Linux三剑客之awk(下):吃透这篇,日志分析一行封神
- 2026-07-01 10:45:42
前面讲解了awk的基础使用,基本上学会了上一篇文章,常规的文本处理及格式已基本够用。其实awk有许多高级功能,如果熟悉了能够起到事倍功半的作用,不过我也经常记不住,只能搜索实践后再整理成为文章,方便日后使用的时候进行查找,大家觉得有用可以进行收藏。
在上一篇内容里,我们一起认识了Linux文本处理三剑客之awk最核心的用法:取列、分隔符、条件筛选、BEGIN/END模块。
但真正让AWK封神的,是它数组统计、字符串处理、多文件关联、日志分析的能力,这些命令可能稍微有些晦涩难记。这一篇,我不讲废话,全是我测试过的,可以在日常运维、面试常问、工作提效的实战内容,吃透它,你就是文本处理高手👇
📌 一、AWK数组:统计去重、计数神器
AWK 数组是关联数组(键值对),不用提前定义,直接用,是做IP统计、访问量、重复数据的核心。
1. 统计某列出现次数
awk '{count[$1]++} END{for(i in count) print i,count[i]}' 123.txt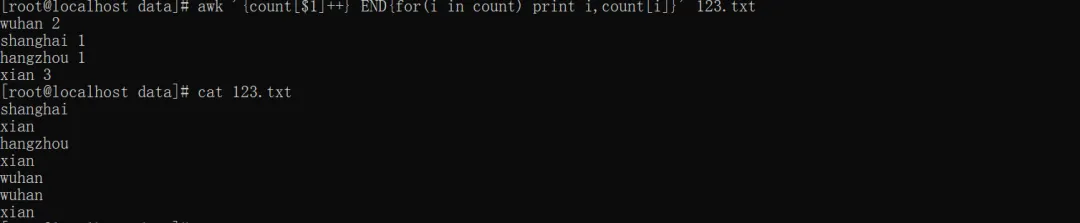
count[$1]++:第一列累计计数
for(i in count):遍历关联数组 count 的所有键(即第一列出现过的所有唯一值),i 代表当前遍历到的键;
print i,count[i]:输出 “键(第一列的值) + 对应的值(出现次数)”,中间用空格分隔。
2. 日志实战:统计访问IP次数
awk '{ips[$1]++} END{for(ip in ips) print ip,ips[ip]}' access.log{ips[$1]++}:逐行读取标准输入的内容,关联数组 ips 统计第一列($1)出现次数;
for(ip in ips):遍历关联数组 ips 的所有键;
print ip,ips[ip]:输出 “IP / 第一列值 + 对应的出现次数”。
3. 访问量Top5 IP
awk '{ips[$1]++} END{for(ip in ips) print ips[ip],ip}' access.log | sort -nr | head -5
📌 二、字符串处理:文本清洗一步到位
AWK 自带强大字符串函数,不用依赖其他命令,直接完成截取、替换、去符号、算长度。
1. 截取字符串(substr)
awk '{print substr($0,1,25)}' secure #截取前25个字符
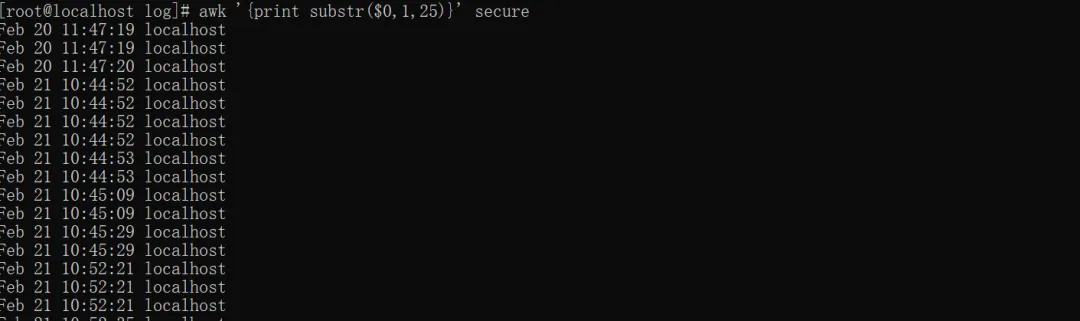
$0:当前整行;
substr截取函数:字符串, 起始位置, 截取长度。
2. 全局替换(gsub)
