
📍 文 / 老Z
大家在比较 LLM 代码能力的时候,有个默认的前提很少有人质疑:Python 分高就是代码能力强。
这个前提来自 LiveCodeBench(LCB)——现在几乎是代码评测的事实标准。DeepSeek 每次发布技术报告,都会贴 LCB 分数;Gemini、GPT 也是如此。LCB 的设计很扎实:从 LeetCode、AtCoder、Codeforces 持续收集竞赛题,按发布日期过滤掉可能进入训练集的题目,防止数据污染。
但 LCB 只跑 Python。
这不是个小问题。真实的软件工程里,Go 在基础设施领域是主力,Java 在企业软件里无处不在,Rust 在系统编程里快速扩张,C++ 在高性能场景里依然不可替代。一个 LLM 如果只会 Python,在实际工程里能做的事是有限的。
这篇来自 GigaCode 和 Yandex 的 ICLR 2026 论文给 LCB 加了 11 种语言,跑了 24 个主流 LLM,结论不太好听:Python 成绩好的模型,在其他语言上经常翻车,有时候差距超过 30 个百分点。
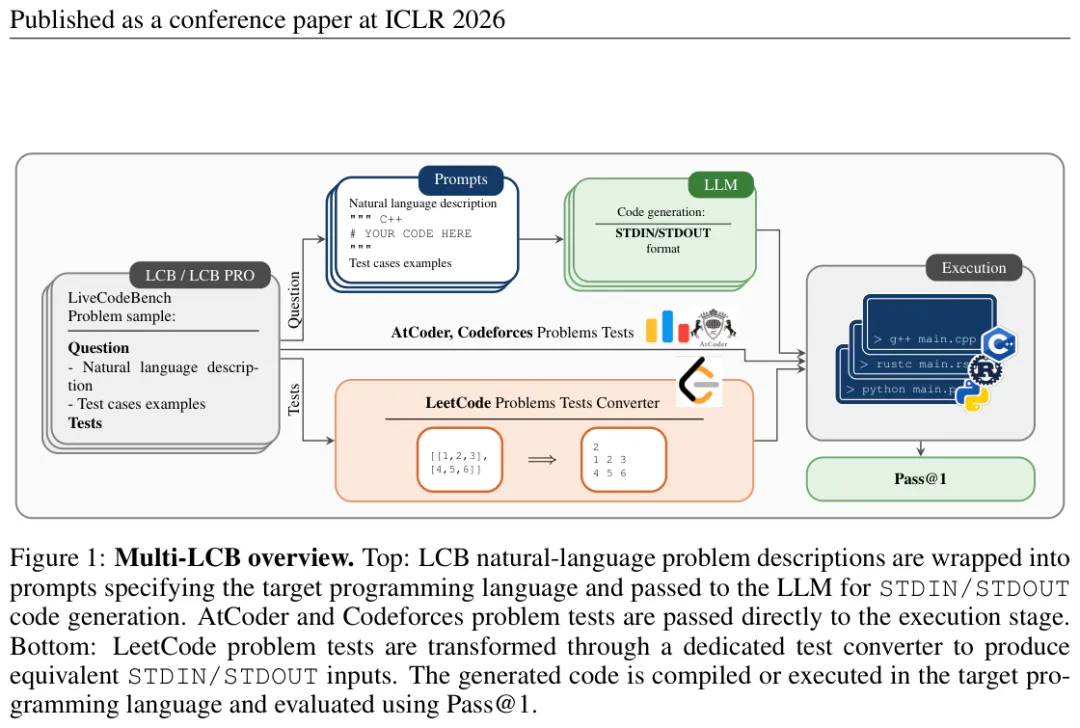
图:Multi-LCB评测流程。LCB的题目描述不变,prompt中指定目标语言,代码用STDIN/STDOUT格式执行评判。LeetCode的函数式题目经过自动转换器统一为STDIN/STDOUT格式。
为什么这件事以前没有人做好
多语言代码 benchmark 不是没有,问题是之前的都有结构性缺陷。
HumanEval、MBPP 是静态数据集,发布之后就不更新,很快就被污染进训练集,分数虚高。MBXP、MultiPL-E 把 HumanEval 翻译成其他语言,但继承了 HumanEval 的局限——小数据集、题型单一、同样静态。
更关键的问题是:之前的多语言 benchmark 不同语言往往用的是不同题目。这意味着你没法直接比较"同一个模型在 Python 和 Go 上的表现",因为两边的题目本来就不一样难。
Multi-LCB 的做法是:用同一套题,然后对每种语言跑。因为题目集完全相同,Python 分数和 Go 分数是直接可比的,差距就是语言差距,不是题目差距。
技术上最难搞的是 LeetCode 的题目格式。LeetCode 用的是 Functional 格式——给你一个 Python 函数签名,让你补全函数体。这个格式天然是 Python 绑定的,直接用在 C++ 里行不通,因为 C++ 没有对应的测试框架。
