先看一张框架图,有助于理解内容,有不懂的先收藏或者评论区讨论。第一章:I/O 分层架构与语义转换
1.1 从用户语义到块设备语义的抽象塌缩
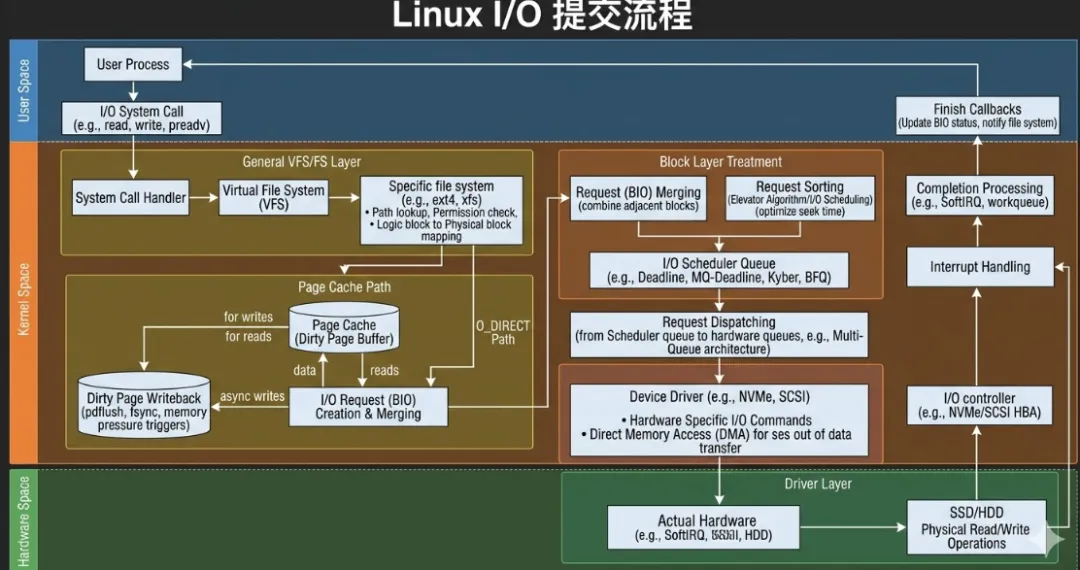
Linux I/O 的本质不是简单的数据拷贝,而是一次“语义逐层塌缩”的过程:用户态通过 write(fd, buf, len) 发起的是字节流语义,但在内核中这一语义会逐层映射为更贴近硬件的表示形式,最终转化为块设备可以识别的 LBA 写入请求。整个路径遵循严格的分层结构:系统调用层负责上下文切换与参数校验,VFS 层提供统一接口抽象,文件系统负责逻辑块到物理块的映射与元数据一致性维护,页缓存负责数据缓冲与写合并,块层负责请求调度与队列化,而驱动层最终将请求转化为 DMA 操作与设备队列提交。这里最关键的设计思想在于:每一层只处理本层抽象,不感知更底层细节,例如 VFS 不关心 ext4 还是 xfs,而块层也不关心数据来自 page cache 还是 direct I/O,这种“抽象隔离”保证了 Linux I/O 栈的高度可扩展性。
从数据结构角度看,这一过程由一条核心链路贯穿:
file → inode → address_space → page → bio → request
其中 file 表示用户打开的文件实例,inode 提供文件元数据与地址空间入口,address_space 管理页缓存,page/folio 承载具体数据页,bio 描述块 I/O 片段,而 request 则是块层调度单位。这个链路不仅是数据流路径,同时也是控制流的依附对象,因此理解这条链路等价于理解 I/O 的“骨架”。
1.2 Buffered I/O 与 Direct I/O 的路径分裂
在进入文件系统之后,I/O 路径会发生第一次关键分裂:Buffered I/O 与 Direct I/O。Buffered I/O 通过 page cache 作为中间层,将写操作转化为对内存页的修改,数据被标记为 dirty 并延迟写回磁盘,这种模式本质上是“写时缓冲 + 后台批量提交”,其核心优势在于可以显著减少随机写并通过页合并提升吞吐,但代价是数据持久性不可控(必须依赖 fsync 或 writeback 机制)。相对地,Direct I/O 通过 O_DIRECT 标志绕过 page cache,直接将用户 buffer 映射为块 I/O,请求立即进入块层,这种模式消除了双拷贝并降低延迟,但要求严格的地址、长度和文件偏移对齐,同时失去了缓存带来的读写优化能力。
更深层来看,这两条路径的差异不仅在“是否经过 page cache”,而在于I/O 生命周期的控制权:Buffered I/O 将控制权交给内核的 writeback 子系统,而 Direct I/O 则由调用者直接驱动 I/O 提交节奏。因此数据库、存储引擎等对延迟敏感的系统更倾向 Direct I/O,而通用应用则依赖 Buffered I/O 提供更高吞吐与更简单的编程模型。
第二章:write() 系统调用到 VFS 分发
2.1 系统调用路径与内核入口收敛
I/O 提交流程从系统调用入口开始,其核心路径为:
__x64_sys_write → ksys_write → vfs_write → __vfs_write → file->f_op->write_iter
在这一链路中,前半部分(syscall → ksys_write)主要负责用户态与内核态切换、参数合法性校验以及文件描述符解析,而真正的 I/O 分发发生在 VFS 层。VFS 作为虚拟文件系统,其职责并不是执行 I/O,而是根据 struct file 中的 file_operations 指针,将操作路由到具体文件系统实现。这里的关键设计在于:通过函数指针实现“运行时多态”,使得 ext4、xfs、btrfs 等文件系统可以在同一接口下提供完全不同的实现路径。
