在技术快速迭代的2025至2026年,开发者与企业面临的核心困惑不再是“某项技术是否强大”,而是“在何种场景下应当选择何种技术组合”。Python、Java、C++作为AI时代的三大支柱语言,各自承担着不可替代的角色:Python主导模型研发与数据科学实验,Java支撑企业级系统的稳定与高并发,C++则负责性能关键的实时推理与底层优化。
注:以营销为例
Python是“策略大脑”和“实验室”
核心含义: 这是“思考和实验”阶段。目标是“把产品卖出去,优化产品”,这个过程需要反复试错,寻找规律,Python就是为此而生的。
在营销中它在做什么:
探索数据:导入Keep用户的跟练记录、李宁的销售报表,像玩积木一样在Jupyter Notebook里分组、画图,寻找“什么时段推送最高效”或“完课率高的用户,买装备的概率是否也高”的规律。
训练模型:用Python调用最先进的模型库,去训练一个“预测用户流失”或“预测爆款码数”的模型。在这个阶段,应更关心“这个想法管不管用”,而不是“它能不能支撑千万人同时访问”。
Python的特点是开发快、出结果快,但它本身运行起来效率不是最高的。所以它最适合用来验证想法、训练模型原型,这是所有创新的起点。
C++是“极限物流配送员”
核心含义: 这是“上战场”阶段。当Python验证好的模型需要部署到真实世界,并且要求它在瞬间做出反应时,就得把模型的“核心引擎”用C++重写。
在营销中它在做什么:
构想一个“实时战术辅助系统”:当教练手上的iPad,需要在球员跑动的0.1秒内,就根据位置和生理数据计算出最佳传球路线。这个级别的速度,Python办不到,必须用C++来为最底层的数学运算,矩阵乘法、向量运算进行极致加速。
所有主流的AI框架(PyTorch/TensorFlow)底层核心都是C++写的,训练时用Python,模型实际运行时,就是在调用这些C++内核。边缘设备上,比如智能手表直接分析心率异常,运行模型,也几乎全靠C++。
Java是“整个商场的基础设施”
核心含义: 这是“开商场迎客”的阶段。当你从实验成果和小范围应用,走向服务千万级用户、并且要与公司内部其他复杂系统,如库存、支付、会员无缝对接时,你需要用Java来搭建这个稳定可靠的平台。
在营销中它在做什么:
搭建一个“李宁官方商城”:这个商城要在“双11”扛住千万人同时抢购,同时调用Python训练的推荐模型,经C++加速后,给每个人推荐不同的鞋,并准确无误地扣减库存、处理支付、生成订单。这个复杂、高并发、需要强数据一致性的业务逻辑,是Java最擅长的。
与此同时,大语言模型(LLM)的崛起催生了“Software 3.0”范式,使得自然语言本身成为一种编程接口,但这并不意味着传统编程语言的消亡。恰恰相反,理解何时用Python写代码、何时调用LLM API、何时必须深入C++优化,构成了现代AI工程师的核心竞争力。
注:
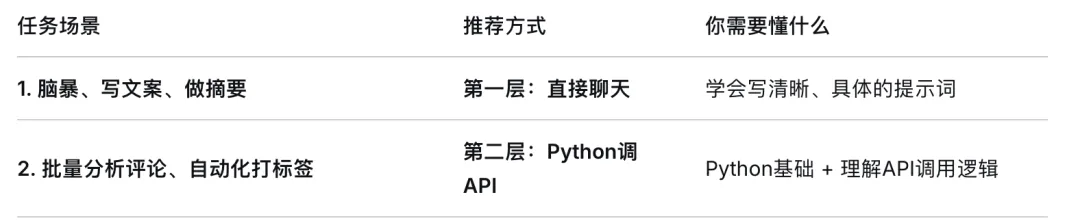
我把使用LLM的方式,按技术门槛从低到高、离你业务从近到远,分成三个层次来讲。
第一层:零代码,直接对话
适用场景:单次、非流程化、需要人类智慧的任务。
典型工具:ChatGPT、Claude、Kimi等聊天界面。
这是最直观的使用方式。你打开对话框,把你的需求用自然语言描述清楚,它给你结果。
在体育运营中能做什么:
内容生成:“为刚跑完半马的用户写10条朋友圈文案,语气要热血又凡尔赛。”
数据分析(初阶):“把这段用户问卷反馈,按‘吐槽课程无聊’、‘抱怨价格高’、‘想要新课种’分成三类,并做个总结。”
构思与调研:“列出2025年跑步鞋的三大营销趋势,面向20-30岁女性。”
文本摘要:“把这篇关于运动饮料成分的长论文,用通俗易懂的话总结出3个卖点。”
核心价值:像和一个全能实习生对话,把需要“创造力”和“常识”的任务丢给它。
第二层:API调用,让程序“长出大脑”
适用场景:需要自动化、批量化、与数据流集成的任务。
这是“Software 3.0”的核心体现。 你不再需要写代码告诉电脑“先找关键词,再按规则分类”,而是直接写一句自然语言指令,让程序去调用LLM。
流程是这样的:
你的Python程序负责从数据库读取今天所有新用户评论。
程序把评论和一句指令(“判断这条评论的情绪是正面、负面还是中性”)打包成API请求,发送给云端的大模型。
几秒后,大模型返回结果(“正面”),你的Python程序接收后,写入数据库,或者触发后续动作。
在体育运营中能做什么(结合Python自动化):
评论智能分析:每天凌晨,Python脚本自动跑一遍Keep新课程的所有评论,调用LLM识别出“吐槽动作太难”、“音乐不好听”等具体维度,存成结构化数据。早上你一上班,就能看到报表。
个性化邮件生成:用户即将流失,Python脚本读取他的历史跟练记录,生成提示词发给LLM:“该用户喜欢高强度间歇训练,最近一周没练,写一封召回邮件,推荐类似课程并附上优惠券链接。” LLM生成内容后,再自动发出。
舆情监控:实时抓取社交媒体上关于“李宁跑鞋”的讨论,调用LLM判断每条是“正面口碑”、“负面吐槽”还是“水军广告”,并自动发出预警。
核心价值:把LLM作为一个“理解文字的函数”,嵌入到你现有的数据流水线里,用代码驱动模型做文本。你不需要懂C++,只需会用Python调用API。
第三层:模型本地部署与深度定制
适用场景:数据极其敏感不能上传云端、需要极高频率调用、需要针对特定领域,如专业运动员生物力学进行深度微调。
