全文链接:https://tecdat.cn/?p=46112
在当今数据驱动的商业环境中,如何从海量用户行为数据中提炼出可执行的洞察,并构建高精度的预测系统,是学术界与工业界共同关注的核心难题。作为长期深耕于机器学习与数据挖掘算法领域的从业者,我们深刻理解将前沿模型落地于真实业务场景所面临的挑战:数据是异构的,模型是盲目的,而业务逻辑往往隐藏在复杂的关联背后。
本文旨在通过端到端的AI解决方案,解决客户的用户留存与满意度预测的痛点。我们摒弃了传统仅依赖单一模型或孤立分析的思路,而是构建了一个从数据清洗、多模型对比到AI增强分析与交互式应用的全链路系统。本文将我们的XGBoost分类预测建模经验沉淀为一个对话式AI智能体,它不仅是一个预测工具,更是一个融合了业务常识的决策支持系统。通过对配送时效、支付方式等核心因素的精准量化,我们不仅揭示了影响用户好评的关键杠杆,还通过一个创新性的单调性约束方法,确保了模型预测逻辑与业务直觉的完美对齐。希望本文能为致力于将AI技术转化为商业价值的研究者与开发者,提供一个清晰且可复现的实践范例。
阅读原文进群获取本文完整代码、数据、AI智能体及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
How to build an end-to-end intelligent agent system that encompasses data analysis, model prediction, business insight generation, and interactive display?
陈鑫
交通运输专业毕业
专注数据分析、数据挖掘与深度学习
在此对陈鑫对本文所作的贡献表示诚挚感谢,他毕业于交通运输专业,现任交通大学就业指导中心岗位分析员,专注数据分析、数据挖掘与深度学习领域。擅长使用Python进行数据处理、建模与可视化,致力于将机器学习算法应用于交通行为分析与商业场景洞察。
