Python difflib库详解:文本差异比较与合并实战指南
- 3、基础比较:SequenceMatcher 与相似度计算
- 4.2、 生成 Unified Diff(最常用)
- 6.1 、模糊匹配:get_close_matches
一、Python difflib库详解
1、 引言:为什么需要文本差异比较?
在日常开发、代码审查、文档协作和日志分析中,我们经常需要比较两个文本的差异。手动逐行比对不仅效率低下,而且容易出错。Python 标准库中的 difflib 模块正是为解决这一问题而生,它提供了一系列强大的工具,用于计算序列(尤其是字符串序列)之间的差异,并以多种直观的格式展示结果。
difflib 的核心算法基于 “最长公共子序列” 和 “Ratcliff/Obershelp 模式识别”,能够高效地找出文本的增、删、改操作。无论是生成代码补丁、对比配置文件版本,还是实现一个简单的在线文本差异查看器,difflib 都是你的得力助手。
2、 核心类与方法概览
difflib 模块主要提供了以下几个类和函数:
| | |
|---|
difflib.SequenceMatcher | | |
difflib.Differ | 逐行比较文本,生成类 Unix diff 命令的输出 | |
difflib.HtmlDiff | | |
difflib.unified_diff | 生成 Unified Diff 格式的差异,广泛用于代码版本控制 | |
difflib.context_diff | | |
difflib.ndiff | | |
difflib.get_close_matches | | |
接下来,我们将逐一深入探讨。
3、基础比较:SequenceMatcher 与相似度计算
SequenceMatcher 是 difflib 的基石。它不直接生成可读的差异报告,而是计算出两个序列之间的匹配块,并提供了计算相似度比率的方法。
3.1、 基本使用
import difflibtext1 = "Python is great for data analysis."text2 = "Python is great for web development and data analysis."# 创建 SequenceMatcher 对象matcher = difflib.SequenceMatcher(None, text1, text2)# 计算相似度比率 (0.0 到 1.0)ratio = matcher.ratio()print(f"相似度比率: {ratio:.2f}") # 输出: 相似度比率: 0.78# 获取匹配块# 每个块是一个三元组 (i, j, n),表示 text1[i:i+n] == text2[j:j+n]matching_blocks = matcher.get_matching_blocks()print("匹配块:")for block in matching_blocks: i, j, n = block if n: # 忽略长度为 0 的块 print(f" text1[{i}:{i+n}] == text2[{j}:{j+n}] -> '{text1[i:i+n]}'")
输出示例
C:\Users\徐鹏\Desktop\55\.venv\Scripts\python.exe C:\Users\徐鹏\Desktop\55\main.py 相似度比率: 0.77匹配块: text1[0:20] == text2[0:20] -> 'Python is great for ' text1[20:34] == text2[40:54] -> 'data analysis.'进程已结束,退出代码为 0
3.2 、理解匹配块与差异
get_matching_blocks() 返回的是两个序列中完全相同的部分。差异部分则位于这些匹配块之间。SequenceMatcher 还提供了 get_opcodes() 方法,它能更清晰地告诉我们为了将序列 a 转换为序列 b 需要执行哪些操作。
a = ["apple", "banana", "cherry", "date"]b = ["apple", "blueberry", "cherry", "elderberry"]matcher = difflib.SequenceMatcher(None, a, b)opcodes = matcher.get_opcodes()print("操作码 (tag, i1, i2, j1, j2):")for tag, i1, i2, j1, j2 in opcodes: print(f" {tag:7} a[{i1}:{i2}] -> b[{j1}:{j2}]", end=" ") if tag == 'equal': print(f" (内容相同: {a[i1:i2]})") elif tag == 'replace': print(f" (将 {a[i1:i2]} 替换为 {b[j1:j2]})") elif tag == 'delete': print(f" (删除 {a[i1:i2]})") elif tag == 'insert': print(f" (插入 {b[j1:j2]})")