工具:llama.cpp (C++)、Ollama、Hugging Face的transformers库 (Python)。
在体育科技中谁在用:
Catapult / STATSports:可能将运动员私密生理数据,在本地用微调过的模型进行分析,不联网,确保数据安全。
Sony的教练辅助系统:需要一个毫秒级响应的战术决策建议,且必须离线可用,这就需要将模型部署在本地高性能服务器上。
技术选型与AI应用落地系统性指南
1. 编程语言与技术工具的分工:Python、Java、C++、大模型如何协同
在人工智能系统从实验室走向产业落地的过程中,单一编程语言已无法满足全链路需求。根据Coderio、Coursera以及Microsoft等权威机构2025至2026年的技术分析,现代AI开发通常涉及三个层次:数据准备、模型开发与部署集成 。在这一分层架构中,Python凭借其无与伦比的机器学习和数据科学生态系统,占据了模型研发和原型验证的绝对主导地位;Java以其企业级的稳定性、并发处理能力和成熟的微服务生态,成为大规模系统后端的基石;而C++则通过对硬件的精细控制和零开销抽象,守护着实时推理、嵌入式系统和性能关键路径。理解这三种语言在AI技术栈中的精确定位,是构建高效、可扩展、可维护的AI系统的首要前提。
1.1 Python:AI与数据科学的绝对核心
Python在AI领域的主导地位并非偶然,而是由其语言设计哲学和庞大的第三方库生态系统共同决定的。根据PYPL和TIOBE编程语言指数,Python自2019年以来持续排名第一 ,在数据科学和机器学习领域尤为显著,因为Python的核心库组合,NumPy(数值计算)、Pandas(数据处理)、scikit-learn(机器学习)、PyTorch/TensorFlow(深度学习),构成了一个完整且高度集成的技术栈,使得数据科学家和AI研究人员能够以极少的代码量实现复杂的分析流程和模型训练 。
1.1.1 数据分析与文本处理:Pandas、NumPy、scikit-learn的不可替代性
在处理结构化数据,比如表格数据时,Python的生态系统的效率和成熟度至今无可匹敌。Pandas库提供了高性能、易于使用的数据结构和数据分析工具,使得数据清洗、转换、合并和聚合等操作变得极为便捷。NumPy则作为Python科学计算的基础包,提供了高效的多维数组对象和数学函数,是几乎所有数据科学库的底层依赖。
注:NumPy是什么
1. “多维数组对象”:结构严谨的数据“超级表格”
普通列表 vs. NumPy 数组
处理用户周训练时长,可能会用 Python 列表 [30, 45, 0, 60, 20],这就像流水账。想给每天加5分钟,你得写个循环一天天加。
而 NumPy 数组就像一个规则统一的超级表格,要求所有数据必须是同一类型。这样做是为了能进行闪电般的整表运算。在 NumPy 里,你想给上面那组训练数据每天加5分钟,只需写成 训练数据 + 5,它会瞬间完成所有运算,速度极快。
“多维”就像多层表格
如果说一份用户名单是“一维”,那么一张记录所有用户每日步数的表格就是“二维”。若再添上心率、速度等多个指标,就构成了“三维”或更高维度的数组。这就是 NumPy 所说的多维数组,一个能装下任意维度数据的强大容器。
当任务涉及数值预测、分类或聚类时,scikit-learn库以其统一且一致的API设计,标准的.fit()和.predict()方法,成为业界事实上的标准,涵盖了从逻辑回归、支持向量机到随机森林和梯度提升等绝大多数经典机器学习算法 (Sprintzeal) 。
注:
1.什么是“.fit( )”和“.predict( )”
你可以把模型想象成一个员工:
.fit(X, y) 是“学习/培训”
你对员工说:“这些是历史数据(X,比如用户的锻炼天数、体重),这是对应的结果(y,比如‘买了课’或‘没买课’)。自己找找规律!” 这一过程就是让算法从历史数据中学习规律。
.predict(X_new) 是“干活/预测”
培训完后,你扔给员工一份新的数据(X_new,比如新用户的数据),但不告诉他结果。他根据学到的规律,告诉你他认为的结果(“这人大概率会买课”)。
2. 什么是“统一的API设计”?
这才是scikit-learn最强大的地方。你不需要为每个算法去学习一套完全不同的新指令。
在营销中,你可以像换“战术”一样换算法:
你有一个“预测用户是否会流失”的任务。你的数据X(训练频率、互动时长)和y(是否流失)已经固定。这时,你想试试哪个模型预测更准,只需替换定义模型的这一行代码,剩下的 .fit() 和 .predict() 流程完全不变。
API(Application Programming Interface,应用程序编程接口),本质上就是不同软件程序之间沟通的“信使”或“中间人”。它定义了一套标准化的请求和响应规则,让一个程序可以安全、可控地使用另一个程序的功能或数据,而无需了解对方内部的复杂实现。
3. 它覆盖了哪些经典算法?
数值预测(回归):预测一个具体的数字。例如,预测一个Keep用户的终生价值是多少钱。常用算法:线性回归、随机森林回归等。
分类:判断一个东西属于哪一类。例如,判断一个用户是“即将流失”还是“高价值”用户,或者区分用户是“跑步爱好者”还是“瑜伽爱好者”。常用算法:逻辑回归、支持向量机、随机森林。
聚类:在没有标签的情况下,让算法自动把用户分成几群,你再给不同群组命名。例如,对李宁的购买者进行消费行为的聚类,算法发现了“价格不敏感、只买最新款”的一群人,你把他们命名为“潮流先锋”。常用算法:K-Means等。
4.这对你有什么启发?
