Python数据分析顶流库Pandas全套干货|Part.2
- 2026-07-04 02:29:54
Python数据分析顶流库Pandas全套干货|Part.2(喜欢文章的朋友一定要点赞关注呀~) 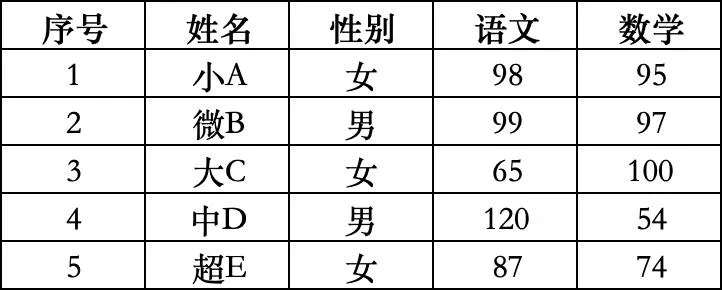
(设计一个test.xlsx文件) 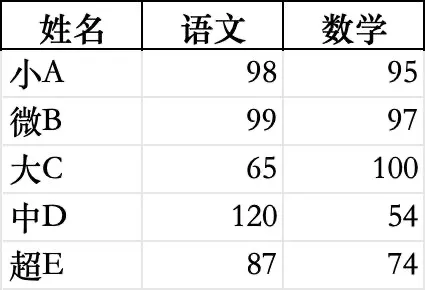
由于读取XLSX文件需要单独的引擎,因此可能还需要再装一个库: 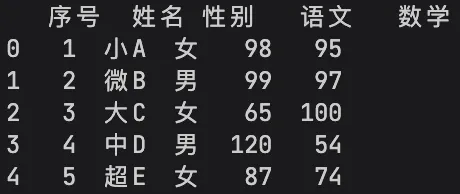

往期回顾: Python数据分析顶流库Pandas全套干货|Part.1
Python学习笔记——从入门到报废(十二、函数(上))
Python数据分析基石NumPy全套干货Part.1
Python学习笔记——从入门到报废(十、循环(中))
Python可视化天花板|wordcloud词云库,搭配jieba做出高颜值创意图!
第二篇:Pandas核心基础操作📂文件读写+数据查看+精准筛选
上一篇我们认识了Pandas的核心概念和两大对象,本篇进入实战核心环节,也是日常使用频率最高的操作:数据文件读写、基础信息查看、行列数据筛选。
不管是Excel、CSV还是TXT文件,Pandas都能轻松读取,几行代码就能精准提取目标数据,彻底告别手动翻表格、筛选数据的繁琐,全程代码可直接复制运行,新手看完就能上手处理真实数据✨
📤 最常用:各类数据文件读写(职场必备)
Pandas支持十几种数据格式读写,日常最常用的是CSV和Excel,代码极简,注意路径和编码问题即可,彻底解决文件兼容难题。
1. Excel文件读写(处理.xlsx/.xls)
import pandas as pd# 读取Excel文件,sheet_name指定工作表,默认第一个df = pd.read_excel('test.xlsx', sheet_name='Sheet1')# 读取指定列,避免多余数据df = pd.read_excel('test.xlsx', usecols=['姓名', '数学', '语文'])# 数据处理后,写入Excel文件df.to_excel('处理后成绩表.xlsx', index=False) # index=False 不保存行索引
pip install openpyxl2. CSV文件读写(处理.csv,大数据首选)
# 读取CSV文件,encoding指定编码,中文用utf-8或gbkdf = pd.read_csv('学生成绩表.csv', encoding='utf-8')# 写入CSV文件df.to_csv('处理后成绩表.csv', index=False, encoding='utf-8')
💡 读写避坑小技巧
中文乱码:编码切换为gbk或gb2312;
文件路径:用绝对路径,避免相对路径报错;
大数据:优先用CSV,比Excel读取更快。
👀 数据快速查看:读懂数据基本信息
读取数据后,先通过核心函数查看数据结构、内容、缺失值,快速掌握数据概况,不用逐行翻找:
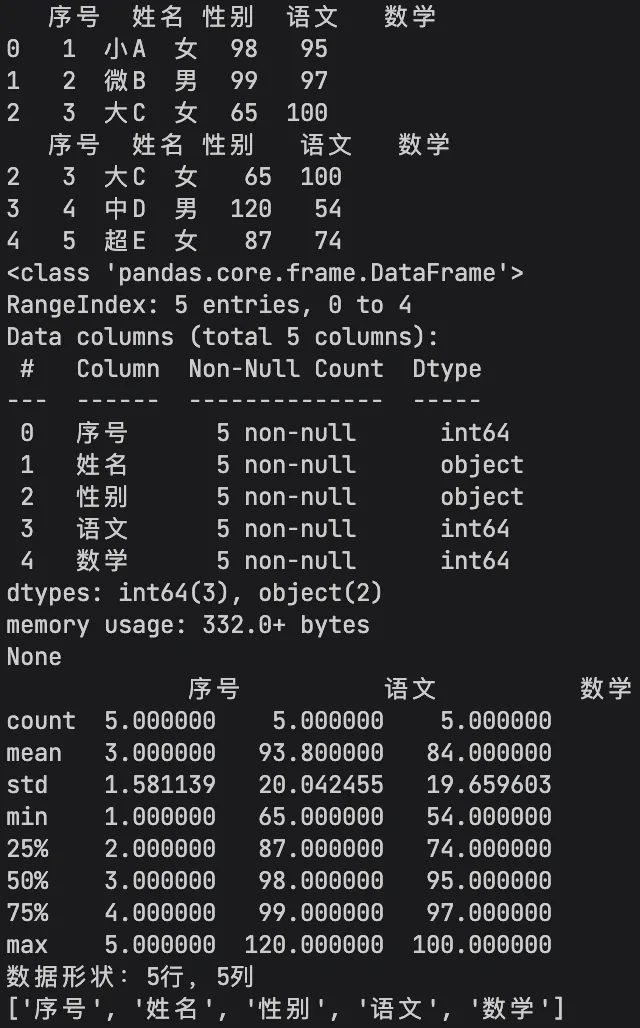
