1. 创始时间与作者
创始时间:Scrapy-Redis 最早由 Rolando Espinoza 等人开发,是 Scrapy 社区为解决分布式爬虫需求而诞生的一个扩展组件。它的第一个版本大约发布于 2012年左右,与 Scrapy 0.16 版本同期发展。
核心开发者:
Rolando Espinoza:Scrapy-Redis 项目的早期核心贡献者,为分布式爬虫架构奠定了基础。
Scrapy 开发团队:Scrapy-Redis 目前由 Zyte(原 Scrapinghub)公司和开源社区共同维护,是 Scrapy 生态中最流行的分布式扩展之一。
开源社区贡献:超过 80 位贡献者参与优化和扩展。
项目定位:一个基于 Redis 的 Scrapy 分布式组件,用于将 Scrapy 单机爬虫扩展为分布式爬虫系统。它通过 Redis 实现请求的分布式调度、去重和爬虫状态的同步,使得多台机器可以协同工作,共同完成大规模抓取任务。
2. 官方资源
GitHub 地址:https://github.com/rmax/scrapy-redis
PyPI 地址:https://pypi.org/project/scrapy-redis/
官方文档:https://scrapy-redis.readthedocs.io/
3. 核心功能
4. 应用场景
1. 大规模分布式数据采集
# settings.py 配置SCHEDULER = "scrapy_redis.scheduler.Scheduler"DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"REDIS_URL = 'redis://redis-server:6379'# 爬虫定义 (继承 RedisSpider)from scrapy_redis.spiders import RedisSpiderclass DomainSpider(RedisSpider):name = 'domain_spider'redis_key = 'domain:start_urls'# 从 Redis 读取起始 URLdef parse(self, response):# 处理逻辑for url in response.css('a::attr(href)').getall():yield {'url': url}启动方式:
# 在任意一台机器上启动爬虫scrapy crawl domain_spider# 在 Redis 中添加起始 URLredis-cli> lpush domain:start_urls https://example.com
2. 多爬虫共享任务队列
# 多个爬虫可以消费同一个任务队列# 爬虫 A (product_spider.py)class ProductSpider(RedisSpider):name = 'product_spider'redis_key = 'common:product_urls'# 爬虫 B (review_spider.py) class ReviewSpider(RedisSpider):name = 'review_spider'redis_key = 'common:product_urls'# 同样消费 product_urls 队列# 这样两个爬虫可以并行处理同一批商品链接
3. 动态任务注入与优先级控制
# 通过 Redis 命令动态添加不同优先级的任务import redisr = redis.Redis()# 添加普通优先级任务r.lpush('myspider:requests', 'https://example.com/page1')# 添加高优先级任务(通过不同的 Redis 键实现优先级)r.lpush('myspider:high_priority_requests', 'https://example.com/important')# 爬虫中可以配置多个队列class PrioritySpider(RedisSpider):name = 'priority_spider'redis_key = 'myspider:requests'# 通过自定义调度器实现优先级队列def start_requests(self):# 先处理高优先级队列yield from self._get_requests_from_redis('high_priority_requests')# 再处理普通队列yield from self._get_requests_from_redis('requests')4. 断点续爬与容灾恢复
# scrapy-redis 自动实现了断点续爬# 即使爬虫进程崩溃重启,也不会重复抓取已处理过的 URL# 检查 Redis 中当前的任务状态import redisr = redis.Redis()# 查看待处理任务数量pending = r.llen('myspider:requests')print(f"待处理任务: {pending}")# 查看已处理任务数量(去重集合大小)processed = r.scard('myspider:dupefilter')print(f"已处理任务: {processed}")# 清除去重集合(强制重新抓取)r.delete('myspider:dupefilter')
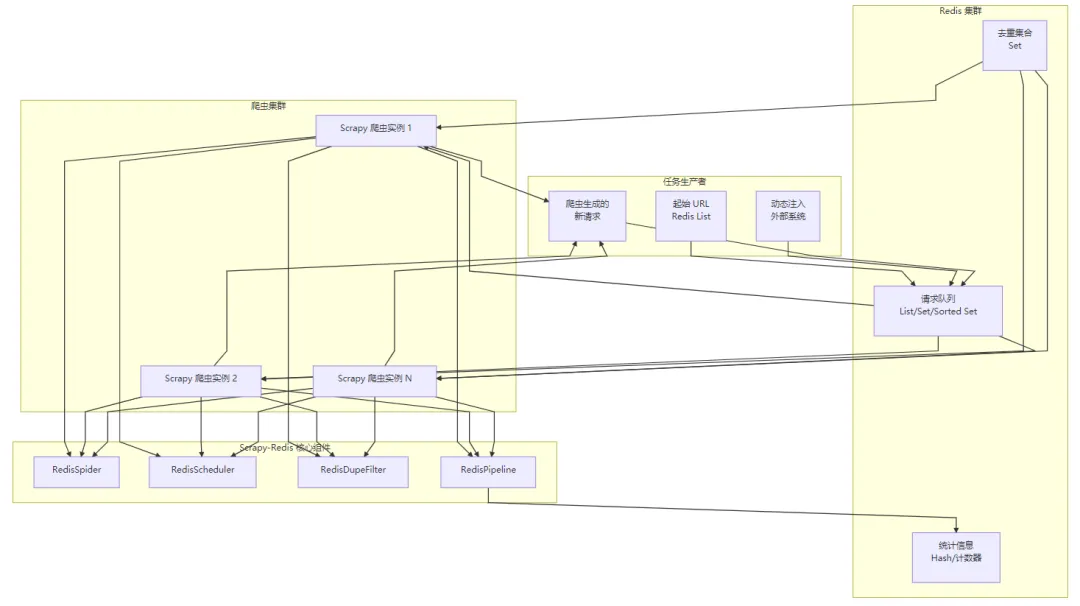
5. 底层逻辑与技术原理
核心架构
关键技术
基于 Redis 的分布式调度器:
替换 Scrapy 默认的本地调度器,使用 Redis 的 List、Set 或 Sorted Set 作为请求队列。