你的工作不涉及编写底层算法
你负责定义问题:想清楚“我要预测什么?”,这是你作为业务专家的直觉。
你负责准备数据:把用户的行为数据整理干净,比如哪些特征可能有助于判断用户流失。
scikit-learn负责建模:你只需调用 .fit() 和 .predict(),算法会自动帮你找出数据里的模式。
根据2026年的行业分析,scikit-learn在表格数据处理、可解释性要求高的场景,如金融、医疗、法律,以及快速原型开发中,仍然是最终解决方案的首选 。即使在LLM时代,这些传统工具依然至关重要,因为大量企业AI应用处理的核心数据仍然是结构化的,而非文本或图像 。
1.1.2 模型训练与实验:PyTorch、TensorFlow、Hugging Face生态
在深度学习领域,Python的地位通过PyTorch和TensorFlow两大框架得到了进一步巩固。PyTorch以其动态计算图(define-by-run)和直观的Pythonic风格,成为学术界和研究领域的首选,其灵活的调试能力和对动态模型架构的天然支持,极大地加速了 novel architectures 的原型验证。TensorFlow则凭借其静态图优化、成熟的跨平台部署工具链(如TensorFlow Lite、TensorFlow.js、TFX)以及在生产环境中的卓越性能,在工业界大规模系统中保持着强大的竞争力。Hugging Face平台的出现更是将Python在NLP领域的地位推向了新的高度,其Transformers库提供了超过100万个预训练模型,使得研究人员和开发者可以轻松地访问、微调和部署BERT、GPT、T5等前沿模型,形成了PyTorch-native的庞大模型生态 。
注:
PyTorch 是“实验室”里的王者,主导着学术探索;
TensorFlow 是“工厂”里的支柱,支撑着大规模应用;
而 Hugging Face 则是一个让所有人都能轻松获取顶尖模型的“公共图书馆”。
PyTorch:研究员的“实验笔记本”
它的核心设计哲学是灵活和直觉,用起来就像在写普通的Python代码。
“动态计算图”(define-by-run)意味着你每写一行代码,计算图就即时构建。这让调试变得非常直观,用Python自带的print()就能检查每一步的结果。
为什么是研究首选:因为它思想开放,不强制你按特定模板写代码。最适合快速验证新想法、设计前所未见的新模型架构(novel architectures)。
场景:一个AI实验室的学生想尝试一种全新的模型结构。使用PyTorch,可以把新想法快速实现、立刻调试,快速判断这个想法是否可行。
TensorFlow:工业界的“自动化流水线”
它的核心优势是全流程工具链和部署能力,能保证模型从“能跑通”到“稳定服务千万用户”。
“静态图优化”在模型运行前,先构建完整的计算图进行全局优化,牺牲了灵活性,换取了极致的运行效率。
跨平台部署工具链:它拥有一个完整的生态系统,能将训练好的模型部署到各种硬件上:
TensorFlow Lite:部署到手机、智能手表等移动端。
TensorFlow.js:部署到浏览器,在网页上直接运行AI模型。
TFX:搭建从数据处理到模型上线的全流程自动化生产流水线。
场景:像“李宁”这样的公司,需要用AI在手机App上实时识别用户脚型来推荐鞋码。TensorFlow能提供成熟的技术栈,把训练好的模型高效、稳定地部署到数百万用户的手机上。
Hugging Face:AI时代的“超级应用商店”
它解决了“自己从头训练大模型成本太高”的核心痛点,形成了一个庞大的模型共享生态。
它是什么:一个预训练模型的托管平台,提供了超过100万个现成的模型,可以直接下载使用。
它能做什么:让你能跳过昂贵的“预训练”环节,直接在现成的顶尖模型(如BERT、GPT)上进行微调,用少量数据训练出解决特定任务的专家模型。
场景:你想做一个分析Keep用户评论情感的AI工具。不必从零开始研究,只需去Hugging Face找一个中文情感分析模型,用你自己的Keep评论数据微调一下,几小时内就能得到一个高性能的专用模型。
1.1.3 快速原型与自动化脚本:AI时代的“胶水语言”
Python的简洁语法和动态类型特性使其成为快速原型开发的理想语言。在AI项目中,从数据探索、特征工程到模型对比,开发者需要频繁地迭代和实验,Python的低代码量和即时反馈机制,如Jupyter Notebook的交互式环境,能够显著缩短从想法到验证的周期。此外,Python作为一种出色的“胶水语言”,能够无缝集成C++编写的高性能库,如NumPy和PyTorch的底层实现,以及Java编写的后端服务。例如,一个典型的AI应用可能使用Python训练模型,然后通过FastAPI或Flask将其封装为REST API,再由Java编写的微服务集群进行调用和负载均衡 。这种多语言协同的开发模式,使得团队可以充分利用每种语言的优势,构建既高效又灵活的AI系统。根据GitHub和Stack Overflow的调查,截至2026年初,92%的美国开发者已日常使用AI编码工具,而这些工具生成的代码绝大多数是Python,进一步巩固了其作为AI时代通用语言的地位。
注:
1. “快速原型开发”:你的“想法试验场”
这是Python对你最大的价值。它意味着把你的商业想法,变成可运行的AI模型,这个过程可以非常快。
在体育运营中意味着什么:你有一个想法:“给总在周末跑步的用户,周一早上推送一期‘恢复性瑜伽’会不会更受欢迎?”
过去,你可能需要提需求、排期、等工程实现,周期以周或月计。现在,你可以在Jupyter Notebook(一个像电子笔记本一样的交互式编程环境)里,写几十行Python代码,把历史数据导出来,关联“周末跑步”和“周一瑜伽”的用户行为,当场验证这个假设是否成立。这种即时反馈,让你从一个“提需求的人”变成了“自己动手用数据验证想法的人”。
2. “胶水语言”:连接所有技术组件的“神经中枢”
Python自身运行效率不是最高,但它能像“胶水”一样,把用其他高性能语言写的模块无缝粘合起来,由它统一指挥调度。
“集成C++高性能库”:NumPy和PyTorch,底层其实是C++在飞速运转。你只需用Python写下简洁的指令,就能驱动那个强大的底层引擎。好比汽车的方向盘(Python)很轻便,但它控制的发动机(C++)却动力极强。
“集成Java后端服务”:整个流程是这样的:
你用Python训练了一个“预测用户流失”的模型。
用轻量级的Web框架FastAPI,把这个模型快速包装成一个在线API接口。这就像给模型装了个电话,别人打这个号码(网址)就能找到它。
公司核心的、能承载千万级用户的Java系统,在需要时拨打这个“电话”,调用你做的模型,把结果整合进App或推送消息里,稳定地呈现给最终用户。
1.2 Java:企业级AI系统的基石
尽管Python在AI模型开发领域风光无限,但在企业级应用的部署和集成层面,Java仍然扮演着不可替代的角色。Java语言的设计哲学强调稳定性、可移植性和可维护性,其“一次编写,到处运行”的特性、强大的内存管理、成熟的并发处理机制以及庞大的企业级框架生态(如Spring Boot),使其成为构建大规模、高可用、长周期运行的AI后端系统的首选。在许多传统企业和金融机构中,核心业务流程系统早已基于Java构建,将AI能力集成到这些现有系统中,Java自然成为了最佳的桥梁。
1.2.1 大数据与分布式计算:Hadoop、Spark生态的主导地位
在处理大规模数据集时,Python的性能瓶颈(解释器开销、全局解释器锁GIL)会变得尤为突出。相比之下,Java虚拟机(JVM)的性能和可扩展性使其成为大数据处理框架的理想选择。
注:
1. Python 的瓶颈:像一个只有单个前台的大型健身房
全局解释器锁(GIL,Global Interpreter Lock):
这是 Python 最著名的性能限制。它就像那个唯一的健身房前台。
假设有1000个用户(数据)同时涌入,想要办手续(被CPU处理)。虽然健身房里有多个教练(CPU多核),但公司规定,在同一时刻,有且仅有一个前台能处理一名用户。其他教练哪怕闲着,也只能干等。
这就导致,即使你的电脑有再多的CPU核心,Python 的多线程程序在计算任务上,很难真正利用到多核的性能,处理大量数据时就会卡在这个“前台瓶颈”上。
解释器开销:
这就像你每次去健身,教练(解释器)都得现场把你的中文指令(Python代码)翻译成英文(机器码)给前台听,而不是你直接说英文。这个翻译过程本身就拖慢了速度。
所以,当数据量达到一定级别后,Python 这种“慢悠悠的单窗口处理”模式就会力不从心。
2. Java 的优势:像一个高效的现代化物流中心
Java 虚拟机(JVM,Java Virtual Machine):
JVM 是运行所有 Java 程序的虚拟环境,它更像是那个自动化物流中心,有非常先进的并行处理能力。它没有 GIL 这样的限制,可以轻松地同时开启多个窗口(多线程),把所有教练(CPU核心)都调动起来,并行处理涌入的1000个用户。
性能和可扩展性:
更重要的是,JVM 经过二十多年的优化,它的即时编译技术能把热点代码直接编译成机器码,运行效率极高。当数据量增长时,它能稳定地把任务分配到几十、上百台机器上并行处理。
这正是 Hadoop、Spark、Flink 这些大数据处理框架都是用 Java(或JVM语言)写成的根本原因。它们被设计用来在成百上千台服务器上,稳定、高效地处理 PB 级别的数据。
3、在运营中,这体现在哪里?
