为什么需要Linux内核?
早期处理器(如8086、80286、80386)能力较弱,通常只能运行一个单循环程序来处理所有任务。那时从汇编语言升级到 C 语言编程已属不易,任务简单,即便整体崩溃影响也有限。
随着处理器能力增强,系统可同时运行多个任务,且这些任务的归属方往往不同。若任务A 影响了任务 B,问题定位困难,互相推诿成为常态。操作系统因此诞生,核心目标之一就是隔离与管理任务。
处理器的指令集逐步分化为不同特权级别(x86:Ring 0~3;ARM:EL0~EL3;RISC-V:U/S/M)。指令总体上可分为两类:
• 普通指令:无特殊权限,无法访问关键硬件资源
• 特权指令:可操作中断控制器、MMU 页表等,直接影响系统稳定性
操作系统的内核是唯一被允许执行特权指令的软件实体。
用户态任务通过系统调用进入内核,彼此之间只能通过进程间通信(IPC)交互,无法直接破坏内核或其他进程。这是现代操作系统设计的核心隔离理念。
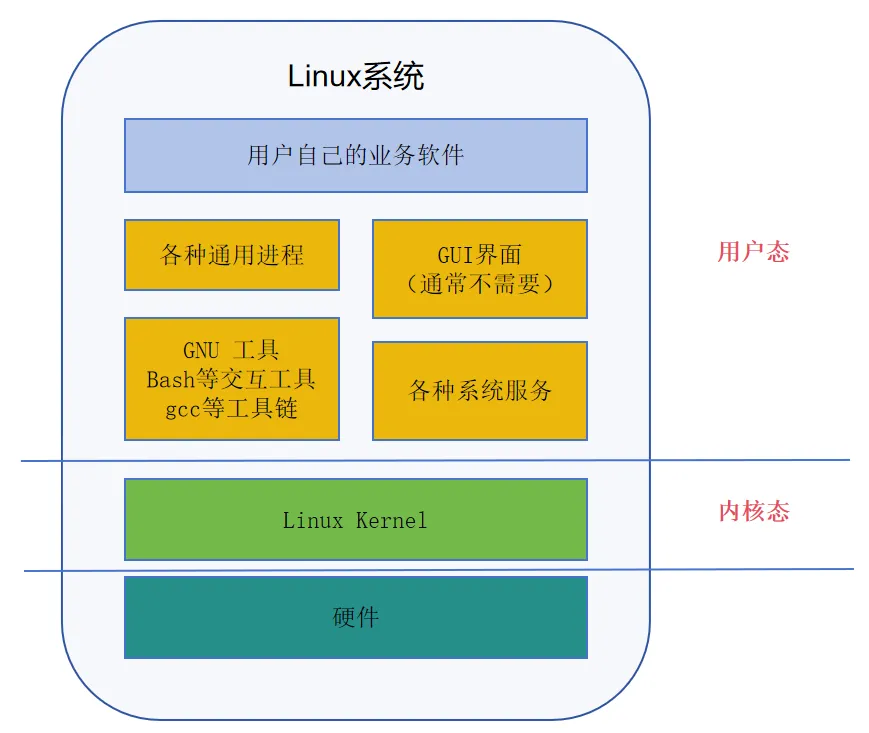
所以大体的一个Linux系统是下图这样,最下面是硬件,包括处理器和各种外围设备,硬件上面是Linux内核和内核态的各种驱动和内核模块,再上面就是各种各样的进程,呈现各种不同的用户界面,但是都是在用户态运行。
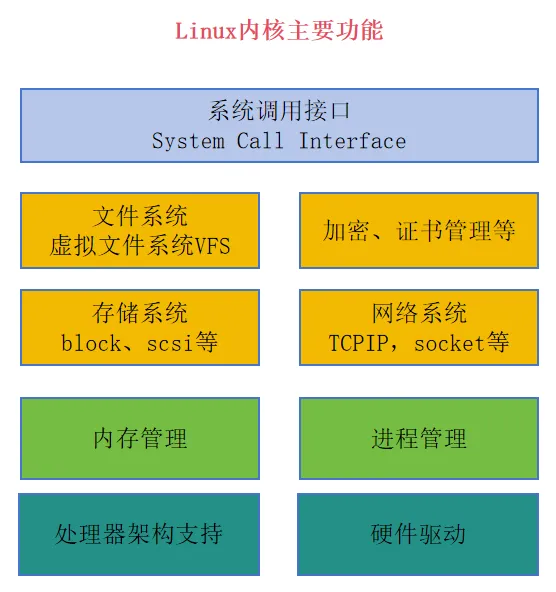
Linux内核主要功能
下图展示了Linux内核的一些主要功能模块,不是全部。
从下图也可以更清楚地看到Linux宏内核的特征,绿色的进程管理和内存管理应该是一个操作系统内核的核心,黄色的这些模块(如文件系统、网络协议栈等)在微内核架构中通常作为用户态服务实现,而 Linux 作为宏内核,将它们全部集成在内核态,因此被称为宏内核。