他们的解法是把所有 LeetCode 题目自动转成 STDIN/STDOUT 格式:解析题目里的样例 I/O,生成一套统一的输入输出规范,然后用同一套 judge 跑所有语言的代码。这样就绕开了语言绑定的问题,题目本质上变成了"读 STDIN,算,写 STDOUT",任何语言都能跑。
AtCoder 和 Codeforces 本来就是 STDIN/STDOUT 格式,不用转换。
跑出来的数字
24 个主流 LLM,12 种语言,零样本评测,Pass@1 指标(生成的代码能不能一次过所有 test case)。

表:Multi-LCB完整评测结果。Python列普遍高于其他语言列,差距在不同模型之间差异显著。粗体为最优,斜体为次优。
排第一的是 GPT-OSS-120B*(Medium),Python 71.1%,12 语言平均 67.8%,差距最小,也就是说它的多语言一致性最好。
第二名 Qwen3-235B-A22B-Thk-2507* 在 Python 上更强(74.0%),但跨语言平均只有 64.0%,差了接近 10 个百分点。
最有意思的数字:GPT-OSS-120B* 在 Go、JavaScript、TypeScript、Rust、Ruby、Kotlin 上全面超过 Qwen3-235B,尽管后者在 Python 上领先。这就是 Python 排名不等于跨语言排名的直接证据。
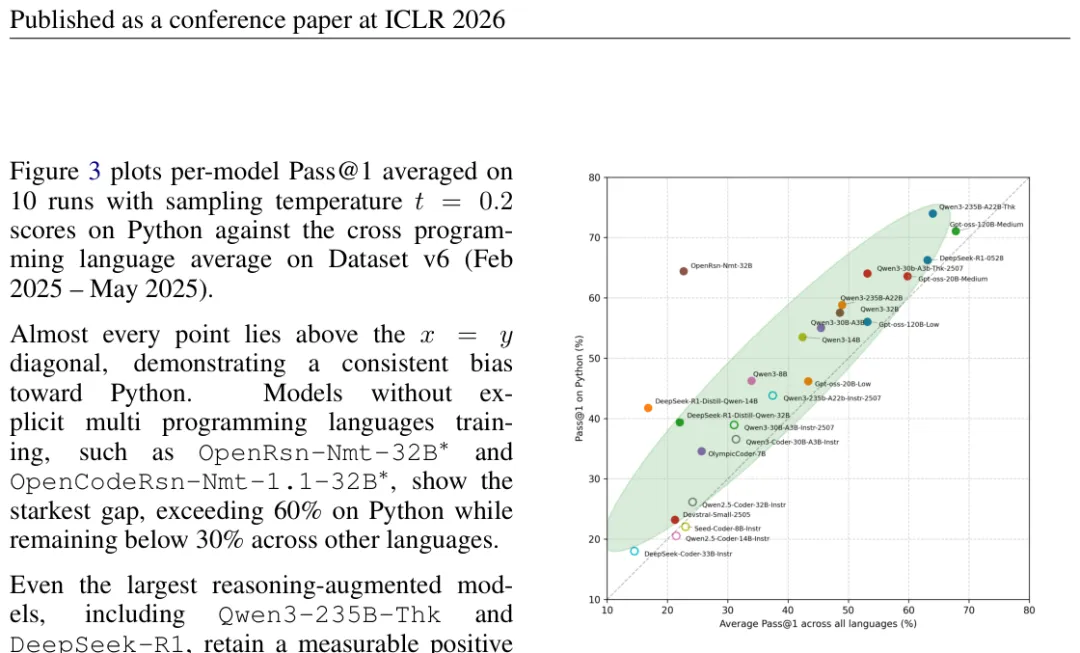
图:纵轴是Python Pass@1,横轴是12语言平均Pass@1。几乎所有点都在y=x对角线上方,证明系统性Python偏差。
散点图(Figure 3)把这个结论说得很直白:纵轴 Python 分数,横轴跨语言平均分。几乎所有点都在 y=x 对角线上方,也就是 Python 分比平均分高。这不是某几个模型的问题,是所有 24 个模型都有的规律性偏差。
Python 过拟合最严重的两个模型:OpenRsn-Nmt-32B 和 OpenCodeRsn-Nmt-1.1-32B。这两个是专门做代码的模型,但没有多语言训练,Python 跑出 60% 以上,其他语言却普遍低于 30%,差距超过 30 个百分点。
语言之间的难度也有清晰的梯度。Python 平均约 48%,Java 和 C++ 约 44%,中间层(C#、Ruby、PHP、Go、Rust、Kotlin、JavaScript/TypeScript)约 33-39%,Scala 持续垫底约 29%。Scala 这么低猜测是因为训练语料本来就少,加上 Scala 的类型系统和惯用法跟 Python 差异大,cross-language knowledge transfer 效果差。