输出示例:
操作码 (tag, i1, i2, j1, j2): equal a[0:1] -> b[0:1] (内容相同: ['apple']) replace a[1:2] -> b[1:2] (将 ['banana'] 替换为 ['blueberry']) equal a[2:3] -> b[2:3] (内容相同: ['cherry']) replace a[3:4] -> b[3:4] (将 ['date'] 替换为 ['elderberry'])
4、生成可读的差异报告
SequenceMatcher 提供了底层数据,但通常我们需要更直观的输出。Differ, unified_diff 和 context_diff 就是为此设计的。
4.1 、使用 Differ 类
Differ 生成的行级差异标记与 Unix diff 命令类似:
' ''-''+''?':指示行内具体字符的增删(需要设置 linejunk 和 charjunk 参数为 None 来启用)
from difflib import Differtext1_lines = [ "def hello_world():", " print('Hello, World!')", " return True"]text2_lines = [ "def hello_world():", " print('Hello, Python!')", " x = 1 + 2", " return True"]d = Differ()diff = list(d.compare(text1_lines, text2_lines))print("Differ 比较结果:")for line in diff: # 根据前缀添加颜色或样式(此处用符号表示) if line.startswith('-'): print(f"\033[91m{line}\033[0m") # 红色表示删除 elif line.startswith('+'): print(f"\033[92m{line}\033[0m") # 绿色表示新增 elif line.startswith('?'): print(f"\033[93m{line}\033[0m") # 黄色表示行内变化提示 else: print(line)
输出示例: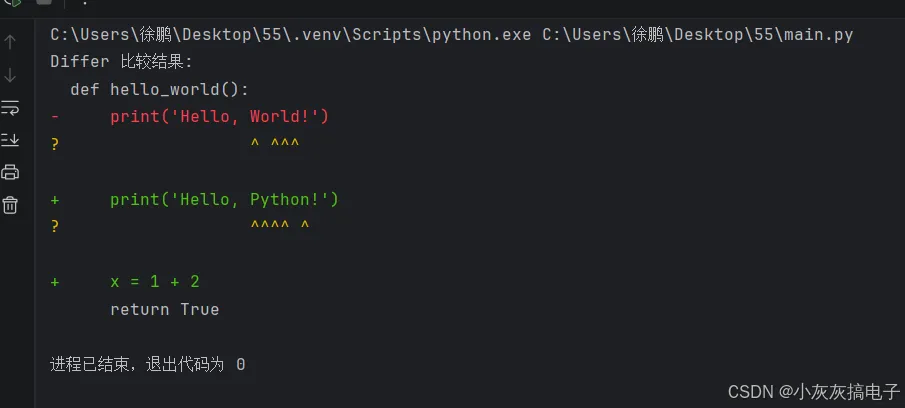
4.2、 生成 Unified Diff(最常用)
Unified Diff 格式是 Git 等版本控制系统使用的标准补丁格式。它非常紧凑,包含了上下文行。
from difflib import unified_diffimport sys# 假设我们有两个版本的代码片段original = """def calculate_sum(a, b): result = a + b print(f"The sum is {result}") return result"""modified = """def calculate_sum(a, b): # 计算两数之和 total = a + b print(f"The sum is {total}") return total"""diff_lines = unified_diff( original.splitlines(keepends=True), modified.splitlines(keepends=True), fromfile='original.py', tofile='modified.py', lineterm='\n' # 确保行尾是换行符)print("Unified Diff 格式:")sys.stdout.writelines(diff_lines)
输出示例:
--- original.py+++ modified.py@@ -1,5 +1,6 @@ def calculate_sum(a, b):- result = a + b+ # 计算两数之和+ total = a + b- print(f"The sum is {result}")+ print(f"The sum is {total}")- return result+ return total