这些内核模块没有上下层级的概念,都属于一个层次,彼此可以互相调用。
各模块简要说明:
内存管理:基于MMU 实现进程地址空间隔离,是进程隔离的硬件基础
存储系统:Block 层位于上层文件系统与底层设备驱动之间,向上提供统一接口,向下通过不同驱动(如 SCSI、NVMe)适配各类硬件。
文件系统:文件系统通常构建于块设备之上,但也有基于内存(tmpfs)、网络(NFS)或特殊设备(proc、sysfs)的文件系统,支持ext4、XFS、NFS、tmpfs 等,通过 VFS 提供统一接口,Linux支持了很多种类的文件系统,这些文件系统统一通过虚拟文件系统VFS进行了抽象,这样上面的进程程序编写代码时,不需要关心具体是哪个文件系统(比如ext4、NTFS等),读写接口都是统一的。
网络系统:管理网络设备,实现TCP/IP 协议栈,提供 Socket 系统调用。TCP/IP 协议栈具有极高的网络兼容性要求,因此 Linux 内核长期维护并优化其 TCP/IP 实现,难以用其他协议栈替代。
加密模块:内核Crypto API,支持对称/非对称加密、哈希等,广泛用于 IPsec、dm-crypt 等。
设备驱动:字符设备、块设备、网络设备等的驱动程序,Linux 内核主线已包含大量通用设备驱动,芯片厂商通常以内核模块形式提供板级支持包(BSP)或通过 upstream 方式提交驱动代码;
基本上Linux内核覆盖了当前IT领域的各种基础需求,用户只需要针对性开发自己特有的部分,避免了相同功能的重复开发,我们都需要感谢Linux。
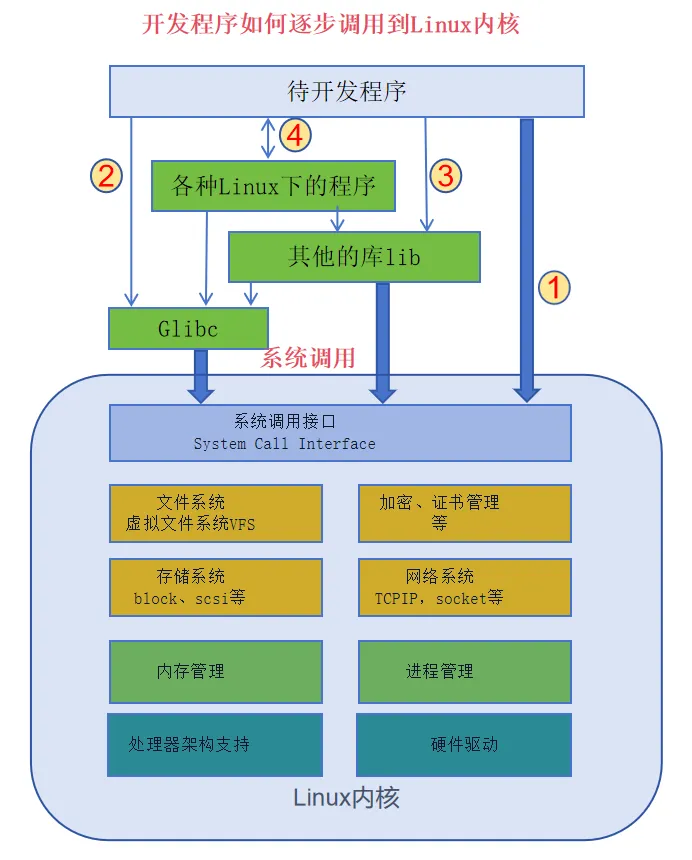
Linux内核是如何对外提供服务的?
