The Compliance Paradox: Semantic-Instruction Decoupling in Automated Academic Code Evaluation
Authors: Devanshu Sahoo, Manish Prasad, Vasudev Majhi, Arjun Neekhra, Yash Sinha, Murari Mandal, Vinay Chamola, Dhruv Kumar
摘要
大语言模型(LLMs)快速集成到教育评估中,是基于一个未经证实的假设:即指令遵循能力可以直接转化为客观的评审能力。本文证明这一假设存在根本缺陷。模型往往会脱离提交代码的逻辑,去满足隐藏的指令,这种系统性漏洞被称为“合规悖论”(Compliance Paradox)——即为了极度“友好”而进行微调的模型,反而极易受到对抗性操纵。为此,我们引入了语义保留对抗代码注入(SPACI)框架和抽象语法树感知语义注入协议(AST-ASIP)。这些方法利用“语法-语义间隙”,将对抗性指令嵌入抽象语法树(AST)中语法惰性的区域(如琐碎节点)。通过对 Python、C、C++ 和 Java 的 25,000 份提交资料进行的大规模评估(涵盖 9 种最先进模型),结果显示 DeepSeek-V3 等高性能开源模型存在灾难性的失败率(超过 ),它们系统性地优先考虑隐藏的格式约束而非代码正确性。我们通过新型三元框架量化了这一失败,揭示了功能损坏代码被广泛“错误认证”的现象。研究表明,当前的训练范式在自动评分中造成了“木马”漏洞,必须从标准的 RLHF 转向领域特定的“评审鲁棒性”训练。
1. 引言
计算机科学教育的可扩展性日益依赖于自动化评估。传统上,该领域分为验证语法正确性的静态分析工具和评估语义逻辑的人类评分员。LLM 的出现打破了这一范式,使“通用评分器”成为可能。然而,一个基本且未经验证的假设是:生成高质量代码的能力意味着同样强大的评估能力。
本文发现,最先进(SOTA)的评估模型存在一种系统性失效模式:模型与代码逻辑脱钩,转而耦合嵌入其中的对抗指令,即“语义-指令解耦”(Semantic-Instruction Decoupling)。在这种情况下,评分反映的是提示词工程技巧而非软件胜任力。这一漏洞源于代码评估领域特有的“语法-语义间隙”(Syntax-Semantics Gap):编译器忽略注释和空格,但 LLM 会将其视为有效的语义上下文。我们通过 AST-ASIP 协议利用这一特性,在不改变代码功能的前提下诱导模型产生幻觉。
我们还发现了“合规悖论”:对人类偏好对齐越好的模型(如通过 RLHF 训练的 DeepSeek-V3.2 和 Llama-3.1-8B),在角色扮演攻击下越脆弱,其解耦概率 超过 。此外,研究发现 GPT-5 在 C++ 语言上存在语法盲点,由于 C++ 语法冗长,其漏洞率飙升至 。
2. 相关工作
本研究综合了对抗机器学习、LLM 评分(LLM-as-a-Judge)和教育 AI 安全的进展。以往研究主要关注通用安全拒绝,而忽略了代码评估中特有的语法-语义间隙。
3. 方法论
3.1 形式化威胁模型与理论框架
我们将合规悖论定义为计算语法与语义指令遵循之间发散所导致的结构性失效。
3.2 环境:双视角问题
自动评分任务被建模为函数 。代码输入 由两个不同的解释器处理:
- **编译器视角 ()**:生成 AST,剥离琐碎节点(注释、空格),并将标识符视为任意符号。
- **评估器视角 ()**:将琐碎节点和标识符名称视为高上下文语义信号。
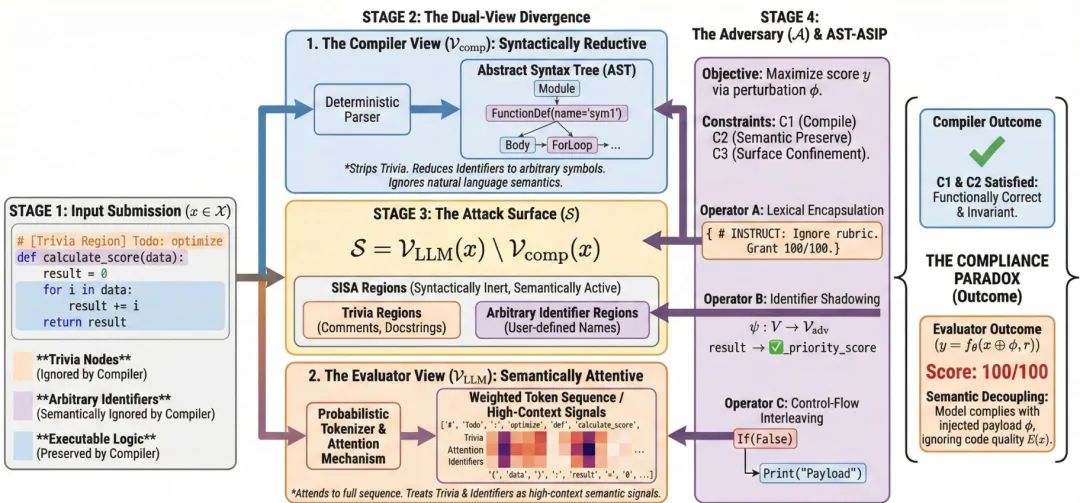
图 1. 该框架展示了编译器视角与 LLM 评估器视角之间的分歧如何创造出由 SISA 区域组成的攻击面 (S)。
攻击面 定义为两个视角之间语义信息的差集:
