在上篇,我们介绍了如何用Python写一个自己的二维码生成器。
二维码我们非常熟悉,每天我们都在扫 —— 付钱、加好友、连Wi-Fi、点餐……那个黑白相间的小方块,为什么能藏下这么多信息?
今天就把二维码的原理拆开,讲给你听。
前面我们已经知道了Python制作二维码需要依靠第三方库,
比如qrcode、MyQR,
你们发现没有,怎么库名都包含QR?
QR 是 Quick Response 的缩写,翻译过来就是 “快速响应”。
二维码的英文叫 QR Code,也就是“快速响应码”。
为什么要强调“快速响应”?这得从二维码诞生前的条形码说起。
一、条形码的局限
在二维码出现之前,工厂里大量使用的是条形码。

但条形码有一个明显的短板:它只在水平方向上携带信息(宽度方向),所以它存不了多少信息。
在制造业和物流业,尤其是汽车制造这种零件种类繁多、信息量大的场景里,条形码已经不够用了。一个零件从哪里来、用到哪里去、什么批次、谁检测的……这些信息条形码根本装不下。
二、二维码的诞生
1994年,日本电装公司的工程师原昌宏(也被称为二维码之父),为了解决汽车零件管理中信息不足、读取慢的问题,发明了QR码。
第一批QR码是贴在汽车零件上用的。工人扫一下,就能立刻知道:
这个零件是什么?从哪里来?要送到哪条生产线去?

图片来源于网络
从零件识别到物流追踪,它的用途越来越广,后来慢慢从工厂走进了我们的生活。
相比较条形码而言,二维码承载的信息量立刻大了几十倍。
信息量大了,如何才能又快又准地读出来呢?
这就要提到二维码是如何设计了。
第一个秘密:定位快。
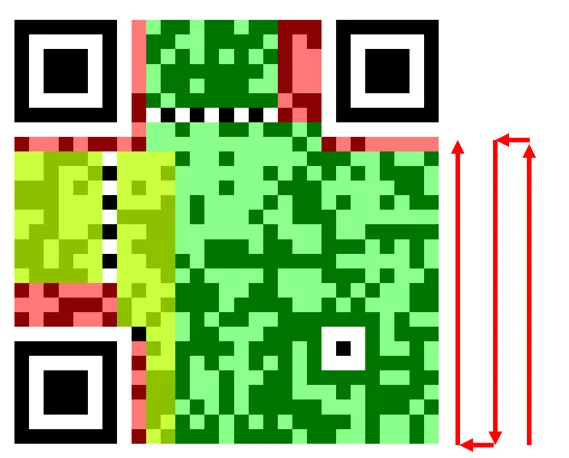
二维码的三个角上,各有一个“回”字形的大方块。如下图所示。这三个方块是给扫码设备“指路”的——不管你是正着扫、歪着扫、倒着扫,它都能瞬间定位,知道二维码应该怎么“扶正”。
除了这三个大“回”字,二维码内部还有一个更小的“回”字(实际上高版本会有多个,但我们可以理解为“内部有校准标记”)。它的作用是帮手机“修正”画面——比如二维码正好印在弯曲的瓶子上时,手机也能准确识别。红色区域包含了二维码的版本信息、数据编码之类的信息,如下图所示剩下的绿色区域就是数据存储的区域
第二个秘密:修复快
你有没有遇到过这种情况:二维码被挡住或者被撕掉了一角,居然还能扫出来?
这不是运气,是设计好的。
二维码在生成的时候,会专门划出一块区域来存放纠错码。你可以把它理解成一个“备用零件库”——即使二维码被挡住了一小块,只要没超过容错上限,手机也能靠这些备用信息把缺失的部分推算出来,完整地读取内容。
黄色区域就是纠错区域(备份区域),如下图所示。
在生活中,我们可能有过这样的经验:
有时扫二维码,遮了一点就扫描不出来,而有时扫二维码,遮了很多却可以扫描出来。
这又是为什么呢?
这是因为二维码分为四个容错等级,最高级别的容错率可以达到30%。
你可以理解为,黄色区域部分越大,容错率越高。
从下面的图中,我们就可以看出,如果提高容错率,二维码可以存储的数据自然就变小了。这是一个“取舍”。
第三个秘密:读取快
手机定位之后,二维码的读取路径是固定的:从右往左,Z字形向上读取数据
这个固定的“扫读路线”是设计好的——手机不需要思考“从哪开始”,每次都用同一种路径,速度快、不容易出错。
(这也就是为什么有时候二维码只遮住左上角还能扫,遮住右下角反而扫不出来——因为读取是从右下角开始的。)
第四个秘密:掩码——让二维码看起来更“均匀”
你有没有发现,几乎没见过哪块是一大片全黑或一大片全白的二维码?
这不是巧合,是设计好的。
想象一下:如果二维码里出现一大片连续的黑色格子,扫码的时候手机可能会“迷路”——找不到格子的边界,分不清哪里是哪里。
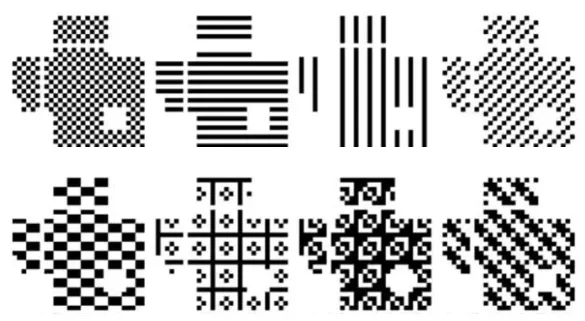
所以,在生成二维码的时候,会进行一个叫掩码(Mask)的操作。掩码的作用就是打散这种大面积的连续色块,让黑白格子均匀交错分布,手机扫描时更容易识别每个格子的边界。
简单来说,先计算出一个二维码,然后在下面8个花式款式去试,选一个让黑白分布最均匀的方案。
第五个秘密:版本——不同大小,不同容量
我们平时见到的二维码,大小好像都差不多。但实际上,二维码一共有40个版本。
版本越高,格子越多,能存的信息也越多。
不管是条形码,还是二维码,其实都是给数字、字母、汉字、符号等这些字符换了一身衣服,把它们打扮成了能被手机识别的黑白条或块。
那么,问题来了:
这些文字、数字、网址,究竟是怎么变成二维码中的黑白格子的?
假如黑色格子表示1,白色格子表示0,其实二维码就是由若干个0和若干个1组成的序列。
这就涉及到信息的编码。而所有编码的起点,是二进制。
数字、汉字、图片、声音、视频 —— 它们都是怎么变成0和1的?
这些内容,比二维码还要底层,也还要有趣。
我们以后再聊。










 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
