做运维的朋友,肯定都遇到过这样的情况:刚部署的Linux服务器,跑起来丝滑流畅,可用了几个月,就开始变得卡顿、响应变慢,甚至偶尔出现服务超时;明明配置不算低,却总感觉“力不从心”,日志越堆越多,进程越跑越杂,重启也只能临时缓解,过几天又打回原形。其实Linux系统卡顿、性能下降,从来都不是“硬件不够用”那么简单,更多是因为我们忽略了细节——没有清理冗余进程、没有优化系统参数、没有管控资源占用、没有规范软件安装。很多人觉得Linux优化“高深莫测”,需要懂底层原理、会写复杂脚本,其实不然。这篇文章,我们就用最亲切、最务实的语气,不讲空洞理论、不搞复杂操作,只给大家整理可直接落地的Linux系统优化技巧、高频实用指令,还有必看的避坑注意事项。不管你是刚接触Linux的小白,还是有一定经验的运维,看完都能照着做,快速提升系统流畅度、稳定性,让你的Linux服务器“重获新生”,再也不用为卡顿熬夜排查。文中穿插清晰的优化流程图,步骤分明,不用猜、不用试,一步步跟着来,就能解决80%的Linux性能问题。
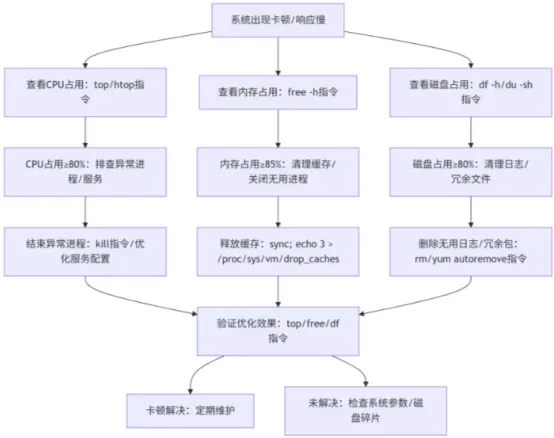
一、先搞懂:Linux系统卡顿的核心原因(附排查流程图)
优化之前,我们得先知道“卡在哪”,不然盲目操作,不仅没效果,还可能越优化越乱。很多人遇到卡顿,第一反应就是“重启”,但重启只能解决临时问题,想要从根源解决,必须先定位原因。Linux系统卡顿的核心原因,其实就5类:资源占用过高(CPU、内存、磁盘)、冗余进程/服务过多、系统参数不合理、磁盘碎片化严重、无用日志/缓存堆积。
下面这张流程图,能帮你快速定位卡顿原因,不管是小白还是老运维,都能直接套用,不用凭感觉排查,节省大量时间。
Linux卡顿快速排查流程图
这里跟大家说个小技巧:排查的时候,一定要“先看资源,再查进程,最后找配置”,不要上来就乱杀进程、乱改配置。比如CPU占用过高,先用top指令看哪个进程占用最高,如果是无用进程,直接结束;如果是核心业务进程,就优化进程配置,而不是盲目杀死,避免影响业务运行。内存占用过高,先清理缓存,再排查是否有内存泄漏;磁盘占用过高,先清理日志和冗余文件,再检查是否有大文件占用磁盘。很多小白容易犯的错误,就是看到卡顿就重启,或者随便结束进程,结果导致业务中断、数据丢失。其实只要按上面的流程排查,90%的卡顿问题都能快速定位,而且不用重启系统,不影响正常业务。另外,建议大家养成定期排查的习惯,每周检查一次资源占用、进程状态,提前清理冗余,避免小问题堆积成大故障,这样才能让Linux系统长期保持流畅。还有一点要注意,不同发行版的Linux(CentOS、Ubuntu、Debian),排查指令基本一致,只是部分软件管理指令有差异(比如CentOS用yum,Ubuntu用apt),后面我会专门标注,大家可以根据自己的系统对应操作,不用怕选错指令。
二、CPU优化:告别卡顿,让系统“轻装上阵”(附实用指令)
CPU是Linux系统的“大脑”,一旦CPU占用过高,系统就会出现卡顿、响应变慢,甚至服务崩溃。很多时候,CPU占用高并不是因为业务压力大,而是因为冗余进程、无用服务太多,或者进程配置不合理。下面这些优化技巧和指令,能帮你快速降低CPU占用,让系统更流畅,所有指令都经过实战验证,小白也能直接复制执行,不用修改参数。
首先,我们要学会查看CPU状态,这是优化的前提,常用的3个指令,大家一定要记牢,平时排查的时候经常用到:
1. top:实时查看CPU、内存、进程占用情况,默认按CPU占用率排序,按下“q”键退出查看。指令直接输入top即可,进入后,%CPU列就是每个进程的CPU占用率,PID是进程ID,后面结束进程会用到。
2. htop:比top更直观,支持鼠标操作,能清晰看到每个进程的CPU、内存占用,还能快速筛选进程。如果系统没有安装htop,CentOS可以用“yum install htop -y”安装,Ubuntu用“apt install htop -y”安装,安装完成后输入htop即可使用。