数据分析与购买预测项目 │ ├── 1. 业务背景与数据总览 │ ├── 数据表关系与规模 │ └── 核心表字段含义 │ ├── 2. 分析流程与核心脚本 │ ├── 数据清洗 → 可视化 → 机器学习 │ ├── AI增强分析 → 报告生成 → 漏斗分析 │ └── 运行教程 │ ├── 3. 交互式数据仪表盘 │ ├── 5页交互式仪表盘 │ └── 核心图表展示 │ ├── 4. 核心发现:配送时效 │ ├── 交互式预测实验 │ └── 真实数据验证 │ ├── 5. 商业诊断:漏斗分析 │ ├── 订单漏斗 vs 客户漏斗 │ └── RFM客户分层 │ ├── 6. 技术攻坚:单调性约束 │ ├── 问题、根因与解决方案 │ ├── 两轮对话驱动建模 │ │ ├── 第一轮:基础模型构建 │ │ └── 第二轮:引入领域知识约束 │ └── 效果验证 │ └── 7. 策略建议与项目总结 ├── 可落地的业务建议 ├── 项目收获 └── 成果概览
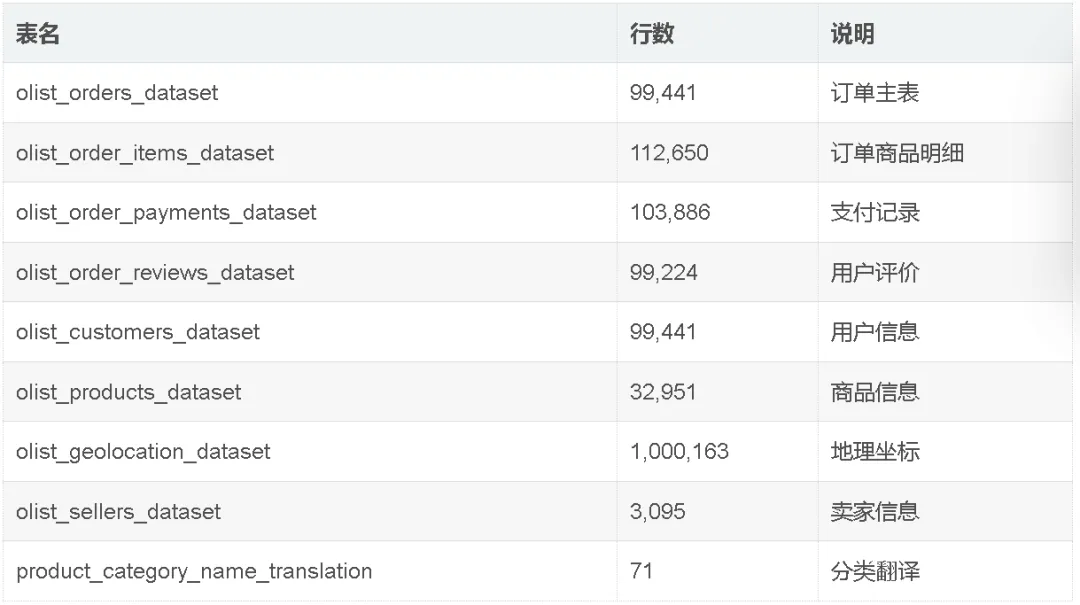
本项目利用某大型电商平台2016年10月至2018年10月的真实交易数据进行深入分析。该数据集包含9张互相关联的表格,总计155万行数据,覆盖了从下单、支付到评价的完整交易链路。其核心关系为:以订单表为中心,通过外键关联支付表、评价表、订单明细表等8张辅助表,形成一个星型结构。数据集的规模与结构如下所示。
这些表格通过order_id、customer_id等键关联,最终被清洗合并为一张包含113,314行、41个特征的主分析表。
本项目采用Python作为主要分析语言,构建了一套包含6个核心脚本的流水线,依次完成数据清洗、可视化、机器学习、AI增强分析、报告生成和客户分群等任务。
安装依赖: pip install -r requirements.txt
数据清洗: python 01_data_cleaning.py
数据可视化: python 02_visualization.py
