数据不丢的底线:Linux运维如何搭建可靠的3-2-1备份体系?
- 2026-06-22 00:51:20
每位Linux运维人员终会意识到一个现实:服务器的稳定状态,从来都不是永恒的。
这并非因为Linux系统本身不可靠,而是其周边的一切都存在故障可能:硬件会老化、SSD会发生静默故障、系统更新可能引入兼容问题、有人会在错误的目录执行rm -rf命令,更不用说如今勒索软件和恶意程序正越来越多地盯上Linux服务器——并非因为其防护薄弱,而是因为这些服务器承载的业务数据价值极高。
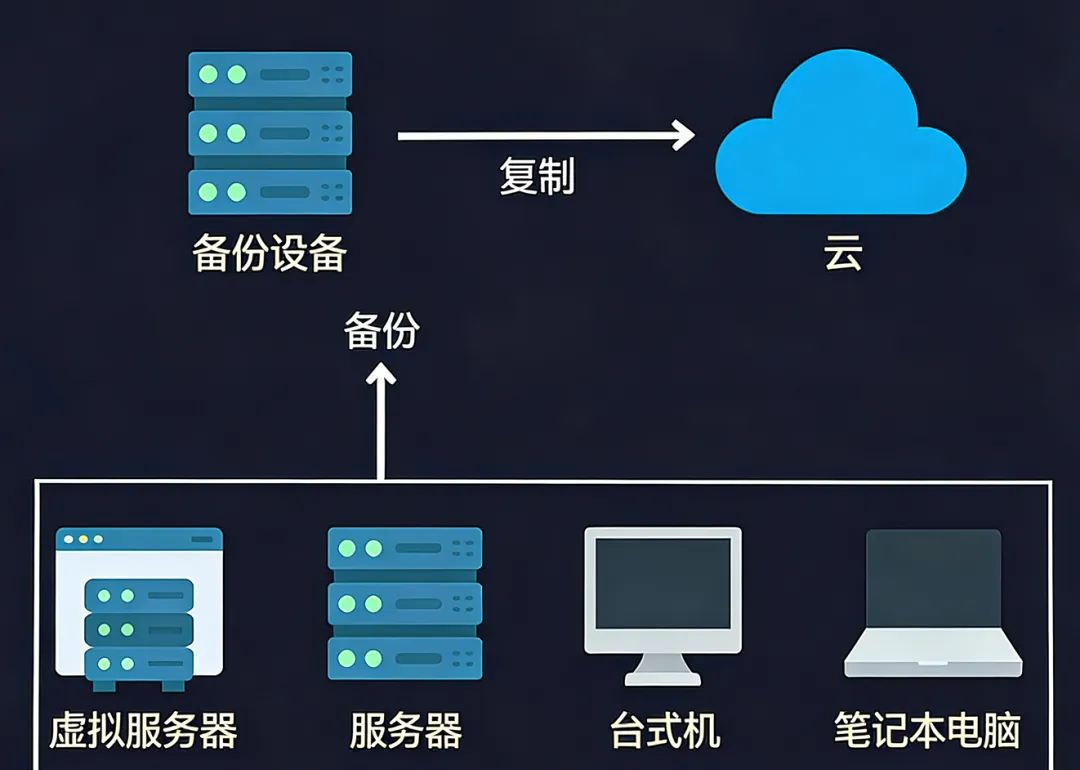
作为运维工程师或网络管理员,搭建一套可靠的备份策略刻不容缓。在挑选合适的工具前,你首先要想清楚一个核心问题:我需要应对哪些实际的故障场景?
答案,就是经典的3-2-1备份策略。本文不会空谈抽象的最佳实践,而是结合实际运维经验,讲解如何在国内环境下落地这套策略,同时适配国内的云服务、工具生态和运维习惯,希望能为你的服务器数据保护提供参考。
💡 小贴士:3-2-1备份策略的实现可以搭配多种工具和存储服务,为了节省时间、减少运维成本,你可以选择国内成熟的一体化备份产品,比如木浪云CDM、Veeam、爱数AnyBackup、鼎甲备份等。本文会结合这类工具的使用逻辑展开,你也可以根据自身需求选择轻量工具组合。
什么是备份3-2-1原则?