3. mpstat:查看CPU核心的详细占用情况,适合排查多核心CPU的负载不均衡问题,指令格式:mpstat -P ALL 1 5,意思是每隔1秒查看一次所有CPU核心的占用情况,共查看5次,能快速发现哪个核心占用过高。
查看完CPU状态,就可以针对性优化了,主要分为3个方面:关闭无用服务、结束异常进程、优化进程配置,每一步都有详细的操作步骤和指令,大家照着做就行。
第一,关闭无用服务。Linux系统默认会启动很多无用的服务,这些服务会一直占用CPU资源,导致系统卡顿,比如postfix(邮件服务)、telnet(远程登录服务,不安全且很少用)、cups(打印服务)等,这些服务如果用不到,就可以直接关闭,并且设置开机不自启,避免下次开机再占用资源。
常用指令(适用于CentOS):① 查看所有服务状态:systemctl list-unit-files --type=service,查看哪些服务是“enabled”(开机自启);② 关闭无用服务:systemctl stop 服务名,比如关闭postfix服务:systemctl stop postfix;③ 设置开机不自启:systemctl disable 服务名,比如systemctl disable postfix。
适用于Ubuntu的指令:① 查看服务状态:systemctl list-unit-files --type=service;② 关闭服务:systemctl stop 服务名;③ 开机不自启:systemctl disable 服务名,和CentOS基本一致,只是部分服务名可能有差异,大家可以根据实际情况调整。
这里提醒大家,关闭服务之前,一定要确认该服务是否有用,比如sshd(SSH远程服务)、nginx(Web服务)、mysql(数据库服务)这些核心服务,绝对不能关闭,否则会影响业务运行。如果不确定服务的用途,可以用“systemctl status 服务名”查看服务描述,再决定是否关闭。
第二,结束异常进程。有时候,某个进程会出现异常,疯狂占用CPU资源(比如占用率超过90%),导致系统卡顿,这时候就需要及时结束该进程。结束进程之前,一定要先确认该进程不是核心业务进程,避免误杀导致业务中断。
常用指令:① 查看异常进程:top/htop,找到CPU占用过高的进程,记录PID(进程ID);② 结束进程:kill -9 PID,比如PID为1234的进程占用过高,指令就是kill -9 1234;③ 批量结束同类进程:pkill 进程名,比如结束所有java进程:pkill java(谨慎使用,避免误杀)。
这里有个避坑点:不要随便用kill -9指令结束进程,尤其是PID较小的进程,很多PID较小的进程是系统核心进程,误杀会导致系统崩溃。结束进程之前,最好先用“ps -ef | grep PID”查看进程详情,确认是无用进程或异常进程后,再执行kill指令。
第三,优化进程配置。如果核心业务进程占用CPU过高,不能直接结束,就需要优化进程配置,比如调整进程的优先级、限制进程的CPU占用率。比如,某个业务进程占用CPU过高,可以提高其他核心进程的优先级,或者限制该业务进程的CPU使用上限,避免单个进程占用过多资源,导致系统卡顿。
常用指令:① 调整进程优先级:nice -n 优先级 PID,优先级范围是-20到19,数值越小,优先级越高,比如将PID为1234的进程优先级提高到-10:nice -n -10 1234;② 限制进程CPU占用率:可以用cpulimit工具,CentOS安装:yum install cpulimit -y,Ubuntu安装:apt install cpulimit -y,使用指令:cpulimit -p PID -l 50,意思是限制PID为1234的进程,CPU占用率不超过50%。
另外,对于长期运行的核心进程,建议配置进程守护,比如用systemd设置进程自启,一旦进程异常退出,能自动重启,避免因为进程退出导致业务中断,同时也能减少手动干预的频率,节省运维时间。