机器学习建模: python 03_machine_learning.py
启动仪表盘: streamlit run streamlit_app.py
项目最核心的成果是一个5页的交互式数据仪表盘,它将分析结果以直观、可交互的方式呈现,是向决策者汇报的理想工具。
| | |
|---|
| | |
| | |
| | |
| | LangGraph架构图、模型自动生成的商业洞察报告 |
| | |
仪表盘中的所有图表均为交互式,支持鼠标缩放、悬停查看数值等操作,极大提升了数据探索的效率。
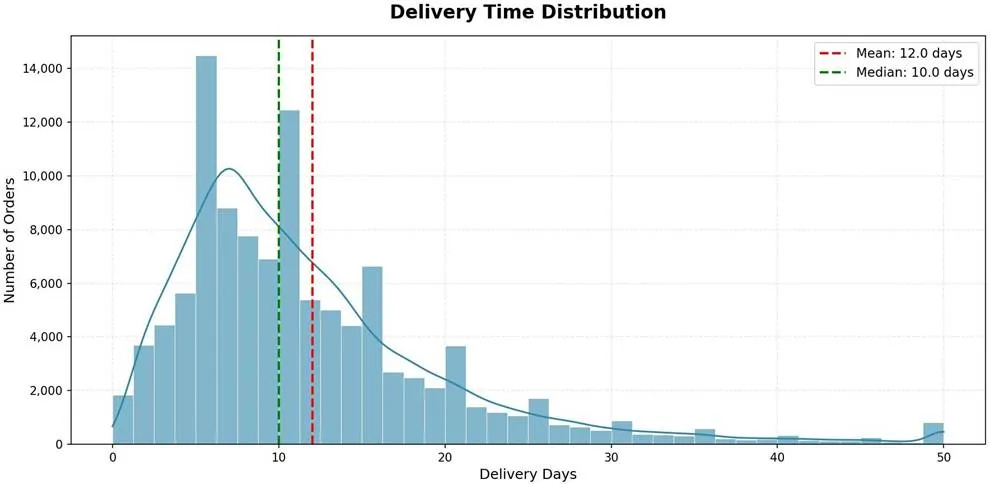
仪表盘第5页的交互式预测工具直观地展示了各特征对好评概率的影响。我们通过控制变量法进行对比:在保持商品价格、运费、支付方式和买家地域完全相同的前提下,仅改变配送天数。
结论十分清晰:在所有其他条件不变时,配送天数从5天延长至30天,会导致好评概率从86.7%暴跌至39.0%,配送速度是决定性因素。
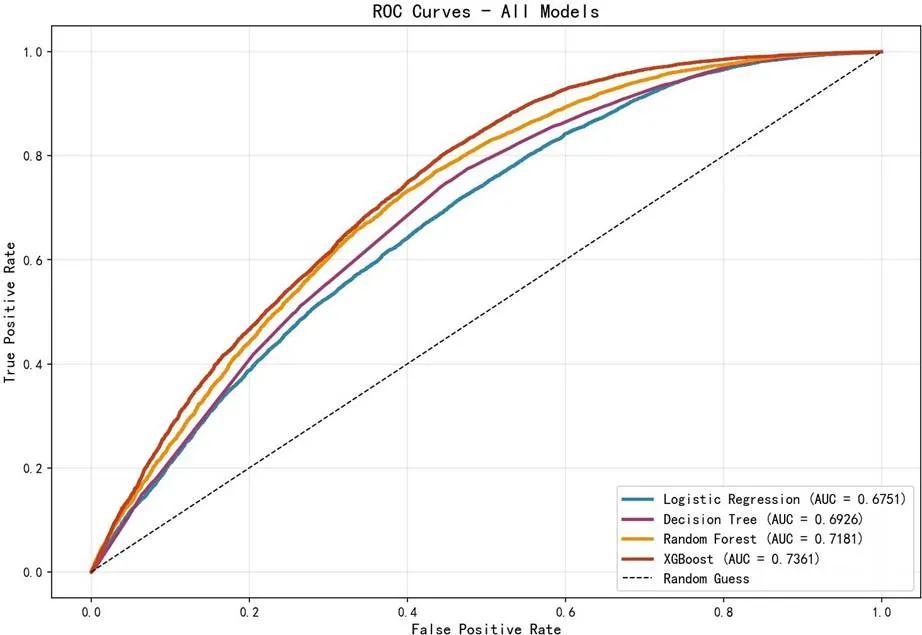
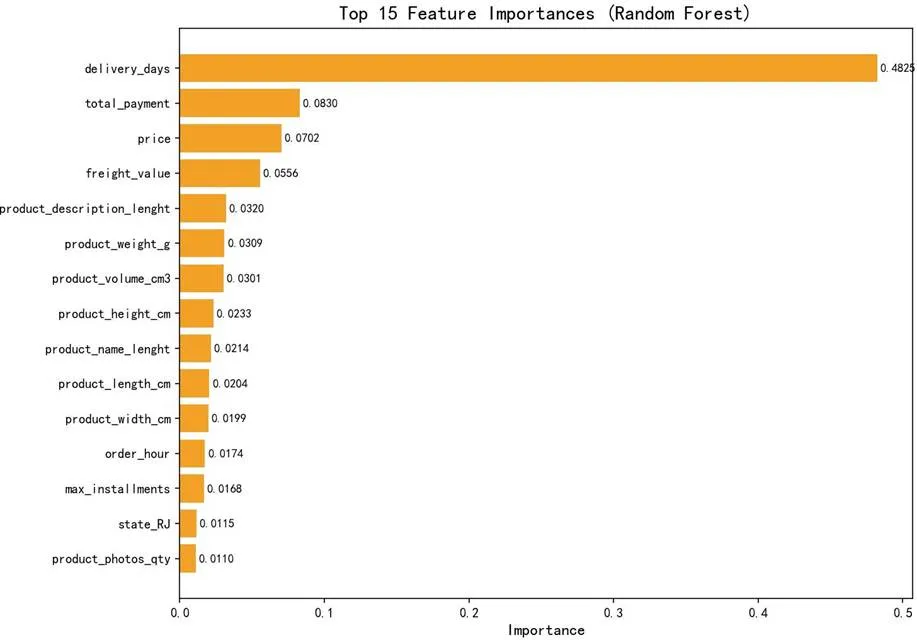
结论:统计结果表明,两者存在极强负相关(Spearman相关系数为-0.98)。从1天到30天,好评率下降了64.5个百分点。XGBoost模型的特征重要性排名也佐证了这一点:delivery_days(配送天数)的重要性得分远高于price(价格)和total_payment(付款总额)。
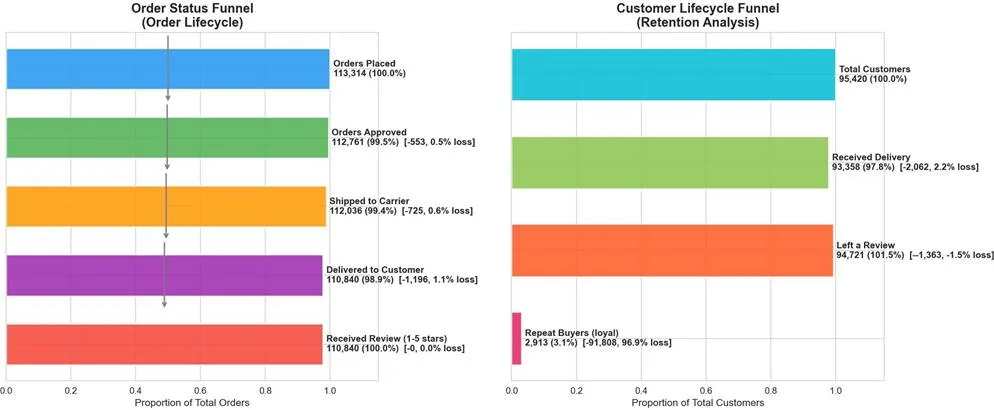
通过漏斗分析,我们发现了一个深刻的问题:平台的运营能力存在巨大不平衡。
核心洞察:订单漏斗的98.9%送达率堪称完美,而客户漏斗的3.1%复购率却触目惊心。这揭示了平台"重交付、轻留存"的运营模式。
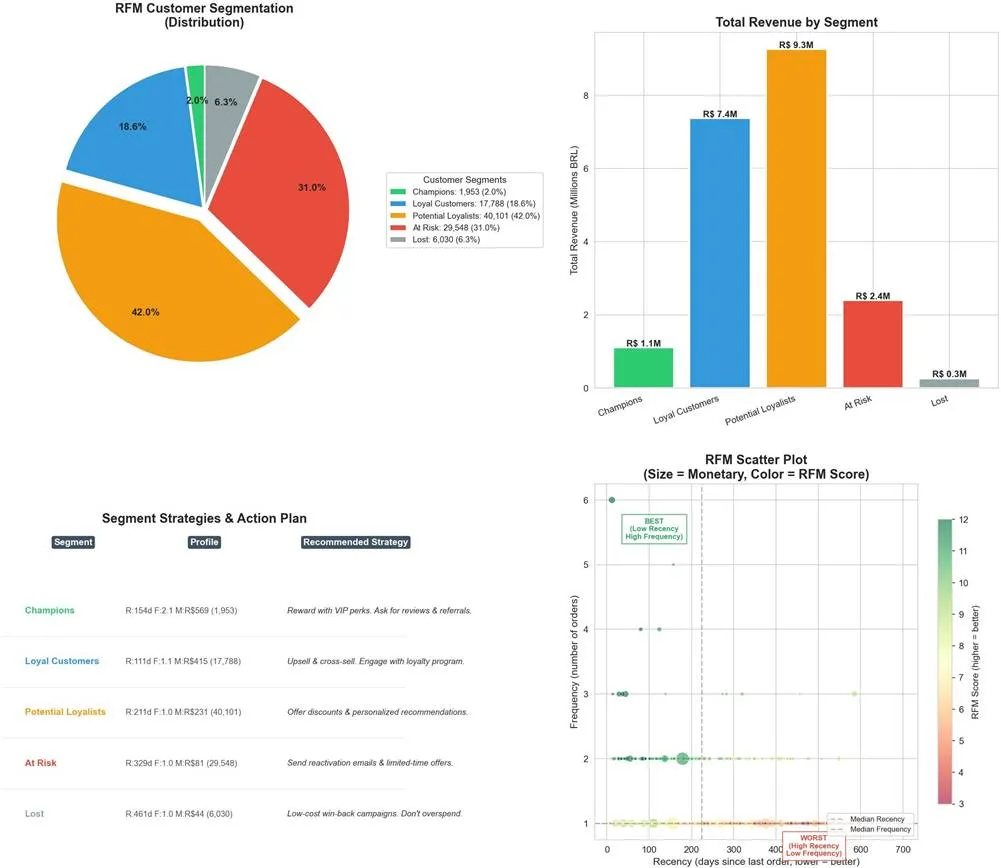
运用RFM模型,我们将全部客户按消费行为分为5个等级,从而实现精细化运营。
