做服务器巡检时,内存是最容易让人紧张的指标之一。
监控图上一条线慢慢爬到 80%、90%,群里马上就会有人问:
我以前也很容易被这个数字带着走。
后来线上机器看多了才发现,Linux 内存真正麻烦的地方,不是它难,而是它太容易被一个“使用率”讲得过于简单。
同样是 90% 内存使用率,有的机器非常健康,只是 page cache 很多;有的机器已经在疯狂 swap;有的机器宿主机看起来还行,但某个容器已经被 cgroup 限制逼到 OOM;还有的机器内存没满,业务却因为内存碎片、tmpfs、slab 或者突发申请被打了一下。
所以这篇想从运维现场常见的几个误判开始,把 Linux 服务器上最该理解的内存问题串起来:
说到底,Linux 内存排查的关键不是问“它用了多少”,而是问:
这些内存用在哪里,它能不能被回收,系统有没有真实压力,业务会不会被影响。
一、内存不是只有“用了”和“没用”
很多人第一次看服务器内存,会下意识把内存分成两块:
已使用,未使用。
这在桌面电脑上勉强还能理解,但放到 Linux 服务器上其实不那么适用了。
Linux 会尽量把空闲内存用起来。你不用它,它也会拿来做文件缓存、目录项缓存、inode 缓存、网络缓冲、内核对象缓存。这样下次读文件、扫目录、跑构建、查日志、访问数据库文件时,速度会快很多。
所以一台长期运行的 Linux 机器,free 很少一直保持很大。
这不是坏事。
真正值得关心的是:这些看起来“被使用”的内存,有多少是业务进程必须占住的,有多少是系统为了性能暂时拿来做缓存的,有多少在压力来临时可以回收。
粗分一下,服务器内存里常见的几类东西包括:
第一类,进程匿名内存。
比如应用堆内存、栈、运行时对象、JVM heap、Redis 数据、数据库 buffer pool。它们通常不能随便回收,要么属于进程,要么要靠进程自己释放。
第二类,文件页缓存。
也就是常说的 page cache。读过的文件内容、写文件时暂存的脏页,都可能在这里。它提升性能,但在需要时可以被回收一部分。
第三类,内核内存。
包括 slab、dentry、inode、网络栈、页表、内核模块使用的对象等。它不像业务进程 RSS 那么直观,但在某些场景下会长得很明显。
第四类,tmpfs 和共享内存。
比如 /dev/shm、某些容器里的 shared memory、临时文件系统。它们看起来像文件,实际吃的是内存。
第五类,交换空间里的旧页。
swap 不是物理内存,但它会影响内存判断。它代表系统曾经把一部分内存页挪到了磁盘或交换设备上。
所以,当你看到“内存用了 90%”,第一反应不应该是扩容。
更好的第一反应是:
这 90% 是谁用的?是不能动的,还是暂时借出去的?
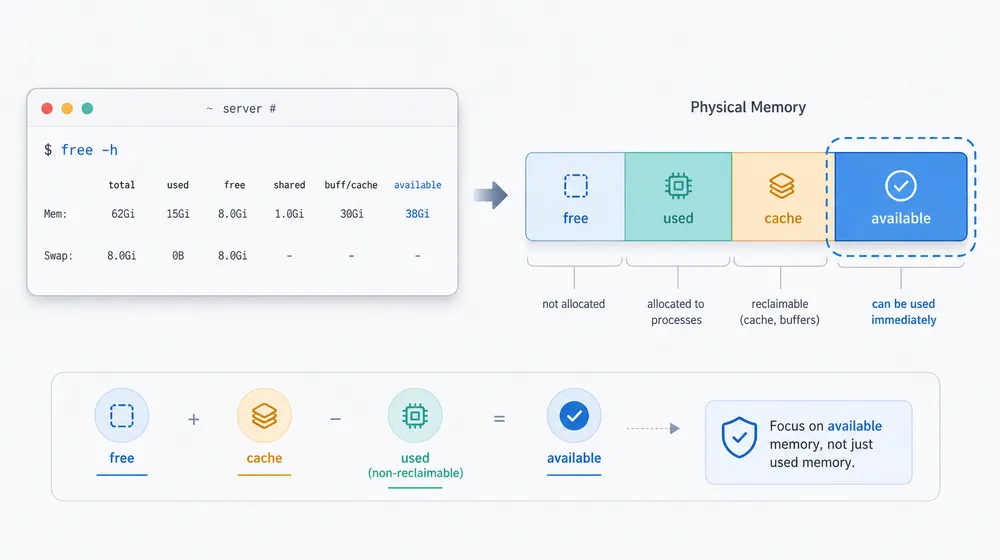
二、free -h 里最该看的不是 free
free 命令里不要只看 used,available 和动态压力更关键很多内存误判都从这个命令开始:
free -h
一眼看过去,最醒目的往往是 used 和 free。
但在 Linux 上,真正更值得看的通常是 available。
free 代表当前完全没被使用的内存。这个值低,不一定说明危险。Linux 本来就不喜欢让内存闲着。
buff/cache 代表一批用于缓冲和缓存的内存。它里面有不少内容在压力下可以被回收,但也不能简单理解成“完全等于可用”。如果里面有大量脏页正在等待写回,或者某些 cache 回收成本很高,它就不会像账面上那样轻松。
