用Python实现复杂人物图片识别,这里的“复杂”通常包括人物姿态多变、背景干扰、多人共存、遮挡等场景。下面我将提供一套完整、可落地的实现方案,涵盖环境准备、核心技术选型、代码实现、功能扩展四个部分,优先选用成熟易用的开源工具,避免复杂的模型训练。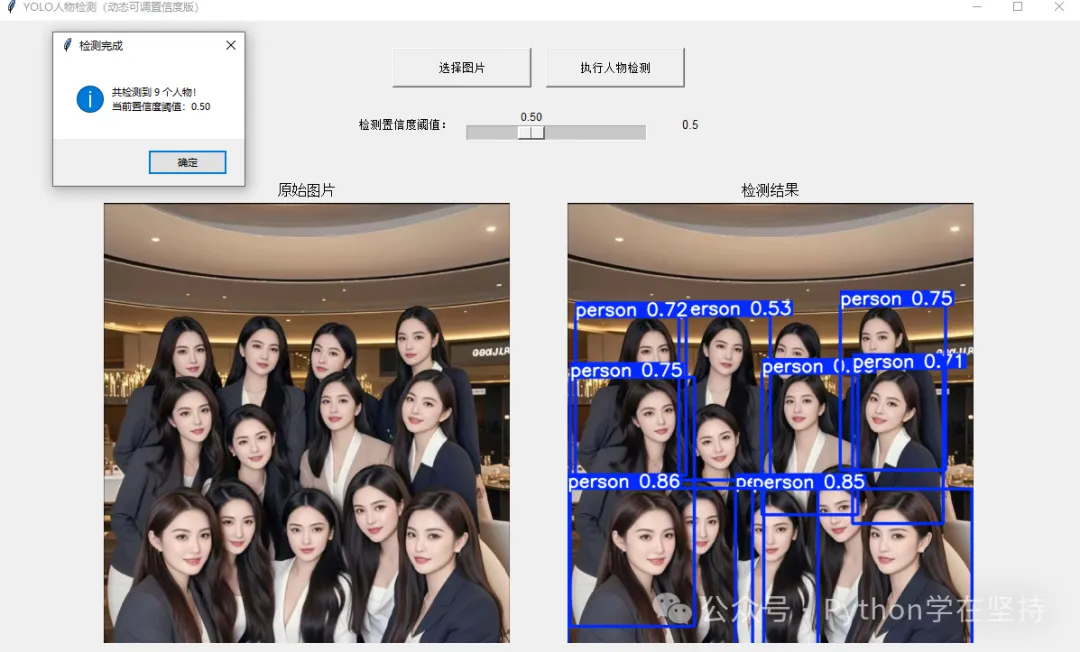
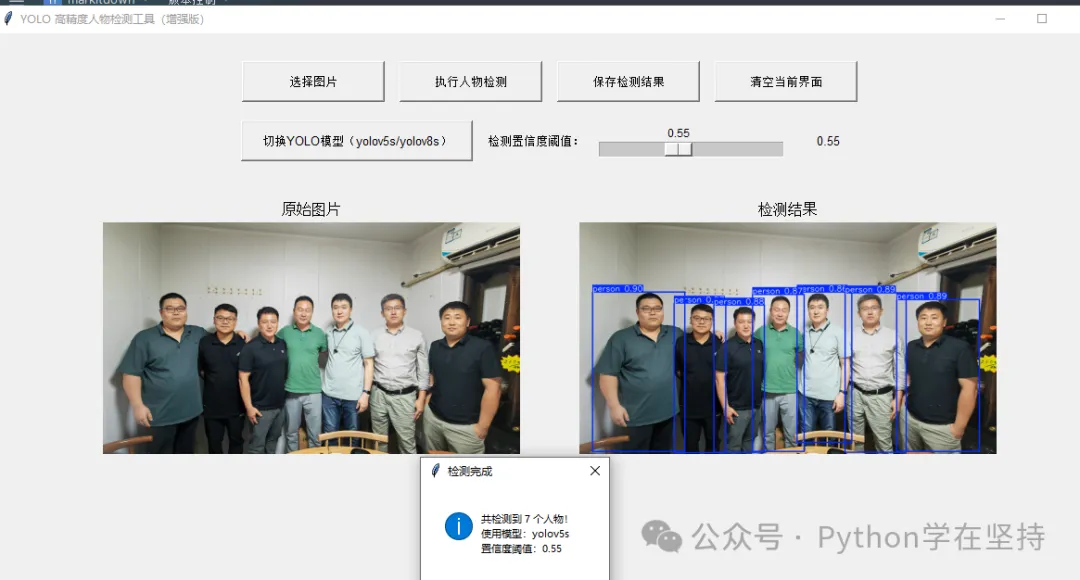 一、核心技术选型说明
一、核心技术选型说明
处理复杂人物图片识别,不建议从零搭建模型(成本高、效果差),优先选择以下成熟工具:
- OpenCV:用于图片预处理(降噪、裁剪、格式转换),是计算机视觉的基础工具。
- MediaPipe:Google开源的轻量级计算机视觉框架,专门优化了人物相关识别(检测、姿态、关键点),对复杂场景适应性强,支持图片/视频输入,且无需GPU即可快速运行。
- Pillow:辅助进行图片读写、格式转换和简单可视化。
其中,MediaPipe的Pose(人体姿态识别)、Face Detection(人脸检测)、Person Segmentation(人物分割)是处理复杂人物图片的核心工具,能够解决大部分复杂场景的人物识别需求。
二、环境准备
首先安装所需依赖库,打开终端执行以下命令:
# 核心依赖:OpenCV + MediaPipe + Pillowpip install opencv-python mediapipe pillow
三、完整代码实现(支持多场景人物识别)
下面实现一个综合的复杂人物图片识别脚本,支持人物检测、人体姿态关键点识别、人脸检测、人物分割四大核心功能,可直接运行。
完整代码
import cv2import mediapipe as mpfrom PIL import Imageimport numpy as npclassComplexPersonRecognizer:def__init__(self):# 初始化MediaPipe相关工具 self.mp_drawing = mp.solutions.drawing_utils # 绘图工具(用于可视化识别结果) self.mp_drawing_styles = mp.solutions.drawing_styles # 预设绘图样式# 1. 人体姿态识别(支持33个人体关键点,应对复杂姿态) self.mp_pose = mp.solutions.pose self.pose = self.mp_pose.Pose( static_image_mode=True, # 静态图片模式(针对单张图片优化) model_complexity=2, # 模型复杂度(0=轻量,1=中等,2=高精度,应对复杂场景选2) enable_segmentation=True, # 启用人物分割(分离人物与背景) min_detection_confidence=0.5# 最小检测置信度(过滤低精度结果) )# 2. 人脸检测(应对多人、部分遮挡场景) self.mp_face_detection = mp.solutions.face_detection self.face_detection = self.mp_face_detection.FaceDetection( model_selection=1, # 模型选择(0=近距离人脸,1=远距离/多人脸,应对复杂场景选1) min_detection_confidence=0.5 )defpreprocess_image(self, image_path):""" 图片预处理:读取、格式转换、降噪(应对复杂背景干扰) """# 1. 用OpenCV读取图片 img = cv2.imread(image_path)if img isNone:raise FileNotFoundError(f"无法读取图片:{image_path}")# 2. 