总结一下CPU优化的核心:关闭无用服务、结束异常进程、优化核心进程配置,定期查看CPU状态,提前排查隐患。只要做好这几点,CPU占用率就能控制在合理范围(建议不超过80%),系统也就不会因为CPU问题出现卡顿。
三、内存优化:释放冗余,避免内存泄漏(附核心指令)
内存是Linux系统的“临时仓库”,所有运行的进程、服务都会占用内存,一旦内存占用过高,系统就会开始使用swap分区(虚拟内存),而swap分区是用磁盘空间模拟的内存,读写速度比物理内存慢很多,这也是导致系统卡顿的重要原因之一。很多人遇到内存占用过高,就以为是物理内存不够,其实大部分时候,是因为内存没有得到合理释放,或者存在内存泄漏,只要做好内存优化,就能有效提升系统流畅度。和CPU优化一样,内存优化的第一步,也是学会查看内存状态,常用的3个指令,简单好记,小白也能快速上手:
1. free -h:查看内存总容量、已用容量、空闲容量、缓存容量,以及swap分区的使用情况,“h”代表人性化显示,能自动转换单位(KB、MB、GB),不用自己换算,输入指令后,Mem行是物理内存,Swap行是虚拟内存,buff/cache是缓存容量,缓存可以手动释放,释放后能增加空闲内存。
2. vmstat 1 5:实时查看内存使用情况,每隔1秒查看一次,共查看5次,其中si(从swap分区读入内存的数据量)、so(从内存写入swap分区的数据量)如果数值过大,说明内存不足,系统正在频繁使用swap分区,需要及时优化。
3. ps aux --sort=-%mem:查看所有进程的内存占用情况,按内存占用率从高到低排序,能快速找到占用内存过高的进程,和top指令类似,但更专注于内存占用的查看。
了解了内存状态,就可以开始优化了,内存优化主要分为4个方面:释放缓存、关闭无用进程、排查内存泄漏、优化swap分区,每一步都有详细的操作方法和指令,大家可以直接对照执行,不用担心操作复杂。
第一,释放内存缓存。Linux系统会自动将常用的数据缓存到内存中,加快读取速度,但缓存占用过多,会导致空闲内存减少,这时候就可以手动释放缓存,释放的缓存不会影响核心业务,只是下次读取数据时,需要重新从磁盘读取,不会对系统造成伤害。
常用释放缓存的指令(需要root权限):① sync; echo 1 > /proc/sys/vm/drop_caches(释放页缓存);② sync; echo 2 > /proc/sys/vm/drop_caches(释放目录项和inode缓存);③ sync; echo 3 > /proc/sys/vm/drop_caches(释放所有缓存,推荐使用)。
这里提醒大家,释放缓存之前,一定要执行sync指令,sync指令会将内存中的数据同步到磁盘中,避免因为释放缓存导致数据丢失。另外,释放缓存只是临时缓解内存占用过高的问题,想要长期解决,还是需要找到内存占用过高的根源,比如关闭无用进程、排查内存泄漏。
第二,关闭无用进程。和CPU优化类似,很多无用的进程会一直占用内存资源,比如后台运行的脚本、未关闭的临时进程等,这些进程可以直接结束,释放内存。结束进程的指令和CPU优化时一样,用kill -9 PID或pkill 进程名,结束之前一定要确认进程不是核心业务进程,避免误杀。
这里给大家一个小建议:可以定期清理后台无用进程,比如每天凌晨用定时任务(crontab)执行清理指令,自动结束无用进程,释放内存,不用手动干预,节省运维时间。定时任务的配置方法,后面会专门讲解,大家可以耐心看完。
第三,排查内存泄漏。内存泄漏是指进程占用的内存不断增加,无法释放,长期下来,会导致内存被占满,系统卡顿、崩溃,这是内存优化中最需要注意的问题。内存泄漏的排查相对复杂,但也有简单的方法,适合小白操作。
常用排查方法:① 用ps aux --sort=-%mem指令,定期查看进程的内存占用情况,如果某个进程的内存占用率一直在上升,没有下降的趋势,说明可能存在内存泄漏;② 用top指令实时监控,观察该进程的内存变化,确认是否存在内存泄漏;③ 如果确认存在内存泄漏,先重启该进程,临时释放内存,然后联系开发人员排查代码问题,从根源解决内存泄漏。