available 更接近一个运维视角的问题:
如果现在来了新的内存申请,系统大概还能拿出多少内存,不至于立刻进入明显的 swap 或回收压力。
所以判断一台 Linux 机器是不是内存紧张,一般会按这个顺序看:
free -hcat /proc/meminfovmstat 1
free -h 先看大面。
/proc/meminfo 再拆细节,比如 MemAvailable、Cached、Buffers、SwapTotal、SwapFree、Dirty、Writeback、Slab、SReclaimable、Shmem。
vmstat 1 看动态压力,尤其是 si、so、wa、r、b 这些字段。
如果一台机器 used 很高,但 available 还比较宽裕,si/so 长期为 0,业务延迟也没有异常,那大概率不是“内存爆了”。
反过来,如果 available 很低,vmstat 里 si/so 持续不为 0,系统 iowait 增加,应用响应变慢,那就不是“缓存多一点”这么轻描淡写了。
这时候要开始认真查:到底是谁在逼系统回收内存。
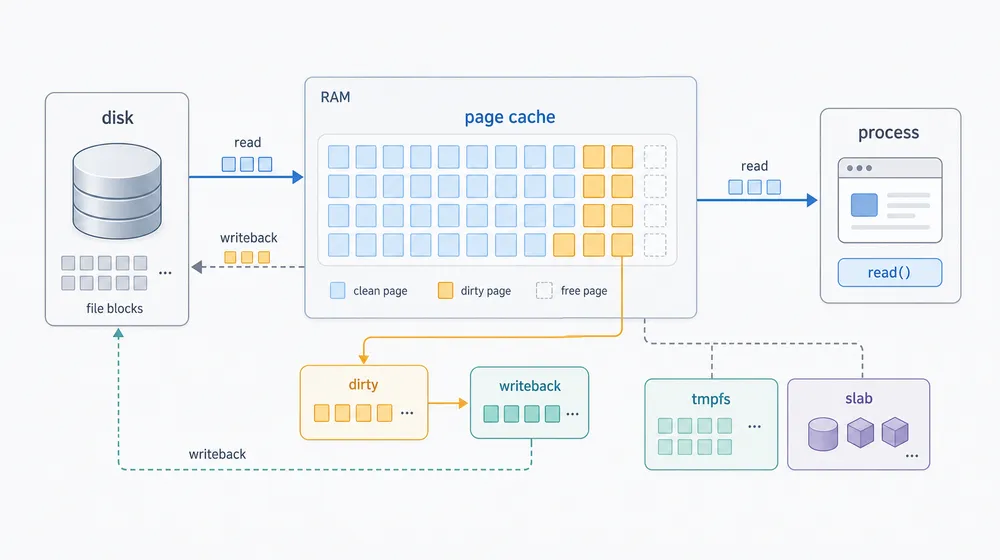
三、page cache 不是敌人
Page cache 通常提升性能,但仍要结合脏页、tmpfs 和 slab 判断Linux 把空闲内存拿去做 page cache,是很多服务器看起来“内存很满”的主要原因。
这件事本身很合理。
数据库读数据文件、Nginx 读静态资源、构建机反复读取依赖、日志系统扫文件、备份程序遍历目录,都会受益于缓存。
如果你每次看到 cache 高就手动清缓存:
echo 3 > /proc/sys/vm/drop_caches
那多数情况下不是优化,而是在主动让系统变慢。
清缓存之后,短时间内内存图好看了,free 变大了,但下一轮文件读取又要重新从磁盘拿数据。对线上服务来说,这通常没有意义。
不过,page cache 也不能成为所有问题的万能挡箭牌。
我见过一些排查里,大家看到 buff/cache 高,就直接下结论“没事,都是缓存”。这个判断也不够。
有几种情况要继续往下看。
第一,脏页太多。
Dirty 和 Writeback 如果异常,说明有不少数据还在等待写回磁盘。写回压力上来时,应用可能会被阻塞,尤其是日志量、批量写入、备份、对象存储网关这类场景。
第二,tmpfs 占用被当成缓存忽略了。
/dev/shm、容器 shared memory、某些临时目录如果挂在 tmpfs 上,吃的就是内存。它不是普通磁盘文件。大文件丢进去,内存会真的少很多。
第三,slab 长得不正常。
大量小文件、目录遍历、容器频繁创建销毁、网络连接对象,都可能让 slab 明显上涨。可以用 slabtop 或 /proc/meminfo 里的 Slab、SReclaimable、SUnreclaim 继续进一步分析。
第四,业务自己的工作集已经太大。
缓存可以回收,但进程真正热数据太大时,系统回收 cache 也只是拖延。最后还是会进入 swap、OOM 或延迟抖动。
所以 page cache 的正确打开方式不是“高了就清”,也不是“高了就没事”。
更准确的说法是:
page cache 是 Linux 用内存换性能的一种方式。它通常是好事,但要结合可回收性、写回压力和业务工作综合判断。
