GESP Python四级2026年3月真题解析
- 2026-06-30 14:19:51

GESP Python四级2026年3月真题解析
「GESP练题小程序艾墨舟编程小先锋」专为GESP考生打造的免费题库。涵盖图形化/Python/C++全真题,支持真题模考、考前预测、错题整理与学习统计,一站式攻克客观题。
---✨ 第1题 ✨---
题目:2026年春节联欢晚会节目《武BOT》中,将机器人视作一个计算机系统,下面哪一项不能作为输入设备?
选项详解:
| 程序是软件,属于系统的一部分,不是输入设备。输入设备负责将外部信息输入计算机。 | ||
考查知识点:计算机硬件基础(输入设备)。
答案:B
---✨ 第2题 ✨---
题目:下面代码用来找出输入的N个正整数中最大的一个。如果将代码段用流程图来表示,则L1标记的代码行应该使用的图形是?
代码:
Max = 0
N = int(input())
while(N):
val = int(input())
if val > Max: #L1
Max = val
N -= 1
print(Max)
选项详解:
| 菱形框用于表示判断/分支。L1行是if判断语句,在流程图中应用菱形框表示。 |
考查知识点:流程图符号。
答案:D
---✨ 第3题 ✨---
题目:执行以下Python代码后,输出的结果是?
代码:
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
total = 0
for row in matrix:
for element in row:
if element % 2 == 0:
total += element
print(total)
解析:
代码遍历二维列表matrix中的所有元素,如果元素是偶数(element % 2 == 0),则将其累加到total中。
偶数元素有:2, 4, 6, 8。
总和为:2 + 4 + 6 + 8 = 20。
考查知识点:二维列表遍历、条件判断、累加求和。
答案:C
---✨ 第4题 ✨---
题目:执行以下Python代码,说法正确的是?
代码:
tup = (1, [2, 3], 4)
tup[1] = [5, 6]
选项详解:
| 正确。尝试修改元组元素会引发TypeError。 | ||
考查知识点:元组的不可变性。
答案:C
---✨ 第5题 ✨---
题目:执行以下Python代码后,输出的结果是?
代码:
words = ["hello", "world", "python"]
result = [char for word in words for char in word if char in 'aeiou']
print(len(result))
解析:
这是一个嵌套列表推导式。
1. for word in words: 遍历列表words中的每个单词。
2. for char in word: 遍历每个单词中的每个字符。
3. if char in 'aeiou': 筛选出元音字母(a, e, i, o, u)。
单词中的元音字母:
- "hello": e, o -> 2个
- "world": o -> 1个
- "python": o -> 1个
总计:2 + 1 + 1 = 4个。result列表长度为4。
考查知识点:列表推导式、字符串遍历、条件筛选。
答案:B
---✨ 第6题 ✨---
题目:函数定义def func(*args): pass中的*args会将传入的参数打包成什么类型?
选项详解:
*args打包的结果不是列表。 | ||
**kwargs用于打包关键字参数为字典。 | ||
正确。*args用于接收任意数量的位置参数,并将其打包成一个元组。 | ||
考查知识点:函数参数、可变位置参数。
答案:C
---✨ 第7题 ✨---
题目:在嵌套函数中,需要修改外层函数(非全局作用域)的变量,应使用哪个关键字?
选项详解:
global | ||
正确。nonlocal用于声明并修改嵌套函数外层(非全局)作用域的变量。 | ||
local关键字。 | ||
outer关键字。 |
考查知识点:变量作用域、nonlocal关键字。
答案:B
---✨ 第8题 ✨---
题目:执行以下Python代码后,输出的结果是?
