在2026年的数据驱动时代,掌握数据分析技能已成为技术从业者的必备能力。然而,许多开发者在实际项目中经常遇到两大难题:中文乱码问题和数据分析流程的不完整性。
本文将介绍一套完整的图书数据分析解决方案,它不仅解决了跨平台中文显示问题,还实现了从数据读取到可视化报告的全流程自动化。
一、中文乱码的终极解决方案
1.1 跨平台字体自动适配
中文乱码是Python数据可视化中最常见的问题之一。传统解决方案通常只针对特定操作系统,缺乏通用性。本方案通过platform.system()自动检测操作系统,并设置相应的中文字体:
defsetup_chinese_font():
plt.rcParams['axes.unicode_minus'] = False
system = platform.system()
if system == 'Windows':
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial']
elif system == 'Darwin': # macOS
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'PingFang TC', 'Heiti TC']
elif system == 'Linux':
plt.rcParams['font.sans-serif'] = ['DejaVu Sans', 'WenQuanYi Micro Hei', 'Noto Sans CJK SC']
return system
1.2 关键技术要点
- axes.unicode_minus参数:解决负号显示为方框的问题
- 图表样式继承:将中文字体设置传递给seaborn样式
二、数据读取与编码处理
2.1 智能编码检测
处理CSV文件时,编码问题经常导致数据读取失败。本方案实现了多重编码尝试机制:
defload_and_explore_data(csv_file='cleaned_book_data_utf8.csv'):
encodings = ['utf-8-sig', 'utf-8', 'gbk', 'gb2312', 'gb18030']
df = None
for encoding in encodings:
try:
df = pd.read_csv(csv_file, encoding=encoding)
break
except UnicodeDecodeError:
continue
2.2 数据完整性检查
在读取数据后,进行全面的数据质量检查:
print(f"数据集形状: {df.shape}")
print(f"行数(图书数量): {df.shape[0]}, 列数(特征数量): {df.shape[1]}")
print("\n缺失值统计:")
missing_data = df.isnull().sum()
print(missing_data[missing_data > 0])
三、数据清洗与特征工程
3.1 异常值检测与处理
采用IQR(四分位距)方法识别和处理异常值:
# 价格异常值检测
Q1_price = df['价格'].quantile(0.25)
Q3_price = df['价格'].quantile(0.75)
IQR_price = Q3_price - Q1_price
price_outliers = df[(df['价格'] < Q1_price - 1.5 * IQR_price) |
(df['价格'] > Q3_price + 1.5 * IQR_price)]
3.2 特征创建与数据离散化
通过特征工程增强数据分析维度:
# 价格区间划分
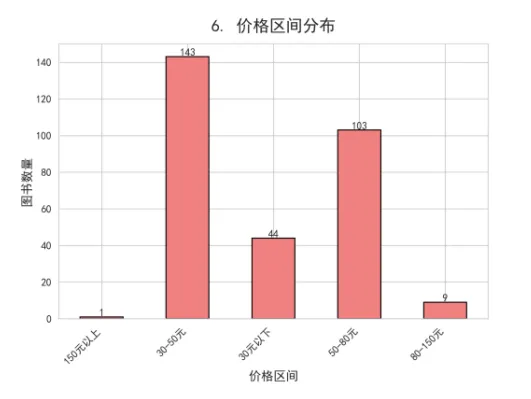
df['价格区间'] = pd.cut(df['价格'],
bins=[0, 30, 50, 80, 150, 1000],
labels=['30元以下', '30-50元', '50-80元', '80-150元', '150元以上'])
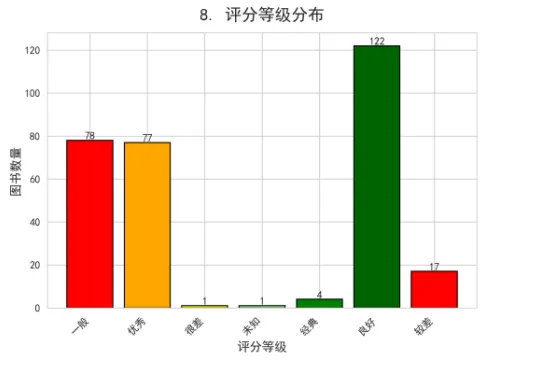
# 评分等级分类
df['评分等级'] = pd.cut(df['评分'],
bins=[0, 4, 6, 7, 8, 9, 10],
labels=['很差', '较差', '一般', '良好', '优秀', '经典'])