此外,write 系统调用并不直接处理单一 buffer,而是通过 iov_iter 抽象统一描述用户态数据源,这一设计支持 writev、splice、sendfile 等多种 I/O 形态。iov_iter 将分散的用户缓冲区组织为一个逻辑连续的数据流,使得后续处理无需关心数据来源细节,从而实现 I/O 框架的通用化。
2.2 数据拷贝与零拷贝路径分化
在 VFS 层之后,数据从用户态进入内核态通常需要经过 copy_from_user(),这是一个不可避免的安全边界检查过程,用于防止非法地址访问。然而在高性能场景中,这种拷贝会成为瓶颈,因此 Linux 提供了多种“绕过拷贝”的机制,例如 splice、sendfile 以及 Direct I/O。这些机制的共同点在于:避免数据在用户态与内核态之间的重复复制,而是通过页引用或 DMA 映射直接构建 I/O 请求。
值得注意的是,即使在 Buffered I/O 路径中,拷贝也只发生一次(用户态 → page cache),之后的数据流动全部在内核内部完成,不再回到用户空间。因此 page cache 本质上既是缓存层,也是“零拷贝优化”的基础设施。在现代内核中,随着 folio 结构的引入,页缓存的管理粒度和效率进一步提升,使得大页(large folio)可以减少页管理开销,从而提升高吞吐 I/O 场景的性能。
第三章:Page Cache 写路径与写回机制
3.1 写入路径:从 write_iter 到 dirty page
在Buffered I/O 模式下,write 调用最终进入 generic_perform_write,其核心流程包括:查找或分配 page(通过 xarray 管理)、调用 write_begin 建立写上下文、将用户数据拷贝到页中、最后通过 write_end 完成状态更新并标记页为 dirty。这一过程的关键在于:I/O 并未立即提交,而只是修改了内存中的缓存页状态。页缓存通过 address_space 结构进行统一管理,每个 inode 对应一个 address_space,其中维护着页索引结构以及写回控制信息。
dirty page 的产生标志着数据进入“待持久化”状态,其生命周期遵循:Clean → Dirty → Writeback → Clean。Linux 内核通过精细的脏页控制策略(如 dirty_ratio、dirty_background_ratio)来平衡内存占用与 I/O 带宽使用,从而避免突发性写回造成系统抖动。
3.2 写回机制:延迟提交与批处理优化
脏页不会立即写入磁盘,而是由 writeback 子系统异步处理,其核心入口为:
wb_workfn → wb_writeback → writeback_sb_inodes → do_writepages
最终调用文件系统实现的 writepages 方法(如 ext4_writepages)。这一设计的核心目标是:通过延迟与合并,将大量小写操作转化为少量大 I/O 请求。在写回过程中,内核会根据页的脏时间、优先级以及 I/O 压力进行排序与调度,从而实现更优的磁盘访问模式。
进一步来看,writeback 不只是一个“刷盘机制”,而是一个复杂的资源调度系统,它需要同时考虑内存压力、I/O 带宽、文件系统一致性以及应用的 fsync 语义。例如,当应用调用 fsync 时,writeback 必须强制将相关 dirty page 同步写入磁盘,并确保元数据一致性,这一过程往往涉及日志提交(journal commit),也是 I/O 延迟的重要来源之一。
第四章:Direct I/O 与 iomap 直通路径
4.1 Direct I/O 提交链路
Direct I/O 路径绕过 page cache,其核心调用链为:
ext4_file_write_iter → ext4_direct_IO → iomap_dio_rw
在这一过程中,内核不再分配 page cache,而是直接将用户 buffer 映射为块 I/O 请求。现代 Linux 内核普遍采用 iomap 框架来统一 Direct I/O 与 DAX(直接访问持久内存)的实现,其核心功能是建立文件偏移到物理块的映射关系,并基于该映射构建 BIO 结构。