对于小白来说,不用深入排查代码问题,只要能发现内存泄漏的进程,重启进程临时缓解,然后反馈给相关人员即可。另外,定期重启核心业务进程(在业务低峰期),也能有效避免内存泄漏导致的内存占用过高问题。
第四,优化swap分区。swap分区是虚拟内存,当物理内存不足时,系统会使用swap分区,但swap分区读写速度慢,频繁使用会导致系统卡顿,所以我们可以通过优化swap分区的配置,减少系统对swap分区的使用,提升系统流畅度。
常用优化方法:① 调整swappiness参数,swappiness参数的范围是0-100,数值越小,系统越倾向于使用物理内存,越少使用swap分区,建议设置为10-20,指令:echo 10 > /proc/sys/vm/swappiness(临时生效,重启后失效);② 永久生效:编辑/etc/sysctl.conf文件,添加一行“vm.swappiness=10”,然后执行sysctl -p指令,使配置生效;③ 如果物理内存充足(比如大于8GB),可以适当减小swap分区的大小,甚至关闭swap分区(谨慎操作,确保物理内存充足)。
这里有个避坑点:不要随意关闭swap分区,如果物理内存不足,关闭swap分区后,系统会因为内存不够而崩溃;如果物理内存充足,关闭swap分区能提升系统流畅度,但一定要提前确认物理内存足够支撑所有业务运行。另外,swappiness参数不要设置为0,设置为0后,系统会完全不使用swap分区,当物理内存耗尽时,会直接导致进程崩溃,建议设置为10-20,兼顾稳定性和流畅度。
内存优化的核心,就是“释放冗余缓存、关闭无用进程、排查内存泄漏、优化swap配置”,只要做好这几点,就能让内存得到合理利用,避免系统因为内存问题出现卡顿,同时也能延长服务器的使用寿命。
四、磁盘优化:清理冗余,提升读写速度(附高频指令)
磁盘是Linux系统的“存储仓库”,所有的文件、日志、软件都存储在磁盘中,随着使用时间的增加,磁盘会积累大量的无用日志、冗余文件、临时文件,导致磁盘空间不足、碎片化严重,进而影响磁盘读写速度,让系统出现卡顿。很多人遇到磁盘空间不足,就只能删除文件临时缓解,但不知道如何从根源优化,其实磁盘优化并不复杂,只要做好“清理冗余、减少碎片、优化挂载”这三点,就能提升磁盘读写速度,让系统更流畅。首先,我们还是要学会查看磁盘状态,常用的4个指令,覆盖磁盘空间、磁盘读写速度、磁盘碎片等,大家一定要记牢,平时排查磁盘问题时经常用到:
1. df -h:查看所有磁盘分区的空间使用情况,包括总容量、已用容量、空闲容量、使用率,“h”代表人性化显示,能自动转换单位,输入指令后,就能快速发现哪个分区的使用率过高(建议不超过80%),需要清理。
2. du -sh 目录名:查看指定目录的大小,比如查看/var/log目录(日志目录)的大小:du -sh /var/log,能快速找到占用磁盘空间过大的目录,针对性清理。如果想要查看目录下所有子目录的大小,可以用du -h 目录名,比如du -h /var/log,会显示该目录下每个子目录的大小,方便定位大文件。
3. iostat -x 1 5:查看磁盘读写速度、IO占用情况,每隔1秒查看一次,共查看5次,其中%util列是磁盘IO使用率,如果数值接近100%,说明磁盘IO压力过大,需要优化磁盘读写。
4. fsck:检查磁盘碎片和磁盘错误,修复磁盘问题,指令格式:fsck /dev/sda1(/dev/sda1是磁盘分区,需要根据实际情况调整),注意:执行fsck指令时,需要卸载该磁盘分区,否则会导致数据丢失,建议在系统重启时执行,或者在业务低峰期,确保数据备份后执行。
了解了磁盘状态,就可以开始优化了,磁盘优化主要分为3个方面:清理冗余文件、减少磁盘碎片、优化磁盘挂载,每一步都有详细的操作方法和指令,小白也能直接上手,不用怕操作失误。
第一,清理冗余文件。这是磁盘优化最基础、最有效的方法,冗余文件主要包括:无用日志文件、临时文件、冗余软件包、过期备份文件等,这些文件占用大量磁盘空间,而且没有实际用途,清理后能快速释放磁盘空间。