核心洞察:42%的"潜力忠诚"客户是最大的增长金矿——他们体验过服务且满意,只是尚未形成消费习惯。通过小成本激励这部分用户复购,将是投资回报率最高的增长策略。
在开发中,我们遇到一个关键技术难点:初始XGBoost模型在3-8天区间内预测的好评率反常地低于9天以上,违背了真实数据呈现的单调递减规律。
以下是实现该约束的核心代码片段。我们先看第一轮对话,如何提出基础建模需求。
我需要对一份清洗好的电商订单数据构建预测模型。数据已经分为训练集X_train, X_test和目标变量y_train, y_test。目标变量y是二分类的,表示是否好评。请帮我用XGBoost构建一个分类器,先用默认参数进行训练,并输出F1分数和AUC值作为初步评估。
from sklearn.metrics import f1_score, roc_auc_score basic_model = xgb.XGBClassifier( random_state=42, n_jobs=-1 ) basic_model.fit(X_train_data, y_train_data) initial_predictions = basic_model.predict(X_test_data) prob_predictions = basic_model.predict_proba(X_test_data)[:, 1] initial_f1 = f1_score(y_test_data, initial_predictions) initial_auc = roc_auc_score(y_test_data, prob_predictions) print(f"初始模型 F1 Score: {initial_f1:.4f}") print(f"初始模型 AUC Score: {initial_auc:.4f}")