四、swap 不一定是坏事,持续换入换出才是坏信号
swap 在很多团队里名声很差。
有人看到 swap used 不是 0,就觉得机器出问题了。
有人干脆所有服务器都关 swap,认为这样更“干净”。
也有人把 swap 当成扩展内存,觉得不够了反正还能顶一顶。
这三种理解都有点危险。
swap 的本质是:当物理内存紧张时,系统可以把一些不常用的内存页换到磁盘或交换设备上,让更重要、更热的数据留在内存里。
它不是洪水猛兽,也不是免费的内存。
判断 swap,重点不是看 SwapUsed 有没有数值,而是看它是不是正在持续发生换入换出。
最简单的现场命令是:
vmstat 1
这里的 si 是 swap in,so 是 swap out。
如果 swap used 有一些,但 si/so 长期为 0,说明系统过去某个时刻把冷页挪出去过,现在并没有持续抖动。这个场景未必严重。
如果 si/so 持续不为 0,同时业务延迟上升、CPU iowait 增加、磁盘延迟变差,那就要认真处理。
因为这意味着系统正在用慢得多的存储设备来弥补内存不足。
对数据库、缓存、搜索、消息队列这类服务,持续 swap 往往非常伤。它不一定马上把服务打死,但会把延迟拖得很难看。
一般倾向于这样看 swap:
swap 可以作为安全垫,但不能当容量规划。
它能让系统在某些边缘情况下多一点缓冲,给监控和运维动作留时间。但如果业务稳定运行必须依赖 swap,那本质上还是内存预算、进程限制或架构拆分出了问题。
五、OOM 不是突然发生的,它通常有前奏
OOM 排查要先区分宿主机、cgroup 和进程运行时边界很多人遇到 OOM 的感受是:服务突然没了。
但从系统角度看,OOM 很少是毫无前奏的。
它通常发生在一条链路的末端:
内存申请增加,
可回收 cache 变少,
后台回收变频繁,
直接回收开始影响进程,
swap 或写回压力上来,
最后系统发现再也满足不了某次内存申请,只能杀进程。
Linux 还有一个很容易被忽略的机制:overcommit。
简单说,进程申请内存时,系统不一定马上给它真实物理页。很多时候它先答应下来,等进程真正访问这些页时再分配。这样能提高效率,也符合很多程序“申请很多,实际用不了那么多”的习惯。
但问题也在这里。
系统“承诺出去”的内存,和物理上真正能支撑的内存,不总是一回事。
当大量进程真正开始触碰内存页,承诺变成现实,压力就会集中爆出来。
排查 OOM 时,不要只看进程退出码。需要去看内核日志和 cgroup 事件:
journalctl -k -g 'oom|Out of memory|Killed process'dmesg -T | grep -Ei 'oom|out of memory|killed process'
如果是容器或 systemd 服务,还要看对应 cgroup:
cat /sys/fs/cgroup/<group>/memory.currentcat /sys/fs/cgroup/<group>/memory.maxcat /sys/fs/cgroup/<group>/memory.events
这里有个很常见的线上误会:
宿主机还有内存,不代表容器不会 OOM。
如果容器被 memory.max 或 Kubernetes limit 限住了,它在自己的边界内撞墙,就可能被杀。宿主机全局还有空闲,也救不了它。
所以看 OOM 时一定要先问清楚范围:
这是宿主机 OOM,还是某个 cgroup OOM?
