深入理解元组:Python中的不可变序列
元组(tuple)作为 Python 中独特的不可变有序序列,看似简单却暗藏高效实用的特性,它以 “不可修改” 为核心,兼具轻量、可哈希、自动解包等优势,是存储固定数据、优化程序性能的重要工具。
本文从元组的基础定义(重点避坑单元素元组需加逗号)出发,层层递进拆解核心知识点:
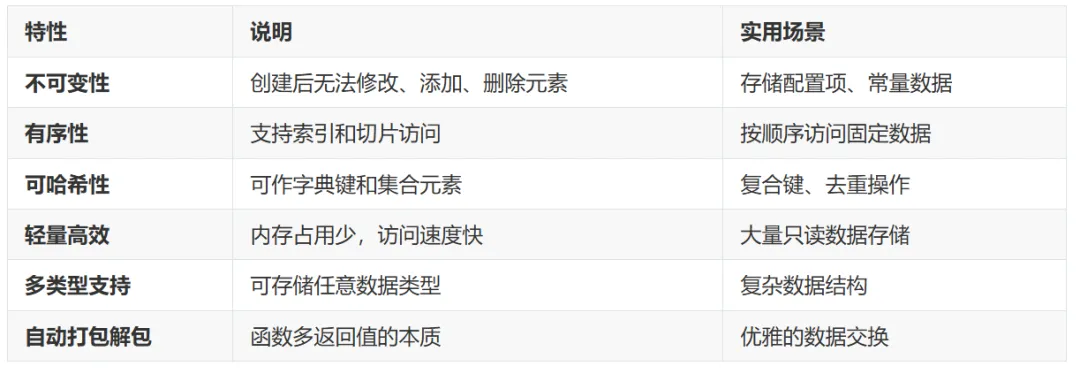
1.六大核心特性:不可变性保障数据安全、可哈希性支持字典复合键、轻量高效适配大量只读数据,还支持自动打包解包,是函数多返回值的本质;2.基础操作:仅支持索引、切片、拼接等只读操作,内置方法仅有count()(统计次数)和index()(查找索引),简洁易用;3.高级技巧:元组解包(普通解包 + 星号解包)实现优雅变量交换、部分元素提取,命名元组则让元组拥有 “属性访问” 能力,更贴合结构化数据场景;4.深层认知:元组的不可变是 “引用不可变”,内部可变元素(列表 / 字典)可修改,同时不可变性带来哈希支持、线程安全、性能优化三大核心价值;5.选型指南:明确元组与列表的适用边界,数据无需修改、需哈希支持、性能敏感时优先选元组,数据动态变化时选列表;6.最佳实践:涵盖配置存储、函数多返回值、字典复合键等实用场景,附带性能对比,帮助开发者在实际开发中高效运用元组。
这份指南全面覆盖元组从基础到进阶的所有知识点,无论是 Python 新手巩固数据结构,还是资深开发者优化程序性能,都能从中获取实用价值,彻底吃透元组的核心用法与底层逻辑。
一、元组核心特性
1.1 定义方式与特点
元组使用小括号 () 定义,元素用逗号分隔。与列表最大的区别在于不可变性:
# 基础定义t1 = (1, 2, 3, "Python")t2 = 4, 5, 6, "Java" # 省略括号同样有效# 单元素元组(必须加逗号)single = (10,) # 元组not_tuple = (10) # 整数,不是元组!# 空元组empty1 = ()empty2 = tuple()# 元组转换list_to_tuple = tuple([1, 2, 3]) # (1, 2, 3)str_to_tuple = tuple("Python") # ('P', 'y', 't', 'h', 'o', 'n')
1.2 六大核心特性
二、基础操作:只读访问
2.1 索引与切片
# 基础访问colors = ("red", "green", "blue", "yellow")print(colors[0]) # redprint(colors[-1]) # yellowprint(colors[1:3]) # ('green', 'blue')print(colors[::-1]) # 反转# 注意:不可修改!# colors[0] = "black" # ❌ 报错
2.2 常用只读操作
t = (1, 2, 2, 3, 4)# 基本信息len(t) # 5,元素个数2 in t # True,成员判断t + (5, 6) # (1, 2, 2, 3, 4, 5, 6),拼接(生成新元组)t * 2 # (1, 2, 2, 3, 4, 1, 2, 2, 3, 4),重复# 比较运算(元素需可比较)(1, 2) < (1, 3) # True,逐元素比较
三、核心方法:仅有两个
由于不可变性,元组只有两个内置方法:
data = (1, 2, 2, 3, 2, 4)# 统计元素出现次数data.count(2) # 3# 查找元素索引(不存在则报错)data.index(3) # 3data.index(2, 2, 5) # 2,在索引2-5之间查找