Python 的地盘(你的地盘):
你从 Keep 数据库中提取十万条用户记录,在 Jupyter Notebook 里用 Python 的 Pandas 做分析、画图、训练一个预测模型。数据量在你单机内存能处理的范围内,Python 完全够用,且最灵活高效。
Java 的地盘(工程团队的地盘):
Keep 的后端系统要处理数千万用户每天产生的数十亿条跟练、打卡、互动数据。这时,后端团队会用基于 Java 的 Flink 或 Spark,进行流式或批量处理。比如,实时统计全平台“今天最受欢迎课程排行榜”,并在瞬间将结果更新到所有用户的 App 首页。这种毫秒级、超大规模的实时计算,是 Java 大展拳脚的领域。
Apache Hadoop和Apache Spark这两个业界最主流的分布式计算框架,其核心都是用Java/Scala编写的 。Spark的MLlib库提供了丰富的机器学习算法实现,可以直接在分布式数据集上进行训练和预测,这对于处理TB甚至PB级别的数据至关重要。当AI项目从GB级的实验数据扩展到生产环境的海量数据时,从Python的scikit-learn迁移到Spark MLlib,或利用PySpark API在Python中调用Spark的分布式计算能力,是一种常见的技术演进路径。Java在这一层的优势在于其能够高效地管理集群资源、处理分布式任务调度,并保证数据管道的高吞吐量和容错性。
1.2.2 高并发后端服务:Spring Boot与微服务架构
AI模型最终需要通过API服务的形式暴露给前端应用或其他系统。在这一环节,Java的Spring Boot框架凭借其自动配置、嵌入式服务器和丰富的生态(如Spring Cloud for微服务),能够帮助企业快速构建稳健、可扩展的生产级服务。
一个典型的企业级AI架构中,Java服务层负责处理用户认证、请求路由、负载均衡、缓存、数据库事务等非功能性需求,同时将核心的预测或推理请求转发给后端的Python模型服务(如通过gRPC或REST API)。
注:
一、为什么拆分?—— 应对企业级核心矛盾
企业级系统面临两个看似矛盾的需求:
1、高并发、高稳定、事务强一致(处理海量用户请求)
2、快速迭代、算法复杂、科学计算(满足AI模型需求)
如果让Python服务(如Flask/Django)直接扛住所有流量,它脆弱的并发能力和全局解释器锁(GIL)会成为瓶颈。如果让Java强行调用或实现AI模型(如用DL4J),其科学计算生态和开发效率远不如Python。拆分是解决这个矛盾的最优解。
二、为什么这样划分职责?—— “稳定”与“多变”的分离
这个架构的本质,是将系统拆分为 “稳定的基础设施”(Java层)和 “多变的应用算法”(Python层)。
Java服务层:系统的“大堂经理”和“后勤总管”
它负责所有非功能性需求,这些是企业级系统的基石。
用户认证:需要与LDAP、OAuth2、SSO等复杂安全协议集成。Java生态有Spring Security等成熟方案,安全可靠。Python的认证方案相对零散。
请求路由与负载均衡:需要处理HTTP/2、WebSocket,并将请求分发到后端成百上千个模型实例。Java的Netty、Spring Cloud Gateway是高性能网关的标配,而Python原生的异步网关性能和成熟度不足。
缓存:需要与Redis、Caffeine等高效集成,支持分布式缓存和本地缓存的二级缓存策略。Java的Caffeine和Redisson客户端性能极佳。
数据库事务:需要保证ACID特性,处理复杂的对象关系映射(ORM)和连接池。Spring事务管理和Hibernate是领域标杆,Python的Django ORM或SQLAlchemy在高并发下的事务处理能力相对较弱。
高并发与弹性:基于Servlet容器的线程池模型成熟稳定。Java成熟的熔断、降级、限流(如Resilience4j)机制比Python的类似方案更健壮。
一句话:Java负责所有“严肃的业务逻辑”和“系统稳定性”。
Python模型服务层:系统的“科学家”和“计算工程师”
它只专注于一件事:高效的模型推理。
科学计算生态:PyTorch, TensorFlow, ONNX Runtime等主流框架的Python API最完善、最及时。
GPU利用效率:Python是CUDA等底层计算库的一等公民,能更好地利用GPU进行张量计算。
快速迭代:算法工程师擅长Python,他们可以独立更新模型服务,优化预处理/后处理代码,只要保证接口兼容,就完全不影响上层的Java网关。
轻量级:模型服务本身是无状态的(推荐),可以借助K8s快速水平扩展。它不需要处理认证、事务等它不擅长的复杂逻辑。
一句话:Python负责所有“不确定的计算逻辑”和“算法创新”。
三、通信方式的选择:gRPC vs REST API
它们之间的通信也体现了这种设计思想:
gRPC(高性能首选):基于HTTP/2和Protobuf(一种高效的数据序列化格式),性能远高于REST/JSON。非常适合内部、低延迟、高吞吐的通信场景。Java和Python对gRPC都有良好支持。
REST API(简单通用):基于HTTP/JSON,虽然性能稍差,但调试简单、防火墙友好,适合对延迟不敏感或需要跨多种异构系统的场景。
企业级架构中,多选用gRPC,因为它更符合“高性能内部服务调用”的定位。