代码:
def process_data(data):
result = []
for item in data:
if item > 0:
result.append(item * 2)
elif item < 0:
result.append(abs(item))
else:
result.append(0)
return result
output = process_data([-2, 0, 3, -1])
print(sum(output))
解析:
函数process_data根据输入列表的每个元素进行处理:
- 如果元素>0,将其乘以2后加入结果列表。
- 如果元素<0,取其绝对值后加入结果列表。
- 如果元素==0,将0加入结果列表。
输入[-2, 0, 3, -1]的处理过程:
- -2 -> abs(-2) = 2
- 0 -> 0
- 3 -> 3 * 2 = 6
- -1 -> abs(-1) = 1
结果列表为[2, 0, 6, 1],其和为 2 + 0 + 6 + 1 = 9。
考查知识点:函数定义、列表操作、条件分支、abs()函数。
答案:D
---✨ 第9题 ✨---
题目:关于lambda匿名函数,以下描述正确的是?
选项详解:
lambda: 5。 | ||
正确。lambda函数的语法是lambda 参数1, 参数2, ...: 表达式。 | ||
return。 |
考查知识点:lambda匿名函数。
答案:C
---✨ 第10题 ✨---
题目:文件text.txt的内容如下。程序统计单词"Python"在文件中出现的次数。Python后面是空格或行尾,且不跟标点。请补全代码。
代码:
count = 0
with open("text.txt", "r") as f:
content = f.________ # 补全代码
words = content.split()
for word in words:
if word == "Python":
count += 1
print("Python出现次数:", count)
选项详解:
split()操作会出错,因为content是列表。 | ||
正确。read()将整个文件内容读取为一个字符串,适合用split()分割成单词列表。 | ||
考查知识点:文件读取方法。
答案:B
---✨ 第11题 ✨---
题目:以下代码的时间复杂度是?
代码:
def func(n):
sum = 0
for i in range(n):
for j in range(i):
sum += j
return sum
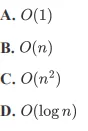
解析:
外层循环i从0到n-1,循环n次。
内层循环j从0到i-1,循环次数取决于i。
总循环次数为:0 + 1 + 2 + ... + (n-1) = n(n-1)/2。
因此,时间复杂度为O(n^2)。
考查知识点:时间复杂度分析(循环嵌套)。
答案:C
---✨ 第12题 ✨---
题目:执行以下Python代码后,输出的结果是?
代码:
try:
print(1, end="")
raise ValueError("x")
except ValueError as e:
print(2, end="")
else:
print(3, end="")
finally:
print(4, end="")
解析:try-except-else-finally执行流程:
1. 执行try块:打印"1",然后主动抛出ValueError异常。
2. 异常被except捕获:打印"2"。
3. else块:仅在try块没有发生异常时执行。此处发生了异常,所以不执行。
4. finally块:无论是否发生异常都会执行。打印"4"。
最终输出为"124"。
考查知识点:异常处理机制(try-except-else-finally)。
答案:B
---✨ 第13题 ✨---
题目:以下代码使用插入排序对列表进行升序排序。空白处应填入?
代码:
def insertion_sort_optimized(arr):
n = len(arr)
for i in range(1, n):
key = arr[i] # 当前待插入元素
j = i - 1
while j >= 0 and arr[j] > key:
arr[j + 1] = arr[j] # 元素后移
j -= 1
_______________ # 插入元素到正确位置
选项详解:
正确。当while循环结束时,j指向最后一个比key大的元素的前一个位置,或者为-1。j+1就是key应该插入的位置。 | ||
j-1可能越界或不是正确位置。 | ||
key,而不是插入key。 | ||
key原本就来自arr[i],且经过后移,arr[i]可能已被覆盖。 |
考查知识点:插入排序算法。
答案:A
---✨ 第14题 ✨---
题目:阅读以下Python代码,下列说法正确的是?