@@ -1,5 +1,6 @@ 表示原始文件从第1行开始的5行,被修改为从第1行开始的6行。-+
4.3 、生成 Context Diff
Context Diff 格式比 Unified Diff 更冗长,但提供了更多上下文,曾经是 patch 命令的默认格式。
from difflib import context_diffdiff = context_diff( a=original.splitlines(keepends=True), b=modified.splitlines(keepends=True), fromfile='old_version', tofile='new_version',)print("Context Diff 格式 (前几行):")for i, line in enumerate(diff): if i > 15: # 只打印一部分 break print(line, end='')
5、 高级应用:生成 HTML 差异报告
HtmlDiff 类可以生成一个完整的 HTML 页面,用颜色高亮显示差异,非常适合集成到 Web 应用中。
from difflib import HtmlDiffhtml_diff = HtmlDiff(wrapcolumn=60) # wrapcolumn 可控制换行宽度# 生成 HTML 表格html_table = html_diff.make_table( fromlines=original.splitlines(), tolines=modified.splitlines(), fromdesc='原始版本', todesc='修改版本', context=True, # 显示上下文 numlines=3 # 上下文的行数)# 生成完整 HTML 页面full_html = html_diff.make_file( fromlines=original.splitlines(), tolines=modified.splitlines(), fromdesc='Original', todesc='Modified')# 将 HTML 保存到文件,方便查看with open('diff_report.html', 'w', encoding='utf-8') as f: f.write(full_html)print("HTML 差异报告已生成到 'diff_report.html',请在浏览器中打开查看。")
生成的 HTML 页面会以并排表格的形式展示,新增行为绿色背景,删除行为红色背景,修改行则会有黄底色提示,非常直观。
6、实用技巧与函数
6.1 、模糊匹配:get_close_matches
get_close_matches 是一个非常实用的函数,它能在列表中快速找到与目标词最相似的几个匹配项。其核心是 SequenceMatcher.ratio()。
from difflib import get_close_matchescandidates = ['apple', 'application', 'apply', 'appliance', 'banana', 'cherry']word = 'appel'# 找出前3个最相似的词matches = get_close_matches(word, candidates, n=3, cutoff=0.6)print(f"与 '{word}' 最相似的词: {matches}")# 输出: 与 'appel' 最相似的词: ['apple', 'apply', 'application']# 应用场景:命令行工具的命令纠错available_commands = ['start', 'stop', 'status', 'restart', 'config']user_input = 'statu'suggestion = get_close_matches(user_input, available_commands, n=1, cutoff=0.5)if suggestion: print(f"您想输入的是 '{suggestion[0]}' 吗?")
输出示例
与 'appel' 最相似的词: ['apply', 'apple']您想输入的是 'status' 吗?
6.2 、忽略“垃圾”字符
在比较时,有时我们希望忽略空格、标点或特定字符。可以通过自定义 isjunk 函数来实现。