awk '{gsub(/shanghai/, "zhejiang"); print}' 123.txt > 222.txt # 把文本中的shanghai全部替换成zhejiang,结果输出到222.txt
gsub:全局替换。
3. 计算行/字段长度(length)
awk 'length($0) > 200' 文件名 # 过滤长度大于200的行
4. 字符串分割(split)
awk '{split($3,t,":");print "时:",t[1],"分:",t[2],"秒:",t[3]}' /var/log/secure#将secure文件的时间提取出来为时分秒

split($3,t,":"):awk字符串分割函数,split(要分割的字符串, 结果数组, 分隔符);第三个字段,存储在数组t、用冒号分隔;
t[1]:分割后的第一个元素。
📌 三、条件与循环:AWK真正的编程能力
awk支持 if/else、for、while,可以撰写复杂逻辑脚本,实现智能判断。
1. if-else 多条件判断
awk '{if($3>80) print "高负载:"$0; else if($3>50) print "中负载:"$0; else print "正常:"$0}' load.log#根据load.log中第3列的数值,输出不同负载等级(高/中/正常)

2. for 循环遍历所有列
awk '{sum=0;for(i=1;i<=NF;i++) sum+=$i; print sum}' 12.txt # 计算一行所有数字之和
📌 四、高级分隔符:处理不规则文本
日常文件不一定是空格分隔,awk支持正则分隔、多符号分隔。
1. 各种分割符同时分隔
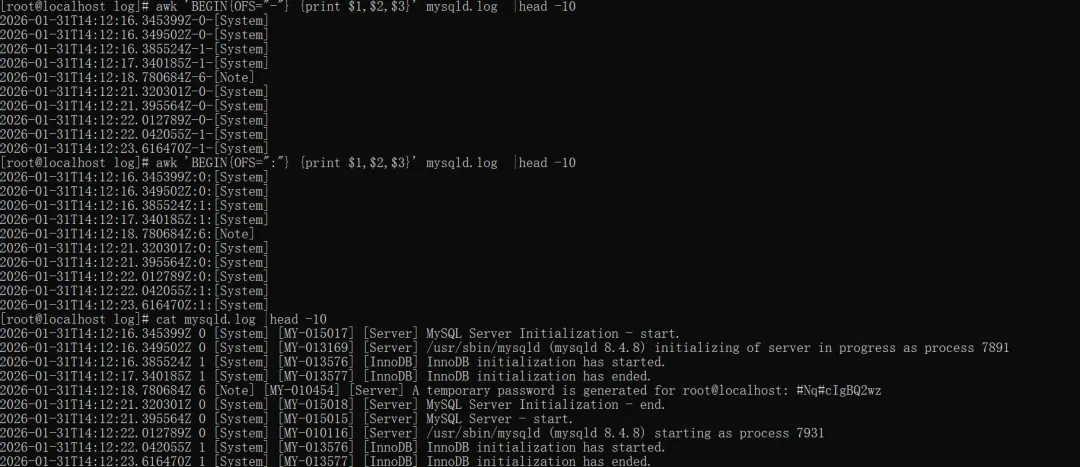
awk -F '[- : .]' '{print $1,$2,$3}' mysqld.log |head -10#同时按照-、空格、:、.四种符号分割每行的前三字段
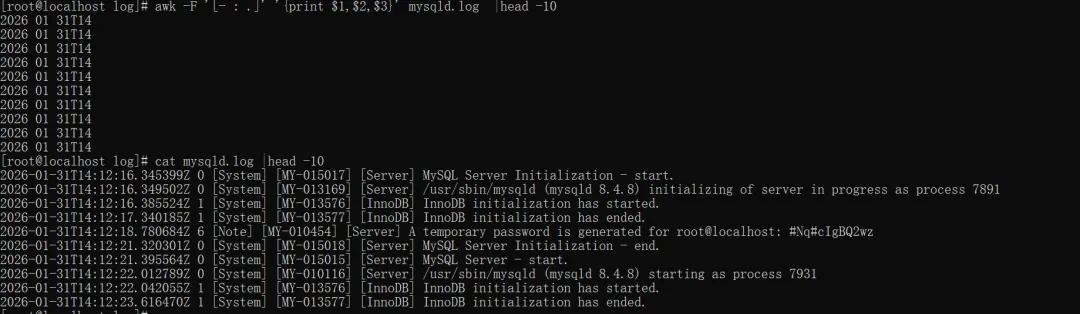
'[- : .]':awk 支持的正则表达式分隔符,中括号 [] 表示 “匹配其中任意一个字符”,即按 -、:、. 空格这 四个字符中的任意一个拆分字段。
2. 连续空格/Tab 自动处理
awk -F '[[:space:]]+' '{print $1,$2,$3}' yum.log |head -10#提取yum.log的前三个字段,自动将连续空格/Tab转为单个空格分隔
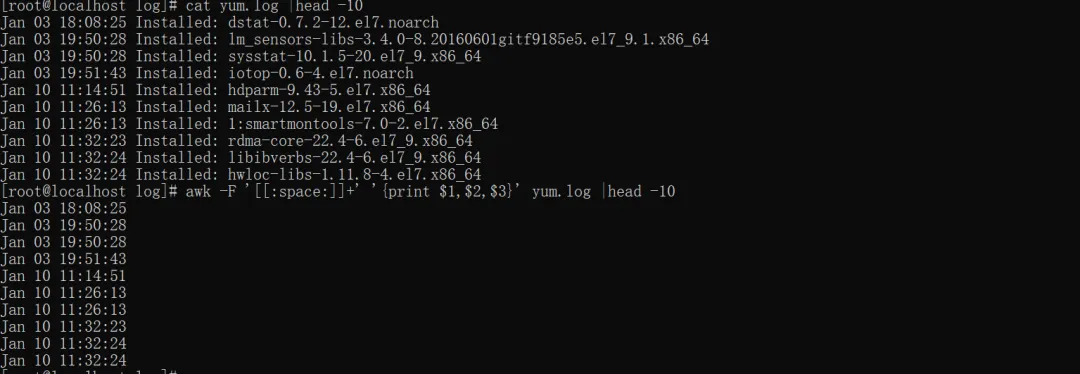
awk -F '[[:space:]]+' '{print $1,$2}' 33.txt |head -10#中间有连续多个空格