代码:
n = int(input())
def is_palindrome(s):
return s == s[::-1]
max_palindrome = 0
for i in range(10 ** (n - 1), 10 ** n):
for j in range(i, 10 ** n):
product = i * j
if is_palindrome(str(product)) and product > max_palindrome:
max_palindrome = product
print(max_palindrome)
选项详解:
正确。i和j的循环范围都是n位数,product是它们的乘积,代码寻找最大的回文乘积。 | ||
考查知识点:回文数判断、循环嵌套、算法理解。
答案:B
---✨ 第15题 ✨---
题目:以下代码实现了根据分数返回等级的功能,请选择正确的选项填入①②处。
代码:
grade_map = {90: "A", 80: "B", 70: "C", 60: "D", 0: "F"}
def get_grade(score):
if score < 0 or score > 100:
return "无效分数"
for key in sorted(grade_map.keys(), reverse=True):
if score >= key:
return _____①_____
score = int(input())
grade = get_grade(score)
print(f"分数 {score} 的等级是 {_____②_____}")
选项详解:
score可能不是grade_map中的键(如85)。 | |||
key。 | |||
grade,而不是分数score。 | |||
正确。①根据阈值key返回对应等级。②输出变量grade。 |
考查知识点:字典操作、排序、函数返回值。
答案:D
---✨ 第16题 ✨---
题目:小明的妈妈最近刚刚给他买了一块电话手表,除了可以看时间,小明也可以用它和妈妈打电话、收发信息,那么可以推测这块手表中装有一款特定操作系统。
选项详解:
| 正确。能够管理硬件资源(如通信模块、显示、输入),并支持多任务(通话、信息、时间)的设备,通常运行着操作系统(如嵌入式系统或智能手表系统)。 | ||
考查知识点:操作系统概念。
答案:A
---✨ 第17题 ✨---
题目:在Python语言中,一个集合可以作为另一个集合的元素。
选项详解:
| 正确。 |
考查知识点:集合的特性、可哈希性。
答案:B
---✨ 第18题 ✨---
题目:执行以下Python代码后,输出的结果是 <class 'set'>。
代码:
my_set = {i: j for i, j in zip([1, 2], [3, 4])}
print(type(my_set))
解析:
代码使用的是字典推导式(因为表达式是i: j),生成的是字典{1: 3, 2: 4},而不是集合。因此type(my_set)的结果是<class 'dict'>。
考查知识点:字典推导式与集合推导式的区别。
答案:B
---✨ 第19题 ✨---
题目:执行以下Python代码后,输出的结果是 20 10。
代码:
def func(a, b):
a = a ^ b
b = a ^ b
a = a ^ b
return a, b
a, b = func(10, 20)
print(a, b)
解析:
这段代码使用异或运算交换两个变量的值。
初始:a=10, b=20。
1. a = a ^ b = 10 ^ 20
2. b = a ^ b = (10 ^ 20) ^ 20 = 10 (因为20 ^ 20 = 0)
3. a = a ^ b = (10 ^ 20) ^ 10 = 20 (因为10 ^ 10 = 0)
函数返回(20, 10),所以打印20 10。
考查知识点:异或运算、变量交换。
答案:A
---✨ 第20题 ✨---
题目:执行以下Python代码后,输出的结果是 [6, 7]。
代码:
print(list(filter(lambda x: x > 5, [3, 6, 7, 2])))
解析:filter(function, iterable)函数过滤出iterable中使得function返回True的元素。lambda x: x > 5是一个判断元素是否大于5的函数。
列表[3, 6, 7, 2]中,大于5的元素是6和7。filter对象转换为列表后是[6, 7]。
考查知识点:filter()函数、lambda表达式。
答案:A
---✨ 第21题 ✨---
题目:执行以下Python代码后,输出的结果是 '789\n456'。
代码:
with open('test.txt', 'w') as f:
f.write('123\n456')
