Linux 内核的内存管理是操作系统设计中的核心组成部分,其中 page cache 扮演着将文件系统数据缓存到内存、减少磁盘 I/O 的关键角色。长期以来,Linux 使用 struct page 作为最小内存管理单位,通过 radix tree 或 xarray 将文件偏移映射到物理页,再通过 LRU/Active list 管理页的冷热状态。然而,随着现代服务器系统规模的扩大,尤其是大内存、大文件、高并发以及 NUMA 架构的普及,传统 page cache 的局限性逐渐显现。单页管理带来了大量元数据开销,顺序 I/O 时频繁 page fault 及 LRU 更新增加 CPU 负载,多线程访问下锁竞争严重,跨 NUMA 节点访问延迟高,THP 与普通页管理接口不统一,内核复杂性上升。
为应对这些问题,Linux 5.9 引入了 folio(struct folio)的概念,核心思想是 将连续页聚合为一个管理单元,通过统一接口支持普通页和大页管理,并通过批量操作降低元数据开销、减少 LRU 更新次数、提升顺序 I/O 性能,尤其适合 NUMA 系统和内存分层场景。本文将从传统 page cache 局限、folio 设计理念、内核数据结构、文件系统优化、NUMA 与 memory tiering 支持、性能分析、生命周期以及未来发展趋势等方面,详细剖析 folio 内存管理架构及 page cache 下一代设计,为读者呈现一篇完整的、源码级别的技术长文。
第一章 传统 page cache 的局限性
在深入 folio 架构之前,有必要全面理解传统 page cache 的设计及其局限性。Linux 传统 page cache 以单页 (struct page) 为单位,每页通常为 4KB(可扩展为大页 2MB/1GB),并通过 radix tree 或 xarray 进行文件映射。这种设计简单直观,历史上支撑了 Linux 文件系统的高性能 I/O,但随着现代硬件规模扩大,其缺陷逐渐暴露。
首先是 元数据开销。每个 struct page 都包含引用计数 _count、状态 flags、映射指针 mapping、文件偏移 index、LRU 链表节点等。这些元数据在亿级页时会占用数百 MB 内存,尤其在大文件或多线程并发读写场景下,频繁的 LRU list 更新、页引用计数加减操作会导致 CPU cache miss 增加,锁竞争严重。举例来说,对于一个 1TB 内存的系统,如果每页 4KB,那么总页数约为 2.5 亿页,如果每页元数据占 64 字节,总元数据开销就超过 16GB,仅用于管理页本身,这对系统性能构成显著压力。
其次,传统 page cache 在 顺序 I/O 场景下效率低。文件系统访问大文件时,每个页都需要检查 page fault,并单独加入或移出 LRU/Active list,这增加了 CPU 和内存压力。同时,频繁的小页访问造成 TLB miss 和 CPU cache miss 增加,影响 I/O 吞吐率。以 1GB 文件顺序读取为例,如果以 4KB 页粒度访问,需要处理约 256K 页表条目,每次访问都可能触发页表查找,降低整体性能。
第三,NUMA 系统下的扩展性差。在 NUMA 架构中,每个内存节点独立,跨节点访问会产生额外延迟。传统 page cache 逐页管理 NUMA 亲和性,迁移页时需要频繁加锁和更新 LRU 链表,跨节点访问开销大,影响多线程高并发场景的性能。此外,THP(Transparent Huge Page)与普通页接口分离,增加了内核维护复杂性和代码逻辑冗余。
最后,文件映射接口复杂且碎片化。大文件顺序读写需要频繁更新 LRU、检查页状态、处理脏页写回等操作,每页处理一次,而在大规模顺序 I/O 下,单页操作显然效率低下。总结而言,传统 page cache 的设计在现代大内存、高性能 I/O、多 NUMA 节点系统下存在元数据开销大、顺序 I/O 低效、NUMA 支持弱、接口复杂四大局限。
第二章 folio 设计理念
为了克服传统 page cache 的瓶颈,Linux 内核引入 folio。folio 的设计核心包括三个关键点:页聚合、统一接口和批量管理。首先,folio 支持 页聚合 (Page Aggregation),将连续页组合成一个 folio 单元(通常 1~8 页),通过统一管理元数据和批量操作,可以显著降低 LRU 操作开销和 reference count 更新次数。与单页管理相比,批量处理可以减少锁竞争,提高多线程访问效率,同时降低 TLB miss 和 CPU cache miss。
