C:\Users\Administrator>python -VPython 3.8.10
没有安装python的请自行下载安装,切记安装时勾选Add pathhttps://www.python.org/downloads/windows/
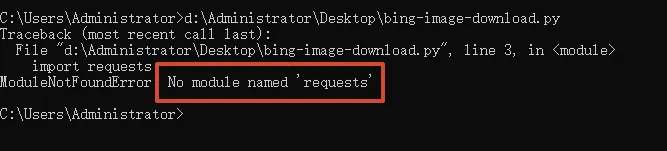

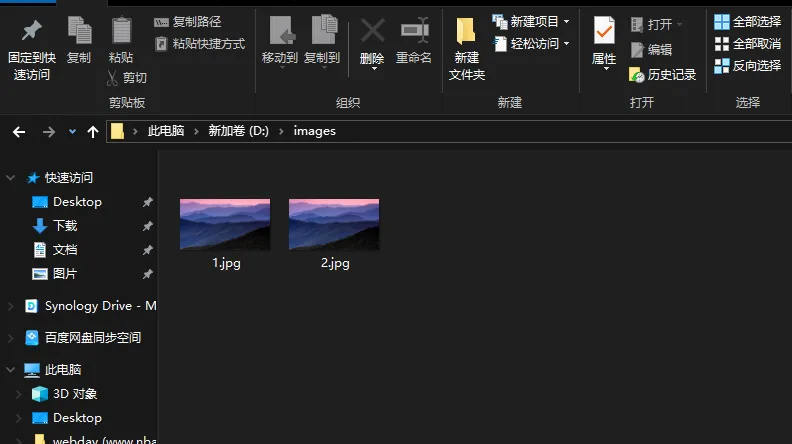
#!/usr/bin/env python# -*- coding: utf-8 -*-import requestsimport reimport osimport datetimedef main(): baseurl = 'https://cn.bing.com' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67" } # 请求必应主页 try: response = requests.get(baseurl, headers=headers, timeout=10) response.raise_for_status() except Exception as e: print(f"访问主页失败:{e}") return html = response.text # 正则提取完整 webp 图片链接 link_list = re.findall(r'https?://[^\s"]+\.webp', html) if not link_list: print("未找到图片链接") return imgUrlall = link_list[0] print("图片链接:", imgUrlall) # 确保保存目录存在 save_dir = r"D:\images" if not os.path.exists(save_dir): os.makedirs(save_dir) # 统计已有文件数 file_count = 0 for _, _, filenames in os.walk(save_dir): file_count += len(filenames) # 下载图片 try: imgRs = requests.get(imgUrlall, headers=headers, timeout=10) imgRs.raise_for_status() except Exception as e: print(f"图片下载失败:{e}") return # 保存文件 save_path = os.path.join(save_dir, f"{file_count + 1}.jpg") with open(save_path, "wb") as f: f.write(imgRs.content) print(f'下载完成,文件保存至:{save_path}')if __name__ == '__main__': main()
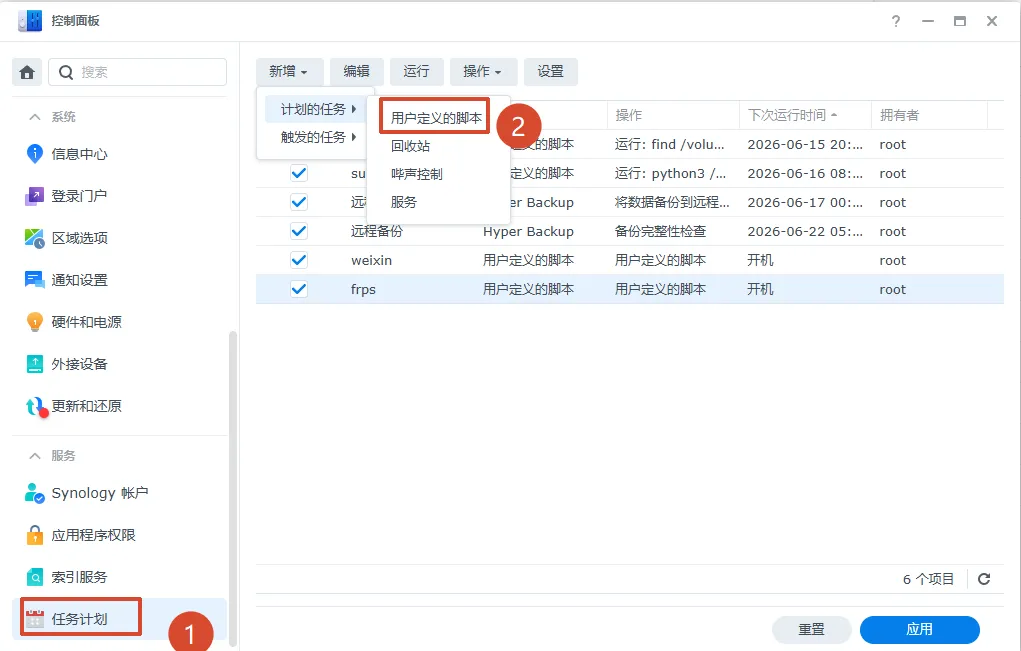
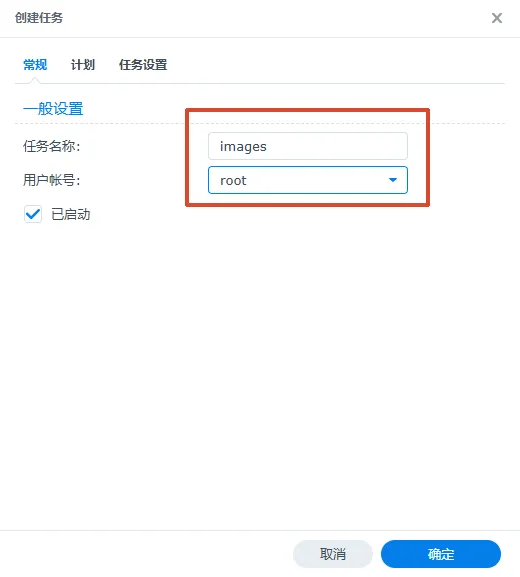
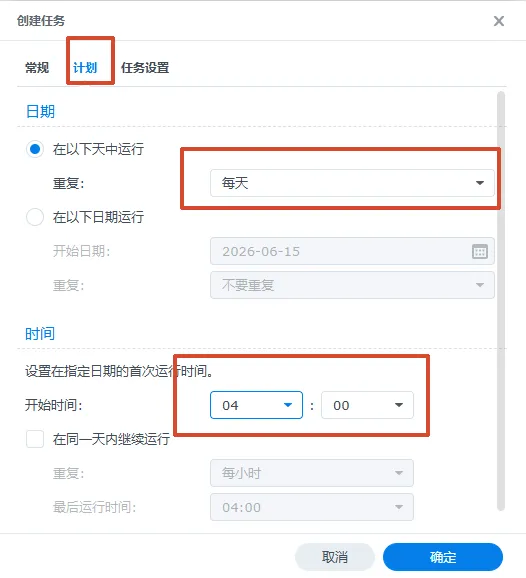
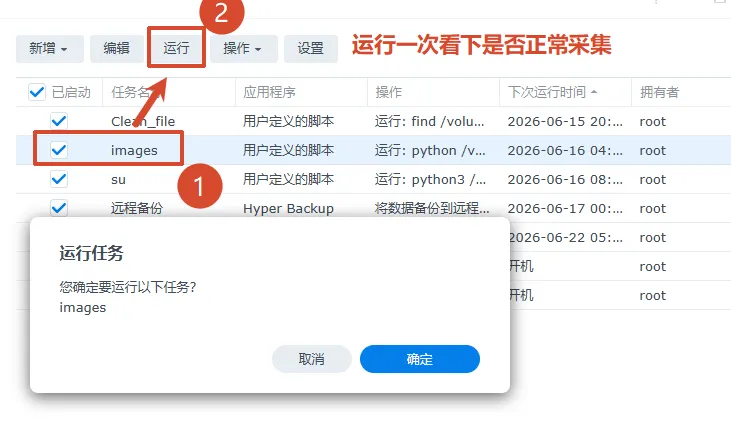
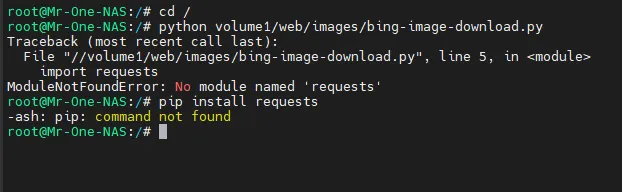
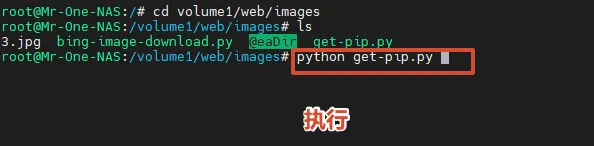
二、当然你也可以在NAS里面让Nas让你每天给你下载1张必应更新的图片3、到这里只能说完成了一半,可以用ssh连接nas测试运行,如图,运行后大概是这样因为缺少python包,但pip install requets又安装不了包,所以我们需要安装pip命令包,安装好pip命令包后,缺少什么我们就安装什么即可https://www.nbabc.cn:5213/f/d3HB/get-pip.py
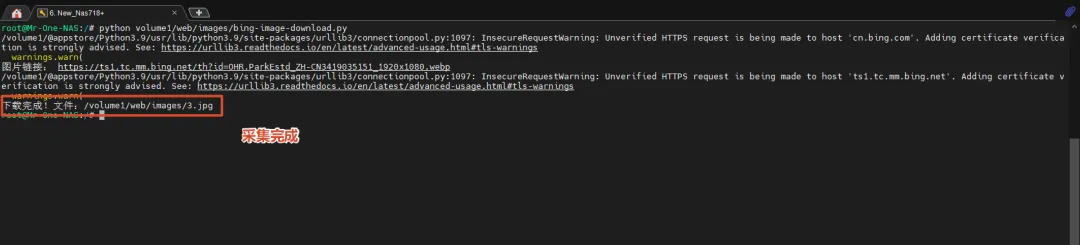
pip安装完成,测试是否正常运行爬取bing的图片查看图片确实存在,前面我们设置了定时,这样NAS每天都会自动下载一张bing的图片。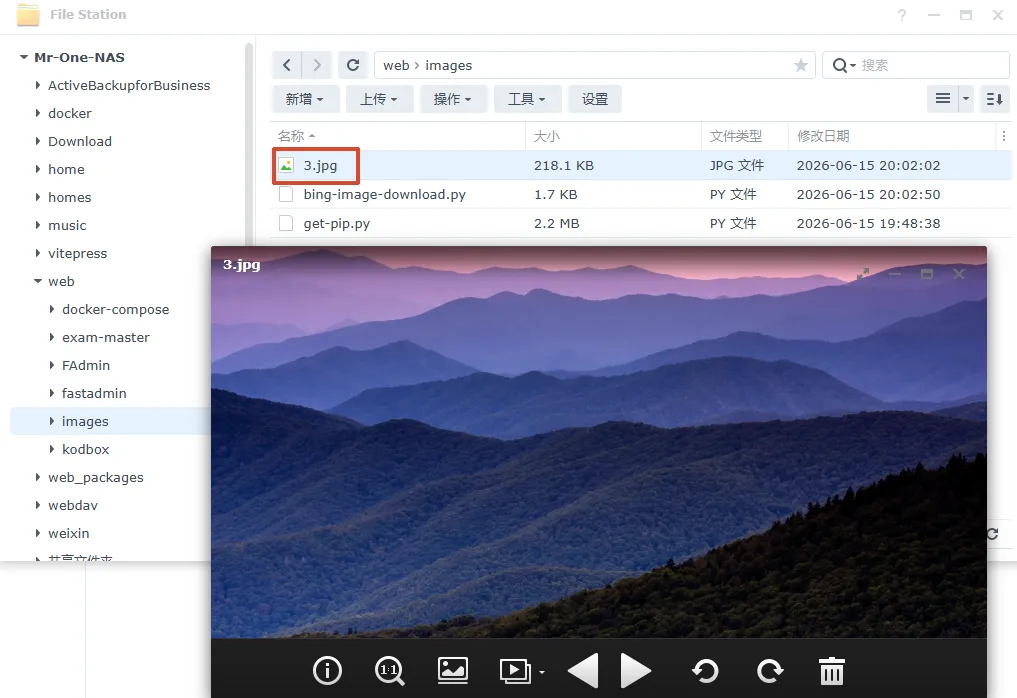
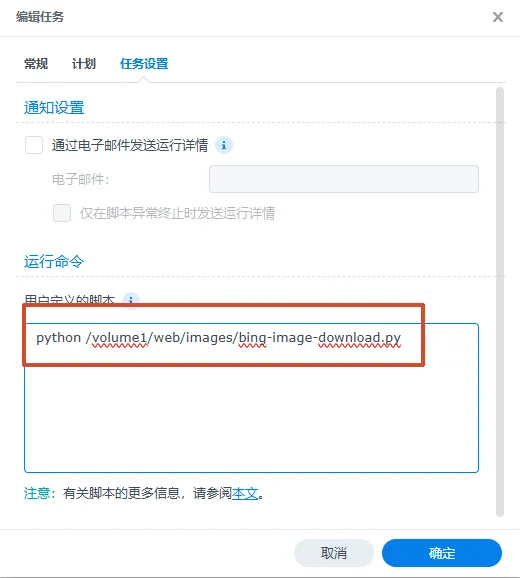
#!/usr/bin/env python# -*- coding: utf-8 -*-import requestsimport reimport osimport datetimedef main(): baseurl = 'https://cn.bing.com' headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/149.0.0.0 Safari/537.36 