Python代码|约束线分析(OLS+二次多项式/三次多项式回归拟合)+阈值识别
本篇文章是在之前双约束线分析的代码基础上进行方法的优化与内容增加。增加的OLS回归分析能够提高数据的R2,增加数据的可解释性。
在处理野外真实采样或宏观社会经济调查时,大家经常会面对上万个杂乱无章的散点数据。传统的回归分析在这里往往会彻底失效。在不同自变量水平下,因变量可能受到什么上限约束、下限约束,以及这种约束如何变化。
这套代码用来提取约束线边界线与阈值识别,用来解决复杂自然或社会系统中传统均值回归彻底失效的难题。当面对海量且高度离散的散点数据时,算法首先将数据空间沿横轴均匀切分为多个垂直区块,并精准抽取每个区块内最顶部与最底部的百分之五极值点,果断剔除受多重未知因素干扰的中间普通样本。
随后,程序调用普通最小二乘法对这些提纯后的边界点进行二次或三次多项式独立拟合,并生成带有95%置信区间的平滑约束曲线。
完整代码获取,关注公众号回复“ 约束线 ”即可获得获取方式
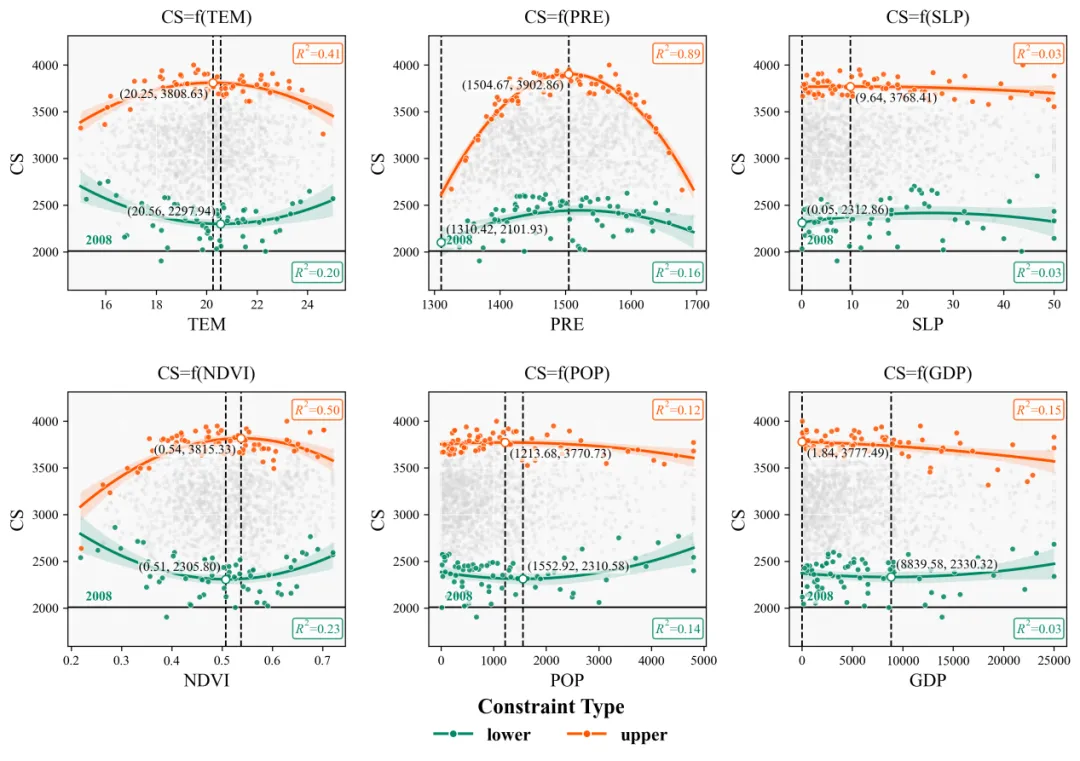
▶ 输出结果:
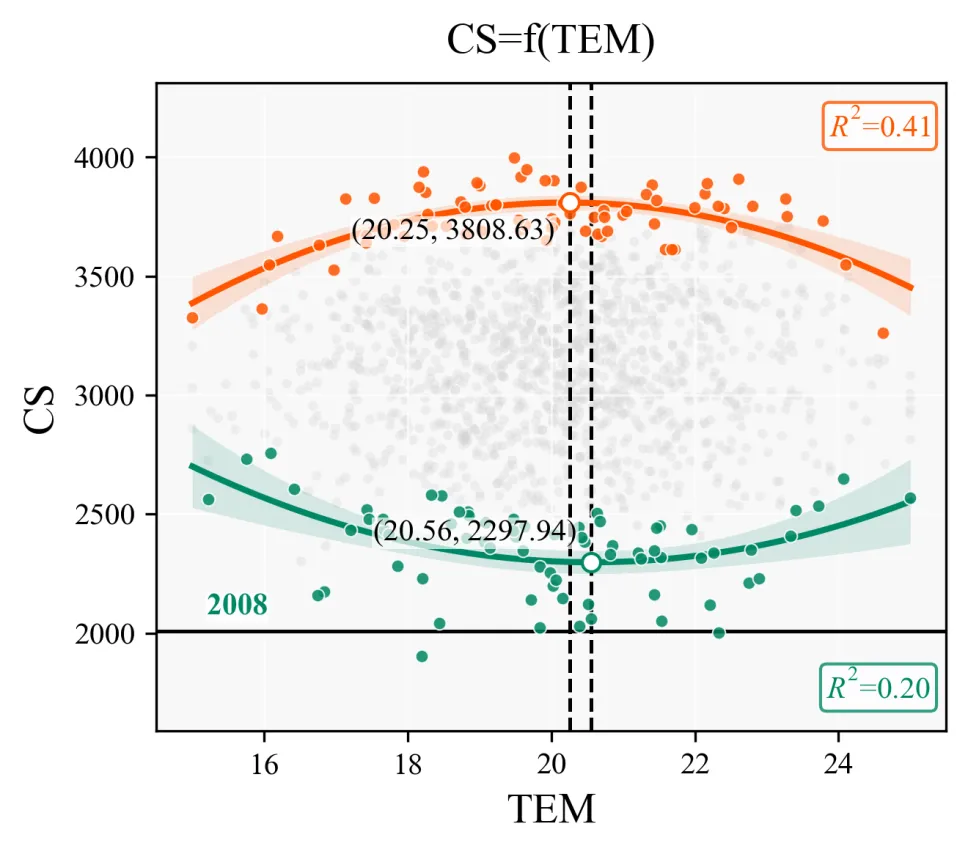
▶ 输出结果解读:
灰色背景散点:这些散点代表原始观测数据,也就是样本的真实分布状态。科研上,背景散点最重要的意义不是好不好看,而是帮助我们判断数据是否存在离散、聚集、偏态、异方差,或者某些区间样本特别稀疏的问题。也就是说,灰色散点让我们先看到真实数据本身的结构。