这种分层设计实现了业务逻辑与AI模型的解耦,使得模型可以独立开发、部署和迭代,而Java层则保证了整个系统的稳定性和安全性。对于需要与现有企业资源规划(ERP)、客户关系管理(CRM)等系统进行深度集成的AI应用,Java的成熟连接器(Connectors)和企业集成模式(EIP)支持是Python难以比拟的。
1.2.3 与Python模型的集成:通过API调用AI能力
Java在AI系统中的角色并非替代Python,而是与之协同。Deep Java Library (DJL) 是一个专为Java开发者设计的开源深度学习库,它提供了与PyTorch、TensorFlow和MXNet等主流框架的原生集成,允许Java开发者直接加载和运行预训练的神经网络模型,而无需编写Python代码 。
注:
类比:发电站与通用插座
发电站 (PyTorch, TensorFlow, MXNet):它们是专业的电力生产者。负责利用复杂的能量转换原理即深度学习算法,生产出供电器工作的强大电力即高性能AI模型。它们非常专业,但输出的接口(API)各不相同。
通用插座 (Deep Java Library, DJL):它是一个Java世界里的标准化“插座”。职责是提供统一的“插孔”(统一的Java API),让你能连接并稳定获取不同“发电站”送来的电力,而无需关心背后的复杂线路。最终,灯(你的Java应用)就亮了。
详解:
Deep Java Library (DJL),是由亚马逊在2019年推出的开源深度学习库。
它不“发电”(训练/运行模型),而是提供统一接口。你可以通过它调用PyTorch、TensorFlow等主流框架,统一用Java代码完成模型加载、推理等任务。
💡 核心价值:
让Java开发者无需切换语言或学习Python,就能无缝利用AI生态。
代码与底层深度学习引擎解耦,未来可随时更换或升级,而无需大规模重构。
🏭 三大深度学习框架:“发电站”
它们是构建和运行深度学习模型的核心引擎。
1. PyTorch:热门的“动态图”
出身:由Meta的AI研究团队(FAIR)开发维护。
特点:采用动态计算图。操作简单直观,像写普通Python代码一样逐行执行,便于调试和快速验证想法。
擅长领域:学术研究和快速原型开发,因其灵活性备受算法研究人员青睐。
2. TensorFlow:稳重的“全能选手”
出身:由Google的Brain团队开发。
特点:最初采用静态计算图,需预先定义计算流程再执行,利于性能优化和生产部署。提供大量工具(如TensorFlow Serving),为AI产品“上市”铺平道路。
擅长领域:企业级应用和大规模生产部署。
3. MXNet:灵活的“多面手”
出身:由多家顶尖大学的研究者发起,后被Apache基金会孵化。
特点:可混合使用动态图和静态图两种模式,兼具灵活开发和生产性能。由亚马逊选为官方首选DL框架,在其云服务中被广泛使用。
擅长领域:云环境下的高效分布式训练和多语言支持。
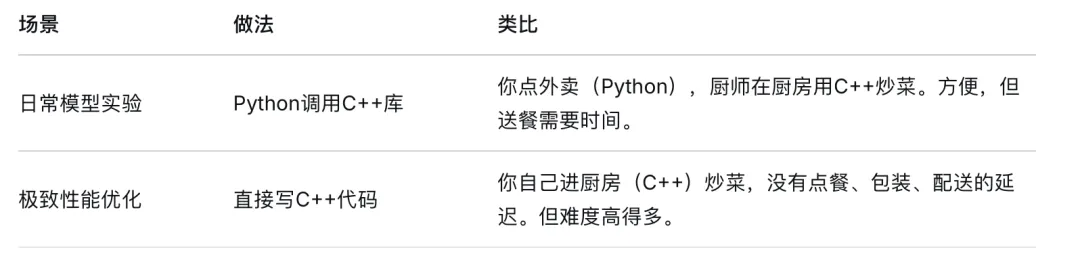
然而,在更常见的实践中,Java服务通过HTTP/REST或gRPC协议调用由Python框架(如FastAPI、Flask、TorchServe)暴露的模型推理服务。这种模式被称为“多语言AI栈”(polyglot AI stack),它允许企业利用Python进行模型研发和实验,同时利用Java构建稳定、高性能的生产环境。
注:
核心比喻:米其林餐厅的后厨与前台
Python + AI框架(如FastAPI, TorchServe):扮演研发实验厨房。主厨(数据科学家)在这里反复尝试食材配比、研究新菜品(训练模型),这里工具最全、最灵活,效率最高,但稳定性不一定好,不适合大规模、高强度的出餐。
Java + Spring Boot(你的Java服务):扮演稳健的大堂与前台系统。负责接待客人、管理订单、处理支付、协调整个餐厅的运营。它非常稳定、可靠,能处理高并发,但它的厨房(Java生态)缺少那些最尖端、新式的厨具(AI库)。
HTTP/REST 或 gRPC:扮演传菜窗口。是一个标准的、清晰定义的接口,用于把实验厨房做好的菜品(推理请求和结果),稳定地传递给大堂。
“多语言AI栈”到底是什么意思?
拆开来看:
多语言:指系统里同时存在两种或以上的主力语言——Python(擅长AI)和Java(擅长企业级后端)。
AI栈:指从模型训练到上线推理这一整套技术链条。
所以合起来就是:用最擅长做AI的Python来完成AI模型本身的工作,同时用最擅长构建可靠大型系统的Java来负责所有业务逻辑和交互。两者通过网络调用各司其职,组成一个完整的系统。
简单说:Python懂“智能”,Java懂“服务”。你不能让Python去做Java擅长的高并发业务编排,也很难让Java去做Python擅长的模型推理计算。
例:一个具体的请求流程
用户的手机App点击“识别这张图片”,请求发到Java后端服务。
Java服务进行身份验证、限流、风控等业务逻辑。
Java服务将图片数据打包成一个HTTP请求(或更高效的gRPC请求),发送给Python推理服务(比如TorchServe)的地址。
Python服务加载了最新训练好的PyTorch模型,计算出图片的类别,返回给Java服务。
Java服务拿到结果,记录日志,并将结果封装成用户需要的格式,返回给手机App。
这种模式解决了什么实际问题?