[[:space:]]:awk 中的「空白字符类」,等价于 [ \t],匹配单个空格或单个制表符(Tab);
+:正则中的 “重复限定符”,表示「匹配前面的字符 / 类 1 次或多次」;
[[:space:]]+ 匹配「一个或多个连续的空格 / 制表符」,作为字段分隔符。
3. 自定义输出分隔符
awk 'BEGIN{OFS="-"} {print $1,$2,$3}' mysqld.log |head -10 #-分隔符awk 'BEGIN{OFS=":"} {print $1,$2,$3}' mysqld.log |head -10 #:分隔符
📌 五、多文件关联:类SQL左连接
awk 可以同时读两个文件,做匹配、关联、补全,像数据库一样好用。
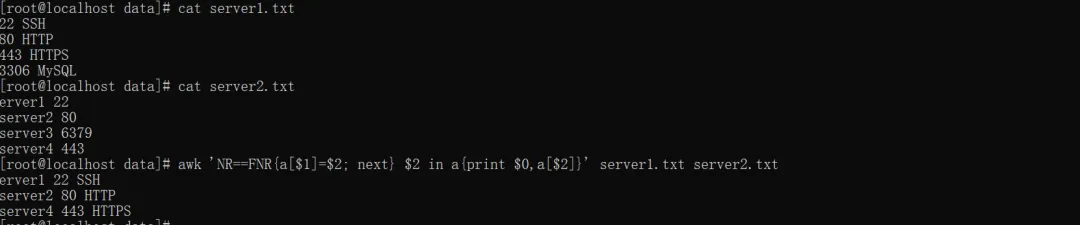
awk 'NR==FNR{a[$1]=$2; next} $2 in a{print $0,a[$2]}' server1.txt server2.txtNR:全局总行数;
FNR:当前行数;
NR==FNR,也就是只有处理第一个文件时才成立;
next 跳过指令;
a[$1]=$2 键=server1.txt的第一列,值=server1.txt的第二列;
$2 in a 判断 server2.txt 当前行的第二列,是否是关联数组 a 的键(即是否在 server1.txt 的第一列中出现过);
print $0,a[$2]:条件成立时,输出 server2.txt 的整行内容($0) + 数组 a 中对应的值(a[$2]);
实例中以server1的端口号去匹配server2的端口号(需确保server1.txt第一列、server2.txt第二列是端口号)。
✅ 适用场景:
用户名单匹配分数、配置文件对比、日志关联分析。
📌 六、生产环境高频实战(直接复制)
这部分建议直接收藏,运维、开发、日志排查天天用。
🔹 1. nginx/apache日志分析
awk '$9~/404|500/{print}' access.log# 筛选404/500错误
~ 是awk的匹配运算符,含义是“匹配于”;!~ 是“不匹配于”;
/.../正则表达式的边界符;
^行首,$行尾;
|逻辑或。

awk '{code[$9]++} END{for(i in code) print i,code[i]}' access.log# 统计所有状态码数量,相对于遍历
code[$9]++,查看第九列的键值,有值加1;
for(i in code):遍历关联数组 code 的所有键(即所有出现过的状态码),i 代表当前遍历到的状态码;
print i,code[i]:输出 “状态码 + 对应的次数”,中间用空格分隔。