下面分场景给大家整理常用的清理指令,大家可以根据自己的系统和实际情况,针对性清理:
1. 清理日志文件:Linux系统的日志主要存储在/var/log目录下,随着使用时间的增加,日志文件会越来越大,尤其是/var/log/messages、/var/log/secure、/var/log/cron这几个日志文件,需要定期清理。常用指令:① 删除指定日志文件:rm -rf /var/log/日志文件名(谨慎使用,避免误删核心日志);② 清空日志文件(推荐使用,不会删除文件,只清空内容):echo "" > /var/log/日志文件名,比如清空messages日志:echo "" > /var/log/messages;③ 定期清理日志:可以配置logrotate(日志轮转),自动切割、压缩、删除过期日志,避免日志文件过大,后面会专门讲解logrotate的配置方法。
2. 清理临时文件:临时文件主要存储在/tmp目录下,系统会自动清理,但有时候临时文件过多,系统清理不及时,就需要手动清理。常用指令:rm -rf /tmp/*,删除/tmp目录下所有临时文件,注意:/tmp目录下的文件都是临时文件,删除后不会影响系统运行,但要确保没有正在使用的临时文件,建议在业务低峰期执行。
3. 清理冗余软件包:安装软件时,会产生很多依赖包、缓存包,这些包在软件安装完成后,就没有实际用途了,可以清理掉,释放磁盘空间。CentOS常用指令:① 清理yum缓存:yum clean all;② 删除无用依赖包:yum autoremove -y;Ubuntu常用指令:① 清理apt缓存:apt clean;② 删除无用依赖包:apt autoremove -y。
4. 清理过期备份文件:如果平时做了数据备份,备份文件会占用大量磁盘空间,过期的备份文件可以删除,只保留最近的几份备份,避免占用过多磁盘空间。常用指令:rm -rf 备份文件路径,比如删除/backup目录下30天前的备份文件,可以用find /backup -mtime +30 -exec rm -rf {} \;(后面会讲解find指令的用法)。
这里提醒大家,删除文件时一定要谨慎,尤其是用rm -rf指令,一旦误删核心文件,会导致系统崩溃、数据丢失,建议删除前先确认文件路径和文件用途,最好做好数据备份。另外,清理文件时,不要一次性删除过多文件,避免影响磁盘IO,导致系统卡顿。
第二,减少磁盘碎片。磁盘碎片是指文件被分散存储在磁盘的不同位置,导致磁盘读写时,磁头需要来回移动,降低读写速度,长期下来,会导致系统卡顿。Linux系统的磁盘碎片相对较少,但随着使用时间的增加,还是会产生碎片,尤其是机械硬盘(HDD),碎片对读写速度的影响更明显,固态硬盘(SSD)几乎不受碎片影响,可以不用刻意优化。
常用减少磁盘碎片的方法:① 定期执行fsck指令,检查并修复磁盘碎片,前面已经讲解过fsck指令的用法,注意执行时要卸载磁盘分区;② 避免频繁创建、删除小文件,频繁创建、删除小文件会快速产生磁盘碎片,尽量将小文件合并成大文件,减少碎片产生;③ 合理分配磁盘分区,不要将所有文件都存储在一个分区,比如将系统文件、日志文件、数据文件分别存储在不同分区,减少碎片对整体读写速度的影响。
第三,优化磁盘挂载。磁盘挂载的配置不合理,也会影响磁盘读写速度,比如挂载时没有设置合适的文件系统、没有开启缓存,都会导致磁盘读写速度变慢。常用的优化方法:① 挂载时开启缓存,在/etc/fstab文件中,添加“defaults,noatime”参数,noatime表示不更新文件的访问时间,能减少磁盘IO操作,提升读写速度;② 选择合适的文件系统,Linux常用的文件系统有ext4、xfs,xfs文件系统的读写速度更快,适合大文件存储,ext4文件系统更稳定,适合系统分区,大家可以根据实际情况选择;③ 定期检查磁盘挂载状态,用mount指令查看挂载情况,如果出现挂载异常,及时修复,避免影响磁盘读写。