支持 FIFO(List)、LIFO(List 右进左出)和优先级队列(Sorted Set)。
多个爬虫实例从同一个 Redis 队列中 pop 请求,实现任务分发。
分布式去重过滤器:
Spider 状态同步:
原子性操作:
数据持久化:
6. 安装与配置
基础安装
# 安装 scrapy-redispip install scrapy-redis# 需要先安装 Redis 服务器# Ubuntu/Debian: sudo apt-get install redis-server# macOS: brew install redis# Windows: 下载 Windows 版本或使用 WSL
Scrapy 项目配置
在 Scrapy 项目的 settings.py 中添加以下配置:
# 启用 Redis 调度器和去重过滤器SCHEDULER = "scrapy_redis.scheduler.Scheduler"DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"# Redis 连接配置REDIS_URL = 'redis://:password@host:port/db'# 或使用独立配置REDIS_HOST = 'localhost'REDIS_PORT = 6379REDIS_PASSWORD = ''REDIS_DB = 0# 可选:请求序列化方式(默认使用 pickle)SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat"# 可选:队列模式(默认是 PriorityQueue)SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'# 其他选项:FifoQueue, LifoQueue# 可选:是否持久化去重记录(重启后不清空)DUPEFILTER_PERSIST = True# 可选:空闲时是否暂停爬虫(等待新任务)SCHEDULER_IDLE_BEFORE_CLOSE = 10# 可选:Item 存储到 RedisITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 300,}爬虫定义
from scrapy_redis.spiders import RedisSpiderclass MySpider(RedisSpider):name = 'myspider'# 从 Redis 中读取起始 URL 的键名redis_key = 'myspider:start_urls'# 可选:允许的域名allowed_domains = ['example.com']def parse(self, response):# 提取数据yield {'url': response.url,'title': response.css('title::text').get(), }# 提取新链接并加入队列for href in response.css('a::attr(href)').getall():yield scrapy.Request(url=response.urljoin(href))环境要求
| 组件 | 最低要求 | 推荐配置 |
|---|
| Python | 3.6+ | 3.8+ |
| Scrapy | 1.0+ | 2.0+ |
| Redis | 2.8+ | 5.0+ |
| Redis-py | 2.10+ | 3.5+ |
| 操作系统 | 所有平台 | Linux(生产环境最佳) |
7. 性能指标
| 配置/场景 | 请求速率 | Redis 内存占用 | 网络带宽 |
|---|
| 单爬虫 + 单 Redis | 500-1000 请求/秒 | 低(取决于队列大小) | 低 |
| 10 爬虫实例 + 单 Redis | 3000-5000 请求/秒 | 中等 | 中等 |
| 100 爬虫实例 + Redis 集群 | 10000-20000 请求/秒 | 高 | 高 |
优化建议:
使用 Redis 集群或哨兵模式避免单点故障。
适当设置 SCHEDULER_IDLE_BEFORE_CLOSE 避免爬虫过早退出。
对于超大规模抓取,考虑对请求队列进行分片(多个 Redis 键)。
使用 RedisPipeline 时注意 Redis 内存限制,可配合其他持久化方案。
8. 高级功能使用
1. 自定义请求队列(优先级队列)
# 使用 Redis Sorted Set 实现优先级队列SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'# 在爬虫中设置请求优先级from scrapy.http import Requestclass PrioritySpider(RedisSpider):name = 'priority_spider'redis_key = 'priority:start_urls'def parse(self, response):# 高优先级请求yield Request(url='https://example.com/important',priority=10, # 数字越大优先级越高callback=self.parse_important )# 低优先级请求yield Request(url='https://example.com/normal',priority=0 )
2. 分布式 Item 处理(使用 RedisPipeline)