🔹 2. 系统监控
ps aux | awk 'NR>1{cpu+=$3;mem+=$4} END{printf "总CPU占比: %.1f%% 总内存占比: %.1f%%\n", cpu, mem}'# 统计总CPU、内存占用

NR>1 跳过第一行,也就是表头;
cpu+=$3 mem+=$4 cpu和内存列求和;
%.1f 表示保留1位小数的浮点数;%% 是输出百分号的转义写法(单个%是格式符,需用两个%输出普通%)。
df -h | awk '/^\/dev/{gsub(/%/,"");if($5>80) print "告警:"$1,$5"%"}'# 磁盘使用率超80%告警

•$1:分区名(如 /dev/sda1);
• $5:磁盘使用率(带百分号,如 85%);
• /^\/dev/是正则规则,只筛选/dev开头的本地分区(排除tmpfs等虚拟文件系统);
gsub(/%/,"")将%号替换为空。
🔹 3. 文本清洗
awk '!/^$/ && !/^#/' /etc/vsftpd/vsftpd.confbak # 去掉空行+注释行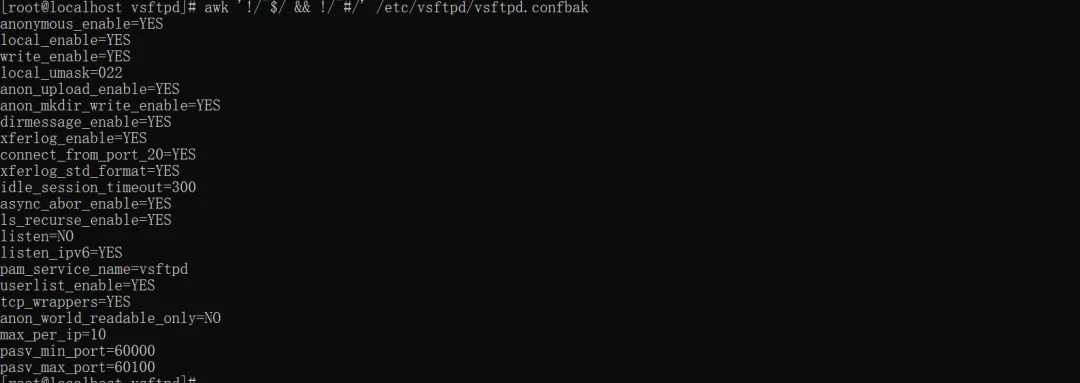
!/^$/:! 表示 “不匹配”,^$ 是正则表达式,匹配空行(^ 表示行首,$ 表示行尾,中间无内容就是空行),就是不匹配 “空行”;
当然最后可以将结果重定向输出即可作为配置文件。
awk 'NR>=50 && NR<=70' /var/log/messages # 取50~70行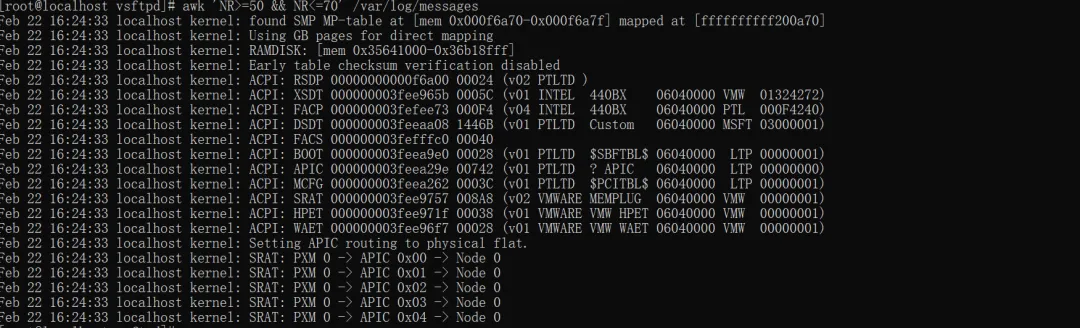
🔹 4. 数据计算
awk '{sum+=$2} END{print sum}' 12.txt # 求和
awk '# 只处理有效行(字段数≥2 + 第二个字段是数字)NF>=2 && $2~/^[0-9.]+$/ {# 核心:先判断max是否为空,为空则初始化,非空再比较if (max == "") {max = $2 # 第一次有效行,直接赋值,避免和空字符串比较} else {max = ($2 > max) ? $2 : max # 后续行正常比较(数值vs数值)}# 同理处理minif (min == "") {min = $2} else {min = ($2 < min) ? $2 : min}sum += $2count++ # 统计有效行数}END {if (count > 0) {print "平均值:", sum/count, "最大值:", max, "最小值:", min} else {print "无有效数据"}}' 12.txt # 平均值+最大值+最小值

📌 七、写成AWK脚本:复杂逻辑永久保存