上边界散点,下边界散点:从科研解释上说,上边界散点不是普通的高值点,而是表示在某一自变量水平下,因变量能够达到的潜在上限;下边界散点也不是普通的低值点,而是表示该条件下系统可能出现的潜在下限。所以,这类图强调的不是平均趋势,而是边界趋势。
上边界拟合线和下边界拟合线:这两条线不是对全部数据求平均后的总体回归线,而是分别描述系统上限和下限随自变量变化的趋势。这代表自变量改变时,因变量的最大可达水平和最小可能水平会怎样变化。这是一种更符合复杂系统分析的方法。如果上边界线向上抬升,说明随着自变量增加,系统的最佳表现被放宽了;如果下边界线也在上移,说明连最低表现都在改善;如果两条边界线之间的距离越来越大,说明系统不确定性在扩大;如果距离缩小,则说明系统在该范围内更稳定、更受控。
95%置信区间:阴影越窄,说明该区间内边界趋势估计更稳定;阴影越宽,说明该位置的不确定性更大,可能是因为样本少、波动大,或者拟合在该区域不够可靠。
上边界曲线的峰值点、下边界曲线的谷值点:峰值点可以理解为在这条上限关系中,自变量取某个值时,因变量的潜在最高水平达到最大;谷值点则对应因变量潜在最低水平最差的位置。
垂直参考线和坐标注释:垂直参考线的作用,是把这个关键点对应的自变量位置明确地投射到横轴上,便于我们直接读出阈值所在。旁边标出的坐标值,则让图从定性描述提升到定量表达。科研里最怕只说这里有个峰值,却说不清峰值出现在什么范围、对应什么数量级;有了这些坐标,图就可以直接服务于结果汇报、论文讨论和参数建议。