import difflibimport stringdef ignore_punctuation_and_space(s): """移除标点和空格""" return s.translate(str.maketrans('', '', string.punctuation + ' '))text1 = "Hello, world!"text2 = "Hello world"matcher = difflib.SequenceMatcher( lambda x: x in " ,!", # isjunk 函数:认为空格、逗号、叹号是“垃圾” text1, text2)print(f"忽略部分字符后的相似度: {matcher.ratio():.2f}") # 可能更高# 另一种方式:预处理文本clean1 = ignore_punctuation_and_space(text1)clean2 = ignore_punctuation_and_space(text2)matcher2 = difflib.SequenceMatcher(None, clean1, clean2)print(f"完全清理后的相似度: {matcher2.ratio():.2f}")
输出示例
忽略部分字符后的相似度: 0.92完全清理后的相似度: 1.00
7、 实战案例:一个简单的文件差异比较工具
让我们综合运用以上知识,构建一个命令行文件比较工具。
#!/usr/bin/env python3"""file_diff_tool.py - 一个简单的文件差异比较工具用法: python file_diff_tool.py <file1> <file2> [--format {unified,context,html}]"""import difflibimport argparseimport sysdef compare_files(file1_path, file2_path, diff_format='unified'): """比较两个文件并输出差异""" try: with open(file1_path, 'r', encoding='utf-8') as f1, \ open(file2_path, 'r', encoding='utf-8') as f2: lines1 = f1.readlines() lines2 = f2.readlines() except FileNotFoundError as e: print(f"错误: 文件未找到 - {e}", file=sys.stderr) return False except UnicodeDecodeError: print("错误: 文件编码可能不是 UTF-8,请尝试其他编码。", file=sys.stderr) return False if diff_format == 'unified': diff_lines = difflib.unified_diff( lines1, lines2, fromfile=file1_path, tofile=file2_path, lineterm='\n' ) sys.stdout.writelines(diff_lines) elif diff_format == 'context': diff_lines = difflib.context_diff( lines1, lines2, fromfile=file1_path, tofile=file2_path, lineterm='\n' ) sys.stdout.writelines(diff_lines) elif diff_format == 'html': html_diff = difflib.HtmlDiff() html_content = html_diff.make_file( lines1, lines2, fromdesc=file1_path, todesc=file2_path, context=True ) output_file = f"diff_{file1_path}_{file2_path}.html" with open(output_file, 'w', encoding='utf-8') as f: f.write(html_content) print(f"HTML 差异报告已生成: {output_file}") else: print(f"不支持的格式: {diff_format}", file=sys.stderr) return False return Truedef main(): parser = argparse.ArgumentParser(description='比较两个文本文件的差异') parser.add_argument('file1', help='第一个文件路径') parser.add_argument('file2', help='第二个文件路径') parser.add_argument('--format', choices=['unified', 'context', 'html'], default='unified', help='差异输出格式 (默认: unified)') args = parser.parse_args() success = compare_files(args.file1, args.file2, args.format) sys.exit(0 if success else 1)if __name__ == '__main__': main()