# settings.pyITEM_PIPELINES = {'scrapy_redis.pipelines.RedisPipeline': 300,'myproject.pipelines.CustomPipeline': 400,}REDIS_ITEMS_KEY = '%(spider)s:items'# 默认键名格式REDIS_ITEMS_SERIALIZER = 'json'# 可选 'pickle' 或 'json'# 另一个进程可以消费 Redis 中的 Itemsimport redisimport jsonr = redis.Redis()while True:# 阻塞获取 Itemitem_data = r.blpop('myspider:items', timeout=0)if item_data:item = json.loads(item_data[1])# 将 Item 存入数据库save_to_database(item)3. 动态添加任务(外部系统集成)
# web_api.py - Flask 应用接收抓取请求from flask import Flask, requestimport redisimport jsonapp = Flask(__name__)r = redis.Redis()@app.route('/crawl', methods=['POST'])def add_crawl_task():data = request.jsonurl = data.get('url')priority = data.get('priority', 0)# 创建请求对象(需要与爬虫的序列化兼容)request_obj = {'url': url,'method': 'GET','priority': priority,'callback': 'parse_product','dont_filter': False }# 添加到 Redis 队列r.lpush('crawler:requests', json.dumps(request_obj))return {'status': 'ok', 'url': url}if __name__ == '__main__':app.run(port=5000)4. 监控和管理
# monitor.py - 实时监控爬虫状态import redisimport timer = redis.Redis()def monitor_spider(spider_name):while True:# 获取队列大小pending = r.llen(f'{spider_name}:requests')# 获取去重集合大小processed = r.scard(f'{spider_name}:dupefilter')# 获取已抓取 Item 数量items = r.llen(f'{spider_name}:items')print(f"[{time.strftime('%H:%M:%S')}] "f"待处理: {pending}, 已处理: {processed}, Items: {items}")# 检查爬虫实例数量workers = r.get(f'{spider_name}:workers') or 0print(f"活跃爬虫实例: {workers}")time.sleep(5)# 在爬虫启动时记录实例数# 可以在爬虫的 spider_opened/spider_closed 中更新计数器
9. 与同类工具对比
| 特性 | Scrapy-Redis | Scrapy-Cluster | Gerapy | Frontera | 自实现 Redis 调度 |
|---|
| 定位 | 轻量级分布式扩展 | 完整集群解决方案 | 分布式管理平台 | 爬虫策略框架 | 定制化实现 |
| 安装复杂度 | 低 | 高 | 中等 | 高 | 不定 |
| 功能完整度 | 调度+去重 | 完整生态系统 | 调度+监控+部署 | 爬取策略 | 取决于实现 |
| 扩展性 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 社区活跃度 | 高 | 中等 | 高 | 中等 | - |
| 适用场景 | 已有 Scrapy 项目分布式化 | 全新大型分布式系统 | 爬虫集群管理 | 自适应爬取策略 | 特殊需求 |
10. 企业级应用案例
电商价格监控平台:
新闻舆情分析系统:
搜索引擎数据源:
学术研究数据采集:
总结
Scrapy-Redis 是 Scrapy 生态中最成熟、最易用的分布式爬虫解决方案,核心价值在于:
无缝集成:只需简单配置即可将现有 Scrapy 爬虫扩展为分布式系统。
轻量高效:基于 Redis 实现核心分布式功能,无额外复杂依赖。
功能完备:提供分布式调度、去重、队列管理、状态同步等完整功能。
生产验证:经过大量企业级项目的实践检验,稳定可靠。
技术亮点:
适用场景:
何时可能不适用:
安装使用:
pip install scrapy-redis# 配置 settings.py# 继承 RedisSpider 编写爬虫
学习资源:
官方文档:https://scrapy-redis.readthedocs.io/
GitHub 仓库:https://github.com/rmax/scrapy-redis
实战教程:Scrapy-Redis 分布式爬虫实战
截至 2024 年,Scrapy-Redis 在 GitHub 收获 4.5k+ Star,是 Scrapy 用户进行分布式爬虫的首选扩展。项目遵循 MIT 开源协议,可免费用于商业和非商业项目。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