3-2-1原则诞生已有数十年,如今已是行业内不成文的标准,核心就三句话:
保留3份数据副本 将副本存储在2种不同类型的存储介质中 确保1份副本为异地存储
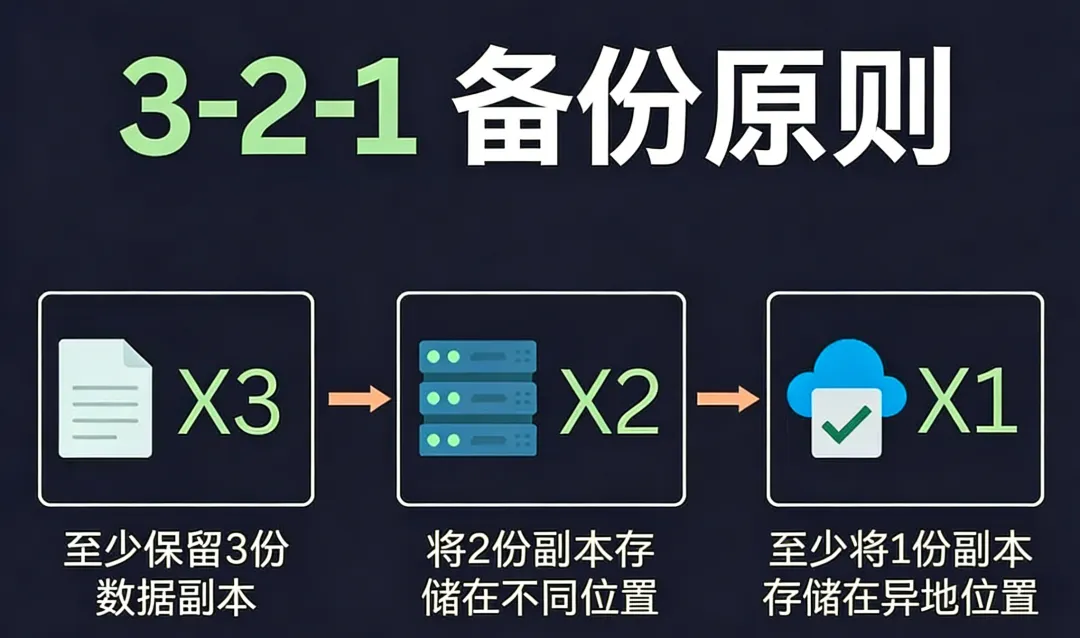
但3-2-1原则的价值,从来不止于数字本身,而是背后的核心思维:预设所有故障可能,围绕数据恢复设计备份体系。
结合国内实际的服务器故障案例,这一原则的每一条都对应着具体的防护场景,具体如下:
理解这一点,你就能更有针对性地为自己的Linux服务器规划备份策略。
第一步:先明确哪些数据值得备份
在接触任何备份软件前,先对生产服务器做了一次全面的资产审计。
Linux系统看似能轻松实现“全量备份”,但盲目备份所有内容,往往会在恢复时引入大量冗余数据,拖慢恢复速度。我的做法是,将服务器数据分为不可替代数据和可重建数据两类,只对核心的不可替代数据做针对性备份。
不可替代数据(重点备份)
这类数据是时间、业务决策和用户行为的沉淀,丢失后无法通过简单操作恢复,也是我备份的核心对象,包括:
应用程序数据目录 数据库(建议导出为逻辑备份文件,而非直接备份原始数据文件) /etc系统配置目录、服务配置文件、系统调优参数、定时任务(crontab)自定义脚本和自动化运维程序 用户生成内容(这部分数据丢失会直接影响业务体验)
可重建数据(无需备份)
如果操作系统崩溃,这类数据可通过重装、重新配置快速恢复,备份它们只会增加存储成本和恢复复杂度,直接排除在备份范围外,包括:
操作系统本身 已安装的软件包(可通过yum/apt/源码重新安装) 临时文件、缓存、日志文件(日志可通过日志平台集中存储,无需纳入备份)
💡 补充说明:如果服务器部署在国内云厂商(阿里云、腾讯云、华为云等),可直接使用其提供的云服务器快照功能(如阿里云ECS快照、腾讯云CVM快照),实现整机/虚拟机的自动化或按需备份,这类功能对快速恢复整台服务器非常友好,适合作为备份的补充。
这一分类策略,能直接减少备份文件的体积、降低备份复杂度,同时大幅提升数据恢复的效率。
备份副本1:生产环境的实时数据(最脆弱的一份)
运行中的服务器本身,就是数据的第一份副本。但这份副本始终处于动态变化中,暴露在用户和各类服务的访问下,也是攻击者最先盯上的目标。
将生产环境的实时数据视为临时态数据,整个备份策略的设计,都建立在“这份副本随时可能故障”的预设上。这种思维转变,是做好备份的关键。
备份副本2:独立存储的本地备份
第二份数据副本存储在本地,但绝对不能和系统盘在同一物理磁盘/存储阵列中。本地备份是国内运维场景中最实用的备份方式,能解决绝大多数日常故障,比如:
误删了重要的目录 配置修改失误导致服务崩溃 前一天的系统/应用更新出现兼容问题
在国内环境下,推荐使用这些工具搭建本地备份:
轻量场景: rsync+crontab,实现增量备份的自动化调度,适合个人或小型团队的服务器企业场景:木浪云CDM、Veeam、爱数AnyBackup、鼎甲,支持可视化配置定时备份、创建增量恢复点,还能实现备份数据的去重和压缩
本地备份的优势是恢复速度最快,无需依赖网络,能在数小时甚至数分钟内将数据回滚到正常状态。但要注意:仅靠本地备份,算不上完整的备份策略。
备份副本3:异地对象存储备份