磁盘优化的核心,就是“清理冗余文件、减少磁盘碎片、优化挂载配置”,定期清理冗余文件,能释放磁盘空间;减少磁盘碎片,能提升磁盘读写速度;优化挂载配置,能进一步提升磁盘性能。只要做好这几点,就能让磁盘长期保持良好的状态,避免因为磁盘问题导致系统卡顿。
五、系统参数优化:精细化调整,提升整体性能(附配置方法)
除了CPU、内存、磁盘的优化,Linux系统的参数配置也很重要,合理的系统参数配置,能进一步提升系统的整体性能,减少卡顿、提升响应速度。很多小白觉得系统参数优化“高深莫测”,不敢轻易修改,其实只要掌握常用的几个参数,按照推荐值调整,就能达到很好的优化效果,而且不会影响系统稳定性。
Linux系统的参数主要存储在/etc/sysctl.conf文件中,修改该文件中的参数,就能实现系统参数的优化,修改后执行sysctl -p指令,使配置生效。下面给大家整理常用的系统参数优化,每一个参数都有详细的说明、推荐值和配置方法,大家可以直接复制到/etc/sysctl.conf文件中,根据自己的系统配置适当调整。
1. 优化TCP连接参数,提升网络性能:TCP连接是Linux系统网络通信的基础,优化TCP连接参数,能提升网络响应速度,减少网络卡顿,适合有网络服务(比如Web服务、数据库服务)的服务器。
常用参数及推荐值:
net.core.somaxconn = 1024 # 最大监听队列长度,默认是128,提高后能处理更多并发连接
net.core.netdev_max_backlog = 4096 # 网络设备接收队列的最大长度,提高后能处理更多网络数据包
net.ipv4.tcp_max_syn_backlog = 2048 # TCP半连接队列的最大长度,防止SYN洪水攻击,提升并发连接能力
net.ipv4.tcp_tw_reuse = 1 # 允许复用TIME_WAIT状态的连接,减少TIME_WAIT连接数量,释放端口资源
net.ipv4.tcp_tw_recycle = 1 # 快速回收TIME_WAIT状态的连接,进一步释放端口资源(注意:NAT网络环境下不建议开启)
net.ipv4.tcp_fin_timeout = 30 # TIME_WAIT状态的连接超时时间,默认是60秒,缩短为30秒,加快端口释放
2. 优化文件描述符参数,提升文件处理能力:文件描述符是Linux系统中用于表示文件、 socket等资源的标识,默认的文件描述符数量较少,当系统中运行的进程、服务较多时,会出现文件描述符不足的问题,导致服务无法正常运行,优化后能提升系统的文件处理能力。
常用参数及推荐值:
fs.file-max = 655350 # 系统最大打开文件描述符数量,默认是65535,提高后能处理更多文件、socket连接
另外,还需要修改用户级别的文件描述符限制,编辑/etc/security/limits.conf文件,添加以下内容:
* soft nofile 65535 # 普通用户的软限制,最多能打开65535个文件描述符
* hard nofile 655350 # 普通用户的硬限制,最多能打开655350个文件描述符
root soft nofile 655350 # root用户的软限制
root hard nofile 655350 # root用户的硬限制
修改完成后,重启系统,或者执行ulimit -n 65535指令,临时生效,用户级别的文件描述符限制就会生效。
3. 优化内存参数,提升内存使用效率:前面已经讲解过内存优化的部分,这里补充几个常用的内存参数,进一步优化内存使用效率,减少内存浪费。
常用参数及推荐值:
vm.swappiness = 10 # 前面讲解过,减少系统对swap分区的使用,优先使用物理内存
vm.dirty_ratio = 20 # 内存中脏数据(未同步到磁盘的数据)的最大比例,默认是20%,超过这个比例,系统会自动将脏数据同步到磁盘
vm.dirty_background_ratio = 10 # 内存中脏数据的后台同步比例,默认是10%,达到这个比例,系统会在后台同步脏数据到磁盘,不影响前台业务