# 评论热度分级
df['评论热度'] = pd.cut(df['评论数'],
bins=[-1, 100, 1000, 10000, float('inf')],
labels=['冷门', '一般', '热门', '爆款'])
四、多维度数据分析
4.1 描述性统计分析
实现全面的数据统计描述:
defanalyze_book_data(df):
# 基本统计
print(f"图书总数: {len(df):,} 本")
print(f"唯一作者数: {df['作者'].nunique()} 位")
print(f"出版社数量: {df['出版社'].nunique()} 家")
# 价格分析
price_stats = df['价格'].describe()
print(f"平均价格: ¥{price_stats['mean']:.2f}")
print(f"价格中位数: ¥{price_stats['50%']:.2f}")
# 评分分析
rating_stats = df['评分'].describe()
print(f"平均评分: {rating_stats['mean']:.1f}/10")
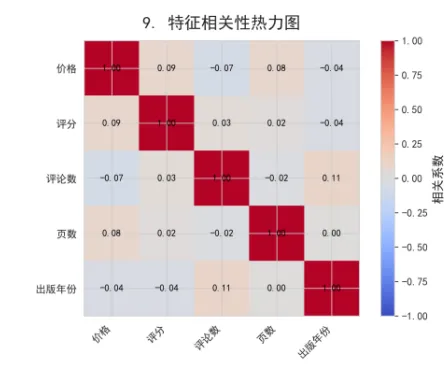
4.2 相关性分析
探索各特征间的相互关系:
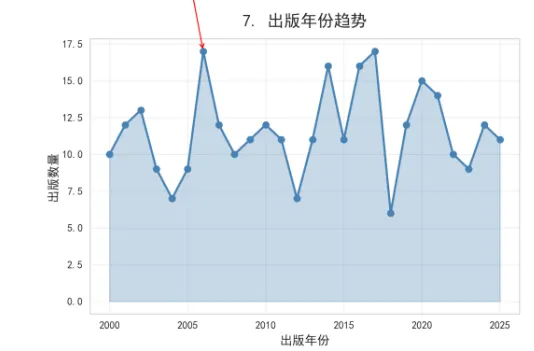
numeric_cols = ['价格', '评分', '评论数', '页数', '出版年份']
correlation = df[numeric_cols].corr()
print("价格与其他因素的相关性:")
for col in numeric_cols:
if col != '价格':
print(f" 价格 vs {col}: {correlation.loc['价格', col]:.3f}")
五、综合数据可视化
5.1 九宫格图表布局
创建包含9个子图的综合可视化报告:
fig = plt.figure(figsize=(20, 16))
fig.suptitle('图书数据分析可视化报告', fontsize=24, fontweight='bold', y=1.02)
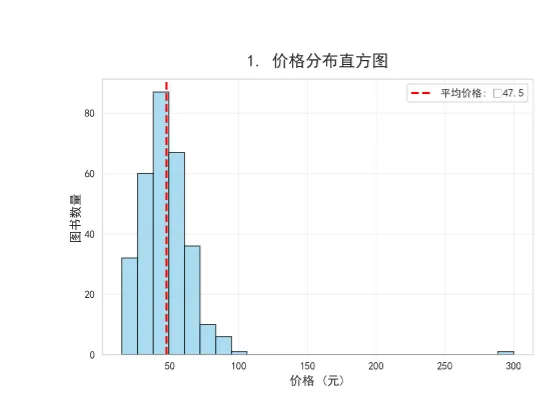
# 1. 价格分布直方图
ax1 = plt.subplot(3, 3, 1)
n, bins, patches = ax1.hist(df['价格'], bins=25, edgecolor='black',
alpha=0.7, color='skyblue')
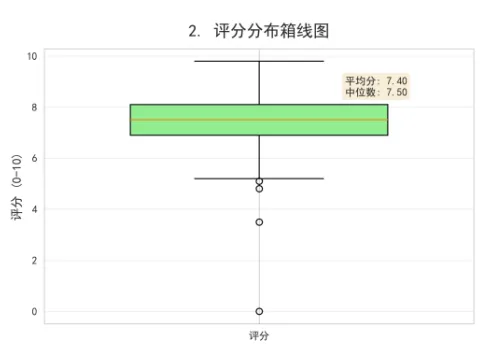
# 2. 评分分布箱线图
ax2 = plt.subplot(3, 3, 2)
box_data = [df['评分'].values]
box = ax2.boxplot(box_data, patch_artist=True, widths=0.6)
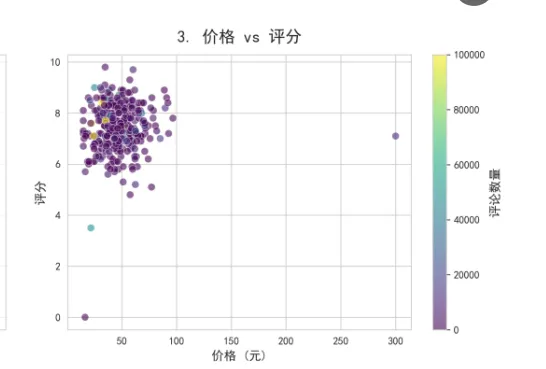
# 3. 价格与评分散点图
ax3 = plt.subplot(3, 3, 3)
scatter = ax3.scatter(df['价格'], df['评分'],
c=df['评论数'], cmap='viridis',
alpha=0.6, s=50, edgecolors='w', linewidth=0.5)
# ... 其他6个子图
5.2 可视化设计原则
- 色彩编码:使用viridis色系表示评论热度,符合数据特性
六、高级分析与业务洞察
6.1 性价比分析
识别高价值投资机会:
df['性价比'] = df['评分'] / df['价格']
top_value_books = df.nlargest(10, '性价比')[['书名', '作者', '价格', '评分', '性价比', '评论数']]
6.2 隐藏宝石发现
寻找高评分低热度的潜力作品:
hidden_gems = df[(df['评分'] >= 8.0) & (df['评论数'] < 1000)].nlargest(5, '评分')
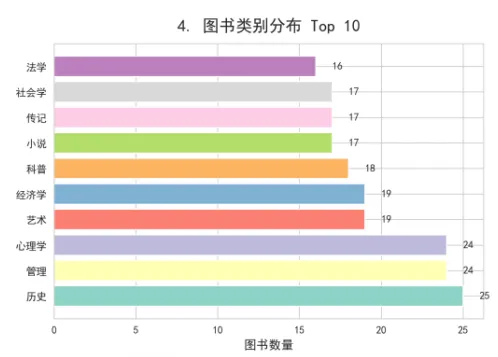
6.3 类别对比分析