降噪处理(高斯模糊,减少背景干扰) img_denoised = cv2.GaussianBlur(img, (5, 5), 0)# 3. 格式转换(OpenCV默认BGR,MediaPipe需要RGB) img_rgb = cv2.cvtColor(img_denoised, cv2.COLOR_BGR2RGB)# 4. 返回预处理后的图片(原始BGR用于后续保存,RGB用于模型推理)return img, img_rgbdefrecognize_person(self, image_path, output_path="output_person_recognized.jpg"):""" 核心识别函数:完成人物检测、姿态识别、人脸检测、人物分割 """# 步骤1:图片预处理 img_bgr, img_rgb = self.preprocess_image(image_path) img_height, img_width = img_bgr.shape[:2]# 步骤2:人体姿态识别与人物分割 pose_results = self.pose.process(img_rgb)if pose_results.pose_landmarks:# 绘制人体姿态关键点(33个)和连接线 self.mp_drawing.draw_landmarks( img_bgr, pose_results.pose_landmarks, self.mp_pose.POSE_CONNECTIONS, landmark_drawing_spec=self.mp_drawing_styles.get_default_pose_landmarks_style() )# 步骤3:人脸检测(标记人脸位置和关键区域) face_results = self.face_detection.process(img_rgb)if face_results.detections:for detection in face_results.detections:# 绘制人脸边界框 self.mp_drawing.draw_detection(img_bgr, detection)# 提取人脸置信度(可选,用于筛选高精度结果) confidence = detection.score[0] print(f"检测到人脸,置信度:{confidence:.4f}")# 步骤4:人物分割结果可视化(分离人物与背景,可选)if pose_results.segmentation_mask:# 生成分割掩码(黑白图,白色为人物) segmentation_mask = pose_results.segmentation_mask.numpy() segmentation_mask = (segmentation_mask * 255).astype(np.uint8)# 合并原始图片与分割掩码(突出显示人物) seg_img = cv2.addWeighted(img_bgr, 0.7, cv2.cvtColor(segmentation_mask, cv2.COLOR_GRAY2BGR), 0.3, 0)else: seg_img = img_bgr# 步骤5:保存识别结果图片 cv2.imwrite(output_path, seg_img) print(f"识别结果已保存至:{output_path}")# 步骤6:返回关键识别结果(可选,用于后续分析)return {"has_person": bool(pose_results.pose_landmarks),"has_face": bool(face_results.detections),"image_size": (img_width, img_height),"output_path": output_path }defrelease(self):"""释放资源""" self.pose.close() self.face_detection.close()# ---------------------- 测试运行 ----------------------if __name__ == "__main__":# 初始化人物识别器 person_recognizer = ComplexPersonRecognizer()# 待识别的复杂人物图片路径(替换为你的图片路径,支持jpg、png等格式) target_image_path = "complex_person.jpg"try:# 执行人物识别 recognition_result = person_recognizer.recognize_person( image_path=target_image_path, output_path="complex_person_result.jpg" ) print(f"识别总结:{recognition_result}")finally:# 释放资源 person_recognizer.release()
四、使用说明
- 准备测试图片:将待识别的复杂人物图片(支持多人、复杂姿态、背景干扰)命名为
complex_person.jpg,放在脚本同一目录下。 - 运行脚本:直接执行Python脚本,无需额外配置。
- 查看结果:脚本运行完成后,会在同一目录下生成
complex_person_result.jpg,包含: - 控制台输出:会打印人脸置信度和识别总结信息,便于筛选有效结果。
五、应对复杂场景的优化技巧
针对“复杂人物图片”的核心痛点,以下优化可进一步提升识别效果:
- 高复杂度模型选型:代码中
model_complexity=2(姿态识别)、model_selection=1(人脸检测)已针对复杂场景优化,无需修改,若追求速度可降低为1/0。 - 置信度阈值调高:将
min_detection_confidence从0.5调整为0.7~0.8,过滤模糊、遮挡严重的低精度结果。 - 图片增强预处理:对于过暗、过亮、模糊的图片,可增加以下预处理步骤:
# 自动调整亮度和对比度img_equalized = cv2.equalizeHist(cv2.cvtColor(img_denoised, cv2.COLOR_BGR2GRAY))img_rgb = cv2.cvtColor(img_equalized, cv2.COLOR_GRAY2RGB)
- 多人识别支持:MediaPipe天然支持多人检测,无需额外修改代码,可直接处理包含多个人物的图片。
- 遮挡场景适配:MediaPipe的姿态识别模型采用注意力机制,对肢体部分遮挡(如手持物品、人物重叠)有较好的鲁棒性。
六、进阶扩展方向
如果需要更复杂的人物识别功能(如人物身份识别、行为分析、性别年龄判断),可基于当前方案扩展:
- 人物身份识别:结合
dlib或FaceNet,在人脸检测基础上实现人脸特征提取与身份匹配。 - 行为/动作分析:基于33个人体姿态关键点,计算肢体角度(如弯腰、举手、跑步),实现行为分类。
- GPU加速:若处理大量图片/高清图片,可安装
mediapipe-gpu版本,开启GPU推理提升速度。 - 批量处理:循环遍历文件夹中的所有图片,实现批量人物识别与结果汇总。
总结
- 处理复杂人物图片识别,优先选用
OpenCV+MediaPipe的组合,成熟高效且无需手动训练模型。 - 核心流程为:图片预处理(降噪、格式转换)→ 模型推理(姿态/人脸/分割)→ 结果可视化与保存。
- 针对复杂场景的优化关键在于:高复杂度模型、合理置信度阈值、增强预处理,可有效提升遮挡、多人、复杂背景下的识别精度。
- 脚本可直接运行,替换图片路径即可快速得到识别结果,具备良好的可扩展性。