污染的证据
这篇论文里有一个细节我觉得挺有意思但没有被重点强调:月度趋势分析(Figure 5)。

图:Top-10模型在所有语言上的月度Pass@1趋势。较早月份的成绩系统性更高,并在模型训练截止日期处有明显下跌,这是残留污染的直接证据。
图里能看出来:所有模型在较早月份的题目上表现系统性更好,而且在各自的训练数据截止日期处有明显的成绩下跌,之后保持在较低水平。这说明即使有发布日期过滤,预训练数据里还是有竞赛题的残留痕迹,模型在见过的题上表现更好。
这不是 Multi-LCB 特有的问题,是整个代码 benchmark 生态的共同问题。论文的做法是把主实验限制在 2025 年 2 月之后发布的题目上,这样能最小化污染干扰,但不能完全消除。
几点个人看法
Multi-LCB 这篇工作的价值主要在"揭露问题"而不是"解决问题"。它证明了 Python 评分在多语言泛化这件事上是个糟糕的代理指标,现有的代码模型存在系统性 Python 偏差,这个偏差在某些模型上超过 30 pp。
但这个发现本身并不令人意外。绝大多数 LLM 训练数据里 Python 代码的比例远超其他语言,这是公开的事实,自然会产生 Python 偏差。让我觉得更有意思的问题是:如果专门在多语言数据上训练,提升能有多大?论文里测试的模型里没有专门做多语言优化的,这是个空白。
有一点没想通:STDIN/STDOUT 的格式转换会不会引入额外的难度?有些语言解析字符串输入的写法比较繁琐(比如 Scala),在 Python 里一行搞定的读取,在 Scala 里可能要五行。这部分难度应该算在"语言能力"里还是"格式适应性"里,论文没有给出分析。
Scala 持续垫底这件事也值得单独说一下。不只是训练数据少的问题,Scala 的函数式编程惯用法跟竞赛编程的命令式风格本来就有不小的阻抗,用 Scala 写竞赛题本身就比用 Python 或 Java 费力。这可能会导致 Multi-LCB 低估了 LLM 真正的 Scala 代码能力。
数据和代码已经开源,benchmark 会跟着 LCB 持续更新。这一点比论文本身更有价值——一个会过时的静态 benchmark 意义有限,但一个跟着新题目自动扩展的多语言 benchmark 是真正能用的工具。
论文链接:https://arxiv.org/abs/2606.20517
代码:https://github.com/Multi-LCB/Multi-LCB
✍️ 老Z ·
欢迎转发,谢绝洗稿
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