category_stats = df.groupby('类别').agg({
'价格': ['mean', 'median', 'count'],
'评分': 'mean',
'评论数': 'mean'
}).round(2)
6.4 作者生产力分析
# 处理多位作者的情况
all_authors = []
for authors in df['作者']:
if'、'in authors:
all_authors.extend(authors.split('、'))
else:
all_authors.append(authors)
author_counts = Counter(all_authors)
top_authors = author_counts.most_common(10)
七、鲁棒性设计与错误处理
7.1 防御性编程
代码中大量使用条件检查,确保在数据列缺失时仍能正常运行:
if'价格'in df.columns:
price_stats = df['价格'].describe()
print(f"平均价格: ¥{price_stats['mean']:.2f}")
if'评分'in df.columns and'价格'in df.columns:
df['性价比指数'] = df['评分'] / df['价格'] * 10
7.2 全面的错误处理
try:
df = load_and_explore_data(csv_file)
except FileNotFoundError as e:
print(f"文件错误: {e}")
print("请确保CSV文件存在于当前目录")
except Exception as e:
print(f"其他错误: {e}")
import traceback
traceback.print_exc()
八、结果输出与报告生成
8.1 多格式输出
# 保存清洗后的数据
df_clean.to_csv('processed_book_data.csv', index=False, encoding='utf-8-sig')
# 保存可视化图表
plt.savefig('book_analysis_report.png', dpi=300, bbox_inches='tight')
# 保存文本摘要
with open('analysis_summary.txt', 'w', encoding='utf-8') as f:
f.write(f"分析时间: {pd.Timestamp.now()}\n")
f.write(f"分析图书数量: {len(df_clean)}\n")
8.2 Excel兼容性
使用UTF-8 with BOM编码确保CSV文件在Excel中正常打开:
df_clean.to_csv('processed_book_data.csv', index=False, encoding='utf-8-sig')
九、使用与扩展
9.1 基本使用
# 运行完整分析流程
df_result, analysis, advanced = main('your_data.csv')
9.2 自定义扩展
十、技术总结
10.1 核心技术栈
- matplotlib/seaborn:可视化工具,解决中文显示问题
10.2 设计模式
10.3 最佳实践
- 优先解决环境问题:在数据分析开始前确保中文显示正常
本文介绍的数据分析解决方案不仅解决了中文乱码这一技术难题,更重要的是提供了一个完整、可复用的分析框架。在2026年,数据分析能力正从专业技能转变为通用技能。掌握这样一套从数据读取到报告生成的完整流程,将使开发者在数据驱动的决策中占据优势。
代码的完整性和鲁棒性设计确保了其在实际项目中的可用性,而模块化的架构则为个性化定制提供了便利。无论是数据分析初学者,还是需要快速搭建分析原型的资深开发者,这套解决方案都能提供有价值的参考。
随着人工智能和机器学习技术的普及,基础数据分析能力的重要性不仅没有降低,反而因为需要为更复杂的模型提供高质量输入而变得更加关键。掌握如本文所述的完整数据分析流程,是构建更高级数据应用的基础。
获取和交流
需要本章或其他文章的源码和数据的同学,关注+三连,在对应文章下评论“6666“,加下面微信,发你!也可以拉你进群交流学习,加群备注:IT小本本学习
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
