作为一名从 Java 转 Python 的工程师,你可能已经习惯了这样的并发模型:每来一个请求就启动一个线程,线程阻塞在数据库查询或 HTTP 调用上,操作系统负责调度。这套模型在 Java 中运行良好,因为 Java 线程是真正的操作系统线程,没有全局锁,多核 CPU 可以并行执行多个线程。
但当你开始用 Python 的 FastAPI 或 asyncio 时,如果继续沿用同样的思维,你会惊讶地发现:为什么我的异步代码还是卡住了?为什么多线程计算反而更慢? 答案是:Python(特别是 CPython)的并发模型本质上是 亲和 IO 密集型、疏远 CPU 密集型 的。理解这一点,是写出高效 Python 异步系统的前提。
本文将从 Java 程序员的视角,用十分钟的时间,带你理解 GIL 与 IO 密集型的底层关系,掌握异步事件循环的本质,并给出七条经过生产验证的铁律。
unsetunset一、核心背景:GIL 与 IO 密集型的天然亲和unsetunset
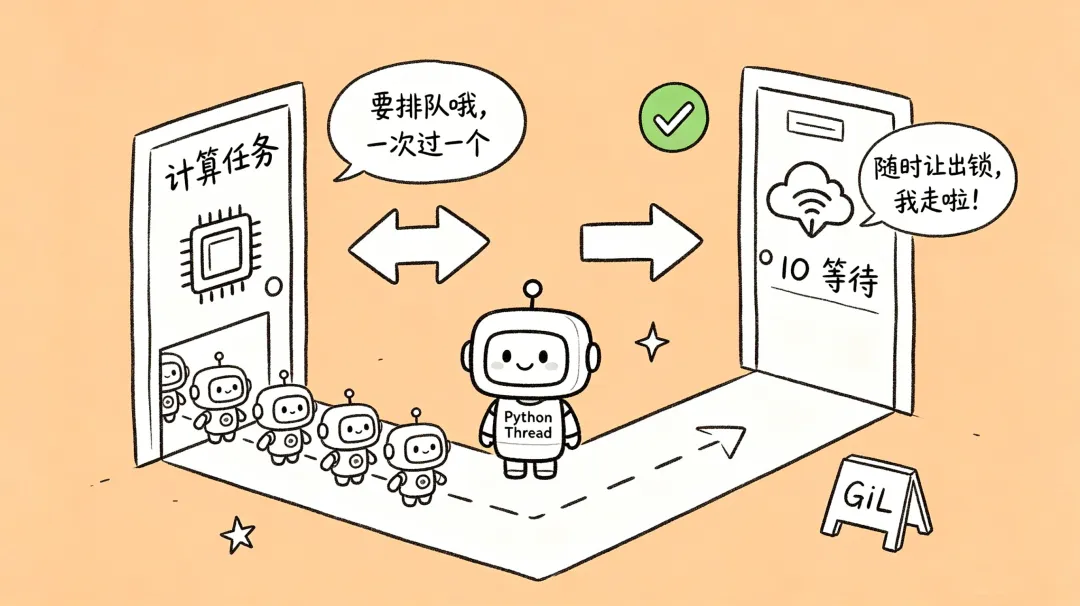
CPython 解释器中有一个全局解释器锁(GIL)。它的规则很简单:同一时刻,只有一个线程能执行 Python 字节码。
1.1 这对 Java 程序员意味着什么?