模型初步结果符合预期,但我们从业务逻辑得知,特征delivery_days对好评率的影响应该是严格负向的,即配送时间越长,好评概率越低。请修改模型,为delivery_days特征加入单调递减约束,其他特征不做约束,并重新训练评估,确保预测逻辑与业务常识一致。
通过一行monotone_constraints代码,我们不仅修复了模型的逻辑缺陷,还意外地提升了模型性能。
核心洞察:添加约束后,模型F1得分不降反升,这强有力地证明:将正确的领域知识注入模型,比完全放任其自由学习更有效,能同时提升模型的可信度与准确性。
优化物流网络:在核心市场设立前置仓,将平均配送时长压缩至7天以内。预期可使好评率提升7%,并显著降低因配送慢导致的差评。
激活潜力客户:针对42%的"潜力忠诚"客户,在购买后14天内推送关联商品优惠券,降低二次购买门槛。若将复购率从3.1%提升至10%,等于增加数千个二次订单。
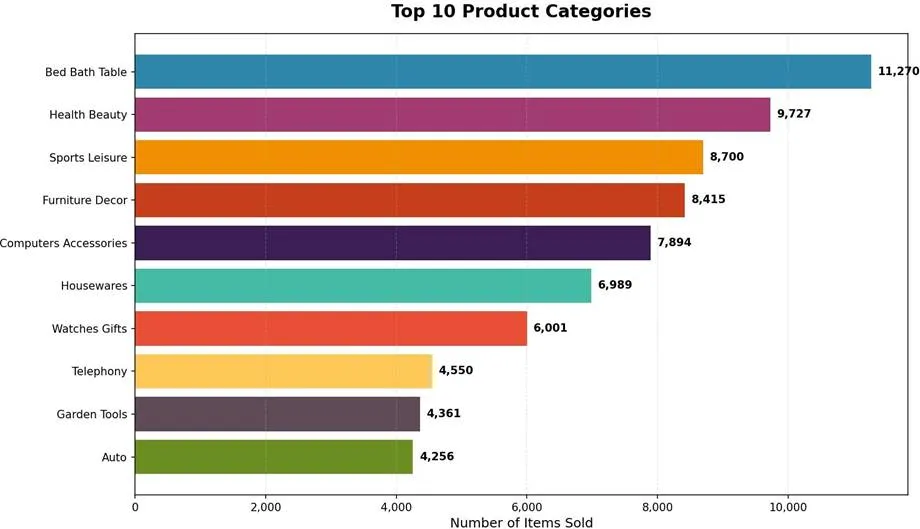
聚焦核心品类:家居家装、健康美容、运动休闲是销量前三的品类,合计贡献超25%的销量。应给予首页置顶、免运费等流量和资源倾斜。
优化支付体验:引导使用银行汇票的用户转向信用卡分期,降低支付摩擦,提高下单转化率。
一句话总结:若有效解决用户留存率低的问题,平台的商品交易总额将有望实现翻倍增长。
| | |
|---|
| | |
| | |
| | |
| Python + XGBoost + LangGraph + DeepSeek | |
| | |
本文配套的建模可直接套用的AI智能体、完整代码包,可加小助手:tecdat_cn领取。
作者系机器学习与数据挖掘领域分析师,拥有多年算法实现与业务建模经验。
本文中分析的完整智能体、数据、代码、文档分享到会员群,扫描下面二维码即可加群!
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。
点击文末“阅读原文”
获取完整智能体、
代码、数据和文档。







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