with open('test.txt', 'r+') as f:
f.seek(0, 2)
f.write('789')
f.seek(0)
print(repr(f.read()))
解析:
1. 第一次with:以写模式打开文件,写入'123\n456'。文件内容为123\n456。
2. 第二次with:以'r+'(读写)模式打开文件。
3. f.seek(0, 2):将文件指针移动到文件末尾。0表示偏移量,2表示从文件末尾计算。
4. f.write('789'):在文件末尾追加写入'789'。此时文件内容为123\n456789。
5. f.seek(0):将文件指针移回文件开头。
6. f.read():读取整个文件内容,得到字符串'123\n456789'。repr()函数显示字符串的原始形式(包括转义字符),所以输出是'123\n456789'。题目给出的'789\n456'是错误的。
考查知识点:文件读写、seek()方法、repr()函数。
答案:B
---✨ 第22题 ✨---
题目:下面这段程序的时间复杂度为平方阶。
代码:
def func(n):
for i in range(n):
for j in range(n):
if i % 2 == 0:
break
解析:
虽然有两层循环,但内层循环在i为偶数时会立即break,所以内层循环最多执行1次。
当i为奇数时,内层循环会执行n次。
但总体来看,外层循环n次,内层循环的执行次数并不固定,但最坏情况下(当i为奇数时),内层循环执行n次。然而,由于break的存在,平均或严格分析,时间复杂度并非简单的O(n^2)。实际上,内层循环在约一半的情况下执行1次,另一半情况下执行n次,总操作次数约为 n/2 * 1 + n/2 * n = n/2 + n^2/2,其主项仍是n^2/2,所以时间复杂度为O(n^2)。但题目表述“时间复杂度为平方阶”可能意在考查是否注意到break的影响。严格来说,该代码的时间复杂度是O(n^2),因为break并没有改变最坏情况(当所有i都是奇数时,内层循环每次都执行n次)。考虑到i的奇偶性,最坏情况确实可能发生。因此,该说法可以认为是正确的。但结合GESP四级考纲(简单复杂度估算)和常见判断题陷阱,可能期望判断为错误,因为break使得很多内层循环提前退出。然而,从最坏情况复杂度分析原则,它仍是O(n^2)。
注意:根据标准的最坏情况复杂度分析,该函数的时间复杂度是O(n^2)。因此原题说法“时间复杂度为平方阶”是正确的。
考查知识点:时间复杂度分析、循环中的break。
答案:A
---✨ 第23题 ✨---
题目:执行以下Python代码后,会抛出异常ZeroDivisionError。
代码:
data = {'a': 1}
index = int(input())
print(data['b'] / index)
解析:
代码执行顺序:
1. 尝试访问字典data中不存在的键'b',会先引发KeyError异常。
2. 由于异常发生在除法运算data['b'] / index之前,程序会因KeyError而终止,不会执行到除法运算。因此不会抛出ZeroDivisionError(除非data['b']能成功获取值且index为0)。
考查知识点:异常类型、代码执行顺序。
答案:B
---✨ 第24题 ✨---
题目:在对列表进行排序时,sorted()函数会返回一个新的排序后的列表,不修改原列表,而sort()方法会直接修改原列表,返回值为None。
选项详解:
正确。这正是sorted()内置函数和列表的sort()方法的主要区别。 | ||
考查知识点:列表排序方法sorted()与sort()的区别。
答案:A
---✨ 第25题 ✨---
题目:阅读以下递推算法的Python代码,执行后的输出结果是13。
代码:
a, b = 1, 2
for i in range(3):
a, b = b, a + b
print(b)
解析:
模拟递推过程(类似斐波那契数列):
初始:a=1,b=2。
循环3次:
- i=0:a, b = 2, 1+2->a=2, b=3
- i=1:a, b = 3, 2+3->a=3, b=5
- i=2:a, b = 5, 3+5->a=5, b=8
循环结束后打印b,结果为8,不是13。
考查知识点:递推、变量同时赋值。
答案:B
---✨ 第26题 ✨---
试题名称:山谷
题目描述:
一片山地视为n行m列的网格,每个单元格有海拔。如果一个单元格的海拔不高于其所有相邻单元格(8个方向)的海拔,则称该单元格为山谷。求山谷的数量。
解题思路:
1. 读入n, m和海拔矩阵。
2. 遍历每个单元格(i, j)。
3. 对于每个单元格,遍历其周围的8个相邻单元格(注意边界判断)。
4. 如果存在任意一个相邻单元格的海拔低于当前单元格,则当前单元格不是山谷。
5. 只有当所有相邻单元格的海拔都不低于(即大于或等于)当前单元格时,当前单元格才是山谷,计数加1。
