Python数据分析顶流库Pandas全套干货|Part.1
- 2026-07-01 20:39:48
第一篇:Pandas到底是什么?为什么是数据分析必学核心库✅
之前我们陆续吃透了NumPy数值计算、jieba分词、wordcloud可视化这些Python实用工具,而真正能把数据处理、表格分析、数据清洗做到极致的,还得是Pandas!
作为Python数据分析领域的“扛把子”,Pandas是NumPy的升级版,专门针对表格型、结构化数据设计,不管是日常Excel数据处理、CSV文件分析,还是大数据清洗、统计汇总,有了它都能轻松搞定,彻底告别手动整理数据的繁琐。本篇作为系列开篇,先带大家从零认识Pandas,搞懂核心定位、安装导入和基础概念,打好数据分析地基🧱

🤔 先搞懂:Pandas是什么?核心作用有哪些?
Pandas是基于NumPy开发的开源Python数据分析库,名字来源于“Panel Data(面板数据)”和“Python Data Analysis”,专为处理结构化、表格型数据而生,完美弥补了NumPy处理非数值型数据、不规则数据的短板。
它最核心的贡献,是推出了Series(一维序列)和DataFrame(二维表格)两大核心对象,把复杂的数据清洗、筛选、计算、汇总操作,简化成几行代码,效率比手动操作Excel、原生Python处理高百倍,是数据分析师、爬虫工程师、算法岗必备的核心技能。
✅ Pandas全场景适用范围
📂 文件读写:快速读取/写入Excel、CSV、TXT、SQL、JSON等各类数据文件,告别格式兼容问题;
🧹 数据清洗:缺失值填充、重复值删除、异常值处理、数据格式转换,批量搞定脏数据;
🔍 数据筛选:按条件、行列、标签精准提取目标数据,灵活过滤无效信息;
📈 统计分析:一键计算均值、求和、最值、分组统计、数据透视表,替代Excel复杂函数;
🔗 数据合并:多表拼接、关联匹配、行列合并,处理多数据源联动分析;
💻 日常办公:职场报表处理、数据汇总、批量生成报告,提升办公效率。
🔥 Pandas VS 手动Excel VS 原生Python:优势碾压
效率超高:百万行数据秒级处理,Excel卡顿崩溃的大数据量,Pandas轻松拿捏;
代码复用:一次写好脚本,重复数据处理直接运行,不用重复操作;
功能全面:涵盖数据处理全流程,从读取到清洗再到分析,一站式完成;
灵活度高:支持自定义逻辑,处理复杂数据规则,远超Excel固定函数;
生态互通:完美兼容NumPy、Matplotlib、Scikit-learn,无缝衔接数据分析全流程。
📥 第一步:Pandas极速安装+标准导入(零失败教程)
Pandas安装全程无复杂依赖,一行命令搞定,导入有行业固定写法,新手直接照搬,避免报错,同时确保已安装NumPy(Pandas底层依赖):
# 常规安装命令,命令行直接运行pip install pandas# 网络差、安装失败时,用清华镜像源加速安装pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
# 行业标准导入写法,固定简写为pd,所有教程通用import pandas as pd# 验证安装:打印版本号,不报错即安装成功print(pd.__version__)# Output: 2.2.3
🧩 核心概念:两大核心对象,Pandas的灵魂
Pandas所有操作都围绕Series和DataFrame两大对象展开,搞懂它们,后续操作一顺百顺:
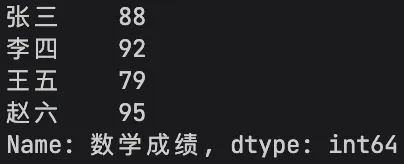
1. Series(一维序列)
相当于带索引的一维数组,由**数据列+索引列**组成,类似Excel里的单列数据,既能存数值,也能存字符串、时间等各类数据,比NumPy一维数组更灵活。
import pandas as pd# 创建Series:数据+自定义索引s = pd.Series([88, 92, 79, 95], index=['张三', '李四', '王五', '赵六'], name='数学成绩')print(s)
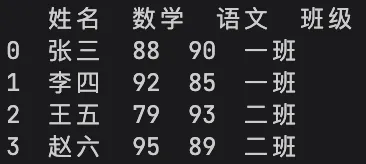
2. DataFrame(二维表格)
Pandas最核心的对象,相当于二维表格,有行有列,和Excel表格、数据库表结构完全一致,包含行索引、列名、数据值三部分,是日常数据处理的主要载体。
# 创建DataFrame二维表格data = {'姓名': ['张三', '李四', '王五', '赵六'],'数学': [88, 92, 79, 95],'语文': [90, 85, 93, 89],'班级': ['一班', '一班', '二班', '二班']}df = pd.DataFrame(data)print(df)
📌 第一篇小结+下篇预告
本篇我们搞懂了Pandas的核心定位、优势、安装导入和两大基础概念,明白它为什么是数据分析必学库。第二篇我们将深入讲解Pandas核心操作:文件读写、数据查看、行列筛选,手把手处理真实表格数据,干货更足,看完就能上手处理Excel/CSV文件,记得持续关注~
往期回顾:
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【Python大语言模型系列】谈一谈大模型应用的两种工作模式:Workflow和Agent(案例分析)
- python备份h3c交换机配置文件(tftp方式)
- Python 4.0 要来了!这 5 个变化你必须知道
- 用 Python 操作网络设备(Telnet)| 第七篇
- Python 环境管理新选择:uv 极速入门指南
- Python可视化 | 无需游戏引擎,用 tkinter 手写一个物理模拟器
- 《Python 从入门到精通》006 | 变量到底是什么:从给数据起名字开始理解编程
- Python:一门 “老少皆宜” 的编程语言
- Python3 数字:编程世界的数学基础
- 16种Python常见的数据分析算法,存一下吧