当命令太长时,直接写成 .awk 脚本,干净、好维护、可重复使用。
1. 新建脚本 ceshi.awk
BEGIN{print "===== 开始统计 ====="OFS=" | "# 显式初始化变量,避免空值干扰total = 0count = 0}# 只处理:字段数≥1 且 第一个字段是数字(整数/小数)的行NF>=1 && $1~/^[+-]?[0-9]+(\.[0-9]+)?$/ {total += $1 # 只累加有效数值count++ # 只统计有效行数}END{print "有效总行数:"countprint "总和:"total# 避免除以0,友好提示if (count > 0) {print "平均值:"total/count} else {print "平均值:无有效数据(无法计算)"}print "===== 统计完成 ====="}
2. 执行
awk -f ceshi.awk 12.txt
📌 八、总结
1. 核心流程:按行读 → 按列切 → 按条件处理 → 按结果输出;
2. 核心优势:取列用`$n`、统计用关联数组、清洗用字符串函数、多文件用NR==FNR;
3. 避坑要点:变量显式初始化(避免空值比较)、分隔符用[[:space:]]+处理多空格、排序前先输数值再输文本;
4. 分工原则:查找用 grep,修改用 sed,统计 / 计算用 awk(三剑客分工)
✍️ 结语
awk看上去语法奇怪,其实逻辑非常清晰:
按行读、按列切、按条件处理、按结果输出。从最简单的取列,到复杂的日志统计,AWK 真正做到了一行顶十行。如果你是运维工程师,这套 AWK 实战技能,一定会成为你效率提升的秘密武器。
awk已经学习完毕,建议收藏+转发,下次处理文本直接拿来用!
#运维 #linux运维 #linux实战 #linux三剑客 #awk
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python Tkinter工控实战:IO点位映射显示,从零搭建你的数字沙盘
- Python每日1语法·Day5
- 电脑屏幕上的提词器!这个Python开源项目让你的演讲不再忘词
- 你的Python程序吃光内存?不是代码问题,是你不懂这4个回收机制!
- 网站改版爬虫就废?这个 Python 库让你告别手动维护
- 拒绝手写 GUI 代码!用国产可视化 Python 工具 PyMe,快速做文件拖拽导入程序
- 用Python和PyBullet在虚拟世界中加载一个R2D2机器人
- 在linux系统里,我用Celluloid + 哔哩哔哩打造了自己喜欢的歌曲库
- 救命!Linux系统越用越卡?40个实战优化技巧+指令,运维小白也能上手
- Linux内核6.18、6.12与6.6 LTS支持周期正式延长