让数据科学家和工程师并行工作:数据科学家在Python里随意折腾模型,Java工程师同时开发稳定的后端服务。双方只需要约定好API接口。
独立扩缩容:如果推理请求量暴增,只扩容Python服务;如果是业务请求暴增,只扩容Java服务。互不干扰,节省资源。
技术选型自由:Java服务想换框架?可以。Python服务想从Flask换成FastAPI?也可以。只要API不变,互相毫无影响。
企业里不追求用“一种通吃所有场景”的神奇语言。而是让Python负责AI模型的研究与实验(因为它快、灵),通过HTTP/gRPC这个标准接口,把结果提供给Java负责的生产环境(因为它稳、强)。两者协作,兼得了研发的灵活性和生产的可靠性。
例如,一个电商推荐系统可能使用Python和PyTorch训练深度学习推荐模型,然后通过TorchServe部署为gRPC服务,而前端的商品详情页、购物车等服务则通过Java Spring Boot应用调用该gRPC服务获取实时推荐结果。这种架构充分发挥了两种语言的优势,是现代企业AI应用的标准实践。
1.3 C++:性能关键的底层支撑
在AI系统的技术栈中,C++位于金字塔的底层,它并非大多数开发者日常会直接使用的语言,但却是支撑整个AI大厦的基石。Python的机器学习库之所以高效,正是因为其核心计算模块(如NumPy的数组操作、PyTorch的autograd引擎)大多是用C++编写的,并通过Python绑定暴露给上层 (ITU Online) 。当AI应用对延迟、吞吐量或资源消耗有极致要求时,直接使用C++进行开发或优化就变得不可避免。
注:
1.想象一座AI大厦:
顶层:数据科学家在用Python写import torch; model.predict(x),快速实验。
中层:各种Python库(PyTorch、TensorFlow、NumPy)提供了高级API。
底层:C++ 负责实际的数学运算、内存管理、多线程调度、GPU通信(CUDA)。
2. “Python库的高效,是因为核心计算模块用C++编写”
Python本身很慢(动态类型、逐行解释)。但NumPy的数组加法a + b看似Python代码,实际执行的是预编译好的C++机器码。
C++做了什么:直接操作CPU向量指令(SIMD)、自动并行化、缓存友好的内存布局。
Python绑定:用pybind11或Cython把C++函数包装成Python可调用的接口。
所以当你写loss.backward()时,Python只是做了一个“远程调用”,真正的自动求导引擎(autograd)是C++在跑。
3. “极致要求时,直接使用C++不可避免”
Python调用C++虽然快,但跨语言调用本身有开销(序列化、类型转换、GIL争用)。在某些场景下,这个开销会成为瓶颈:
毫秒级延迟要求:高频交易、自动驾驶的实时控制。哪怕多花0.1毫秒从Python调用C++,也可能超标。
超高吞吐量:每秒处理百万级请求的推荐系统。每个请求都从Python到C++往返一次,CPU会烧在绑定层。
资源极其受限:嵌入式设备、手机端侧模型。Python运行时(几十MB)本身就可能超限。
此时只能直接用C++写整个推理服务,去掉Python中间层。比如:
用 TensorRT(C++库)部署GPU推理,绕过PyTorch的Python API。
用 ONNX Runtime 的C++ API,在移动端直接运行模型。
用 vLLM 这类高性能大模型服务框架,其核心调度也是C++。
1.3.1 实时推理与嵌入式系统:自动驾驶、机器人、IoT
在自动驾驶、工业机器人和物联网(IoT)等场景中,模型推理必须在毫秒甚至微秒级别完成,且计算资源(CPU、内存)极为有限。C++作为一门编译型语言,能够生成高度优化的机器码,直接操作硬件资源,避免了Python解释器的运行时开销和垃圾回收(GC)带来的不确定性延迟 (ITU Online) 。例如,TensorFlow Lite和PyTorch Mobile等端侧推理框架,其核心运行时就是用C++实现的,并针对ARM等嵌入式处理器进行了深度优化。
注:
1. 为什么必须是毫秒/微秒级?——因为“慢”会出事故
自动驾驶:汽车以120km/h行驶,每毫秒前进3.3厘米。从摄像头拍到行人到刹车执行,整个链路的延迟必须控制在几十毫秒内。如果模型推理多花10毫秒,刹车距离就多出33厘米,可能决定生死。
工业机器人:机械臂抓取移动的零件,控制周期通常在1毫秒以内。一旦推理延迟抖动(有时快有时慢),就会抓空或撞坏。
物联网设备(如智能门锁):电池供电,CPU主频可能只有几百MHz。不能跑一个Python解释器来浪费电和内存。
在这些场景里,稳定、可预测的低延迟比平均速度快更重要。
打个比方:
Python像一位同时做翻译和跑腿的助手——每做一个动作都要先“理解指令”,而且时不时会停下来收拾房间(GC)。
C++像一张写满机器指令的硬纸板——CPU拿到直接执行,没有任何中间人,也不会突然停下来整理桌面。
在自动驾驶里,你无法容忍“收拾房间”的那几十毫秒——这会让汽车在路口发呆。
2. “端侧推理框架核心用C++实现并深度优化”是什么意思?
TensorFlow Lite、PyTorch Mobile 这些框架专门为手机、树莓派、ARM芯片设计。它们的底层计算引擎(矩阵乘、卷积、激活函数)全部用C++编写,并且针对ARM的NEON指令集、缓存大小、甚至特定芯片的内存带宽做了手工汇编级优化。
Python只是这些框架的一个可选前端,在PC上做模型转换时可以调用Python API,但到了嵌入式设备上,你可以完全不用Python,直接调用C++ API运行模型。
例如,你在手机上用Google相机的人像模式,那个分割模型大概率是TensorFlow Lite的C++ runtime在DSP或NPU上跑的,整个过程中没有一行Python代码。
特斯拉的自动驾驶系统Autopilot就是一个典型案例:其系统中包含了大量C++代码来处理传感器融合、路径规划等硬实时任务,同时集成神经网络进行目标检测和语义分割,Andrej Karpathy在Tesla AI Day上展示的架构图清晰地表明,随着神经网络能力的增强,系统中大量原本用C++编写的传统逻辑代码被逐步“删除”,由Software 2.0的神经网络所取代 (36kr.com) 。这一案例生动地展示了C++与深度学习模型在高性能系统中的协同与演进。
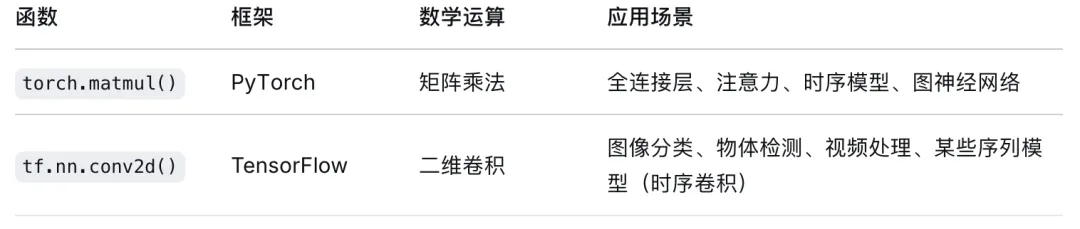
1.3.2 深度学习框架底层:TensorFlow、PyTorch的C++后端
PyTorch和TensorFlow等主流深度学习框架虽然提供了对用户友好的Python前端,但其高性能的计算后端无一例外都是用C++和CUDA(NVIDIA的并行计算平台)编写的。当开发者调用torch.matmul()或tf.nn.conv2d()时,实际执行的是高度优化的C++和GPU内核代码。对于需要定制算子或优化特定硬件(如NPU、FPGA)上推理性能的高级用户,编写C++扩展是必不可少的技能。例如,PyTorch 2.0引入的torch.compile功能,其背后的Inductor后端能够生成优化的C++内核(用于CPU)和Triton内核(用于GPU),从而显著提升训练和推理速度。NVIDIA的TensorRT推理优化器同样是一个C++库,它通过对模型进行层融合、精度校准(如INT8量化)和内核自动调优,能够在NVIDIA GPU上实现比原生框架快数倍甚至数十倍的推理性能。
注:
PyTorch 和 TensorFlow 是当今构建和训练人工智能模型的两个核心开源框架。可以说,PyTorch 是更受科研界青睐的“灵巧实验台”,而 TensorFlow 则是工业界久经考验的“稳定生产线”。
如果你是学生或研究者,想紧跟前沿技术和快速实验,首选 PyTorch。它在学术界的主导地位意味着你能找到绝大多数最新的论文代码和模型实现,上手快,交流社区也最活跃。