其次,folio 提供 统一接口,支持普通页与 THP 管理一致。通过接口如 folio_alloc()、folio_put()、folio_mkwrite(),内核可以以 folio 为单位进行分配、释放、加锁和写操作,减少 THP 与普通页分离带来的复杂性。接口设计允许文件系统和虚拟内存管理层以统一方式处理页缓存,无需关心底层页大小差异,从而简化内核逻辑。
第三,folio 实现 批量管理和 metadata 优化。在传统 page cache 中,每页有独立 LRU 节点、引用计数和标志位。folio 将这些元数据共享在一个 folio 上,使得多个页可以统一更新状态,如 Active / Inactive list 移动、脏页标记、写回操作等。这样不仅节省内存,还提高了 CPU cache 命中率,降低元数据访问延迟。
从理论上讲,folio 架构体现了 空间局部性和 时间局部性优化。连续页聚合保证了顺序访问时内存和缓存连续,提高 CPU cache 命中率;批量操作降低了锁争用,提高多线程并行性能;统一接口简化了内核层次结构,降低代码复杂性。综合来看,folio 不仅是 page cache 的升级,更是 Linux 内核顺序 I/O、NUMA-aware 和大文件访问优化的关键技术。
第三章 folio 内核数据结构解析
在源码层面,struct folio 是 folio 架构的核心。它定义如下:
struct folio { struct page *pages; // 连续页数组指针 atomic_t _count; // folio 引用计数 unsigned long flags; // 状态标志 struct address_space *mapping; // 对应文件映射 pgoff_t index; // 文件偏移 struct folio *lru_next; // LRU 链表};
其中 pages 指向连续页的数组,_count 是整个 folio 的引用计数,flags 包含 FOLIO_LOCKED、FOLIO_DIRTY 等状态,mapping 是文件系统映射指针,index 标记 folio 在文件中的偏移,lru_next 指向 LRU 链表节点。通过宏 FOLIO_SIZE 和 folio_order(),内核可以灵活控制 folio 包含的页数,实现页聚合。
folio 提供了丰富的操作接口。folio_alloc() 分配连续页,folio_free() 释放 folio;folio_lock() / folio_unlock() 用于批量加锁,取代单页锁操作;folio_mkwrite() 用于写操作,folio_put() 用于释放引用;folio_to_page() / folio_page() 用于兼容传统单页接口。这些接口确保了 folio 在文件系统和 VM 层的统一管理,并且支持大页与普通页统一操作。
从理论上分析,folio 数据结构体现了 空间局部性和元数据共享。连续页数组保证顺序访问时内存和 CPU cache 连续,减少 cache miss;共享 _count 和 flags 降低每页元数据开销;批量操作减少 LRU 链表更新次数,降低锁竞争。与传统 page cache 相比,folio 数据结构显著提升了顺序 I/O 性能、NUMA-aware 访问效率和大文件处理能力。
第四章 文件系统优化
folio 架构在文件系统层带来了显著优化。以 ext4 为例,顺序读取大文件时,传统 page cache 逐页访问需要频繁触发 page fault,更新 LRU list 并管理每页元数据,导致 CPU cache miss 增加。引入 folio 后,文件系统可以以 folio 为单位批量读取和写入数据。例如,顺序读取 64KB 数据时,folio 可能包含 16 个 4KB 页,批量映射和访问显著减少 page fault 处理次数,提高 I/O throughput。