- 多线程无法并行计算:即使在 16 核的机器上,启动 16 个 Python 线程同时做
for i in range(10**8): pass,它们不能真正同时运行。GIL 会强制它们轮流执行,反而因为线程切换和锁争用而变慢。 - 但 GIL 在 IO 等待时会主动释放:当一个线程执行
socket.read() 或 time.sleep() 时,它知道要等很久,于是主动释放 GIL,让其他线程运行。这正是 Python 多线程(以及建立在其上的 asyncio)擅长 IO 密集型任务的原因——大量时间花在等待,而不是计算。
1.2 Java 程序员容易犯的第一个错
用 Java 的习惯,在 Python 中写这样的代码:
# ❌ 你以为开了 10 个线程并行计算,实际上它们在轮流执行from threading import Threaddef cpu_bound(): sum(i * i for i in range(10**7))threads = [Thread(target=cpu_bound) for _ in range(10)]for t in threads: t.start()for t in threads: t.join()
这段代码不会比单线程快,甚至更慢。正确的做法是使用多进程(multiprocessing)绕过 GIL,或者将计算任务交给 C 扩展(如 NumPy)。
1.3 Java 程序员容易犯的第二个错
在 FastAPI 中写同步阻塞的代码:
# ❌ 你习惯用的 requests 库是同步阻塞的@app.get("/data")def get_data(): response = requests.get("https://api.example.com") # 阻塞整个线程return response.json()
如果一个请求在等待外部 API,整个线程(以及该线程上的所有其他协程)都会被卡住。这完全浪费了 asyncio 的并发能力。
1.4 正确的思维转变
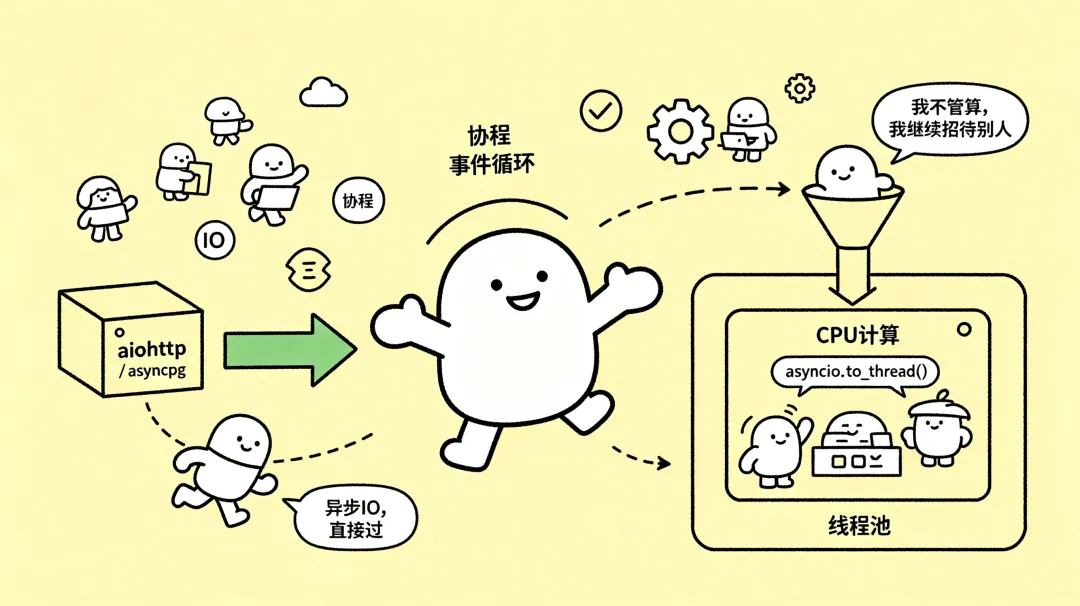
在 Python 中,并发(处理大量同时发生的 IO 等待)不等于并行(同时执行多个计算)。
- IO 密集型任务:用
asyncio + 异步库(aiohttp, asyncpg, aiofiles),单线程即可处理成千上万连接。 - CPU 密集型任务:要么用多进程(
multiprocessing),要么用 C 扩展,要么把计算任务拆分到消息队列(如 Celery)中。
理解了这个背景,下面七条铁律才有了根基。
unsetunset二、单线程异步的本质:不是你变快了,而是你学会了“让”unsetunset
事件循环的工作原理就像一个永不停止的调度员:它维护一个就绪任务队列和一个等待任务集合。每个协程执行到 await 时,如果等待的事件尚未就绪(比如 socket 还没收到数据),事件循环会把这个协程挂起到等待区,然后从就绪队列中取出另一个协程执行。当 IO 事件触发(数据到达),对应的协程重新回到就绪队列。
关键认知(对 Java 程序员尤其重要):
- 所有协程运行在同一个线程中,没有真正的并行计算——这不同于 Java 的线程池。
- 任务切换只发生在
await 处——这是显式、确定的主动让权,而非操作系统的抢占式调度。 - 任何不经过
await 的长时间同步操作(包括你用惯了的 requests.get、time.sleep、大循环)都会像一堵墙一样卡住整个循环。
所以,写好异步系统的本质就是:把所有的阻塞操作变成可等待的协程,并且时刻准备让出 CPU。
unsetunset三、七条铁律:从能用、好用到稳固unsetunset
3.1 绝不阻塞事件循环 —— 否则你失去一切
Java 程序员最容易踩的坑,就是把同步 IO 库带到异步代码中。
常见阻塞操作:
time.sleep() 而不是 asyncio.sleep()- 同步的文件读写、网络请求(
open、requests.get、urllib.request)
正确做法:
- 用
asyncio.sleep() 替代 time.sleep()。 - 使用异步库:
aiohttp 替代 requests,aiofiles 替代 open,数据库选用 asyncpg、aiomysql。 - 对于 CPU 密集型任务,用
asyncio.to_thread() 转移到线程池执行(注意:因为 GIL,多个此类任务仍不能并行,但至少不会阻塞事件循环)。
import asyncioimport requests # ❌ 别这样用async def bad(): requests.get("https://api.com") # 阻塞整个事件循环async def good(): async with aiohttp.ClientSession() as session: await session.get("https://api.com") # ✅ 异步非阻塞async def cpu_task():# 重计算在后台线程中运行,事件循环不受影响 result = await asyncio.to_thread(sync_heavy_function)return result
3.2 任务创建:要么跟踪,要么包裹异常
asyncio.create_task() 类似于 Java 的 CompletableFuture.runAsync(),但有一个关键差异:如果任务内部抛出异常而你没处理,异常会被悄悄吞掉(仅在任务对象被垃圾回收时打印一次警告)。Java 的 Future.get() 会抛出异常,但 Python 不会主动提醒。