四、高级技巧:元组解包
4.1 基础解包
# 变量数与元素数匹配point = (10, 20)x, y = point # x=10, y=20# 函数多返回值(本质就是元组)def get_coordinates(): return 30, 40x, y = get_coordinates()# 优雅的变量交换a, b = 5, 10a, b = b, a # a=10, b=5
4.2 星号解包
numbers = (1, 2, 3, 4, 5)# 获取首尾,中间用*收集first, *middle, last = numbers# first=1, middle=[2,3,4], last=5# 忽略某些元素(使用_占位符)_, second, *_, last = numbers# second=2, last=5# 函数调用解包def multiply(x, y): return x * yparams = (3, 4)multiply(*params) # 12,等价于 multiply(3, 4)
五、不可变性的深层理解
5.1 "不可变"的真实含义
# 元组存储的是引用,不可变的是引用本身t = (1, [2, 3], 4)# 不能修改元组的元素引用# t[1] = [5, 6] # ❌ 报错# 但可以修改可变元素的内容t[1].append(7) # ✅ 允许t[1][0] = 8 # ✅ 允许print(t) # (1, [8, 3, 7], 4)
5.2 为什么需要不可变性?
1.数据安全:防止意外修改2.哈希支持:可作字典键3.性能优化:内存占用小,访问速度快4.线程安全:无需加锁保护
六、实用场景精选
6.1 配置项存储
# 数据库配置DB_CONFIG = ("localhost", 3306, "my_db", "user", "password")# 解包使用host, port, db, user, pwd = DB_CONFIG
6.2 函数多返回值
def analyze_data(data): """返回统计结果""" min_val = min(data) max_val = max(data) avg_val = sum(data) / len(data) return min_val, max_val, avg_val # 自动打包为元组# 解包接收min_val, max_val, avg_val = analyze_data([1, 2, 3, 4, 5])
6.3 字典复合键
# 坐标到颜色的映射color_map = { (0, 0): "red", (0, 1): "green", (1, 0): "blue"}print(color_map[(0, 1)]) # green
6.4 命名元组(更优雅的选择)
from collections import namedtuple# 定义结构Point = namedtuple('Point', ['x', 'y', 'z'])Color = namedtuple('Color', ['red', 'green', 'blue'])# 创建实例p = Point(10, 20, 30)c = Color(255, 0, 0)# 访问方式print(p.x, p.y, p.z) # 10 20 30print(c.red) # 255
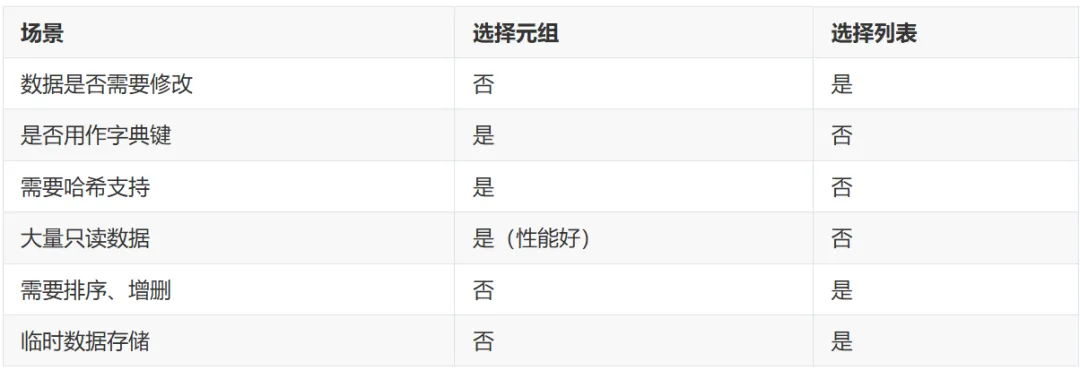
七、元组 vs 列表:如何选择?