如果你在构建需要稳定上线的产品,特别是对性能和部署工具有严格要求,首选 TensorFlow。它完整的生产套件能帮你更快、更可靠地将模型部署到服务器、手机或嵌入式设备上。
如果项目需要部署到手机或物联网设备,务必选择 TensorFlow。它的 TensorFlow Lite (TFLite) 是移动端和边缘计算的事实标准,无论是成熟度、性能优化还是设备支持都远超PyTorch Mobile。
如果想快速上手,无所谓生产场景:可以优先考虑 TensorFlow + Keras 组合。Keras 作为 TensorFlow 的高级 API,将神经网络的层、优化器等抽象成开箱即用的模块,代码简洁,堪称“深度学习界的Scikit-learn”,非常适合初学者快速搭建和验证模型
CUDA是NVIDIA推出的一套并行计算平台和编程模型,它的核心作用是让GPU不仅能处理图形,更能像“超级大脑”一样,去高效解决深度学习、科学计算等极其复杂的通用计算问题。
1.3.3 高频交易与计算密集型任务
在金融领域的高频交易(HFT)系统中,延迟是决定盈亏的关键。C++因其对内存布局的精确控制和零开销抽象,成为构建低延迟交易系统的首选语言。虽然交易决策本身可能由机器学习模型做出,但模型的加载、特征的计算、信号的触发和订单的下达等关键环节,都需要用C++来实现以满足微秒级的延迟要求。同样,在科学计算、计算机图形学、物理仿真等领域,C++的性能优势使其成为处理大规模数值计算和复杂算法的标准工具。根据ITU Online的技术分析,在AI系统中,Python与C++的分工是明确的:Python负责速度较慢但灵活性要求高的部分(如实验、编排、数据处理),而C++则负责性能关键路径(如实时推理、自定义计算内核)。一个成熟的AI工程团队,应当具备在两种语言之间进行无缝协作的能力。
1.4 大模型(LLM):新时代的“超级工具”
如果说Python、Java、C++是构建AI系统的传统工具,那么大语言模型(LLM)的出现则带来了一种全新的“超级工具”,它正在从根本上改变软件的开发方式和AI能力的交付模式。LLM不仅仅是另一种需要被集成的组件,它代表了一种新的编程范式,通过自然语言指令(Prompts)来驱动复杂任务,这在Andrej Karpathy提出的“Software 3.0”框架中得到了系统性的阐述。
注:
Andrej Karpathy提出的 "Software 1.0" 到 "Software 3.0" 的框架,并非描述了技术上的代数更替,而是揭示了软件开发从 "如何做" 到 "做什么" 的根本性范式转移:
Software 1.0 (经典编程):程序员用 C++/Python 等编程语言编写精确的指令 (代码)。核心是"程序员明确告诉计算机每一步怎么做",明确但无法应对模糊规则。
Software 2.0 (统计学习):程序+优化器基于大数据训练神经网络,生成的权重参数相当于最终程序。核心是"程序员告诉计算机学习的方法,计算机从数据中自己学会怎么做",性能强但过程是个黑盒。
Software 3.0 (模型指挥):用户通过自然语言 Prompt 与大模型 (LLM) 交互,大模型生成最终指令。核心是"用户告诉计算机目标,计算机自己理解并规划怎么做",门槛极低但依赖模型能力,且结果不可预测。
1.4.1 LLM作为“自然语言编程接口”
在Software 3.0范式中,LLM本身被视为一种可编程的计算机,而自然语言(如英语)则成为了最热门的“编程语言”。开发者不再需要精确地编写每一行代码来指定计算机的每一步操作,而是可以通过高层次的、描述性的自然语言指令,让LLM来理解意图并生成相应的代码、文本或执行逻辑。这种方式极大地降低了编程的门槛,使得非专业开发者(甚至业务人员)也能够通过“vibe coding”的方式快速构建应用原型 。例如,一个市场营销人员可以通过向LLM描述需求,如“写一个Python脚本,读取CSV文件中的销售数据,按地区分组计算总销售额,并生成一个柱状图”,LLM可以直接生成可运行的代码。这种从“指令式编程”到“意图式编程”的转变,正在催生大量的AI应用,如代码助手(GitHub Copilot)、对话式数据分析(PandasAI)和自动化工作流构建工具。
1.4.2 LLM在代码生成、文本理解、数据分析中的应用边界
LLM的能力边界决定了它在何种场景下能够替代传统编程,在何种场景下只能作为辅助。在代码生成方面,LLM擅长处理样板代码、API调用、常见算法实现和单元测试编写。在文本理解和生成方面,LLM展现了强大的能力,能够进行高质量的翻译、摘要、情感分析、内容创作和复杂推理,这使得它在客服机器人、内容营销、文档处理等领域有着广泛的应用。在数据分析领域,像PandasAI这样的工具允许用户用自然语言查询DataFrame,LLM在背后生成相应的Pandas代码并执行,极大地降低了数据分析的技术门槛。然而,LLM在处理需要精确数值计算、复杂算法逻辑、严格事务控制或与特定硬件深度交互的任务时,仍然无法替代传统编程语言。在这些领域,LLM更适合扮演“协作者”而非“替代者”的角色。
注:
样板代码:不得不写的“八股文”
定义:为了满足编程规范或框架要求而必须写,但本身不包含任何业务逻辑的、重复性很高的代码结构。
就像你每次去住酒店,都得重复“出示身份证、人脸识别、交押金”这一套流程。这些事跟你的旅行目的(业务逻辑)无关,但又必须做。
单元测试:给代码上的“健康保险”
定义:为了验证程序中最小的独立单元(通常是一个函数或方法)是否工作正确而编写的自动化测试代码。
它像你买车时测试刹车、方向盘、车灯是否正常。你不会等到上路才发现刹车失灵,而是每个部件单独测试好了再组装。
1.5 技术选型决策框架:一张图看懂何时用何物
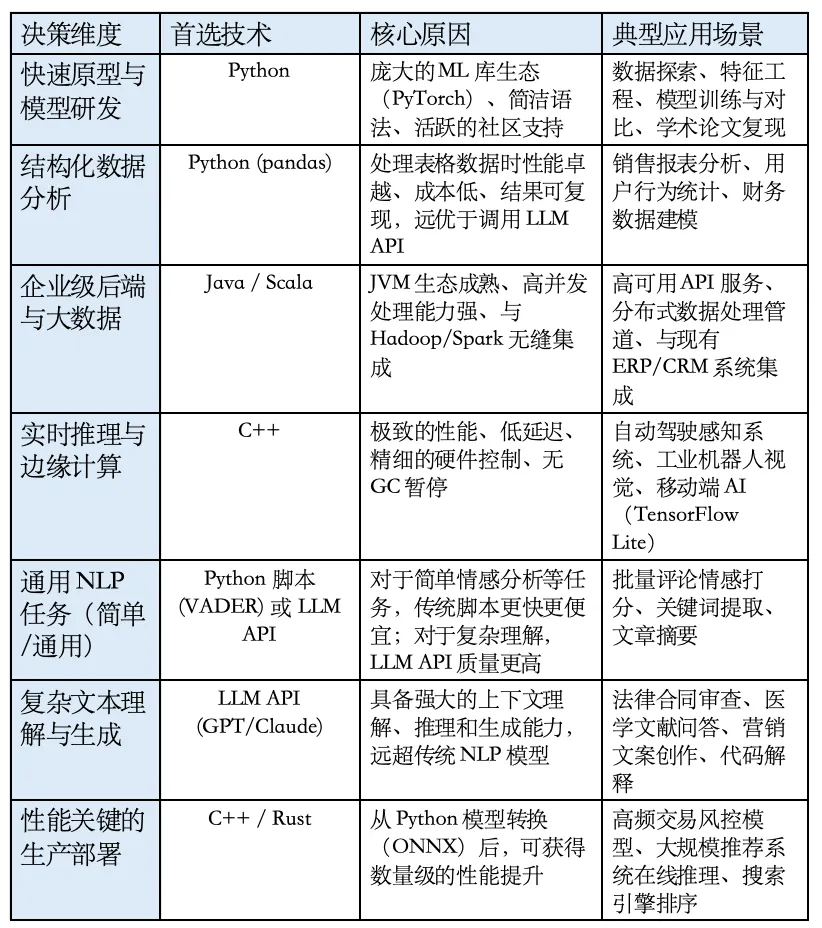
面对Python、Java、C++和大模型这四种核心技术,如何根据具体场景做出正确的选择?下表提供了一个综合性的决策框架,它综合了Coderio、Coursera、Microsoft和AgileEngine等权威机构在2025至2026年的技术建议。
1.5.1 数据分析任务:Python vs LLM API的选择
在数据分析任务中,选择使用纯Python还是调用LLM API,取决于数据的规模、任务的复杂度和成本的考量。对于结构化的、大规模的数据集,例如超过1万行的表格,使用Python的Pandas和scikit-learn库进行处理和建模,在速度和成本上具有压倒性优势。LLM API通常是按token收费的,将大量数据通过API进行处理会产生高昂的费用,并且存在数据隐私的风险。此外,Python脚本的可复现性和可维护性也远优于依赖外部API的解决方案。然而,对于小规模的、探索性的数据分析任务,或者当分析师不熟悉编程时,使用像PandasAI这样集成了LLM的工具,可以通过自然语言提问快速获得洞察,这种便利性在某些场景下是值得付出一定API成本的。
1.5.2 文本分析任务:传统NLP vs 大模型的选择
文本分析任务的选型决策更为 nuanced。对于简单的、通用的情感分析,如判断一条推文是正面还是负面,使用Python的VADER或TextBlob等库,在速度和成本上远优于调用LLM API 。这些传统工具已经针对这类任务进行了高度优化。但是,当任务涉及到复杂的语义理解、领域特定的知识推理、或需要处理长篇文档中的复杂逻辑关系时,LLM的优势就显现出来了。例如,要求模型从一份法律合同中提取特定条款、分析其潜在风险,并根据过往案例给出建议,这类任务超出了传统NLP脚本的能力范围,必须依赖LLM强大的推理和知识整合能力。因此,决策的关键在于评估任务所需的“理解深度”:是模式匹配和统计规律,还是真正的语义推理和知识应用。
1.5.3 系统开发任务:三种语言的协同模式
