不少刚开始接触 Python 的小伙伴,经常会遇到一种“灵异事件”:明明代码是照着敲的,一字不差,但运行起来就是报错。
今天,我们就来拆解一个零基础小白最容易踩的坑。
诡异的报错:我的 random 怎么失灵了?
假设我们现在要写一段简单的代码,生成一个随机数。按照常理,我们会这样写:
import random# 生成一个1到10之间的随机整数num = random.randint(1, 10)print(num)
这段代码看起来逻辑清晰、语法严谨,对吧?
但是,当你满怀信心按下运行键时,控制台却跳出了一串冷冰冰的红字:
❝AttributeError: module 'random' has no attribute 'randint'
你可能会揉揉眼睛大喊:“这不可能!random 模块里明明有 randint 这个函数,我确定以及肯定!”
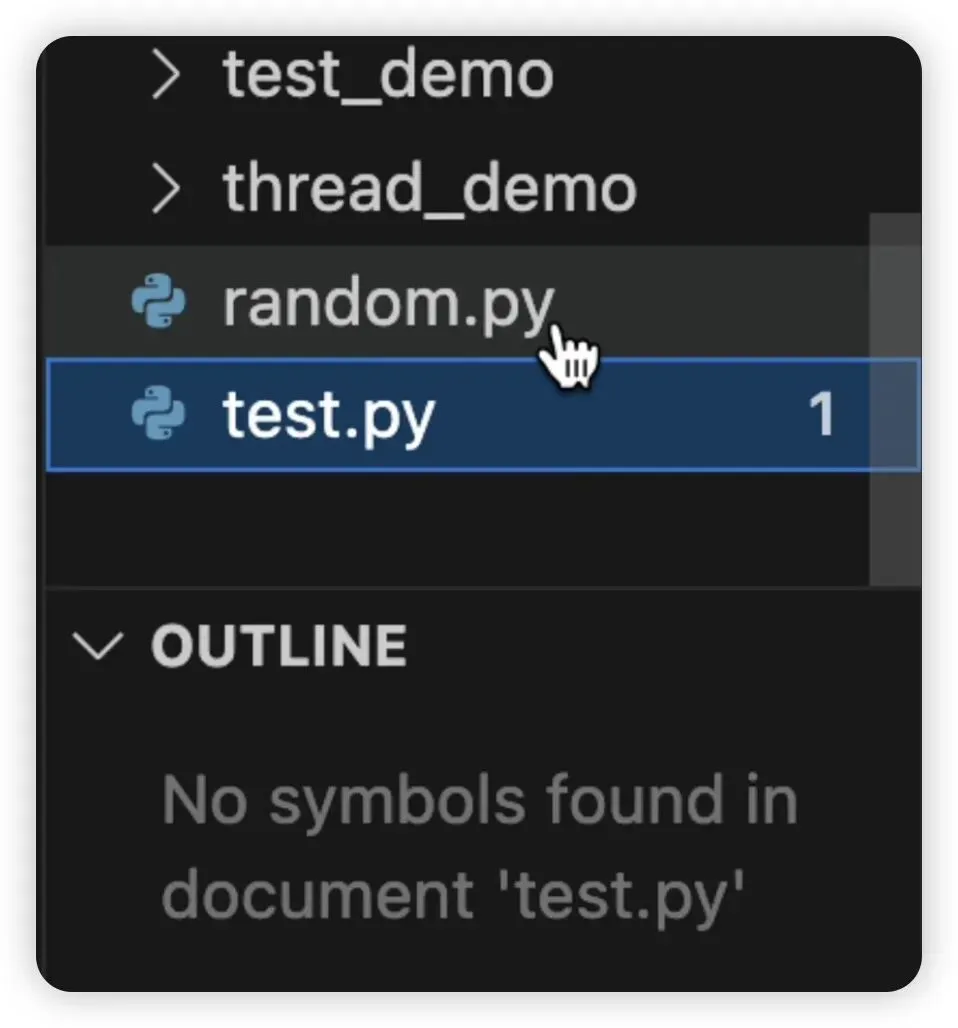
破案现场:真相就在你的左边栏
其实,问题根本不在于 Python 的标准库,而是在于你的目录结构。
请大家盯着你的项目文件夹看。你会发现,在当前目录下,你是不是为了方便记忆,顺手把自己的脚本文件也命名成了 **random.py**?
真相大白了: 当你执行 import random 时,Python 并没有去调用那个官方自带的、功能强大的随机数标准库,而是“就近”加载了你自己写的那个 random.py。
既然你自己的文件里没有定义 randint 函数,程序当然会理直气壮地报错给你看。
深度硬核:Python 到底是怎么找模块的?
为了彻底搞明白这个问题,我们需要掌握 Python 的模块搜索路径优先级。
我们可以使用 sys 模块写一段简单的代码来观察 Python 的查找逻辑。注意,为了让结果更清晰,我们建议使用 for 循环逐行打印(如下图所示):
import sys# 逐行打印路径,优先级从上到下for item in sys.path: print(item)
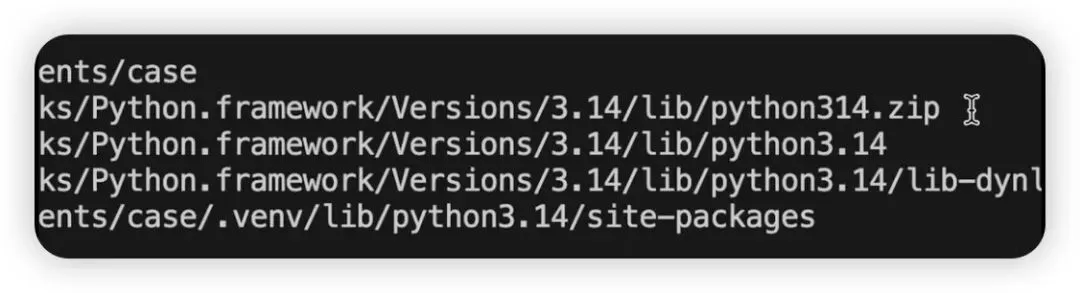
当你运行这段代码,观察输出结果,你会发现一个惊人的规律:
- 排名第一的路径: 永远是当前目录(即你存放脚本的那个文件夹)。
- 后续路径: 依次是
python3.14.zip(标准库压缩文件)、官方标准库路径、dynload(动态加载库),最后才是我们通过 pip 安装的 site-packages(第三方包)。
划重点:由于当前目录的优先级最高,一旦你给自己的文件起了一个和系统库一模一样的名字,就会发生“模块遮蔽”现象。
你的 Python 此时就像是“认贼作父”,对着你那个空空如也的 random.py 猛使劲,自然找不到任何实现方法。
这个坑虽然小,但杀伤力极大,尤其是当你还在学习阶段,习惯用知识点给文件命名(比如 string.py, json.py, test.py)时,最容易中招。
避坑请记牢:
- 起名要避嫌: 永远不要让你的文件名与 Python 的内置模块、标准库或第三方库重名。
- 报错先看路径: 遇到
AttributeError 却确定方法存在时,第一时间检查当前目录下有没有同名文件。
你还遇到过哪些让你抓狂的 Python “灵异”报错?欢迎在评论区留言,我们一起避坑!
想要获取更多 Python 实战小技巧吗?点击下方名片关注我,每天一分钟,带你从小白进阶大牛!

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