简单判断原则:
•如果数据创建后不需要修改 → 选择元组•如果数据需要动态变化 → 选择列表•如果需要哈希支持 → 必须用元组
八、性能对比
import sysimport timeit# 测试次数test_times = 5# 数据量data_size = 1000# 内存占用(固定,无需多次测试)t = tuple(range(data_size))l = list(range(data_size))print(f"元组内存占用:{sys.getsizeof(t)} 字节")print(f"列表内存占用:{sys.getsizeof(l)} 字节")# 创建速度:多次测试取平均值tuple_create_times = []list_create_times = []for _ in range(test_times): tuple_time = timeit.timeit(f'tuple(range({data_size}))', number=10000) list_time = timeit.timeit(f'list(range({data_size}))', number=10000) tuple_create_times.append(tuple_time) list_create_times.append(list_time)# 计算平均值avg_tuple_time = sum(tuple_create_times) / test_timesavg_list_time = sum(list_create_times) / test_timesprint(f"\n元组创建平均耗时:{avg_tuple_time:.6f} 秒")print(f"列表创建平均耗时:{avg_list_time:.6f} 秒")avg_tuple_time = timeit.timeit('(1,2,3,4,5,6,7,8,9,10)*100', number=10000)avg_list_time = timeit.timeit('[1,2,3,4,5,6,7,8,9,10]*100', number=10000)print(f"元组创建耗时:{avg_tuple_time:.6f}")print(f"列表创建耗时:{avg_list_time:.6f}")
Python 对列表的转换操作有更细致的底层优化,因此在该场景下列表创建略快,后面换成手动输入后,可以看出元组的创建速度更快
具体结果如下:
元组内存占用:8040 字节列表内存占用:8056 字节元组创建平均耗时:0.102996 秒列表创建平均耗时:0.085451 秒元组创建耗时:0.014062列表创建耗时:0.015652
我们之前强调的元组性能优势,核心是 元素访问速度(不可变序列内存布局更紧凑,解释器无需额外校验)和 内存占用效率(无冗余缓冲区),而非创建速度。创建速度的微小波动,不影响元组在只读场景下的性能优势。
九、最佳实践总结
1.单元素元组务必加逗号:(10,) 而非 (10)2.批量解包善用星号:first, *rest = data3.函数返回多值用元组:自动打包解包更优雅4.配置数据优先选元组:保证数据安全5.性能敏感场景用元组:内存占用小,访问快6.需要哈希时必须用元组:字典键、集合元素7.星号解包不能单独使用:*rest = (1,2,3) 会报错,必须搭配至少一个固定变量(first, *rest = (1,2,3) 合法);8.元组拼接 / 重复会生成新元组:原元组始终不变,频繁拼接大量数据时,建议先转为列表操作,再转回元组,提升性能;9.index() 方法查找不存在的元素会报错,若需安全查找,可先通过 in 判断元素是否存在,再调用 index()。
元组的核心价值在于不可变性带来的安全性、哈希性和性能优势。在实际开发中,明确数据是否需要修改是选择元组还是列表的关键判断依据。
记住:当你想要一个不可变的列表时,你需要的就是元组。