# ❌ 危险:无人照看的任务(异常会丢失)asyncio.create_task(long_running())# ✅ 安全包装async def safe_wrapper(): try: await long_running() except Exception as e: logger.exception("Background task crashed")asyncio.create_task(safe_wrapper())
Python 3.11+ 推荐使用 asyncio.TaskGroup,它类似 Java 的 ExecutorService.invokeAll(),会自动传播异常并取消其他任务。
async def main(): async with asyncio.TaskGroup() as tg: tg.create_task(task1()) tg.create_task(task2())# task1 抛异常 → task2 被自动取消,异常抛出
3.3 用信号量控制并发 —— 保护下游资源
在 Java 中,你可能会用固定大小的线程池来控制并发。在 asyncio 中,用 Semaphore 达到同样的效果。
sem = asyncio.Semaphore(10) # 最多 10 个并发协程async def fetch(url): async with sem:return await aiohttp_get(url)# 同时启动 1000 个 fetch,但只有 10 个能真正同时执行results = await asyncio.gather(*[fetch(url) for url in urls])
3.4 每个等待都要有超时 —— 避免资源悬空
Java 中你可能习惯设置连接超时和读取超时。在 asyncio 中,asyncio.wait_for 是标配。
try: result = await asyncio.wait_for(fetch(url), timeout=5.0)except asyncio.TimeoutError:# 记录、重试或降级
进阶:对于超时后仍需部分结果的场景,用 asyncio.shield 保护关键操作不被取消。
# 重要写入操作不允许被超时取消await asyncio.shield(db.commit())
3.5 异步上下文管理器 —— 资源清理的唯一正解
Java 的 try-with-resources 对应 Python 的同步上下文管理器 with。在异步中,你需要 async with。
async def get_db(): conn = await asyncpg.connect(...) try: yield conn finally: await conn.close()async def handler(): async with get_db() as conn: await conn.execute("SELECT ...")# 自动关闭连接
3.6 背压控制:用有界队列防止系统被冲垮
Java 中你可能用 BlockingQueue 来协调生产者和消费者。asyncio 的 Queue(maxsize=N) 提供完全类似的能力。
queue = asyncio.Queue(maxsize=100)async def producer():for item in huge_list: await queue.put(item) # 队列满时阻塞async def consumer():while True: item = await queue.get() await process(item) queue.task_done()
3.7 结构化并发:清晰的生命周期管理
Java 中 ExecutorService.shutdown() 和 CompletableFuture.allOf() 提供了任务组的粗粒度管理。Python 3.11+ 的 asyncio.TaskGroup 是更优雅的结构化并发原语。
async def crawl(): async with asyncio.TaskGroup() as tg:for url in urls: tg.create_task(fetch_and_save(url))# 这里保证所有任务都已结束(成功或失败)
unsetunset四、常见陷阱与调试(Java 程序员特别版)unsetunset
| | |
|---|
| 用了 requests、time.sleep 等同步库 | |
| | |
| | |
| | 用 TaskGroup 或显式 try/except |
| 用 asyncio.Event 或 Semaphore 时循环等待 | |
调试工具:
- 设置环境变量
PYTHONASYNCIODEBUG=1,会报告慢回调、未等待的任务等。 - 调用
asyncio.all_tasks() 打印当前所有待处理任务。 - 使用
loop.set_debug(True) 启用调试。
unsetunset五、结语:放下线程,拥抱协程unsetunset
Java 的线程模型是强大的,但它假定你有足够的内存和 CPU 来运行成千上万个线程(每个线程 1MB 栈)。Python 的异步模型则走了另一条路:用一个线程,协调所有任务。
这对于 IO 密集型应用是巨大的优势:你可以用很少的内存处理海量连接。但代价是,你必须遵守协作式调度的规则——永远不要在异步代码中同步阻塞。
从 Java 转到 Python,最难的不是语法,而是并发模型的思维切换。忘记你对线程的信任,学会在每一个 await 处温柔地让出控制权。遵循上述七条铁律,你的异步系统就能像瑞士钟表一样稳定运行,既享受了单线程免锁的便利,又扛住了高并发的冲击。
这正是 Python 异步编程的优雅之处:用最少的资源,处理最多的连接,而这一切仅仅取决于你是否愿意在每个 await 处,温柔地让出 CPU。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