Linux内核通过系统调用接口(System Call Interface)对上面的用户态程序提供支持。
但是我们实际编程的时候,很少会直接使用系统调用接口,那是因为glibc库已经基于系统调用接口封装好了更容易调用的glibc提供的库函数api。
下图展示了如果我们新开发一个C语言程序,一般有3种函数调用的方式:
Linux内核提供的系统调用,这个调用一般不推荐使用
Glibc提供的api,这是最常用的方式,符合POSIX接口标准,glibc(GNU C Library) 是 GNU 项目提供的 C 标准库 + POSIX 接口的主流实现,glibc就是上一篇提到的GNU的项目输出,glibc会进行系统调用)
其他软件也可以做成类似glibc的库,提供api供其他程序调用
还有一种方式,图中的4,程序之间通过进程间通信或网络通讯等方式进行交互。
总结一下这4种方式:
1.直接系统调用(不推荐,需处理架构差异与 errno)
2. glibc 封装 API(最常用,符合 POSIX 标准)
3. 其他第三方库(如 libuv、libevent)
4. 进程间通信/网络通信(不经过内核接口,但依赖内核IPC 机制)
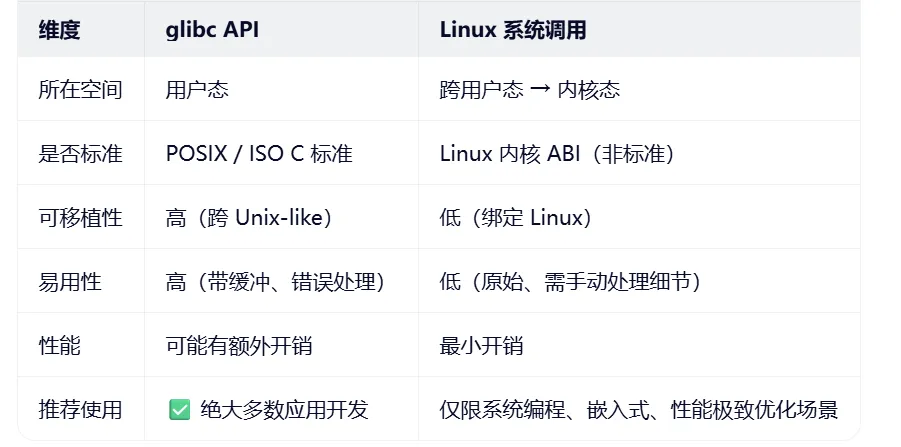
通常的C语言编程,推荐使用glibc,而不是Linux系统调用,可以看一下千问总结的二者的区别
顺便提一下POSIX标准
POSIX = Portable Operating System Interface + X
(可移植操作系统接口)(表示Unix传统)
POSIX是由IEEE主导制定,得到ISO国际认可,并由多组织共同维护的开放系统接口标准。它的诞生解决了Unix分裂带来的兼容性问题,如今已成为跨平台系统编程的事实标准。当你使用Linux的write()、fork()、open()等接口时,你正在使用的正是这个30多年前确立的标准。
同时也了解一下,Linux下,除了glibc之外,也有其他的常用库可以选择。
举例说明:一个写磁盘操作的过程
假设要写几个字符(字节)到一个已经打开的文件中,那么在用户态程序(软件)编程的主要过程是这样的:
用户态执行路径:
1,调用glibc的write函数:ssize_t ret = write(fd, buffer, size);
2,Glibc 内部调用 syscall() 函数:ssize_t ret = syscall(SYS_write, fd, buffer, size);