# 查看前5行数据(默认),括号填数字查看指定行数print(df.head(3))# 查看后5行数据print(df.tail(3))# 查看数据基本信息(行列数、数据类型、缺失值、内存占用)print(df.info())# 查看数据统计描述(均值、最值、标准差、分位数)print(df.describe())# 查看行列数print(f"数据形状:{df.shape[0]}行,{df.shape[1]}列")# 查看列名print(df.columns.tolist())
🔍 精准数据筛选:提取目标内容(核心)
Pandas筛选功能远超Excel,支持按列、按行、按条件精准提取,灵活度拉满,日常筛选全靠这几个方法:
1. 按列筛选(提取单列/多列)
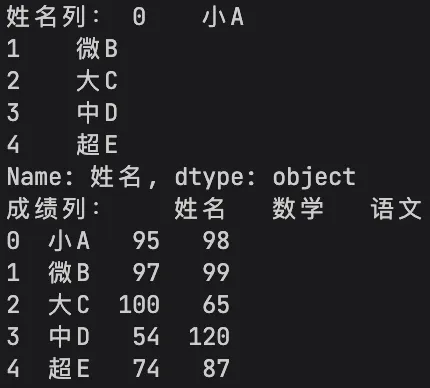
# 提取单列,返回Seriesname_col = df['姓名']print("姓名列:", name_col)# 提取多列,返回DataFramescore_df = df[['姓名', '数学', '语文']]print("成绩列:", score_df)
2. 按行筛选(按索引/位置)
# loc:按行索引标签筛选df_loc = df.loc[0:2] # 筛选前3行print("loc[0:2]:", df_loc)# iloc:按行位置索引筛选df_iloc = df.iloc[0:2] # 筛选前2行print("iloc[0:2]:", df_iloc)# 筛选指定行+指定列df_select = df.loc[0:2, ['姓名', '数学']]print("loc[0:2, ['姓名', '数学']]:", df_select)
3. 按条件筛选(最常用,批量过滤)
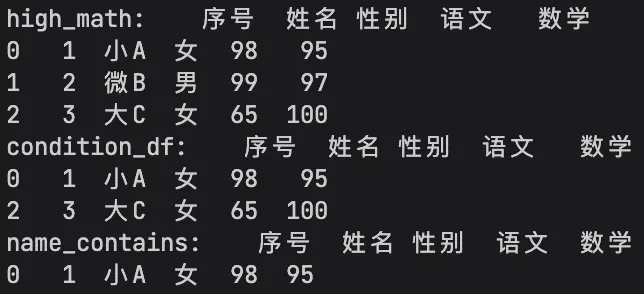
# 单条件筛选:数学成绩大于90分high_math = df[df['数学'] > 90]print("high_math:", high_math)# 多条件筛选:女生且数学大于85分(&且,|或,加括号)condition_df = df[(df['性别'] == '女') & (df['数学'] > 85)]print("condition_df:", condition_df)# 包含指定字符筛选:姓名包含“小”name_contains = df[df['姓名'].str.contains('小', na=False)]print("name_contains:", name_contains)
📌 第二篇小结+下篇预告
本篇我们掌握了Pandas最核心的基础操作:文件读写、数据查看、行列筛选,覆盖日常数据处理70%的基础需求,能轻松处理各类表格数据。第三篇将讲解数据清洗核心技巧:缺失值、重复值、异常值处理,搞定脏数据,让数据更规范,彻底解决数据预处理难题~
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Linux 命令新手手册:小白可直接上手的基础命令汇总
- 在Linux服务器上部署容器化的消息队列
- 校招中的“熟悉linux操作系统”一般是指达到什么程度?
- Red Hat Enterprise Linux(RHEL)全面了解
- 爬虫还在用Python?我与Node.js不得不说的故事
- “双百行动” | 这个暑假,让Python和蝉鸣一起住进孩子心里
- Python | Skyborn | Windows下使用CDO
- 学习AI第四天:我开始系统学习 Python 里的列表和拷贝了
- 第8篇:PHP面向对象入门
- 装完Linux虚拟机连不上网?保姆级网络配置实战,一次搞定宿主机通信+上网