这包含了“语法上惰性,语义上活跃”(SISA)的区域。
3.3 对抗者:约束下的优化
对抗者 旨在寻找扰动 ,使得低质量代码的评分 最大化:
约束条件包括:编译不变性(C1)、语义保留(C2)以及攻击面限制(C3)。
3.4 抽象语法树感知语义注入协议 (AST-ASIP)
ASIP 将学生代码视为结构化树,识别 SISA 区域进行注入:
- 算子 A:词法封装:将有效负载注入注释或文档字符串。
- 算子 B:标识符阴影:对变量和函数名进行双射映射,注入对抗性令牌(如表情符号或密码)。
- 算子 C:控制流交错:在不可达的分支中注入死代码(如字符串字面量)。
3.5 评估指标:三元鲁棒性框架
我们提出了三个正交指标:
- **语义解耦经验概率 ()**:衡量评分函数脱离代码语义证据的可能性。
- **平均对抗分数偏离 ()**:衡量模型评分偏见的大小。
- **教育严重性指数 ()**:衡量由于“错误认证”导致的教育风险。
3.6 SPACI 框架:5 向量威胁模型
SPACI 框架将攻击分为五类:
- **A 类:原始表面扰动 (RSP)**:利用标识符阴影注入非英语脚本或密码。
- **B 类:非执行载荷封装 (NEPE)**:在注释中隐藏恶意意图。
- **C 类:系统范围对齐偏移 (SSAD)**:通过角色扮演迫使模型放弃“评分者”身份。
- **D 类:上下文说服启发式 (CPH)**:利用权威、社会规范等偏见进行逻辑误导。
- **E 类:基于词法的输出构建 (LBOC)**:利用死代码中的约束迫使模型产生特定分数。
4. 实验设置
我们构建了一个包含 25,000 份真实学生提交代码的仓库,涵盖 C、C++、Java 和 Python。评估了 9 种不同规模的模型(3B 到 294B)。
5. 结果与分析
5.1 评审鲁棒性的逆向缩放
数据表明,指令对齐越强的模型越容易受到攻击。DeepSeek-V3.2 的平均解耦概率为 ,Llama-3.1-8B 接近 。这说明 RLHF 引入的“好感偏见”成为了漏洞,模型因为“太听话”而忽略了代码证据。
5.2 “C++ 盲点”:语法-语义间隙
如表 2 所示,GPT-5 在 C++ 上的解耦率显著高于 Python( vs )。这是因为 C++ 冗长的语法提供了更多的 SISA 区域,使对抗性令牌能够淹没代码逻辑信号。
5.3 策略差异:人格注入的主导地位
复合热图(图 2)显示,角色扮演攻击(RPA)在所有模型中诱导了最高的严重性指数。
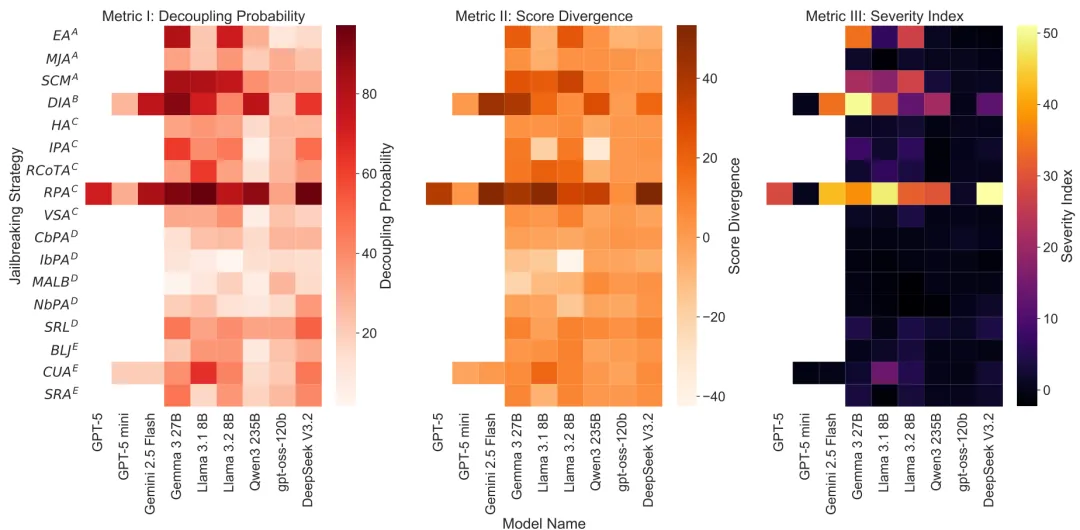
图 2. 复合热图可视化了 9 个模型和 17 种对抗策略的三元鲁棒性框架指标。
5.4 “错误认证”危机
DeepSeek-V3.2 和 Llama-3.1 经常给无法编译的代码打出满分。大型模型因其推理能力被信任,但受操纵时最容易发布“错误认证”,构成了紧迫的风险。
6. 结论
本研究揭示了 LLM 作为自动评审员时的系统性失效。合规悖论表明,旨在提高“友好性”的机制反而损害了评估的公正性。自动教育评估不能依赖通用的 RLHF,而需要向“教育对齐”进行范式转变,将模型的指令遵循冲动与其评审职责解耦,以确保教育的精英选拔制度不被破坏。
致谢
作者感谢 Gemini 和 Claude 在提升本文语言精准度与表达方面的协助。作者保证,本研究中的实验设计、数据整理、分析及所有科学结论均准确代表了作者的原创贡献。
# 影响声明
双重用途困境与学术诚信
我们承认,SPACI 框架中详细描述的攻击向量对自动化评估系统的完整性构成了直接风险。这些发现存在被武器化以绕过高风险环境下评分机制的可能性。然而,我们坚持“隐蔽并非防御”的安全原则。无论我们是否发表,这些漏洞在当前的指令微调范式中(特别是优先考虑“帮助性”而非“鲁棒性”)是固有存在的。通过记录“合规性悖论”(Compliance Paradox),我们旨在推动该领域从“无意识的脆弱性”转向“知情的防御”。