在构建完整的AI应用系统时,三种语言的协同工作是最优解。一个典型的架构是:使用Python进行模型训练和实验;将训练好的模型通过ONNX或TorchScript转换为高性能格式;使用C++或Rust编写高性能的推理服务;最后,通过Java或Go构建API网关和业务逻辑层,将AI能力集成到企业应用中。这种“多语言AI栈”的模式,允许开发团队在项目的不同阶段、不同层次上,选择最合适的工具,从而在保证开发效率的同时,满足生产环境对性能、稳定性和可扩展性的严苛要求。例如,Netflix、Spotify和Instagram等公司,其推荐引擎和内容发现系统的后端大量使用Python,但这些Python服务通常被集成在由Java或Scala构建的更大规模的微服务架构中。
参考文献
1.Andrej Karpathy (2017, 2025). “Software 2.0” and “Software is changing (again)” Keynote at YC AI Startup School. Karpathy’s framework distinguishes Software 1.0 (human-written code), 2.0 (learned neural network weights), and 3.0 (LLM prompting with natural language), providing the foundational paradigm for understanding the evolution of programming in the AI era (36kr.com) .
2.Gartner (2025-2026). “Predicts 2026: AI-Assisted Development” and related Low-Code/No-Code forecasts. Gartner forecasts that by 2026, 75% of new enterprise applications will use low-code technologies, and 75% of developers will focus on orchestration rather than direct coding, highlighting the massive market shift towards AI-augmented development (firstlinesoftware.com) .
3.CRISP-DM Special Interest Group (1999). CRISP-DM 1.0: Step-by-step data mining guide. This cross-industry standard process model, developed by SPSS, NCR, and other companies, remains the foundational methodology for translating business problems into data mining tasks, with its six-phase iterative cycle (CSDN博客) .
4.Yann LeCun (2024-2026). Critiques of LLM limitations and advocacy for World Models. As a Turing Award winner and “Godfather of Deep Learning,” LeCun’s arguments that LLMs lack world models, logical reasoning, and data efficiency, and his subsequent founding of AMI Labs to pursue world models, provide a critical counterpoint to uncritical LLM adoption (mike.gold) .
5.Coderio, Coursera, Microsoft (2025-2026). Technical guides on AI programming languages. Multiple authoritative sources consistently map Python to research/prototyping, Java to enterprise backend, and C++ to high-performance inference, forming the basis of the polyglot AI stack recommendation (Coderio) .
6.Jason G. Adelanado et al. (2024). “A Comprehensive Analysis of Various Tokenizers for Arabic Large Language Models”. Published in Applied Sciences (MDPI), this academic paper provides empirical evidence that tokenizer choice significantly impacts model performance across different NLP tasks, supporting the argument that understanding tokenization remains valuable (MDPI) .
7.Scikit-learn Development Team (2024-2026). Official documentation and release notes. Scikit-learn remains the core library for classical ML on tabular data in 2026, with its consistent API and integration with NumPy/Pandas making it indispensable for structured data analysis and interpretable modeling (Sprintzeal) .
8.LazyProgrammer (2026). “Is Classic / Traditional Machine Learning Dead?”. This influential technical blog post argues against the notion that traditional ML is obsolete, emphasizing that statistical intuition and mathematical foundations are durable skills that remain highly valuable, even as tooling evolves (Lazy Programmer) .
9.J. Bećirović et al. (2025). “A Comparative Survey of PyTorch vs TensorFlow for Deep Learning”. This academic survey provides detailed performance benchmarks and trade-off analysis between the two dominant deep learning frameworks, noting PyTorch’s ~25.5% faster training in some CNN workloads and its dominance in research adoption (>55% of papers) (arXiv.org) .













 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
