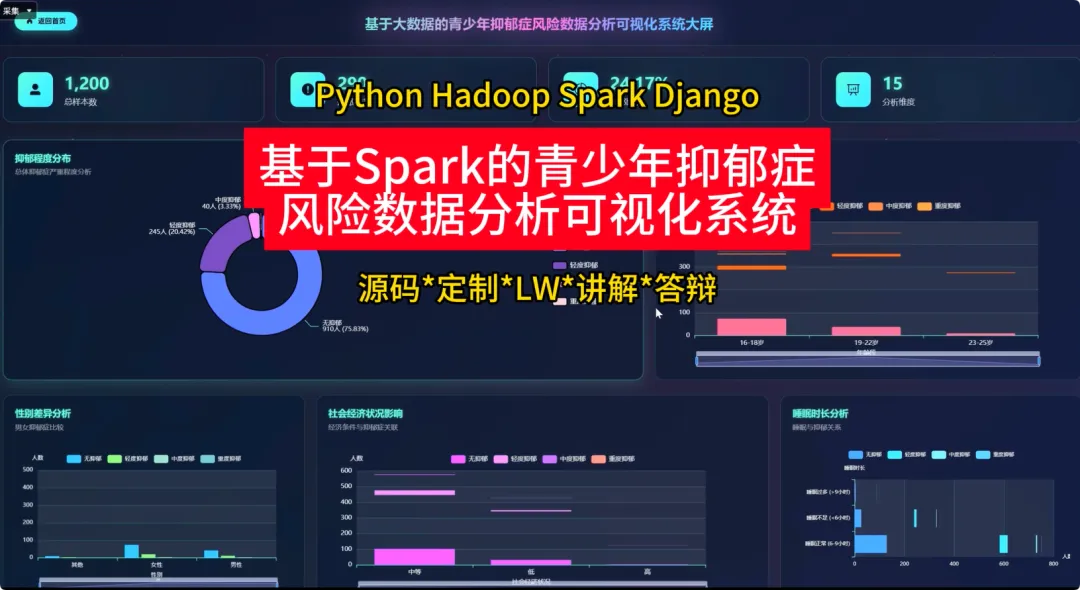
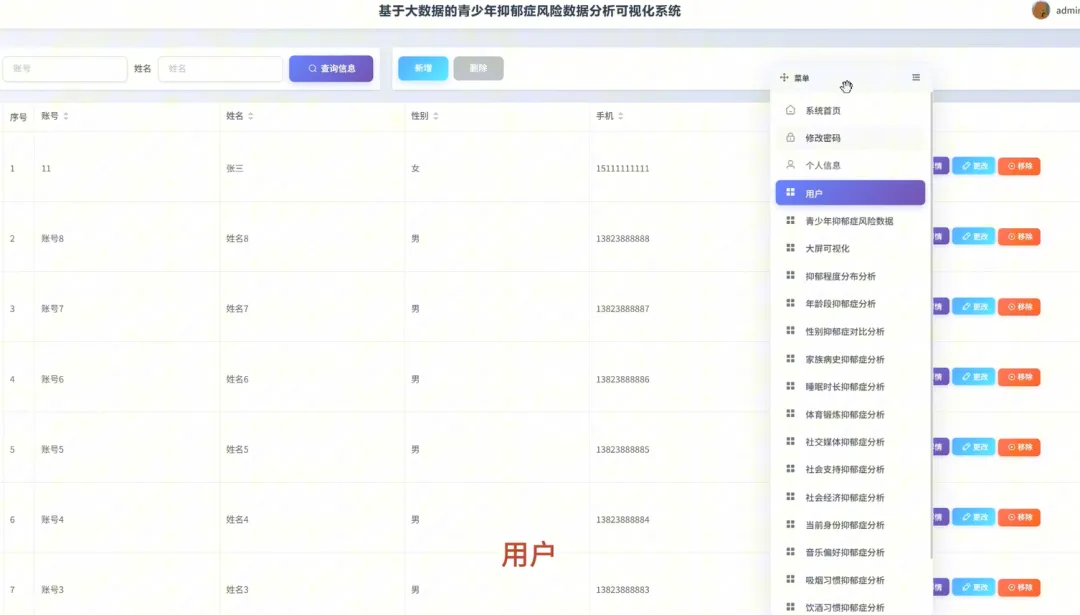
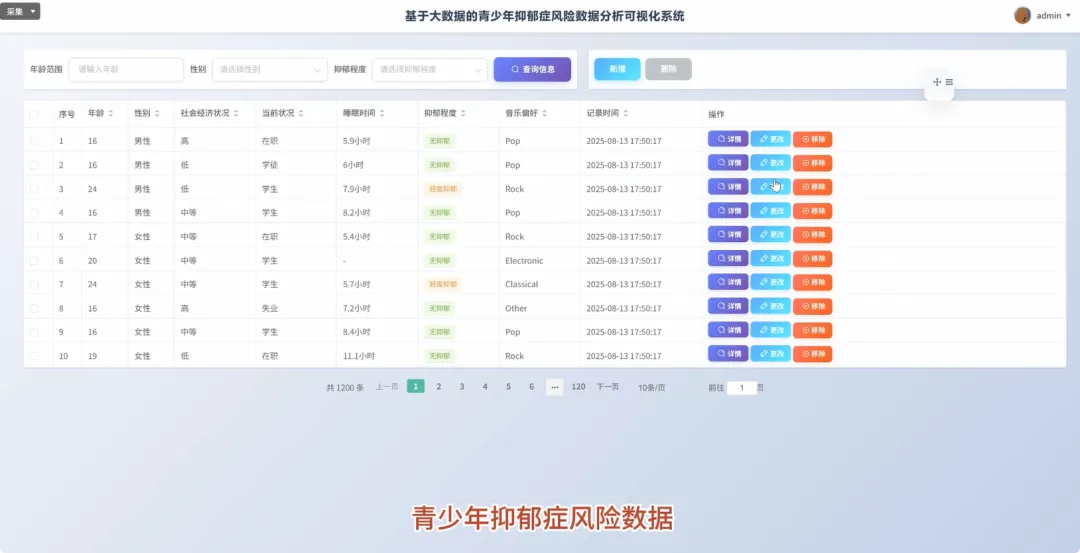
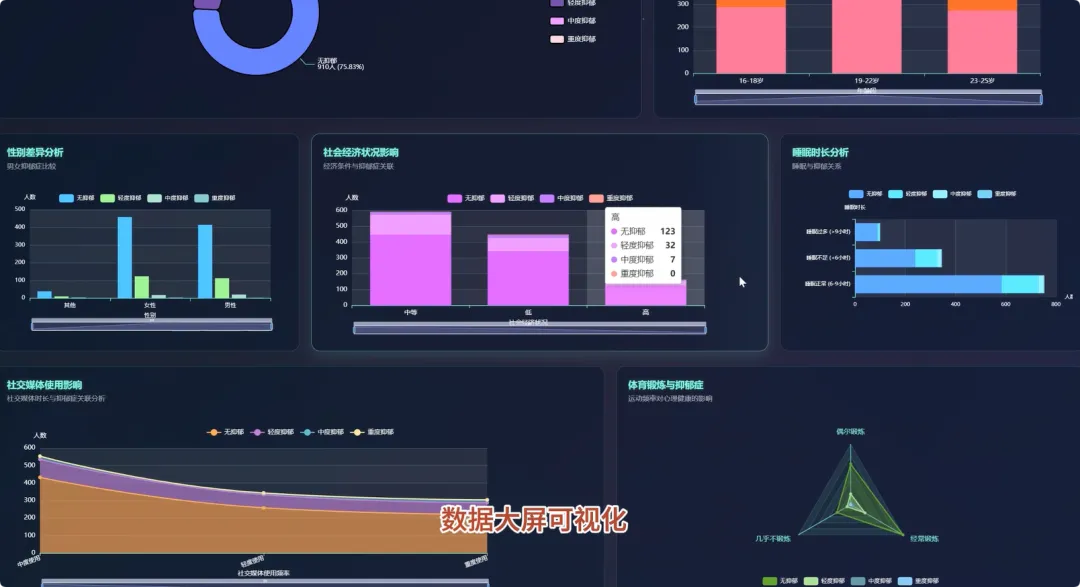
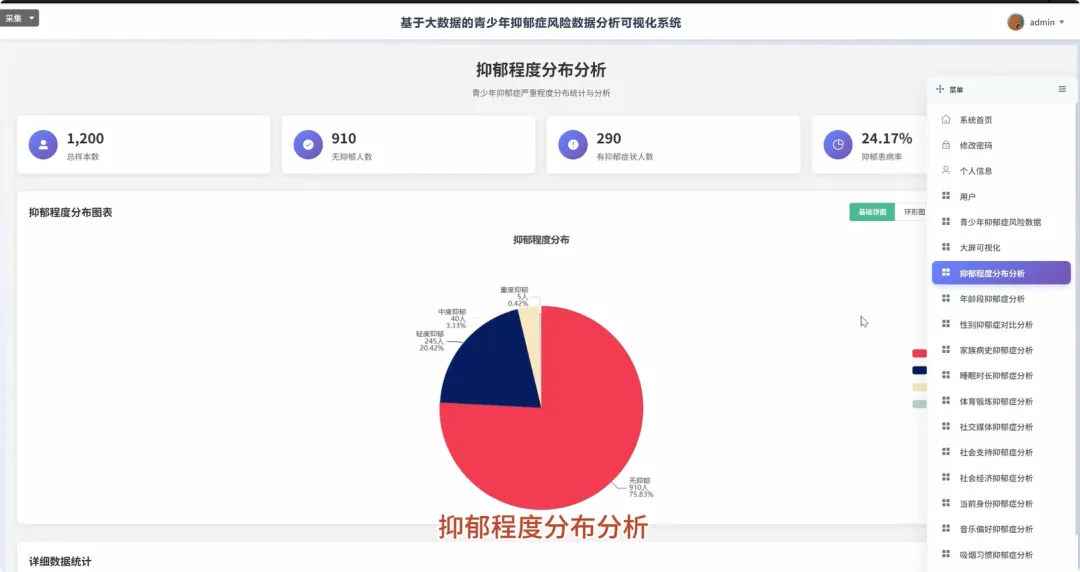
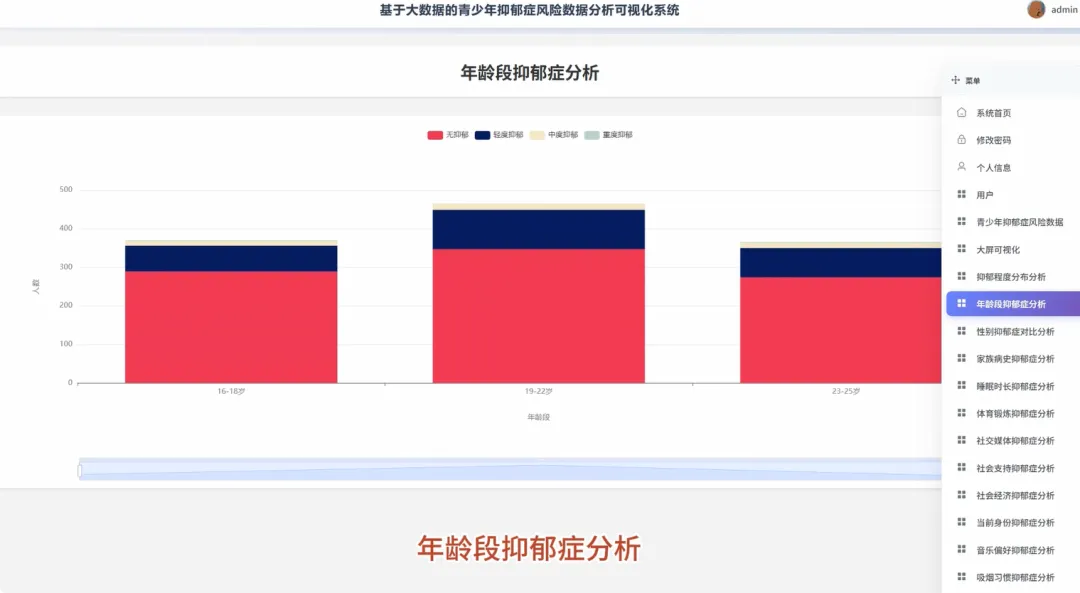
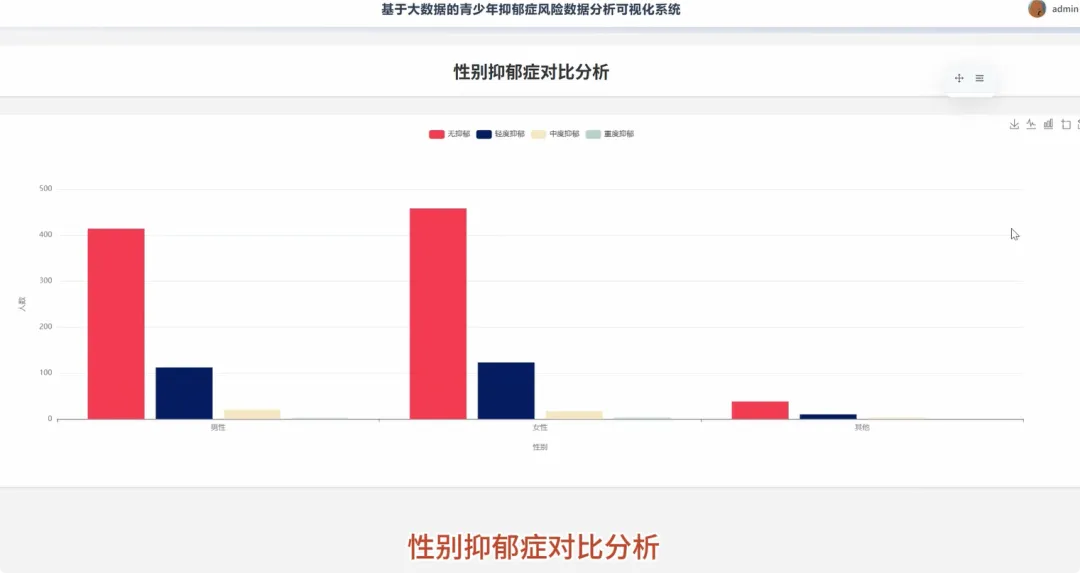
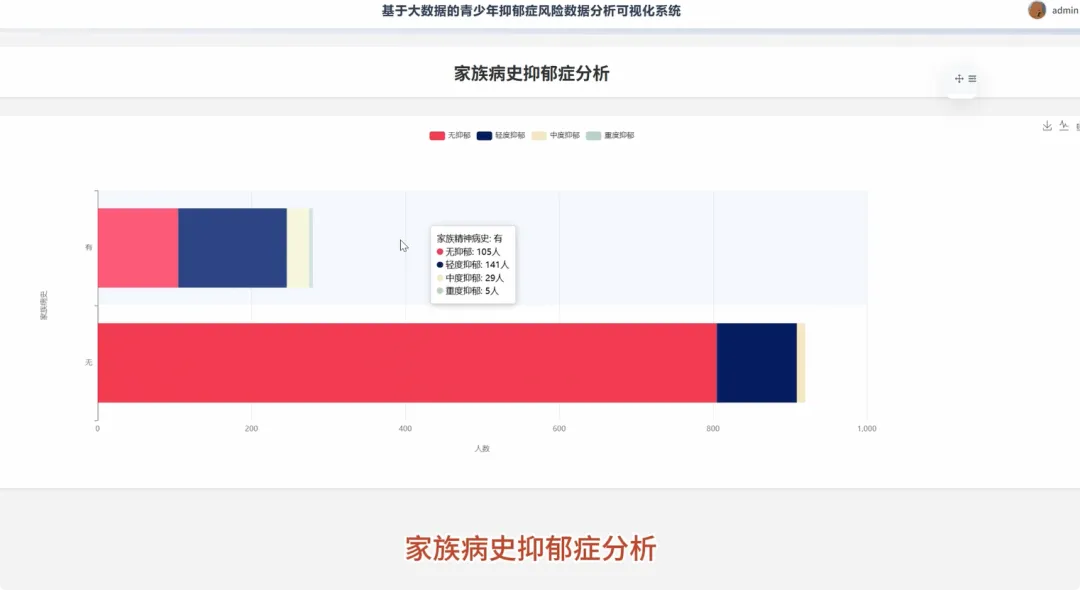
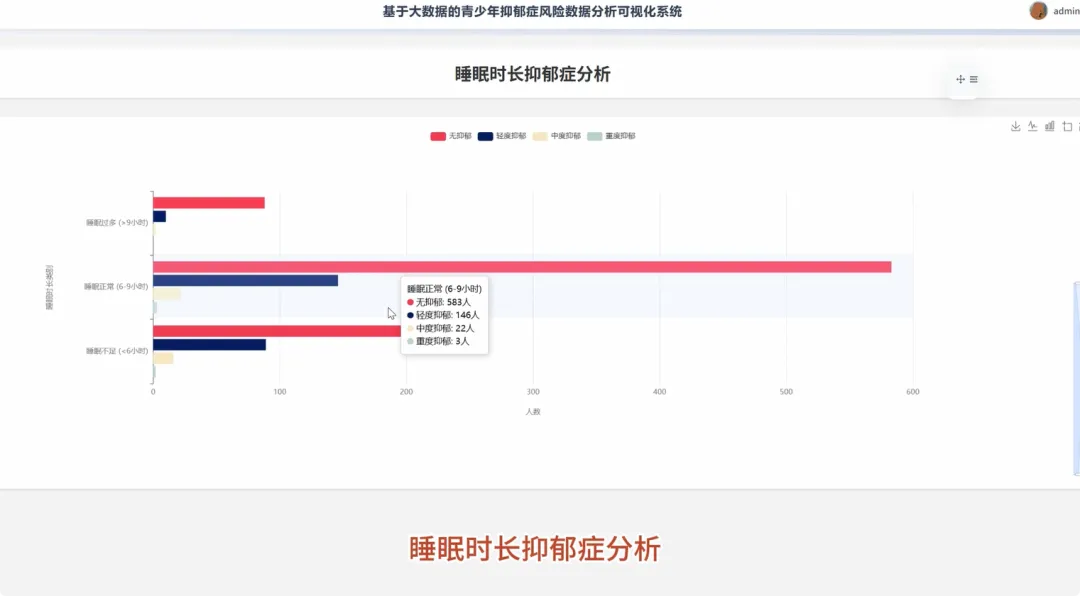
