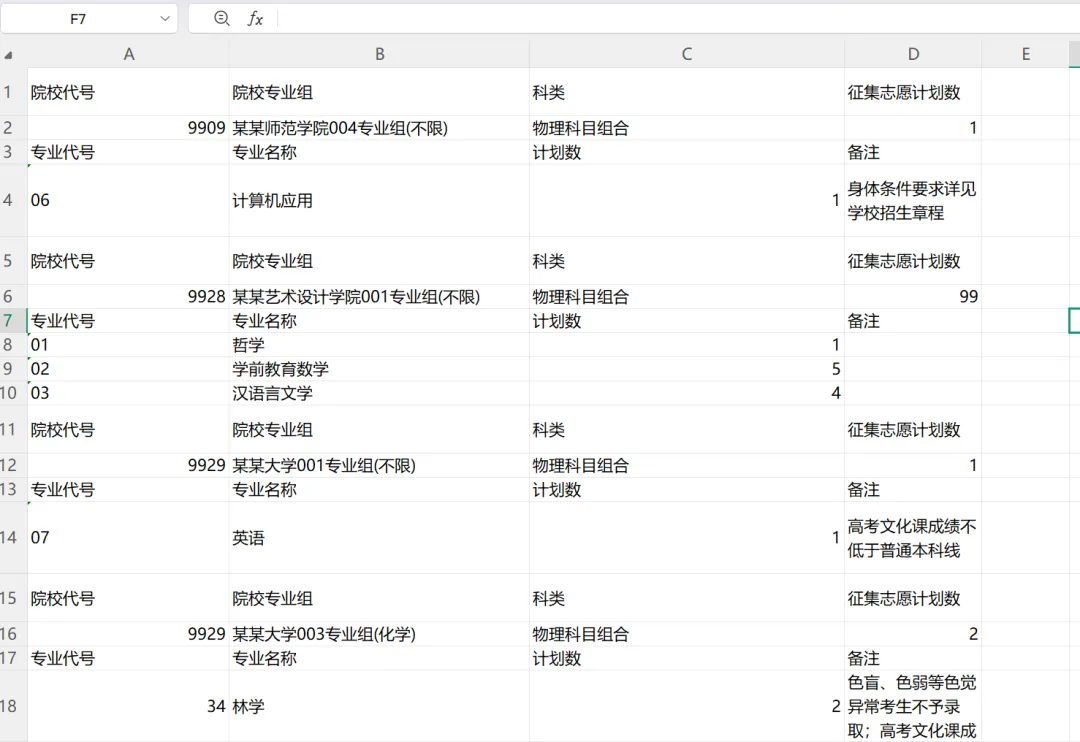
在处理招生计划、财务报表或库存清单时,我们经常会遇到一种“令人头疼”的 Excel 格式:院校信息(父层级)占据一行,其下紧跟着数个专业信息(子层级)。比如这样:
这种格式虽然方便人类阅读,但在数据分析时却无法直接筛选或透视。今天我们分享如何利用 Python 的 pandas 库,通过“状态机”逻辑,将这种嵌套数据扁平化。
今天,教你用 Python 瞬间完成“降维打击”,把这种嵌套 Excel 变成标准的一行一稿。
一、 痛点分析:为什么你的 Excel 难处理?
传统的 Excel 处理逻辑是“横向”的,但这类数据是**“纵向关联”**。
手动操作?复制、粘贴、填充……如果数据有 5000 行,怕是下班天都黑了。
二、 核心思想:逻辑“广播”法
让 Python 像“扫描仪”一样工作:
- 持续填充: 只要没遇到下一个院校,就把当前记住的信息拼在专业数据前面。
三、 Python 自动化代码实现
直接上干货!只需安装 pandas 库,运行以下脚本:
import pandas as pd
deffast_clean_excel(input_file):
# 1. 读取数据 (header=None 保证不漏掉任何一行)
df = pd.read_excel(input_file, header=None)
clean_data = []
current_school = None# 这里的变量就像我们的“短期记忆”
for _, row in df.iterrows():
# 排除表头干扰
if"代号"in str(row[0]):
continue
# 判定逻辑:院校行的特征是第二列含有“专业组”
if"专业组"in str(row[1]):
# 更新“短期记忆”:暂存院校信息
current_school = row[0:4].tolist()
else:
# 遇到专业行:将“记忆”中的院校+当前专业拼接
current_major = row[0:4].tolist()
full_row = current_school + current_major
clean_data.append(full_row)
# 2. 定义清洗后的标准表头
columns = ['院校代号', '院校专业组', '科类', '总计划',
'专业代号', '专业名称', '专业计划', '备注']
# 3. 生成并保存
result_df = pd.DataFrame(clean_data, columns=columns)
result_df.to_excel("清洗完成结果.xlsx", index=False)
print(" 处理完成!请在当前文件夹查看结果。")
# 运行
fast_clean_excel('data0211.xlsx')
四、 为什么这个方法更高级?
- 容错性强: 即使院校下面的专业数量不固定(有的 1 个,有的 10 个),代码也能自动适配。
五、 运行后的结果:
在这个数据驱动的时代,“自动化”不是为了取代人,而是为了让人从繁琐的机械劳动中解放出来。 如果你也经常被类似的 Excel 格式折磨,不妨试一试这个 Python 小脚本。遇到问题,欢迎在评论区交流!
🎁 你还遇到过哪些难搞的 Excel 格式?留言告诉我,下一期或许就是你的定制教程!
🔮 获取和交流
需要源码和数据的同学,关注+三连,加下面微信,发你!也可以拉你进群交流学习,加群备注:IT小本本学习
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