4.2 BIO 构建与对齐约束
在 Direct I/O 中,BIO 的构建直接基于用户提供的内存页,通过 bio_add_page 将页加入 BIO 向量中,随后提交到块层。这一过程要求用户 buffer、文件偏移以及 I/O 长度满足设备对齐要求(通常为 512B 或 4KB),否则内核将拒绝或回退到 Buffered I/O。由于缺乏 page cache 的缓冲与合并能力,Direct I/O 的性能高度依赖 I/O 请求的大小与对齐情况,小 I/O 或未对齐访问会显著降低性能。
从系统设计角度看,Direct I/O 实际上是将 I/O 调度权交给用户空间,使应用能够精确控制 I/O 行为,但同时也要求应用具备更高的 I/O 模型设计能力,否则很容易因请求粒度不合理而导致性能退化。
第五章:Block Layer 与 blk-mq 多队列模型
5.1 BIO 到 Request 的转换与提交
无论是 Buffered I/O 的 writeback,还是 Direct I/O,最终都会生成 BIO 并通过
submit_bio → generic_make_request → blk_mq_submit_bio
进入块层。在 blk-mq(multi-queue)架构下,BIO 会被映射为 request,并分配到对应的 software queue(per-CPU)与 hardware queue 中。这一设计彻底解决了传统单队列模型中的锁竞争问题,使得多核系统能够并行提交 I/O 请求。
5.2 调度、合并与队列映射机制
在 request 生成之后,块层会根据 I/O 调度器(如 mq-deadline、kyber、bfq)对请求进行排序与合并。合并策略包括前向合并与后向合并,其目标是减少磁盘寻道或提升顺序访问比例。随后 request 会被映射到具体的硬件队列(blk_mq_hw_ctx),并通过调度器策略控制发往设备的请求节奏。对于 NVMe 设备而言,多队列模型可以直接映射到硬件 submission queue,从而实现真正的并行 I/O。
这一阶段的本质是:将离散的 BIO 请求组织为高效的硬件访问序列,并在吞吐与延迟之间取得平衡。
第六章:驱动提交与 I/O 完成闭环
6.1 驱动层提交与 DMA 执行
当 request 被分发到驱动层后,块层会调用驱动实现的 queue_rq 接口(例如 NVMe 的 nvme_queue_rq),驱动负责将 request 转换为设备可识别的命令结构,并建立 DMA 映射,将内存数据地址告知设备。随后通过写 doorbell 寄存器通知设备开始执行 I/O。这一过程完全在内核与硬件之间完成,CPU 仅负责提交与管理,不参与数据搬运,从而实现高效的数据传输。
6.2 中断完成与上层回调收敛
当设备完成 I/O 后,会通过中断通知 CPU,内核进入中断处理流程,调用 blk_mq_complete_request 完成 request 生命周期,并逐层回调到 bio_endio。对于 Buffered I/O,这意味着页状态从 writeback 转为 clean;对于 Direct I/O,则意味着用户请求完成,可以返回给应用。至此,一个完整的 I/O 闭环结束,其路径为:
write → VFS → FS → page cache / direct I/O → BIO → request → driver → device → interrupt → completion
从性能角度总结,I/O 提交流程的优化本质集中在三点:一是通过 page cache 与 writeback 实现批处理与合并,二是通过 blk-mq 提供高并发队列模型,三是通过 DMA 与零拷贝减少 CPU 参与。理解这三点,就抓住了 Linux I/O 性能的核心。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
