1. re模块在使用时,需要先应用inport语句引入,具体代码如下:import re。
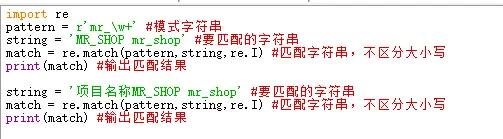
1.1 match()方法用于从字符串的开始处进行匹配,如果在起始位置匹配成功,则返回Match对象,否则返回None。其语法格式如下:re.match(pattern, string, [flags])
参数说明:■ pattern:表示模式字符串,由要匹配的正则表达式转换而来。■ string:表示要匹配的字符串。■ flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
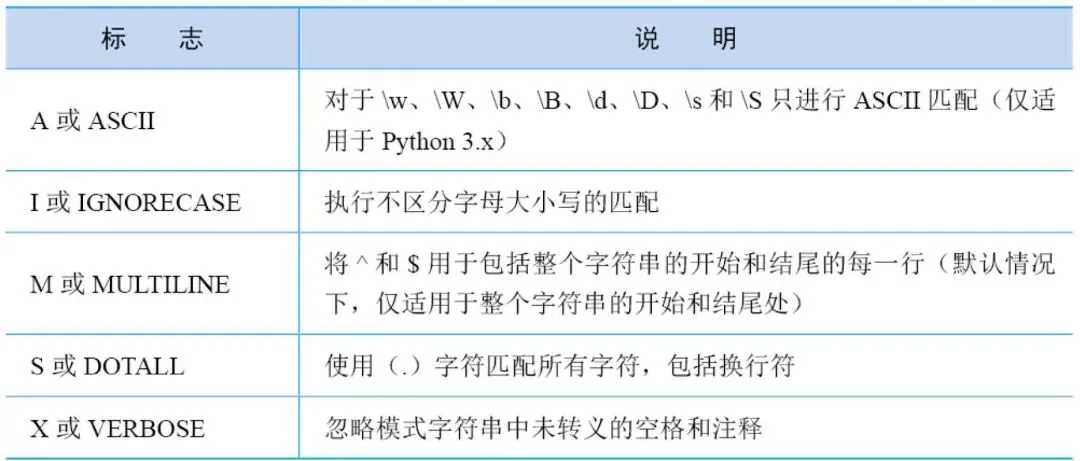
表1 常用标志
运行结果,第一个匹配到了信息,返回一个Match对象,第二个没用匹配到信息,返回None:match对象包含了匹配值的位置数据。要获取匹配值的起始位置可以使用Match对象的start()方法;要获取匹配值的结束位置可以使用end()方法;通过span()方法可以返回匹配位置的元组;通过string属性可以获取要匹配的字符串。
将上面的程序改一下:
应用实例,验证输入的手机号码是否为中国移动号码:
1.2 使用search()方法用于在整个字符串中搜索第一个匹配的值,如果匹配成功,则返回match对象,否则返回None。语法格式如下:
re.search(pattern, string, [flags])
将前面match()语句的程序改成search()语句程序,运行后则输出以下结果:
search()方法与match()方法不同的地方在于它不仅仅是在字符串的起始位置搜索,其他位置如果有符合的匹配也可以进行搜索。
应用实例,验证是否出现危险字符:
1.3使用findall()方法用于在整个字符串中搜索所有符合正则表达式的字符串,并以列表的形式返回。语法格式如下:
re.findall(pattern, string, [flags])
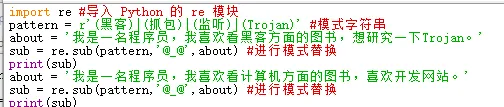
2 替换字符串
sub()方法用于实现字符串替换,语法格式如下:
re.sub(pattern, repl, string, count, flags)
参数说明:■ pattern:表示模式字符串,由要匹配的正则表达式转换而来。■ repl:表示替换的字符串。■ string:表示要被查找替换的原始字符串。■ count:可选参数,表示模式匹配后替换的最大次数,默认值为0,表示替换所有的匹配。■ flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
以下是替换敏感词的例子:
3.使用正则表达式分割字符串
split()方法用于实现根据正则表达式分割字符串,并以列表的形式返回。
语法格式如下:
re.split(pattern, string,【maxsplit】,【flags】)






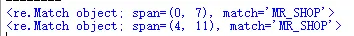







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