使用示例:
# 生成 Unified Diffpython file_diff_tool.py old_code.py new_code.py# 生成 Context Diffpython file_diff_tool.py old_code.py new_code.py --format context# 生成 HTML 报告python file_diff_tool.py old_code.py new_code.py --format html
8、 总结
difflib 是 Python 标准库中一个强大而实用的模块,它使得文本差异比较变得简单高效。通过本文,你应该掌握了:
- 核心类与函数:
SequenceMatcher, Differ, HtmlDiff, unified_diff 等的用途与区别。 - 差异格式:理解并能够生成 Unified Diff、Context Diff 和 HTML 报告。
- 实用技巧:使用
get_close_matches 进行模糊匹配,通过 isjunk 参数忽略无关字符。 - 实战应用
最佳实践建议:
- 对于代码版本比较,优先使用
unified_diff,因为它最紧凑且被广泛支持。 - 需要在 Web 页面展示差异时,
HtmlDiff 是最佳选择。 - 进行模糊搜索或拼写检查时,别忘了
get_close_matches。 - 处理大文件时,注意内存消耗,可以考虑逐块读取比较。
二、代码示例
1、示例代码
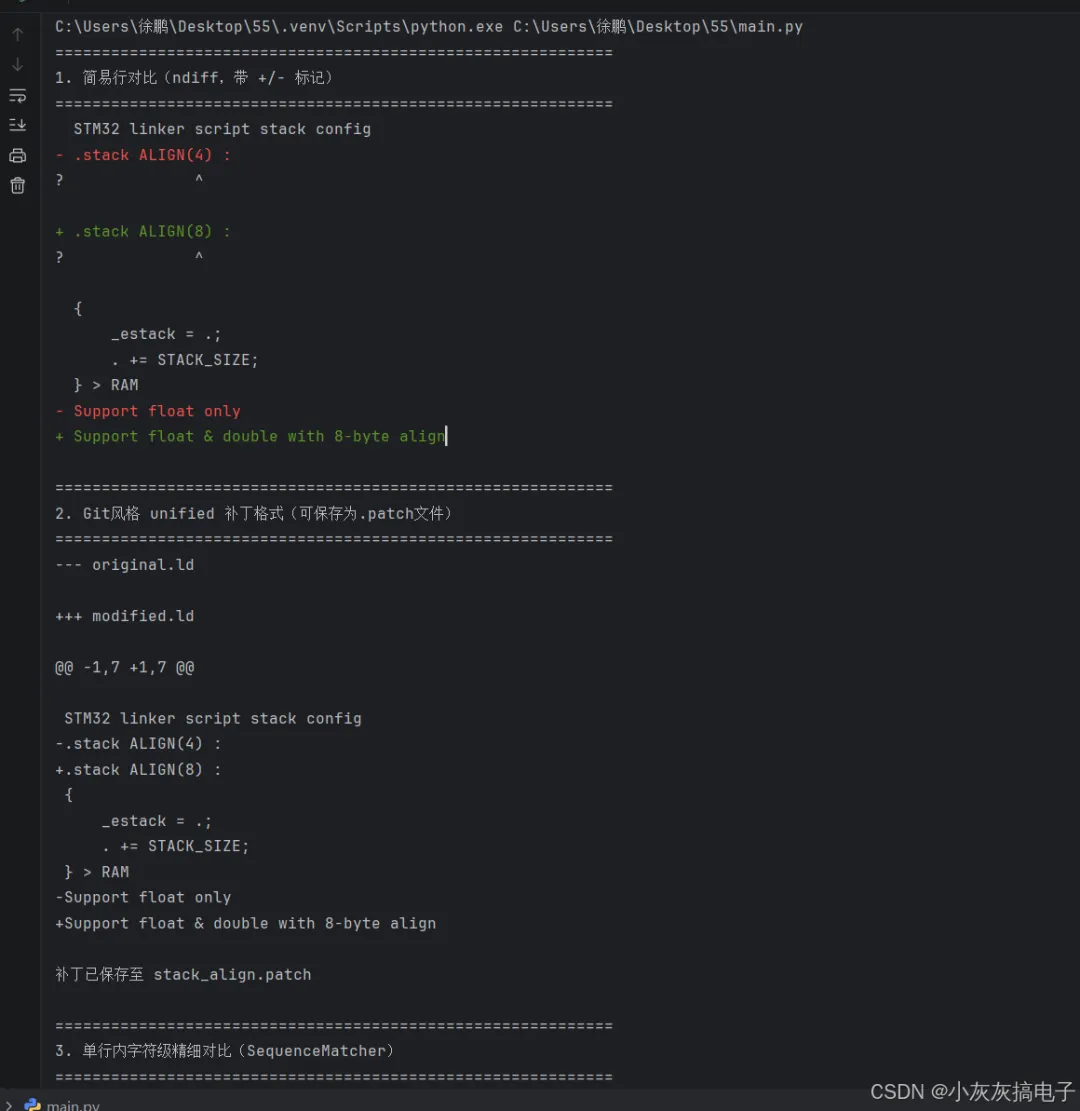
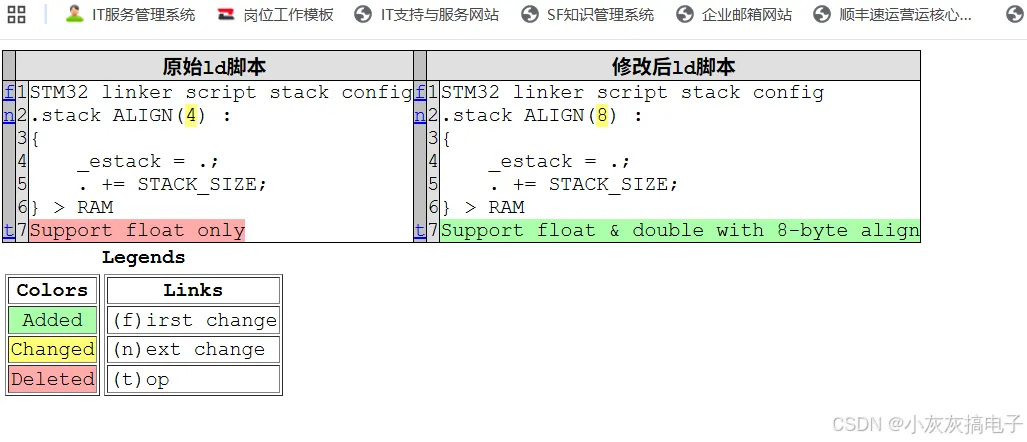
import difflib# 两段STM32链接脚本文本(和Rust示例一致)old_text = """STM32 linker script stack config.stack ALIGN(4) :{ _estack = .; . += STACK_SIZE;} > RAMSupport float only"""new_text = """STM32 linker script stack config.stack ALIGN(8) :{ _estack = .; . += STACK_SIZE;} > RAMSupport float & double with 8-byte align"""# 按行切分成列表old_lines = old_text.splitlines()new_lines = new_text.splitlines()print("=" * 60)print("1. 简易行对比(ndiff,带 +/- 标记)")print("=" * 60)diff_ndiff = difflib.ndiff(old_lines, new_lines)for line in diff_ndiff: # 标记说明:- 删除行、+新增行、 不变行、?字符改动提示 if line.startswith("-"): print(f"\033[31m{line}\033[0m") # 红色删除 elif line.startswith("+"): print(f"\033[32m{line}\033[0m") # 绿色新增 else: print(line)print("\n" + "=" * 60)print("2. Git风格 unified 补丁格式(可保存为.patch文件)")print("=" * 60)# context=2 上下文显示2行unified_diff = difflib.unified_diff(old_lines, new_lines, fromfile="original.ld", tofile="modified.ld", n=2)patch_content = "\n".join(unified_diff)print(patch_content)# 保存补丁到文件with open("stack_align.patch", "w", encoding="utf-8") as f: f.write(patch_content)print("\n补丁已保存至 stack_align.patch")print("\n" + "=" * 60)print("3. 