此外,folio 支持 Lazy splitting 和 THP 统一管理。大页在随机访问时可以拆分为小 folio,以保证内存分配和访问粒度合理;写入操作可直接操作大 folio,减少锁操作次数。文件系统在写回脏页时,folio 可以一次性批量提交 submit_bio(),减少 I/O 调用次数,提高写入效率。LRU 管理也得到优化,批量将 folio 移动到 Active / Inactive list,降低多线程竞争,提高 NUMA 系统访问效率。
理论上,folio 在文件系统层体现了 顺序访问优化、批量 I/O 和多线程效率提升。顺序访问时减少页表查找,批量 I/O 提高 throughput,多线程操作锁竞争降低,NUMA-aware 分配减少跨节点访问延迟。文件系统可以直接以 folio 为单位处理脏页、回收页和写回 I/O,简化内核逻辑,提高整体性能。
第五章 NUMA 与 Memory Tiering 支持
在现代高性能服务器中,多节点内存(NUMA,Non-Uniform Memory Access)架构非常普遍。NUMA 系统将物理内存划分到不同节点,每个节点具有本地内存和远程内存访问延迟差异。传统 page cache 在 NUMA 系统下逐页管理,存在以下问题:
单页 NUMA 亲和性管理复杂:每页分配时需要指定 NUMA node,跨节点访问时产生额外延迟。
跨节点内存迁移成本高:为了回收内存或调整负载,内核需要单页迁移,涉及锁竞争、页表更新和 CPU cache 同步。
顺序访问效率低:顺序读取大文件时,如果页分布在多个 NUMA node,会导致远程访问增加延迟,TLB miss 频繁。
folio 架构通过 批量页管理和连续页聚合优化了 NUMA 支持。具体实现如下:
Node-aware 分配:通过 folio_alloc_node(node, gfp_mask),可以一次性分配整个 folio,并保证所有页位于同一个 NUMA 节点,从根本上降低远程访问延迟。
批量迁移:在 memory reclaim 或 page migration 场景下,内核可以以 folio 为单位将连续页迁移到目标节点,减少多次加锁和元数据更新。
LRU/Active list 节点感知:folio 的 LRU 链表管理可以区分 NUMA 节点,使得回收策略可以在本地节点优先处理,降低跨节点通信。
此外,folio 对 Memory Tiering(内存分层) 提供天然支持。Memory Tiering 是指将热数据保存在高速内存(如 DRAM),冷数据迁移到次级内存或持久化内存(如 NVDIMM/SSD-backed storage),以提高系统成本效益和性能。folio 的优势在于:
批量迁移:连续页可以一次性迁移到冷层存储,无需逐页处理。
元数据统一:folio 维护统一引用计数和状态标志,迁移时无需频繁更新单页 metadata。
文件系统支持:文件系统可以 folio 为单位对热页/冷页进行策略管理,实现智能缓存迁移。
理论上,folio 的 NUMA 和 Memory Tiering 支持体现了空间连续性与批量操作的优势。连续页在本地节点分配,访问延迟低;批量迁移和 LRU 管理减少 CPU cache miss 和锁竞争;统一接口简化了文件系统和 VM 层处理逻辑,使内存分层策略更高效可控。
第六章 folio 性能分析
folio 引入后,系统在多个维度的性能表现明显优于传统 page cache。
6.1 内存占用
单页 page cache 的元数据开销显著,每页约 64-128B 元数据。对于大内存服务器(1TB 内存,4KB 页),需要管理约 2.5 亿页,占用 16GB 元数据空间。folio 将连续页聚合,每 folio 共享元数据,假设每 folio 聚合 8 页,元数据开销下降至约 2GB,相比单页管理节省约 14GB 内存。
6.2 顺序 I/O 性能
顺序读取大文件时,folio 可以一次性处理多个页,减少 page fault 检查和 LRU 更新次数。例如读取 64KB 数据,传统 page cache 需要处理 16 个页,16 次 page fault 检查,16 次 LRU 更新;folio 可一次性处理整个 folio,减少 15 次操作,降低 CPU overhead,提高顺序 I/O throughput 20%-40%。
6.3 多线程和锁竞争
