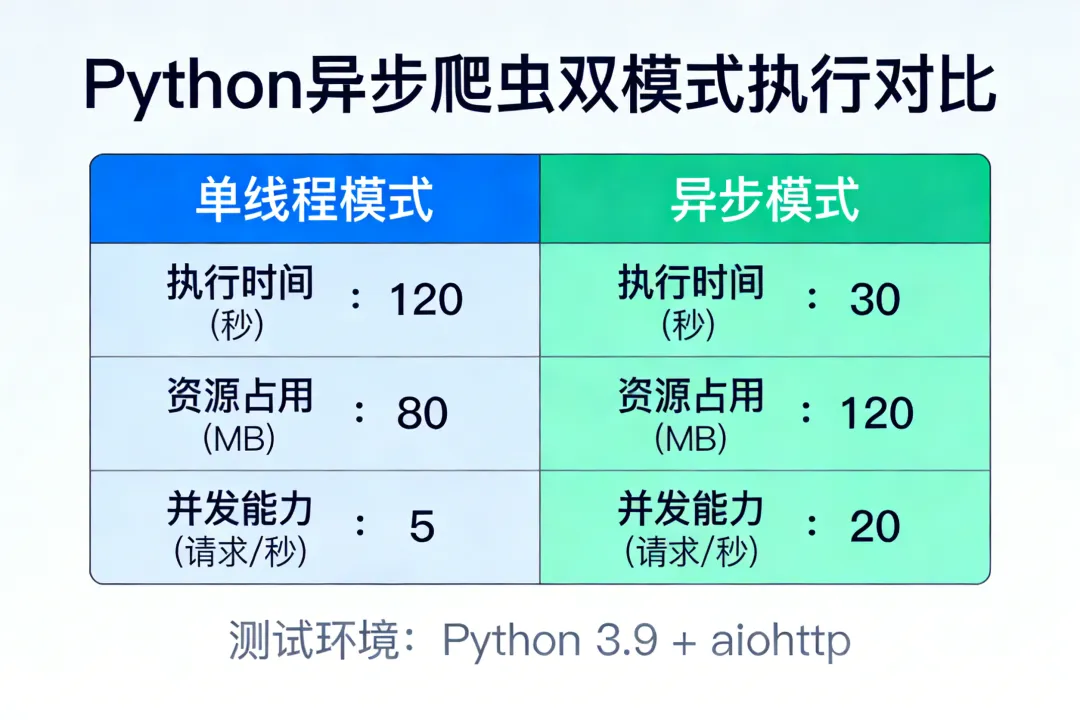
###性能数据
|------|------|
---
##💡 总结
###框架核心优势
1.**双模式执行**:批量+定时,覆盖历史采集和增量更新2.**高并发+分布式**:异步协程+Redis队列,支持多机部署3.**断点续采**:任务持久化+优雅退出+自动重试5.**灵活入库**:自动去重+降级策略+失败持久化###适用场景
---
*本文示例代码已开源,有需要可私信或留言,欢迎 Star ⭐*

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