这两个问题的处理方式不一样。
宿主机 OOM 可能要看整机进程、内核内存、swap、overcommit、突发任务和容量规划。
cgroup OOM 则更常见于容器 limit 太紧、JVM 或数据库配置没按 limit 调整、sidecar 和主进程抢内存、批处理峰值被低估。
如果范围判断错了,后面的排查很容易跑偏。
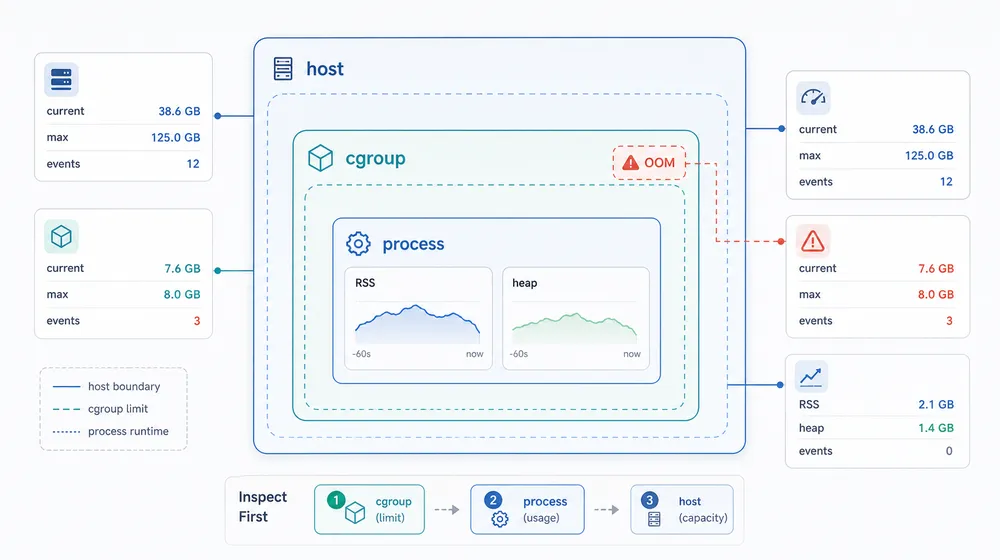
六、容器时代,内存排查更需要分层
以前看一台物理机或虚拟机,边界比较清楚。
现在不一样。
一台 Linux 宿主机上可能跑着很多容器,每个容器有自己的 cgroup 限制,每个服务又有自己的运行时内存管理。Java 有 heap 和 off-heap,Go 有 GC 和 arena,Node.js 有 V8 heap,数据库有 buffer pool,Nginx 有 worker 和连接缓冲。
所以不能只站在一个层级看问题。一般会分三层:
第一层,看宿主机。
宿主机的 MemAvailable、swap、PSI、slab、dirty/writeback 是否异常。它回答的是:整台机器有没有真实内存压力。
第二层,看 cgroup 或容器。
memory.current、memory.max、memory.events、容器重启原因、Kubernetes 里的 OOMKilled。它回答的是:某个工作负载有没有撞到自己的边界。
第三层,看进程和运行时。
RSS、PSS、heap、off-heap、线程栈、连接数、缓存大小、对象数量、GC 日志。它回答的是:业务进程为什么会长到这个程度。
很多线上问题卡住,就是因为一直在一个层级里打转。
比如应用被 OOMKilled,宿主机看着还有很多 available,于是觉得监控不准。其实只是容器 limit 太小。
再比如宿主机 available 越来越低,但容器内进程 RSS 都不夸张。继续往下看才发现是宿主机 slab、tmpfs 或某个日志写入链路在吃内存。
还有一种情况是 JVM heap 配得很保守,但 off-heap、direct buffer、线程栈、native library 加起来超过了容器限制,最后看起来像“Java 没用满 heap 也 OOM”。
容器没有让内存变简单,它只是让边界更明确,同时也让误判更多。
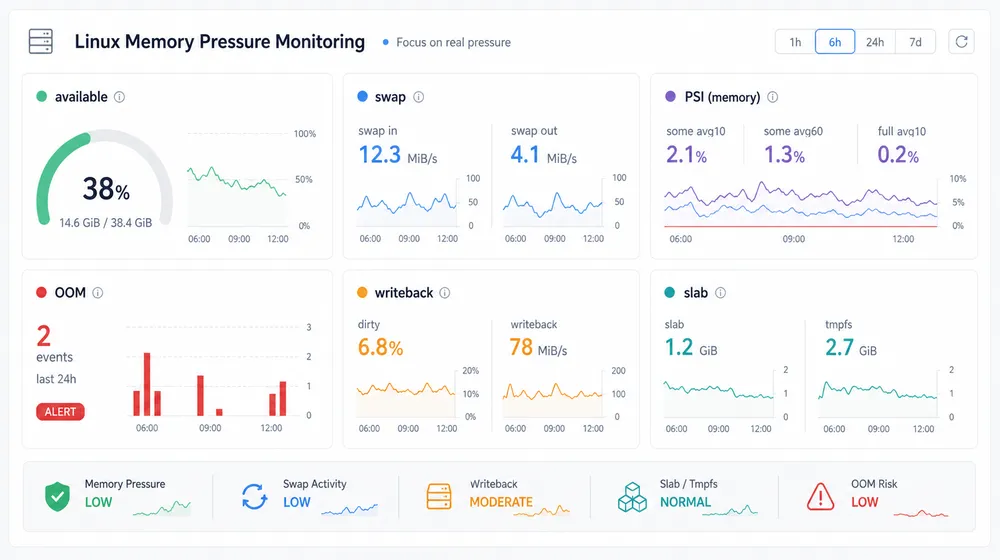
七、生产环境上可以关注这些
生产监控应覆盖可用内存、swap、PSI、OOM、写回和内核内存如果只给一台 Linux 服务器做内存监控,不要只放一个“内存使用率”。因为它太粗了。建议关注以下内容:
MemAvailable 比例。
比 free 更有参考价值。它持续走低时,才更像真实压力的前奏。
swap in/out 速率。
swap used 只是历史痕迹,持续 si/so 才是当前压力。