异地备份,是3-2-1策略中不可妥协的一环。相信很多运维人员都见过这样的笑话:“服务器崩了,备份在哪?”“在服务器上。”

这个场景看似滑稽,却是国内很多中小企业的真实写照。如果服务器遭遇勒索软件攻击,本地备份大概率会被一同加密;如果机房发生火灾、被盗等物理故障,本地的所有数据都会化为乌有。此时,异地备份就是数据恢复的最后一道防线。
第三份数据副本,全部存储在国内主流的云对象存储中,这也是适配国内环境的最佳选择。
国内主流的对象存储服务商
替换海外的Amazon S3、Backblaze B2,国内这些对象存储服务成熟、性价比高,且大多支持S3兼容协议,适配各类备份工具:
阿里云OSS(支持标准、低频、归档等存储类型,备份场景性价比突出) 腾讯云COS(同城多活架构,可靠性高,支持跨地域复制,适合多地容灾) 华为云OBS(冷热分层存储,适配海量数据的长期备份归档) 七牛云Kodo(适合轻量应用和个人开发者,工具生态丰富)
国内常用的异地备份工具
轻量工具: rclone,支持国内所有主流对象存储的配置,可通过命令行实现本地备份文件的加密上传,替代海外的s3cmd企业工具:木浪云CDM(与腾讯云COS深度合作,实现混合云备份,数分钟内可恢复业务)、Veeam(支持将备份数据上传至国内对象存储,自带不可变性防护勒索软件) 云原生方案:直接使用阿里云、腾讯云等厂商的原生备份服务,与云服务器、对象存储无缝衔接,无需额外配置工具
异地备份的核心要求
无论选择哪种工具,都要确保异地备份满足这几点:
数据在本地加密后再上传,传输过程采用SSL加密(国内主流对象存储均默认支持) 配置强制的备份保留策略,防止备份数据被误删或恶意删除 上传完成后自动验证数据完整性,确保备份文件可正常恢复
做到这一点,即便服务器、本地存储、甚至整个机房都出现故障,你依然能从异地对象存储中恢复所有核心数据——这是异地备份的核心价值。
3-2-1中的“2”:存储多样性的真正含义,90%的人都理解错了
很多人会误解“两种存储类型”的要求,认为是“两个云厂商”或“两个不同品牌的磁盘”,但真正的含义是:两个不同的故障域。
故障域,指的是发生故障时,会同时受影响的一组资源。具体为:
本地备份:存储在块存储中(如本地RAID磁盘、企业级存储阵列、腾讯云CBS块存储、阿里云云盘) 异地备份:存储在分布式对象存储中(如阿里云OSS、腾讯云COS)
这两种存储系统的故障逻辑完全不同:文件系统的漏洞不会影响对象存储,云厂商的服务中断也不会影响本地的块存储恢复。这种刻意的隔离,能避免因单一存储类型的故障,导致所有备份副本失效。
自动化:备份策略的生命线,绝不能省略
最危险的备份策略,就是依赖人工执行的策略。无论设置多少提醒,人工备份终会因为遗忘、疏忽而中断——这是国内无数运维事故的教训。
因此,国内运维场景中,建议至少自动化以下环节:
备份调度:按业务需求设置全量/增量备份的时间(如每月全量、每周增量) 保留策略:自动清理过期的备份文件,节省存储成本 加密:本地和异地备份的全程自动加密 上传:本地备份完成后,自动同步至异地对象存储 完整性检查:备份完成后自动校验数据一致性 故障通知:备份失败/警告时,通过钉钉/企业微信/短信推送通知(替换海外的邮件通知,更贴合国内运维的即时沟通需求)
国内的一体化备份工具(如木浪云CDM、Veeam)都支持“一次配置,永久生效”的策略定义,无需像传统方式那样拼接cron任务和脚本。核心原则是:如果备份失败了我却不知道,那和没有备份毫无区别。