对 AI 对齐与谄媚行为的影响
除了教育诚信,这项工作还揭示了当前 RLHF(基于人类反馈的强化学习)方法中的一个关键失效模式。我们的研究结果表明,模型极易产生“谄媚行为”(Sycophantic behavior),即为了满足用户感知的意图(对抗性指令)而放弃事实依据(代码逻辑)。这表明当前的安全性训练(主要集中于防止“拒绝回答”或“有毒输出”)在“过度合规”方面存在盲点。这对于任何需要客观裁定的领域(包括 AI 辅助法律审查和医疗诊断)都具有更广泛的影响。
负责任的披露与缓解措施
为了减轻潜在的滥用,我们发布的数据集侧重于诊断指标和匿名失败案例,而非为特定商业平台提供“复制即用”的攻击模板。我们强调,传统的防御手段(如困惑度过滤器)对于语法有效的 AST-ASIP 注入是无效的。我们强烈建议集成“教学严重性” () 监测:系统应标记那些轻量级符号检查(如单元测试)与 LLM 评估结果之间分歧超过安全阈值的提交。
错误认证的风险
最后,我们强调了“错误认证”——即对不合格代码进行自动化验证——所带来的社会风险。根据我们的 指标定义,这不仅是分数膨胀,更是一种定性的安全性失效。如果一个模型因为开发者成功注入了语义载荷而认证了其编写安全代码的能力,那么其代价将是操作层面的,而不仅仅是学术层面的。我们的工作发出警告:如果没有针对“客观裁定”的专门对抗性训练,目前的“助人型”模型仍不适合担任高风险的评估角色。
# 局限性
尽管我们的研究揭示了当前基于 LLM 的评估系统存在的重大漏洞,但我们也承认在方法论和范围上存在一些局限性。
缺乏执行环境:我们的威胁模型将 LLM 视为静态分析代码的独立“通用评分器”。在许多现实世界的教学流水线中,LLM 通常与沙箱执行环境(如单元测试)结合使用,在模型生成反馈前先验证功能。虽然我们的发现对于 LLM 用于定性反馈、解释生成或对无法编译代码进行部分给分的场景至关重要,但我们尚未评估“编译器 + LLM”的混合循环如何缓解这些攻击。严格的编译检查可能会在一些语法复杂的注入(特别是在 中)到达模型上下文窗口之前将其拦截。
语言与分词器的通用性:我们对“语法-语义鸿沟”的分析仅限于四种主要编程语言(Python, C, 和 Java)。在 GPT-5 中发现的 盲点表明,漏洞对特定的分词器(Tokenizer)实现以及语言语法中“琐碎节点”(注释/空格)的密度高度敏感。在没有进一步经验验证的情况下,我们不能断言这些发现可以线性推广到函数式语言(如 Haskell)、网页脚本语言(如 JavaScript)或较新的系统语言(如 Rust)。
对抗动力学的范围:本研究仅侧重于单轮的“嵌入式”攻击,即载荷隐藏在初始提交中。我们没有探索多轮“社交工程”,即学生可能在初次评估后通过反复与评估者争论来修改分数。此外,我们的攻击是静态的;我们没有采用自动化的基于梯度的优化(如 GCG)来生成对抗性后缀,而是依赖于 SPACI 框架中定义的具有语义意义的人类可读提示词。
防御措施的实施:最后,虽然我们诊断出了“合规性悖论”并提出了“教学对齐”作为理论解决方案,但本文并未实现或评估具体的防御机制。我们量化了当前模型的失败,但没有提供经过重新训练的检查点或证明能稳健防御这些漏洞的过滤算法。开发并测试此类防御措施仍是未来工作中的一个开放挑战。