PSI memory pressure。
PSI 能反映任务因为内存压力被阻塞的时间比例。它比单纯使用率更接近“业务是否被内存拖慢”。
OOM kill 次数和日志。
宿主机 OOM、cgroup OOM 都要分开看。不能只看进程重启次数。
major page faults。
大量 major fault 可能意味着进程频繁从磁盘读页,性能会受影响。
Dirty 和 Writeback。
写回异常时,内存和 IO 问题会纠缠在一起。
Slab、SReclaimable、SUnreclaim。
尤其是文件很多、容器很多、网络连接很多的机器。
容器的 memory.current、memory.max、memory.events。
容器环境里,这是判断边界的关键。
关键进程的 RSS/PSS 趋势。
看单点没用,趋势更重要。内存泄漏往往不是某一秒突然出现,而是连续几小时、几天慢慢爬。
八、一个栗子
“这台机器内存快满了”的排查顺序
第一步,看是不是误报。
free -hcat /proc/meminfo | egrep 'MemAvailable|Cached|Buffers|Slab|SReclaimable|SUnreclaim|Dirty|Writeback|Shmem|Swap'
重点看 MemAvailable、swap、cache、slab、shmem。
第二步,看有没有动态压力。
vmstat 1cat /proc/pressure/memory
如果 si/so、PSI、iowait 都没异常,业务也没慢,先别急着扩容。
第三步,看谁在占。
ps aux --sort=-rss | headtop
有条件的话,用 smem 看 PSS 会更准一点,因为共享内存只看 RSS 容易重复计算。
第四步,看是不是内核或文件系统相关。
slabtopdf -hdf -h /dev/shm
很多“进程看起来不大,但内存不见了”的问题,最后会落到 slab、tmpfs、page cache、脏页写回上。
第五步,看有没有 OOM 证据。
journalctl -k -g 'oom|Out of memory|Killed process'
容器环境继续看 cgroup 或 Kubernetes 事件。
第六步,再决定动作。
如果是 cache 正常增长,别手痒清缓存。
如果是进程 RSS 持续上涨,优先查泄漏或配置。
如果是容器 limit 太紧,调整 limit 和运行时参数。
如果是 swap 持续抖动,考虑拆负载、限峰值、优化内存使用或扩容。
如果是 slab、tmpfs、dirty/writeback 异常,就按具体来源处理。
如果是业务增长导致工作集变大,那扩容可能就是正确答案。
Linux 内存的很多现象,看起来像容量问题,背后其实是使用方式问题。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