6. 注意:题目条件是“不高于”,即“小于或等于”。在判断时,我们检查是否有相邻格子低于当前格子,如果有则不是山谷。
复杂度分析:
- 时间复杂度:O(n * m * 8) = O(nm),因为每个单元格检查最多8个邻居。
- 空间复杂度:O(nm),用于存储海拔矩阵。
参考代码:
# 输入行列数
n, m = map(int, input().split())
# 输入每一行的海拔
h = []
for i in range(n):
row = list(map(int, input().split()))
h.append(row)
ans = 0
# 遍历每一个单元格
for i in range(n):
for j in range(m):
is_valley = True
# 遍历周围8个方向
for dx in range(-1, 2):
for dy in range(-1, 2):
# 排除自己
if dx == 0 and dy == 0:
continue
ni, nj = i + dx, j + dy
# 检查边界
if 0 <= ni < n and 0 <= nj < m:
# 如果存在相邻格子海拔更低,则不是山谷
if h[ni][nj] < h[i][j]:
is_valley = False
break
if not is_valley:
break
if is_valley:
ans += 1
print(ans)
代码说明:
- 使用两层循环遍历所有单元格。
- 对于每个单元格,使用两层内循环遍历周围8个方向(dx, dy从-1到1)。
- 通过if dx == 0 and dy == 0: continue排除自身。
- 检查邻居时,如果发现海拔更低的邻居,立即标记is_valley = False并跳出循环。
- 最后根据is_valley的值决定是否计数。
---✨ 第27题 ✨---
试题名称:礼盒排序
题目描述:
有n个礼盒,每个礼盒有k件商品,每件商品有价格。排序规则:
1. 总价从小到大。
2. 总价相同,按最贵商品价格从小到大。
3. 仍相同,按最便宜商品价格从小到大。
4. 仍相同,按礼盒编号从小到大。
输出排序后的礼盒编号。
解题思路:
1. 读入n, k和每个礼盒的商品价格列表。
2. 对于每个礼盒i(编号从1开始),计算其总价s、最大值mx、最小值mn。
3. 将(s, mx, mn, i)作为一个元组存入列表v。这里i是礼盒编号。
4. 利用Python列表的sort()方法对v进行排序。由于元组默认按元素顺序比较,正好符合题目要求:先比较s(总价),再比较mx(最大值),再比较mn(最小值),最后比较i(编号)。
5. 排序后,依次输出每个元组的第四个元素(即编号)。
复杂度分析:
- 时间复杂度:O(n * k + n log n),其中O(n*k)用于计算每个礼盒的sum、max、min,O(n log n)用于排序。
- 空间复杂度:O(n),用于存储礼盒信息列表。
参考代码:
n, k = map(int, input().split())
v = []
for i in range(n):
nums = list(map(int, input().split()))
s = sum(nums)
mx = max(nums)
mn = min(nums)
v.append((s, mx, mn, i + 1)) # 编号从1开始
v.sort() # 元组默认按元素顺序比较
# 输出编号
for i in range(n):
print(v[i][3], end=" " if i < n - 1 else "")
print()
代码说明:
- 使用sum(), max(), min()内置函数快速计算总价、最贵和最便宜商品价格。
- 将排序依据的四个属性放入一个元组,利用元组的比较特性实现多关键字排序,简洁高效。
- 输出时注意末尾空格的处理。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 嵌入式Linux,学应用还是驱动?
- llama.cpp在Linux上安装使用指南
- 如何用Python+AI打造一个能自动回复的聊天机器人?
- 【零基础玩转Python】Day42:数据排序与排名 – sort_values, rank,让数据有序竞争
- OpenAI Python SDK 实战:responses.create 和 responses.parse 到底怎么选?
- Python是最适合 AI 代码生成的语言?答案可能出乎意料
- 用Python做科研级画图——分组误差
- 如何使用pyinstaller对python程序进行打包
- Python 零基础100天—Day26 正则表达式基础
- 31.Python实战__自定义类的导入和使用2
