在机器学习领域,我们常常会遇到这样的问题:训练好的模型能给出预测结果,却无法说清 “为什么这么预测”。尤其是随机森林、XGBoost 这类复杂模型,就像一个 “黑盒”,内部决策逻辑难以捉摸。而今天要介绍的 Python 库 ——Dalex,正是打破这个 “黑盒” 的利器,它能帮我们清晰解读模型行为,让每一次预测都有理可依。
Dalex 是什么?
Dalex(Descriptive mAchine Learning EXplanations)是一款专为提升机器学习模型可解释性设计的 Python 库。它不局限于特定模型框架,无论是 scikit-learn、XGBoost,还是 Keras、PyTorch 构建的模型,都能通过 Dalex 进行解析。
其核心作用就是 “打开黑盒”:从全局层面分析模型的整体表现、特征重要性,到局部层面解读单个预测结果的成因,让数据科学家、分析师甚至业务人员都能看懂模型的决策逻辑,进而提升对模型的信任度,也方便后续的模型优化与问题排查。
Dalex 怎么用?
一、安装步骤
Dalex 的安装非常简单,只需通过 Python 的包管理器 pip 一行命令即可完成:
这条命令会自动安装 Dalex 及其所有依赖包,无需额外配置,安装完成后就能直接在代码中调用。
二、核心功能模块
Dalex 的功能围绕 “模型解释” 展开,主要分为三大类,每类都有对应的核心函数,上手门槛低,且支持交互式可视化,结果直观易懂。
1. 全局解释:掌握模型整体情况
全局解释主要用于分析模型的整体行为,比如哪些特征对预测结果影响最大、模型在不同数据上的表现是否稳定。核心函数包括:
model_parts()model_performance()评估模型性能,生成残差分布、准确率等指标,诊断模型是否存在过拟合或欠拟合;model_profile()绘制部分依赖图(PDP),展示单个或两个特征对预测结果的影响趋势。
2. 局部解释:拆解单个预测结果
当你想知道 “为什么这个样本会被预测为正类”“哪个特征导致了这次预测误差” 时,就需要局部解释。核心函数是predict_parts(),它支持两种主流解释方法:
- SHAP 值:通过博弈论的思路,计算每个特征对预测结果的贡献度,正负贡献一目了然;
- LIME:构建局部线性模型,模拟样本附近的决策边界,解释该样本的预测逻辑。
3. 模型对比:选出更优方案
当你同时训练了多个模型(比如两个不同参数的 XGBoost 模型),想知道哪个更可靠时,Dalex 的plot_model_comparison()函数能帮上忙。它会从特征重要性、预测稳定性等维度,直观对比不同模型的表现,辅助你做出选择。
实战案例:用 Dalex 解析鸢尾花分类模型
下面我们以经典的鸢尾花分类任务为例,一步步展示 Dalex 的使用流程。整个案例基于 XGBoost 模型,带你体验特征重要性分析和部分依赖图的绘制。
步骤 1:准备数据与训练模型
首先加载鸢尾花数据集,划分训练集和测试集,并用 XGBoost 训练一个分类模型:
import dalex as dximport xgboost as xgbfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets import load_iris# 1. 加载并处理数据data = load_iris()X = data.data # 特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度y = data.target # 标签:鸢尾花品种feature_names = data.feature_names # 特征名称,方便后续解读# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 2. 训练XGBoost分类模型model = xgb.XGBClassifier(random_state=42)model.fit(X_train,y_train)