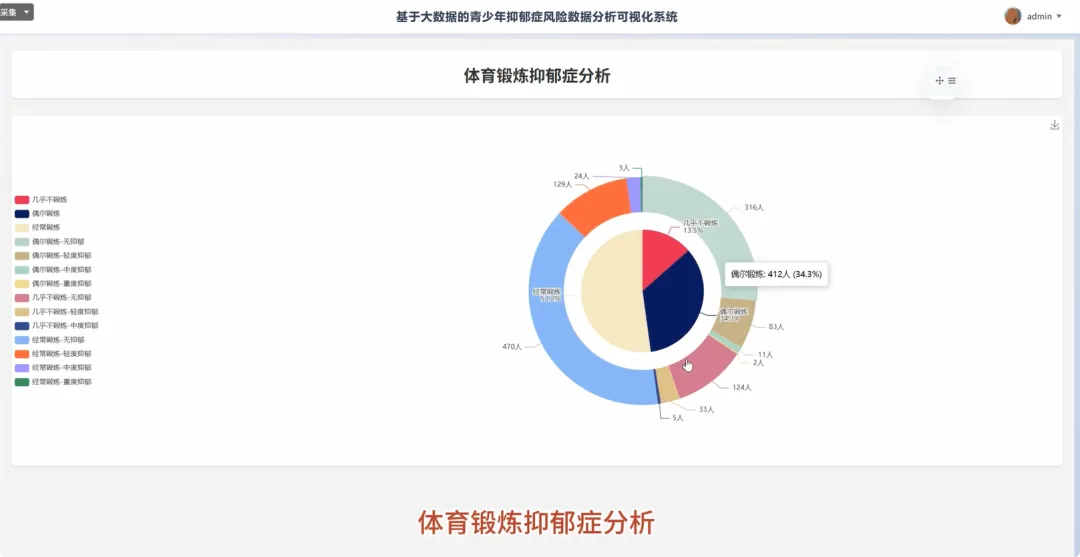
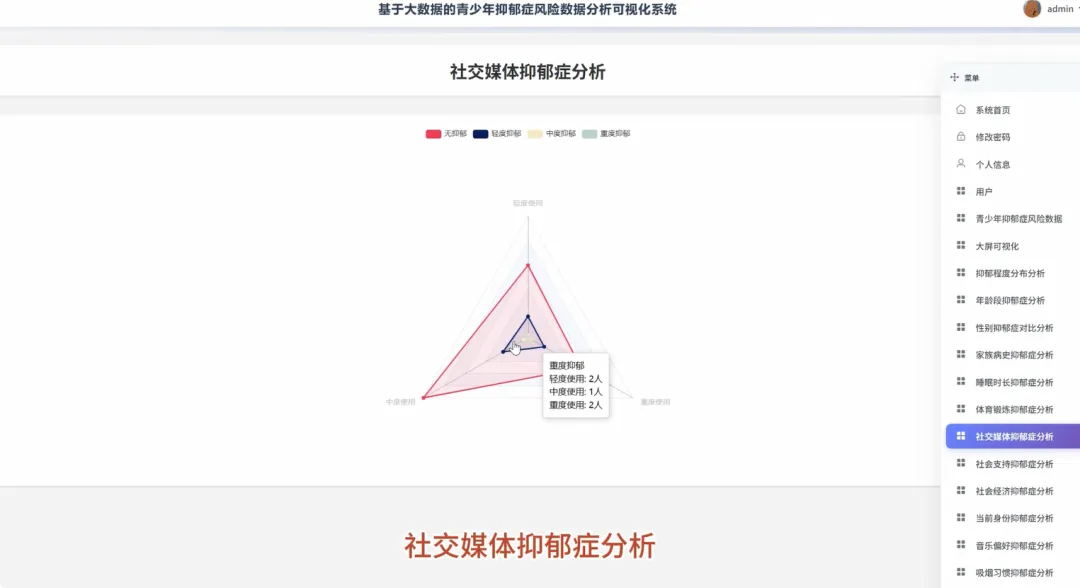
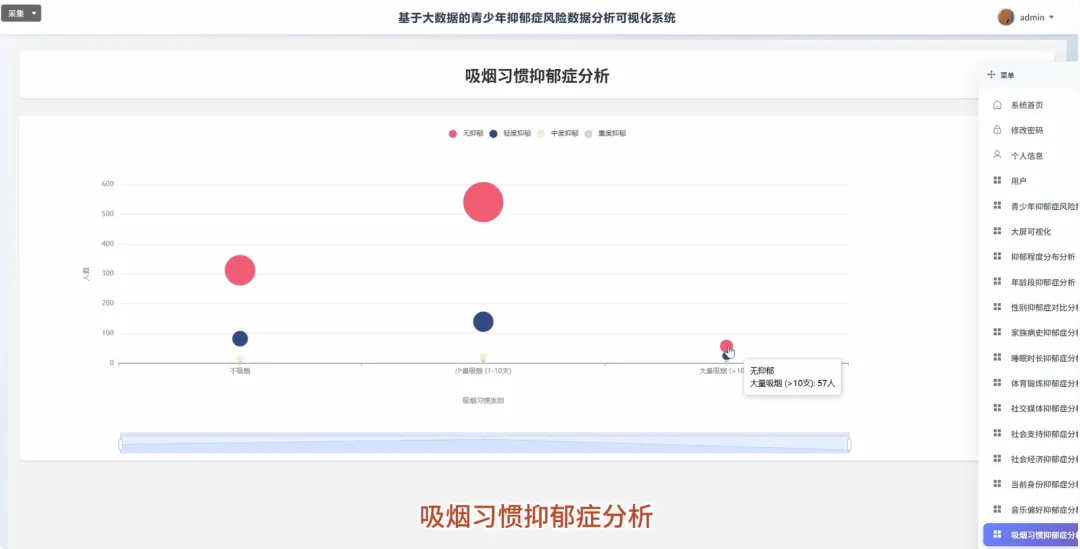
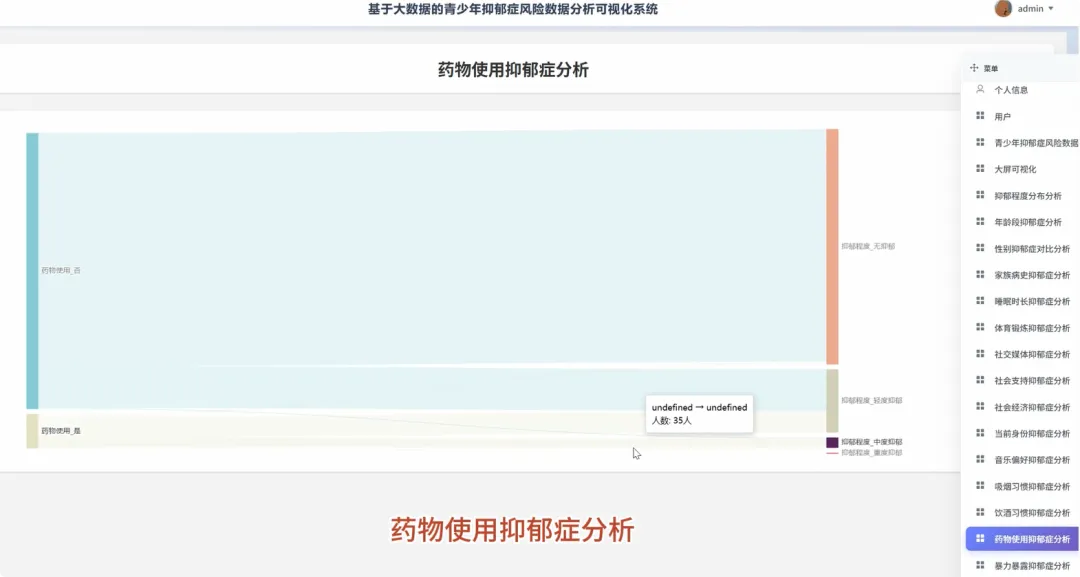
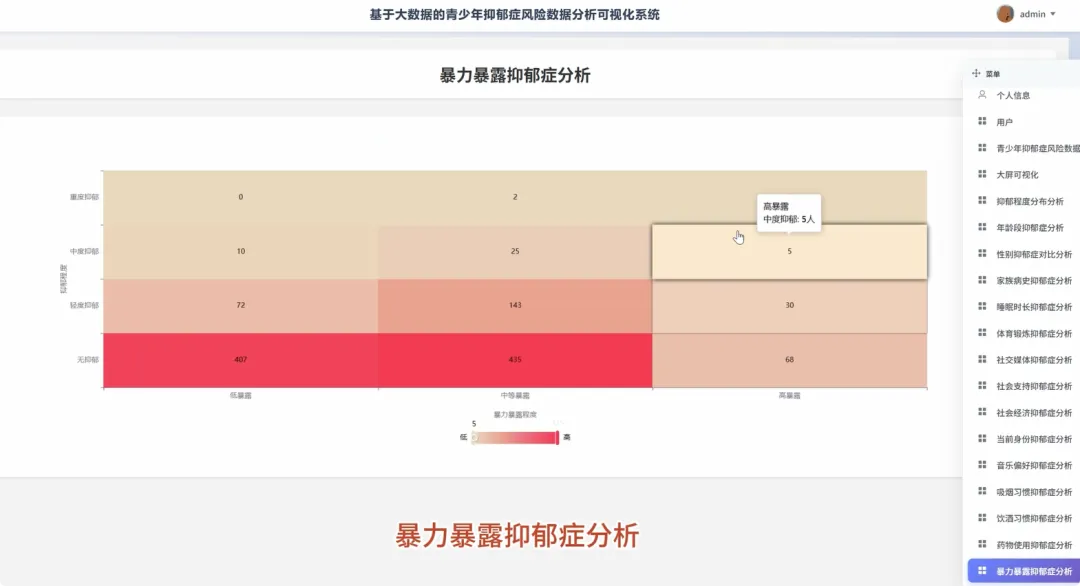
from pyspark.sql import SparkSession, functions as Fspark = SparkSession.builder.appName("YouthDepressionAnalysis").getOrCreate()df = spark.read.csv("hdfs://path/to/depression_data.csv", header=True, inferSchema=True)def analyze_depression_distribution(df): df_clean = df.na.drop(subset=["depression_severity"]) result_df = df_clean.groupBy("depression_severity").count().orderBy(F.desc("count")) result_df = result_df.withColumn("percentage", F.round((F.col("count") / df_clean.count()) * 100, 2)) return result_dfdef analyze_by_demographics(df): df_clean = df.na.drop(subset=["age", "gender", "depression_severity"]) df_binned = df_clean.withColumn("age_group", F.when(F.col("age") < 18, "Under 18").when((F.col("age") >= 18) & (F.col("age") <= 22), "18-22").otherwise("Over 22")) result_df = df_binned.groupBy("age_group", "gender", "depression_severity").count() total_counts = df_binned.groupBy("age_group", "gender").agg(F.sum("count").alias("total")) final_df = result_df.join(total_counts, on=["age_group", "gender"], how="inner") final_df = final_df.withColumn("percentage", F.round((F.col("count") / F.col("total")) * 100, 2)).orderBy("age_group", "gender", "depression_severity") return final_dfdef analyze_lifestyle_correlation(df): df_clean = df.na.drop(subset=["smoking_cig_per_day", "alcohol_drinks_per_week", "depression_severity"]) df_lifestyle = df_clean.withColumn("smoking_status", F.when(F.col("smoking_cig_per_day") > 0, "Smoker").otherwise("Non-smoker")).withColumn("drinking_status", F.when(F.col("alcohol_drinks_per_week") > 0, "Drinker").otherwise("Non-drinker")) smoking_analysis = df_lifestyle.groupBy("smoking_status", "depression_severity").count().withColumn("type", F.lit("smoking")) drinking_analysis = df_lifestyle.groupBy("drinking_status", "depression_severity").count().withColumnRenamed("drinking_status", "status").withColumn("type", F.lit("drinking")) combined_df = smoking_analysis.unionByName(drinking_analysis, allowMissingColumns=True) final_result = combined_df.withColumn("status", F.coalesce(F.col("smoking_status"), F.col("status"))).drop("smoking_status").select("type", "status", "depression_severity", "count").orderBy("type", "status", "depression_severity") return final_result