单行内字符级精细对比(SequenceMatcher)")print("=" * 60)# 对比改动行:ALIGN(4) → ALIGN(8)old_line = ".stack ALIGN(4) :"new_line = ".stack ALIGN(8) :"sm = difflib.SequenceMatcher(None, old_line, new_line)output = []for tag, i1, i2, j1, j2 in sm.get_opcodes(): if tag == "equal": output.append(old_line[i1:i2]) elif tag == "delete": output.append(f"\033[31;9m{old_line[i1:i2]}\033[0m") elif tag == "insert": output.append(f"\033[32;1m{new_line[j1:j2]}\033[0m") elif tag == "replace": output.append(f"\033[31;9m{old_line[i1:i2]}\033[0m") output.append(f"\033[32;1m{new_line[j1:j2]}\033[0m")print("原行对比高亮:", "".join(output))print("\n" + "=" * 60)print("4. 生成HTML可视化对比页面")print("=" * 60)html_diff = difflib.HtmlDiff(wrapcolumn=80)html_page = html_diff.make_file(old_lines, new_lines, fromdesc="原始ld脚本", todesc="修改后ld脚本")with open("diff_view.html", "w", encoding="utf-8") as f: f.write(html_page)print("可视化对比页面已保存 diff_view.html,浏览器打开即可查看")
2、运行结果
============================================================1. 简易行对比(ndiff,带 +/- 标记)============================================================ STM32 linker script stack config- .stack ALIGN(4) :? ^+ .stack ALIGN(8) :? ^ { _estack = .; . += STACK_SIZE; } > RAM- Support float only+ Support float & double with 8-byte align============================================================2. Git风格 unified 补丁格式(可保存为.patch文件)============================================================--- original.ld+++ modified.ld@@ -1,7 +1,7 @@ STM32 linker script stack config-.stack ALIGN(4) :+.stack ALIGN(8) : { _estack = .; . += STACK_SIZE; } > RAM-Support float only+Support float & double with 8-byte align补丁已保存至 stack_align.patch============================================================3. 单行内字符级精细对比(SequenceMatcher)============================================================原行对比高亮: .stack ALIGN(48) :============================================================4. 生成HTML可视化对比页面============================================================可视化对比页面已保存 diff_view.html,浏览器打开即可查看进程已结束,退出代码为 0

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