4. 优化磁盘IO参数,提升磁盘读写性能:针对磁盘IO压力较大的服务器,优化磁盘IO参数,能提升磁盘读写速度,减少IO卡顿。
常用参数及推荐值:
vm.dirty_writeback_centisecs = 500 # 脏数据后台同步的间隔时间,单位是毫秒,默认是500毫秒,缩短间隔时间,减少脏数据堆积
blockdev --setra 16384 /dev/sda # 设置磁盘的预读大小,单位是字节,默认是4096字节,提高到16384字节,能提升磁盘读取速度(需要根据磁盘类型调整,SSD可以适当提高)
这里提醒大家,修改系统参数时,一定要谨慎,不要随意修改不熟悉的参数,建议先备份/etc/sysctl.conf文件,备份指令:cp /etc/sysctl.conf /etc/sysctl.conf.bak,一旦修改错误,能及时恢复。另外,不同的服务器配置、业务场景,参数的推荐值也会有所不同,大家可以根据自己的实际情况,适当调整参数值,不要生搬硬套。
系统参数优化的核心,就是“针对性调整,提升整体性能”,根据自己的业务场景,优化TCP连接、文件描述符、内存、磁盘IO等参数,就能让Linux系统的性能更上一层楼,运行更流畅、更稳定。
六、常用优化指令汇总+避坑注意事项(必看)
前面给大家讲解了CPU、内存、磁盘、系统参数的优化技巧和指令,为了方便大家记忆和使用,这里汇总了常用的优化指令,按场景分类,大家可以直接复制执行,同时整理了常见的避坑注意事项,避免大家操作失误,导致系统故障、数据丢失。
一、常用优化指令汇总(按场景分类)
1. CPU优化指令:
top/htop # 查看CPU占用情况
mpstat -P ALL 1 5 # 查看CPU核心占用情况
systemctl stop 服务名 # 关闭无用服务
systemctl disable 服务名 # 禁止服务开机自启
kill -9 PID # 结束异常进程
pkill 进程名 # 批量结束同类进程
nice -n 优先级 PID # 调整进程优先级
cpulimit -p PID -l 50 # 限制进程CPU占用率不超过50%
2. 内存优化指令:
free -h # 查看内存使用情况
vmstat 1 5 # 实时查看内存状态
ps aux --sort=-%mem # 查看进程内存占用情况
sync; echo 3 > /proc/sys/vm/drop_caches # 释放所有内存缓存
sysctl -w vm.swappiness=10 # 临时调整swappiness参数
3. 磁盘优化指令:
df -h # 查看磁盘空间使用情况
du -sh 目录名 # 查看指定目录大小
iostat -x 1 5 # 查看磁盘IO占用情况
fsck /dev/sda1 # 检查并修复磁盘碎片(需卸载分区)
echo "" > /var/log/日志文件名 # 清空日志文件
rm -rf /tmp/* # 清理临时文件
yum clean all / apt clean # 清理软件缓存(CentOS用yum clean all,Ubuntu用apt clean,二选一执行)
yum autoremove -y / apt autoremove -y # 删除无用依赖包(CentOS用yum autoremove -y,Ubuntu用apt autoremove -y,二选一执行)
find /backup -mtime +30 -exec rm -rf {} \; # 删除30天前的备份文件
4. 系统参数优化指令:
vim /etc/sysctl.conf # 编辑系统参数配置文件
sysctl -p # 使系统参数配置生效
vim /etc/security/limits.conf # 编辑用户文件描述符限制
ulimit -n 65535 # 临时调整用户文件描述符限制
blockdev --setra 16384 /dev/sda # 设置磁盘预读大小