------ 用户态 ↔ 内核态切换点 ------
内核态执行路径:
3. 系统调用入口 → sys_write()
4. VFS 层 → vfs_write(),定位具体文件系统;文件是属于文件系统的,Linux实现了一个虚拟文件系统VFS,所以在Linux内核情况下,sys_write会先调用到vfs的write
5. 文件系统层(如 ext4)→ ext4_file_write_iter(),从VFS再定向到特定的文件系统比如ext4对应的write操作;
6. 块设备层(Block Layer)→ 提交 I/O 请求到块设备队列;文件系统是构建在块设备block上的,所以write操作最终会调用到块设备block层的write操作;
7. 设备驱动层(如 SCSI 驱动 sd)→ 与硬件控制器交互;块设备block的write操作又会根据块设备具体的驱动,比如磁盘挂载的SCSI 控制器(SAS、SATA等)的驱动,调用到对应驱动的一系列操作,最终完成写入文件对应的最终磁盘上;
8. 硬件控制器(SAS / SATA / NVMe)→ 与磁盘固件通信,完成物理写入
然后逐级返回,支持同步/异步完成通知。
【说明】
• 磁盘固件与控制器之间的协议交互不属于 Linux 内核,内核只负责驱动侧实现
• 本例假设文件已打开;若未打开,需先调用 open(),并可能需要 lseek() 定位写入位置
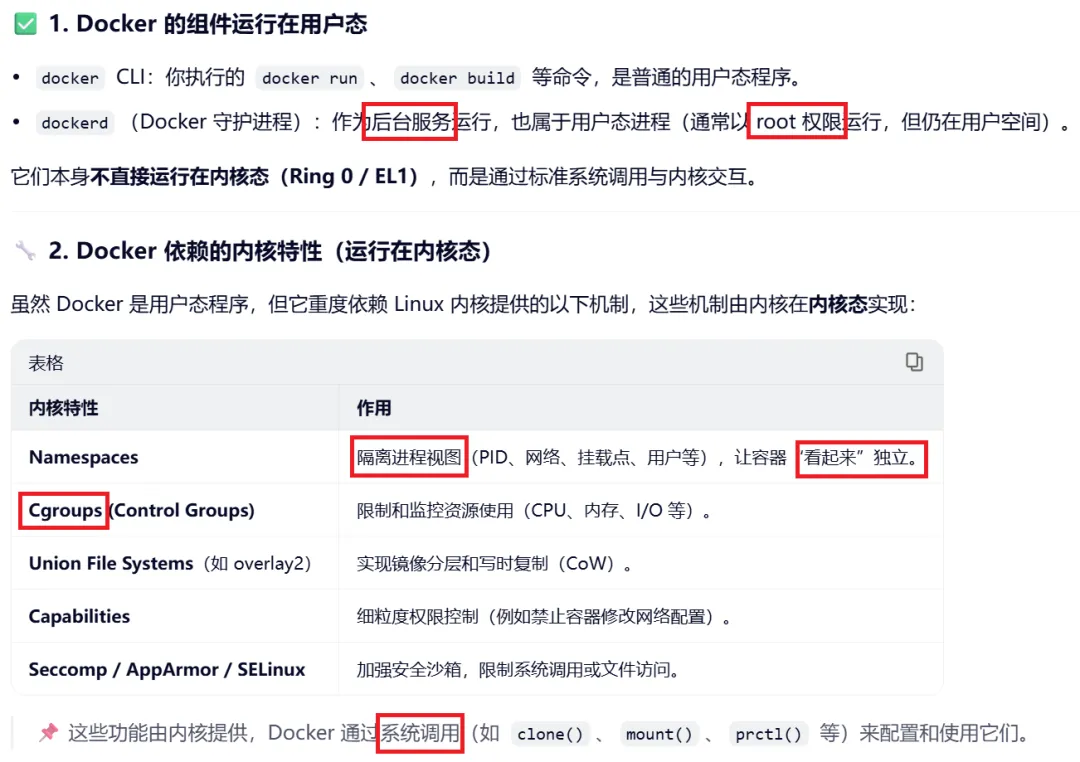
Docker容器在用户态
现在AI Agent使用较多的docker容器,功能比较强大,但其实也是在用户态的。但容器的隔离与资源限制完全由内核提供,因此“容器在用户态”是指进程执行级别,而非容器实现不依赖内核
一个Docker 容器本质上是由 Namespaces 提供隔离、Cgroups 提供资源限制的一组普通 Linux 进程。
这些进程仍然运行在用户态,但被内核“隔离”和“限制”了。
容器内的应用代码(比如你的Python 或 Nginx)和宿主机上的普通用户程序一样,运行在 CPU 的用户态(如 x86 的 Ring 3,ARM64 的 EL0)。
下面是千问总结的Docker信息:
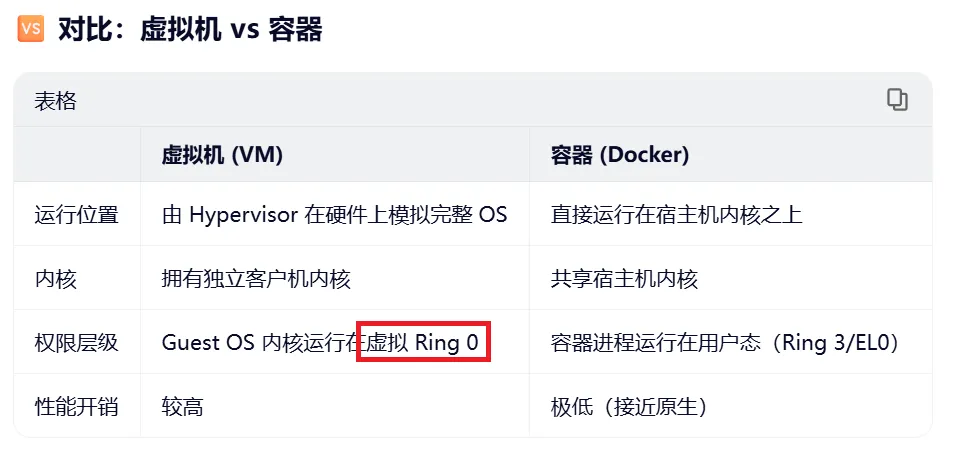
顺便对比一下容器与虚拟机的区别:

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