Edg/149.0.0.0" } # 访问必应主页,关闭SSL校验+超时,适配NAS try: response = requests.get(baseurl, headers=headers, timeout=15, verify=False) response.raise_for_status() except Exception as e: print(f"访问主页失败:{e}") return html = response.text # 精准正则提取完整 https 图片链接 link_list = re.findall(r'https://[^"\s]+\.webp', html) if not link_list: print("未匹配到图片链接") return imgUrlall = link_list[0] # 修复残缺协议兜底 if imgUrlall.startswith("s://"): imgUrlall = "https://" + imgUrlall[4:] print("图片链接:", imgUrlall) # 保存目录 save_dir = "/volume1/web/images/" if not os.path.exists(save_dir): os.makedirs(save_dir) # 统计已有文件数 file_count = 0 for _, _, filenames in os.walk(save_dir): file_count += len(filenames) # 下载图片 try: imgRs = requests.get(imgUrlall, headers=headers, timeout=15, verify=False) imgRs.raise_for_status() except Exception as e: print(f"图片下载失败:{e}") return # 保存文件 save_path = os.path.join(save_dir, f"{file_count + 1}.jpg") with open(save_path, "wb") as f: f.write(imgRs.content) print(f"下载完成!文件:{save_path}")if __name__ == '__main__': main()
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