5. 定时任务指令(用于定期优化):
crontab -e # 编辑定时任务
crontab -l # 查看定时任务
示例:每天凌晨2点清理内存缓存、日志文件
0 2 * * * sync; echo 3 > /proc/sys/vm/drop_caches && echo "" > /var/log/messages # 注意:echo后用双引号,避免语法错误,CentOS适用;Ubuntu日志路径可替换为/var/log/syslog
二、避坑注意事项(必看)
1. 不要随意结束进程,尤其是PID较小的进程,PID较小的进程多为系统核心进程,误杀会导致系统崩溃;结束进程前,一定要用ps -ef | grep PID查看进程详情,确认是无用进程或异常进程后,再执行kill指令。
2. 删除文件时,一定要谨慎,尤其是rm -rf指令,避免误删核心文件、日志文件、数据文件;删除前最好做好数据备份,或者先查看文件内容,确认无误后再删除。
3. 修改系统参数时,先备份配置文件(比如/etc/sysctl.conf、/etc/security/limits.conf),一旦修改错误,能及时恢复;不要随意修改不熟悉的参数,避免影响系统稳定性。
4. 释放内存缓存时,一定要先执行sync指令,将内存中的数据同步到磁盘,避免因为释放缓存导致数据丢失;释放缓存只是临时缓解内存占用问题,不能替代根源优化。
5. 关闭服务、卸载软件时,一定要确认该服务、软件没有被核心业务使用,避免影响业务运行;关闭服务后,建议观察一段时间,确认系统运行正常,再设置开机不自启。
6. 优化swap分区时,不要随意关闭swap分区,确保物理内存充足后,再考虑关闭;swappiness参数不要设置为0,建议设置为10-20,兼顾稳定性和流畅度。
7. 执行fsck指令时,一定要卸载对应的磁盘分区,否则会导致数据丢失;建议在系统重启时执行,或者在业务低峰期,做好数据备份后执行。
8. 不同发行版的Linux,部分指令有差异(比如CentOS用yum,Ubuntu用apt),执行指令前,确认自己的系统发行版,避免指令错误。
9. 优化完成后,一定要验证优化效果,用top、free、df、iostat等指令查看CPU、内存、磁盘、IO的状态,确认优化有效,没有出现异常。
10. Linux优化是一个持续的过程,不是一次性完成的,建议定期(每周/每月)进行优化维护,清理冗余、排查隐患,让系统长期保持良好的运行状态。
七、总结:Linux优化的核心,是“规范+持续”
其实Linux系统优化,从来都不是“一蹴而就”的事情,也不需要高深的技术,核心就是“规范操作+持续维护”。很多人觉得Linux越用越卡,就是因为平时不注重维护,小问题堆积成大故障,等到卡顿严重、服务崩溃时,才想起优化,这时候不仅麻烦,还可能造成业务损失。总结一下,Linux优化的核心要点:CPU优化,重点是关闭无用服务、结束异常进程、优化进程配置,让CPU“轻装上阵”;内存优化,重点是释放冗余缓存、关闭无用进程、排查内存泄漏、优化swap分区,让内存得到合理利用;磁盘优化,重点是清理冗余文件、减少磁盘碎片、优化挂载配置,提升磁盘读写速度;系统参数优化,重点是针对性调整TCP连接、文件描述符、内存、磁盘IO等参数,提升整体性能。
这篇文章给大家整理的优化技巧、指令、注意事项,都是实战中总结的干货,没有空洞的理论,没有夸张的比喻,小白也能直接照着做。不管你是刚接触Linux的新手,还是有一定经验的运维,都可以把这篇文章收藏起来,平时优化的时候对照查看,节省时间、少踩坑。最后提醒大家,Linux优化不是“一次性操作”,而是一个持续的过程,建议大家养成定期维护的习惯,每周检查一次资源占用、进程状态、磁盘空间,每月进行一次深度优化,清理冗余、排查隐患。只要坚持下去,你的Linux服务器就能长期保持流畅、稳定,再也不用为卡顿熬夜排查,让你少背锅、多省心。
欢迎大家点赞、收藏、转发!


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