步骤 2:创建 Dalex 解释器
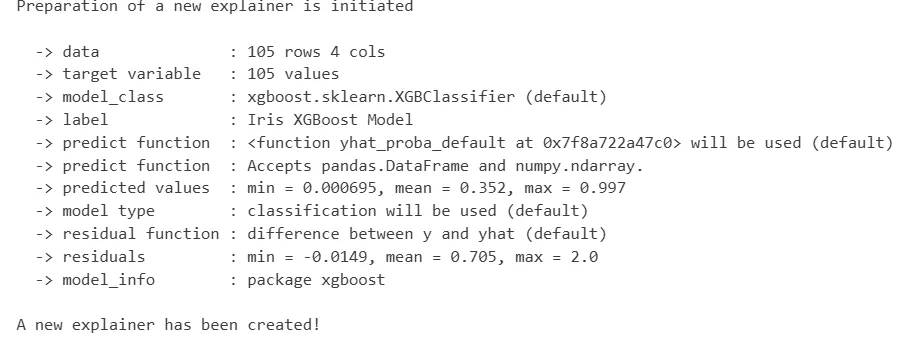
这是使用 Dalex 的关键一步,通过dx.Explainer()函数包装模型和训练数据,生成解释器对象,后续的所有分析都基于这个对象展开:
# 创建解释器,指定模型、训练数据、训练标签和特征名称import pandas as pdX_train_df = pd.DataFrame(X_train, columns=feature_names)exp = dx.Explainer( model=model, data=X_train_df, y=y_train, label="Iris XGBoost Model" # 模型标签,方便区分多个模型)
返回:A new explainer has been created!表明解释器被初始化成功
步骤 3:分析特征重要性
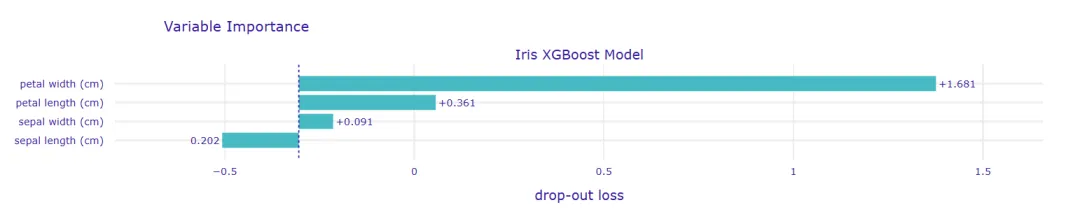
用model_parts()函数计算特征重要性,并通过plot()方法可视化结果:
# 计算特征重要性fi = exp.model_parts()# 可视化特征重要性fi.plot()
运行后会生成一张条形图,从图中可以清晰看到:“花瓣长度” 和 “花瓣宽度” 是影响鸢尾花分类的关键特征,而 “花萼宽度” 的影响相对较小。这个结论与鸢尾花的生物学特性完全一致,也验证了模型的合理性。
步骤 4:绘制部分依赖图(PDP)
想进一步了解 “花瓣长度” 如何影响分类结果?用model_profile()函数绘制部分依赖图:
# 生成“花瓣长度”的部分依赖图pdp = exp.model_profile(variables=["petal length (cm)"])# 可视化部分依赖图pdp.plot()
部分依赖图展示了 “花瓣长度” 在不同取值时,模型预测各类鸢尾花的概率变化。比如当花瓣长度小于 2cm 时,模型预测为 “山鸢尾” 的概率接近 100%;当花瓣长度大于 5cm 时,预测为 “维吉尼亚鸢尾” 的概率显著上升 —— 这让模型的决策逻辑变得清晰可见。
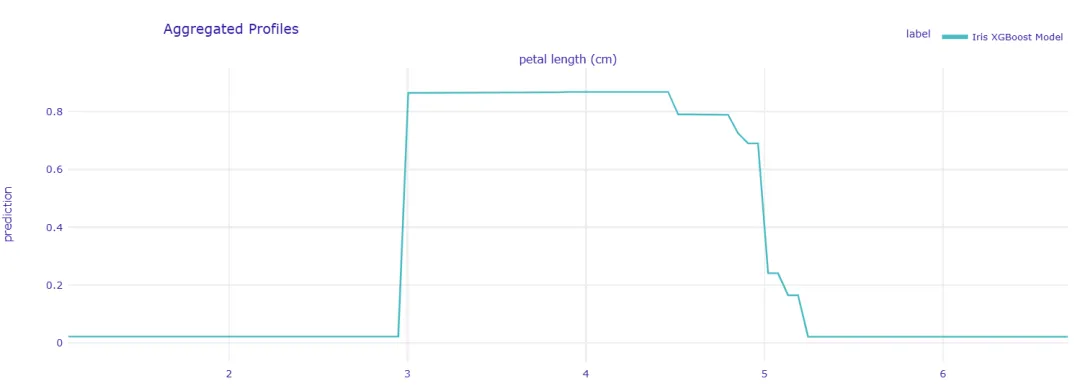 阶梯状曲线表明XGBoost模型通过多个分裂点将花瓣长度划分为不同的区间,每个区间对应不同的类别预测概率。
阶梯状曲线表明XGBoost模型通过多个分裂点将花瓣长度划分为不同的区间,每个区间对应不同的类别预测概率。
Dalex 的优势与局限性
优势
- 兼容性强支持几乎所有主流机器学习框架,无需因模型类型更换解释工具;
- 操作简单API 设计简洁,核心功能只需几行代码就能实现,且可视化结果默认样式美观,无需额外调整;
- 解释全面既支持全局分析,又能深入局部解读,满足不同场景下的解释需求。
局限性
- 对于超大规模数据集(如千万级样本),部分函数(如
model_profile())运行速度会较慢,需要适当采样; - 目前对深度学习模型的支持虽已覆盖,但在复杂网络(如 Transformer)的解释深度上,仍有提升空间。
总结
如果你经常被 “模型为什么这么预测” 的问题困扰,或者需要向非技术同事解释模型逻辑,那么 Dalex 绝对是值得一试的工具。它就像一把 “X 射线”,能穿透模型的 “黑盒”,让每一个决策都有据可查。
后续我们还会分享更多 Dalex 的高级用法,比如用 SHAP 值解读单个样本、对比不同模型的表现等。感兴趣的话,欢迎关注本账号,一起探索数据工具的实用技巧!
📚资源
- 官方文档:https://dalex.drwhy.ai/

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