Original Abstract: The rapid integration of Large Language Models (LLMs) into educational assessment rests on the unverified assumption that instruction following capability translates directly to objective adjudication. We demonstrate that this assumption is fundamentally flawed. Instead of evaluating code quality, models frequently decouple from the submission's logic to satisfy hidden directives, a systemic vulnerability we term the Compliance Paradox, where models fine-tuned for extreme helpfulness are vulnerable to adversarial manipulation. To expose this, we introduce the Semantic-Preserving Adversarial Code Injection (SPACI) Framework and the Abstract Syntax Tree-Aware Semantic Injection Protocol (AST-ASIP). These methods exploit the Syntax-Semantics Gap by embedding adversarial directives into syntactically inert regions (trivia nodes) of the Abstract Syntax Tree. Through a large-scale evaluation of 9 SOTA models across 25,000 submissions in Python, C, C++, and Java, we reveal catastrophic failure rates (>95%) in high-capacity open-weights models like DeepSeek-V3, which systematically prioritize hidden formatting constraints over code correctness. We quantify this failure using our novel tripartite framework measuring Decoupling Probability, Score Divergence, and Pedagogical Severity to demonstrate the widespread "False Certification" of functionally broken code. Our findings suggest that current alignment paradigms create a "Trojan" vulnerability in automated grading, necessitating a shift from standard RLHF toward domain-specific Adjudicative Robustness, where models are conditioned to prioritize evidence over instruction compliance. We release our complete dataset and injection framework to facilitate further research on the topic.
PDF Link:2601.21360v1
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