底部水平基准线:这条线可以理解成一个参照水平,基准线常用于判断某些点或某些区域是否处于较低水平、临界水平或背景水平附近。尤其当不同变量生成多张子图时,基准线能够帮助我们更直观地比较:哪一个自变量对应的下边界抬升更明显,哪一个自变量对应的低值风险更突出。它相当于给图增加了一条判读尺。
R²数值:这里的 R²不是在评价全部原始数据的整体相关程度,而是分别在评价上边界拟合和下边界拟合的解释程度。R²越高,说明边界曲线对这些被提取出来的边界点解释得越好;R²越低,则说明边界关系可能更复杂,或者当前模型形式对边界的刻画还不充分。
▶代码运行:
1.代码运行前需要先安装模型库:
新建文件——复制代码:pip install pandas numpy matplotlib statsmodels openpyxl
点击运行,等待安装成功。还有其他安装方法,小伙伴们可以自行查找。
2.数据准备
将所有数据放在Excel文件中,第一列为Y(因变量/目标),其他列为X(自变量/特征)。
3.输入Excel文件路径:复制粘贴您的Excel文件,输入导出文件名。点击运行
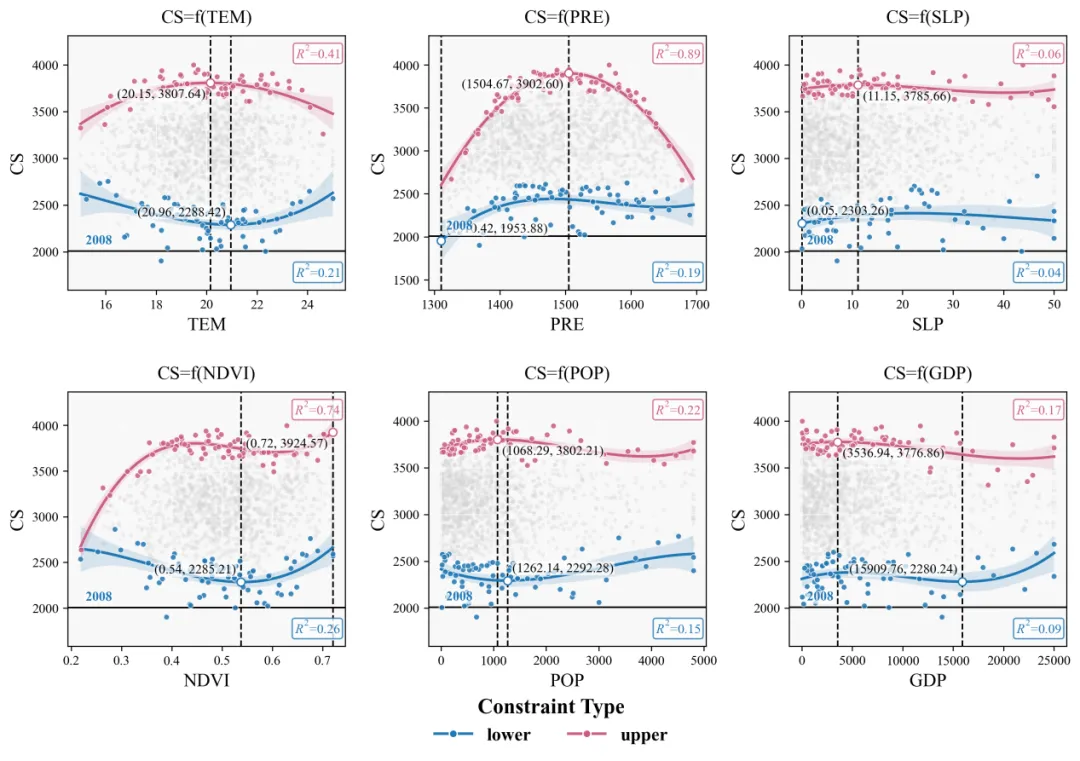
自定义配色区域:

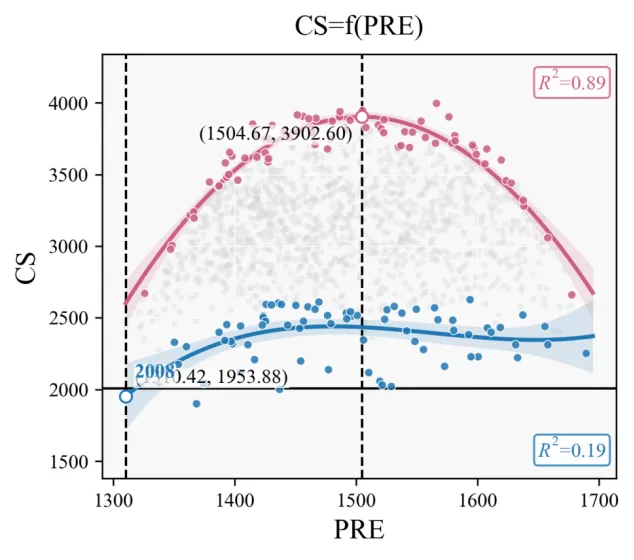
不同配色的输出结果:
完整代码获取,关注公众号回复“ 约束线 ”即可获得获取方式
全中文注释代码,替换自己的Excel数据即可运行
包含:完整Python代码( .ipynb格式和.py格式)
示范数据(Excel文件)
运行结果图片(png+PDF)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