恢复测试:所有人都会跳过,却事后追悔莫及的步骤
⚠️ 1份备份 = 没有备份
✅ 2份备份 = 1份有效备份
⛔ 未测试的备份,根本不算备份
一份从未被恢复过的备份,只是你的“心理安慰”,而非真正的保障。这也是国内很多企业在遭遇故障时,明明有备份却无法恢复的核心原因。
因此,定期执行真实的恢复测试是必要的,测试内容包括:
恢复单个文件,验证文件完整性 恢复整个目录,验证目录结构和权限 验证数据库备份文件,确保能正常导入 检查恢复后文件/目录的权限和归属,匹配生产环境的配置
Linux环境下的备份恢复失败,绝大多数并非因为数据丢失,而是因为上下文缺失:路径错误、权限不匹配、服务依赖的状态异常等。而恢复测试,能在故障发生前发现这些问题,此时修复的成本和压力,远低于故障后的紧急修复。
总结
一套可靠的3-2-1备份策略,并非源于对故障的恐惧,而是源于对运维现实的客观认知:服务器总会故障、人总会犯错误、软件总会出现意外。围绕分层存储、故障隔离、可恢复性设计备份体系,最终能让你的数据保护系统变得可预测、低维护、高可靠。
而对于备份来说,“平淡无奇”就是最好的状态——你永远不想体验数据丢失后,手忙脚乱恢复数据的“惊险”。
在国内Linux运维环境中,更推荐兼顾可控性和易用性的工具组合:轻量场景用rsync+rclone+crontab,企业场景用木浪云CDM、Veeam等一体化工具,或直接使用云厂商的原生备份服务。这些工具都不会改变Linux的原生工作逻辑,也不会强制绑定专有存储,能让你完全掌控自己的数据。
如果你现在运行的Linux服务器,还只依赖单一份备份,甚至没有备份——这就是你重新规划数据保护策略的最佳时机,不妨从3-2-1原则开始,为你的数据加上多重保险。
推荐阅读:👉 1.基于 Rocky9 搭建 MySQL8 实践,理解数据库高可用主从架构基础原理👉 2.国产平台实战分享:Kylin系统安装遇RAID卡驱动识别难题,附详细解决步骤👉 3.Jenkins 安装实践:在 Ubuntu 24.04上搭建 CI/CD 自动化平台
请在微信客户端打开
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- python中有關分數操作的一些事
- 【时间序列机器学习】Python14时间序列分布滞后非线性模型(DLNM)拟合及可视化
- 初学Python练题:函数(六),返回值
- 【岩石识别系统】Python+深度学习+人工智能+算法模型+TensorFlow+图像识别+2026计算机毕设项目
- 不会写 Python 也能做爬虫?这款浏览器插件,让我 5 分钟抓了 1000 条数据
- Python编程小技巧--桑基图(Sankey Diagram)
- Python编辑开发JetBrains Pycharm Pro 2024 for Mac v2024.3.6中文直装版安装包【多网盘分享】
- 从零到精通:Python 列表操作的系统化学习手册
- B 站 Python 封神课清单|零基础→就业全免费,照着学少走 90% 弯路(三、爬虫开发)
- 中篇Python(ODOO)篇 第一章 Python基础(六)基础部分 5.字符串