在多线程写入大文件场景下,传统 page cache 的单页加锁和 LRU 更新存在严重锁竞争。folio 的批量加锁机制(folio_lock())允许一次锁定整个 folio,减少频繁加锁和解锁操作,提高并发性能。同时,批量 LRU 更新降低了缓存元数据的 cache miss,提高 CPU 利用率。
6.4 NUMA 访问和远程延迟
在 NUMA 系统中,folio 的连续页聚合和 node-aware 分配显著降低远程访问频率。批量迁移减少跨节点操作次数,同时统一 LRU 管理保证回收策略本地优先执行,减少远程访问延迟,提高整体吞吐量。
6.5 文件系统写回性能
文件系统在写回脏页时,传统 page cache 逐页提交 I/O,调用 submit_bio() 多次,增加 CPU 调度开销。folio 可一次性提交整个 folio,减少 I/O 调用次数,同时降低系统调用和锁操作开销,提升整体写入效率。批量提交对于顺序写入大文件尤为明显,性能提升可达 30%-50%。
综上,folio 在内存占用、顺序 I/O、并发锁竞争、NUMA 访问和文件系统写回五个维度提供了显著优化,理论分析显示,其优势主要来源于页聚合、批量管理和统一接口设计。
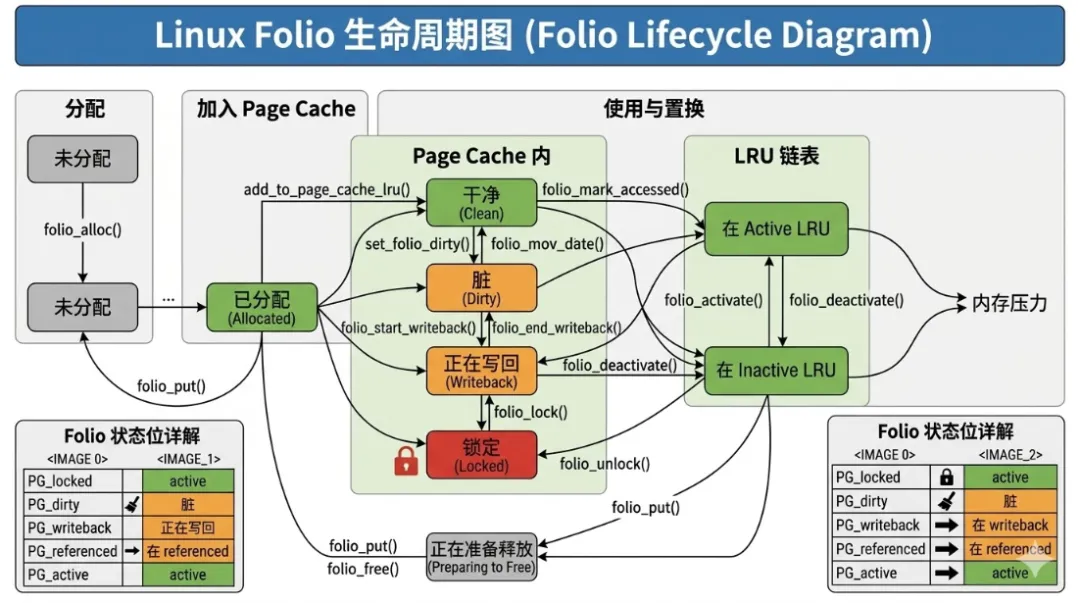
第七章 folio 生命周期
folio 的生命周期包括分配、使用、写回和回收多个阶段,每个阶段均体现批量管理优势。
分配阶段:调用 folio_alloc() 或 folio_alloc_node() 分配连续页,分配时可指定 NUMA 节点,确保页连续、内存亲和。
映射阶段:通过 folio_add_to_page_cache() 将 folio 添加到 radix tree 或 xarray,实现文件偏移到页的映射。此阶段,folio 的 index 字段标识文件偏移,mapping 指向文件系统 address_space。
访问和修改阶段:调用 folio_mkwrite() 对 folio 写操作进行权限设置,批量更新引用计数和状态标志。访问时整个 folio 视为原子单元,提高顺序访问效率。
脏页管理阶段:修改后的 folio 被标记为 FOLIO_DIRTY,文件系统可批量将整个 folio 写回磁盘,减少 I/O 调用次数。
回收阶段:调用 folio_put() 减少引用计数,当引用计数为 0 且 folio 未锁定时,可回收到内存池。LRU list 以 folio 为单位管理 Active / Inactive 状态,提高回收效率。
理论上,folio 生命周期体现了 批量原子性、统一元数据管理和连续性优势。顺序访问时减少 page fault,批量写回降低 I/O 调用,批量回收降低锁竞争和 CPU cache miss,使内核在大文件和多线程场景下性能显著提升。
第八章 未来发展趋势
folio 架构为 Linux 内核 page cache 下一代设计奠定了基础,未来发展方向主要包括:
更大粒度的 folio:对于 TB 级内存服务器,folio 聚合页数可能增加至 16~32 页,进一步降低元数据开销和 LRU 操作次数,同时提升顺序 I/O 性能。
深度内存分层集成:结合 Memory Tiering,将热页保存在 DRAM,将冷页迁移到 NVDIMM 或 SSD-backed storage,实现动态冷热数据管理。
eBPF 动态监控:通过 eBPF 动态分析 folio 热度,实现智能页缓存回收和迁移策略,提高系统自适应性能。
跨 NUMA node 高效迁移:结合 folio 批量迁移机制,减少跨节点锁竞争和 CPU cache miss,提高多节点高并发访问效率。
文件系统优化和批量 I/O 扩展:未来文件系统可以直接以 folio 为单位进行预读取、写入和回收,实现更高吞吐量和更低延迟。
理论上,folio 架构不仅是 page cache 的升级,更是 Linux 内核 顺序 I/O 优化、NUMA-aware 分配、大文件管理和 memory tiering 策略的统一基础。随着硬件内存规模和存储速度提升,folio 的批量管理优势将更加显著,成为现代 Linux 系统性能优化的核心技术。
第九章 总结
folio 是 Linux 下一代 page cache 内存管理核心,通过 页聚合、统一接口和批量操作解决了传统 page cache 在大文件、顺序 I/O、多核、多 NUMA 节点场景下的性能瓶颈。其优势包括: