前言
“为什么同样的学历,他的工资是我的两倍?”——这个问题困扰过无数打工人。
抛开运气和机遇不谈,从数据科学的角度来看,年龄、学历、职业、工作时长这些因素到底能在多大程度上决定一个人的收入水平?如果能用一个模型来量化这些关系,我们就能更客观地理解"高薪密码"。
本文使用经典的 UCI Adult 人口普查收入数据集,带你从零走完一个完整的机器学习分类项目:数据探索 → 特征工程 → 模型训练 → 评估优化。不只是跑代码,更讲清楚每一步"为什么这么做"。
一、项目全景概览
1.1 项目目标
根据人口普查数据(年龄、学历、职业、婚姻状况等14个特征),预测个人年收入是否超过 $50,000。这是一个典型的二分类问题。
1.2 数据来源
数据集来自 UCI Machine Learning Repository,由 Barry Becker 从 1994 年美国人口普查局数据库中提取。
- 数据集地址:https://archive.ics.uci.edu/ml/datasets/adult
- 样本量:32,561 条训练数据 + 16,281 条测试数据
1.3 项目流程架构图
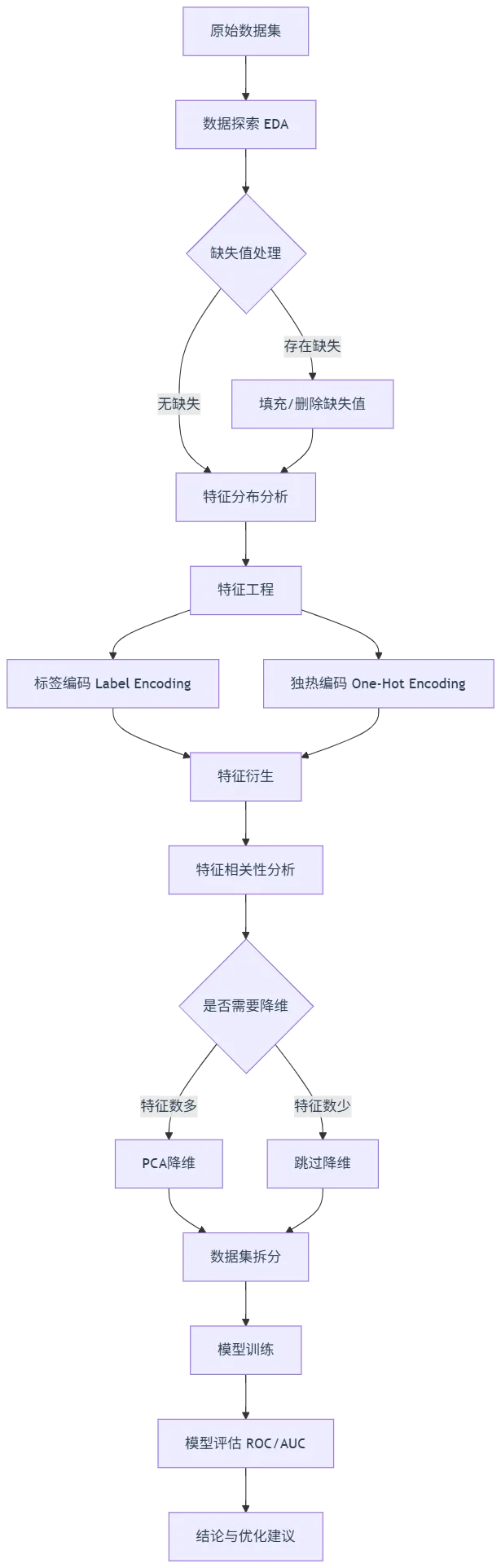
1.4 数据集特征一览
| | | | |
|---|
| | | | |
| | | | Private, Self-emp, Federal-gov |
| | | | |
| | | | Bachelors, Masters, HS-grad |
| | | | |
| | | | Married, Divorced, Never-married |
| | | | Tech-support, Sales, Exec-managerial |
| | | | |
| | | | White, Black, Asian-Pac-Islander |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | United-States, China, India |
二、环境准备与数据加载
2.1 导入依赖
库
# 数据处理与可视化import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns# 机器学习from sklearn.model_selection import train_test_split, cross_val_scorefrom sklearn.preprocessing import LabelEncoder, StandardScalerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import ( accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, roc_curve, confusion_matrix, classification_report)# 降维(备用)from sklearn.decomposition import PCA# 忽略警告import warningswarnings.filterwarnings('ignore')# 设置中文显示plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']plt.rcParams['axes.unicode_minus'] = Falseprint("✅ 环境准备完成")
2.2 加载数据集
# UCI Adult 数据集列名(不含标签列)column_names = [ 'age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital_status', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_per_week', 'native_country', 'predclass']# 加载训练集和测试集train_data = pd.read_csv( 'https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data', names=column_names, sep=',\s*', engine='python', na_values='?')test_data = pd.read_csv( 'https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test', names=column_names, sep=',\s*', engine='python', na_values='?', skiprows=1)print(f"训练集形状: {train_data.shape}")print(f"测试集形状: {test_data.shape}")print(f"\n训练集标签分布:\n{train_data['predclass'].value_counts()}")
⚠️ 注意:测试集文件第一行是注释行,需要用 skiprows=1 跳过;分隔符是 , (逗号+空格),使用正则 ,\s* 处理。
三、数据探索(EDA)
3.1 整体概览
# 查看数据基本信息print("=" * 50)print("数据集基本信息")print("=" * 50)print(train_data.info())print("\n" + "=" * 50)print("统计描述(连续型特征)")print("=" * 50)print(train_data.describe())print("\n" + "=" * 50)print("离散型特征分布")print("=" * 50)for col in ['workclass', 'education', 'marital_status', 'occupation', 'race', 'sex']: print(f"\n--- {col} ---") print(train_data[col].value_counts().head(5))
3.2 缺失值检查
# 检查各列缺失值print("=" * 50)print("缺失值统计")print("=" * 50)missing = train_data.isnull().sum()missing_pct = (missing / len(train_data)) * 100missing_df = pd.DataFrame({ '缺失数量': missing, '缺失比例(%)': missing_pct.round(2)})print(missing_df[missing_df['缺失数量'] > 0].sort_values('缺失数量', ascending=False))
常见输出:
3.3 标签分布可视化
# 标签分布饼图fig, axes = plt.subplots(1, 2, figsize=(14, 5))# 饼图labels = ['<=50K', '>50K']sizes = train_data['predclass'].value_counts().valuescolors = ['#ff9999', '#66b3ff']axes[0].pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90, explode=(0, 0.05))axes[0].set_title('收入标签分布(训练集)', fontsize=14, fontweight='bold')# 柱状图train_data['predclass'].value_counts().plot(kind='bar', ax=axes[1], color=['#ff9999', '#66b3ff'], edgecolor='black')axes[1].set_title('收入标签数量对比', fontsize=14, fontweight='bold')axes[1].set_ylabel('样本数量')axes[1].set_xticklabels(['<=50K', '>50K'], rotation=0)plt.tight_layout()plt.savefig('label_distribution.png', dpi=150, bbox_inches='tight')plt.show()
📊 关键发现:数据集存在明显的类别不平衡问题——约 76% 的样本收入 ≤50K,仅 24% 收入 >50K。这意味着如果模型"偷懒"全预测 ≤50K,也能拿到 76% 的准确率。后续需要用 AUC 而非准确率来评估模型。
四、数据预处理与特征工程
4.1 缺失值处理
# 策略:用众数填充离散型特征的缺失值for col in ['workclass', 'occupation', 'native_country']: mode_val = train_data[col].mode()[0] train_data[col].fillna(mode_val, inplace=True) test_data[col].fillna(mode_val, inplace=True) print(f"✅ {col}: 缺失值已用众数 '{mode_val}' 填充")# 验证缺失值是否全部处理assert train_data.isnull().sum().sum() == 0, "❌ 训练集仍有缺失值!"assert test_data.isnull().sum().sum() == 0, "❌ 测试集仍有缺失值!"print("\n✅ 所有缺失值已处理完毕")
4.2 标签编码(Label Encoding)
对于有序的离散特征,使用标签编码:
# education 是有序的,用 Label Encodingedu_order = [ 'Preschool', '1st-4th', '5th-6th', '7th-8th', '9th', '10th', '11th', '12th', 'HS-grad', 'Some-college', 'Assoc-voc', 'Assoc-acdm', 'Bachelors', 'Masters', 'Prof-school', 'Doctorate']# 创建映射字典edu_mapping = {level: idx for idx, level in enumerate(edu_order)}train_data['education_encoded'] = train_data['education'].map(edu_mapping)test_data['education_encoded'] = test_data['education'].map(edu_mapping)print("✅ education 标签编码完成")print(f"编码范围: {train_data['education_encoded'].min()} ~ {train_data['education_encoded'].max()}")
⚠️ 常见错误:对无序离散特征(如 workclass、occupation)使用 Label Encoding 会导致模型误以为"Private(0) < Self-emp(1) < Federal-gov(2)",引入虚假的顺序关系。
4.3 独热编码(One-Hot Encoding)
对于无序的离散特征,使用独热编码:
# 需要 One-Hot 编码的特征列表onehot_cols = ['workclass', 'marital_status', 'occupation', 'relationship', 'race', 'sex', 'native_country']# 对训练集和测试集分别编码train_encoded = pd.get_dummies(train_data, columns=onehot_cols, drop_first=True)test_encoded = pd.get_dummies(test_data, columns=onehot_cols, drop_first=True)# 对齐列(测试集可能缺少某些类别)train_encoded, test_encoded = train_encoded.align(test_encoded, join='left', axis=1, fill_value=0)print(f"One-Hot 编码后训练集特征数: {train_encoded.shape[1]}")print(f"One-Hot 编码后测试集特征数: {test_encoded.shape[1]}")
💡 drop_first=True:删除每个特征的第一个类别(作为基准),避免虚拟变量陷阱(多重共线性)。
4.4 特征衍生
从原始特征中组合出新特征,挖掘更深层的信息:
# 连续型特征衍生:age × hours_per_week(工作经验强度)train_encoded['work_intensity'] = train_encoded['age'] * train_encoded['hours_per_week']test_encoded['work_intensity'] = test_encoded['age'] * test_encoded['hours_per_week']# 连续型特征衍生:capital_gain - capital_loss(净资本收益)train_encoded['net_capital'] = train_encoded['capital_gain'] - train_encoded['capital_loss']test_encoded['net_capital'] = test_encoded['capital_gain'] - test_encoded['capital_loss']# 离散型特征衍生:sex + marital_status 组合# (已在 One-Hot 编码中体现,此处可跳过)print("✅ 特征衍生完成")print(f"新增特征: work_intensity, net_capital")print(f"当前特征总数: {train_encoded.shape[1]}")
4.5 特征相关性分析
# 计算相关性矩阵corr_matrix = train_encoded.corr()# 可视化(取前15个特征)plt.figure(figsize=(14, 10))top_features = corr_matrix.abs().mean().sort_values(ascending=False).head(15).indexsns.heatmap(train_encoded[top_features].corr(), annot=True, fmt='.2f', cmap='RdBu_r', center=0, square=True, linewidths=0.5)plt.title('特征相关性热力图(Top 15)', fontsize=14, fontweight='bold')plt.tight_layout()plt.savefig('correlation_heatmap.png', dpi=150, bbox_inches='tight')plt.show()
五、建模与评估
5.1 数据集拆分
# 分离特征和标签X = train_encoded.drop(['predclass', 'education'], axis=1)y = (train_encoded['predclass'] == '>50K').astype(int) # 转换为 0/1# 注意:测试集标签格式不同(带句点)X_test = test_encoded.drop(['predclass', 'education'], axis=1)y_test = (test_encoded['predclass'] == '>50K.').astype(int)# 训练/验证集拆分(8:2)X_train, X_val, y_train, y_val = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y)print(f"训练集: {X_train.shape[0]} 样本")print(f"验证集: {X_val.shape[0]} 样本")print(f"测试集: {X_test.shape[0]} 样本")print(f"\n训练集正类比例: {y_train.mean():.2%}")print(f"验证集正类比例: {y_val.mean():.2%}")
⚠️ 关键参数 stratify=y:确保拆分后训练集和验证集的标签比例一致,避免某一方正类比例严重偏离。
5.2 模型训练——逻辑回归
# 标准化(逻辑回归对特征尺度敏感)scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_val_scaled = scaler.transform(X_val)X_test_scaled = scaler.transform(X_test)# 训练逻辑回归模型lr = LogisticRegression( max_iter=1000, # 增加迭代次数确保收敛 class_weight='balanced', # 处理类别不平衡 random_state=42)lr.fit(X_train_scaled, y_train)print("✅ 逻辑回归模型训练完成")
5.3 模型评估
# 预测y_val_pred = lr.predict(X_val_scaled)y_val_prob = lr.predict_proba(X_val_scaled)[:, 1]# 分类报告print("=" * 60)print("📊 验证集分类报告")print("=" * 60)print(classification_report(y_val, y_val_pred, target_names=['<=50K', '>50K']))# 混淆矩阵cm = confusion_matrix(y_val, y_val_pred)print("\n📊 混淆矩阵:")print(f" 预测<=50K 预测>50K")print(f"实际<=50K {cm[0][0]:>6}{cm[0][1]:>6}")print(f"实际>50K {cm[1][0]:>6}{cm[1][1]:>6}")# ROC-AUCauc_score = roc_auc_score(y_val, y_val_prob)print(f"\n🎯 ROC-AUC: {auc_score:.4f}")
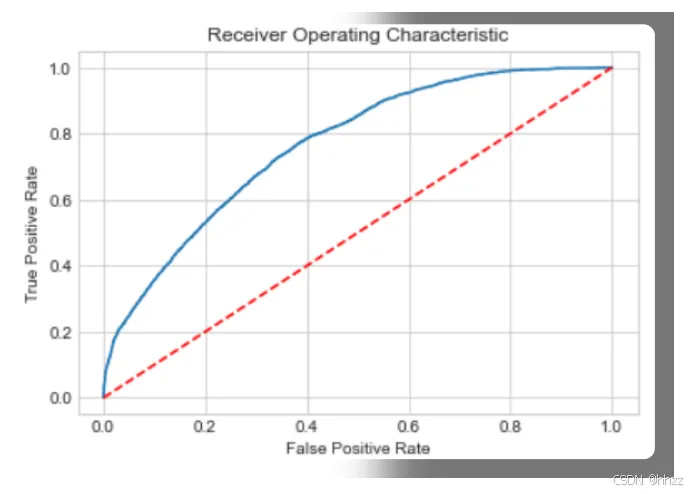
5.4 ROC 曲线绘制
# 计算 ROC 曲线fpr, tpr, thresholds = roc_curve(y_val, y_val_prob)# 绘制plt.figure(figsize=(8, 6))plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'Logistic Regression (AUC = {auc_score:.3f})')plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--', label='随机猜测 (AUC = 0.500)')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('假正率 (False Positive Rate)', fontsize=12)plt.ylabel('真正率 (True Positive Rate)', fontsize=12)plt.title('ROC 曲线 — 工资分类预测', fontsize=14, fontweight='bold')plt.legend(loc='lower right')plt.grid(alpha=0.3)plt.tight_layout()plt.savefig('roc_curve.png', dpi=150, bbox_inches='tight')plt.show()
ROC 曲线解读:
六、踩坑记录与解决方案
🐛 坑1:测试集标签格式不匹配
问题描述: 直接使用 train_data['predclass'] == '>50K' 转换训练集标签没问题,但测试集标签带了一个句点 >50K.,导致所有标签都被错误地标记为 0。
# ❌ 错误写法y_test = (test_data['predclass'] == '>50K').astype(int)# 结果:全部为 0!因为实际值是 '>50K.'# ✅ 正确写法print(test_data['predclass'].unique()) # 先查看实际值# 输出: [' <=50K.' ' >50K.']y_test = (test_data['predclass'].str.strip() == '>50K.').astype(int)
教训: 加载外部数据集后,第一步永远是 print(df['label'].unique()) 检查标签格式。
🐛 坑2:One-Hot 编码后训练集和测试集列数不一致
问题描述: 测试集中某些离散特征的类别在训练集中没有出现过(或反之),导致 pd.get_dummies 生成的列数不同,模型无法预测。
# ❌ 错误写法train_dummy = pd.get_dummies(train_data, columns=['workclass'])test_dummy = pd.get_dummies(test_data, columns=['workclass'])# train_dummy 和 test_dummy 列数可能不同!# ✅ 正确写法:先合并再拆分,或使用 aligntrain_dummy = pd.get_dummies(train_data, columns=['workclass'])test_dummy = pd.get_dummies(test_data, columns=['workclass'])train_dummy, test_dummy = train_dummy.align( test_dummy, join='left', axis=1, fill_value=0)
教训: 对训练集和测试集做特征工程时,始终以训练集的列结构为基准,用 align 对齐。
🐛 坑3:类别不平衡导致"高准确率陷阱"
问题描述: 训练完模型后准确率达到 80%+,沾沾自喜。但一看混淆矩阵——模型把所有样本都预测为 ≤50K,对 >50K 的召回率为 0!
# 准确率有欺骗性print(f"准确率: {accuracy_score(y_val, y_val_pred):.2%}")# 输出: 准确率: 76.2% ← 看起来不错?# 但正类召回率可能很低print(f">50K 召回率: {recall_score(y_val, y_val_pred):.2%}")# 输出: >50K 召回率: 12.5% ← 真相大白!
解决方案:
# 方案1:设置 class_weight='balanced'lr = LogisticRegression(class_weight='balanced')# 方案2:调整决策阈值y_val_prob = lr.predict_proba(X_val_scaled)[:, 1]threshold = 0.3 # 降低阈值,提高正类召回率y_val_pred_adjusted = (y_val_prob >= threshold).astype(int)# 方案3:使用更适合不平衡数据的评估指标print(f"AUC: {roc_auc_score(y_val, y_val_prob):.4f}") # 不受类别不平衡影响
七、模型优化方向
7.1 当前模型性能总结
| | |
|---|
| | |
| | 预测为 >50K 的样本中 70% 确实 >50K |
| | |
| | |
| | |
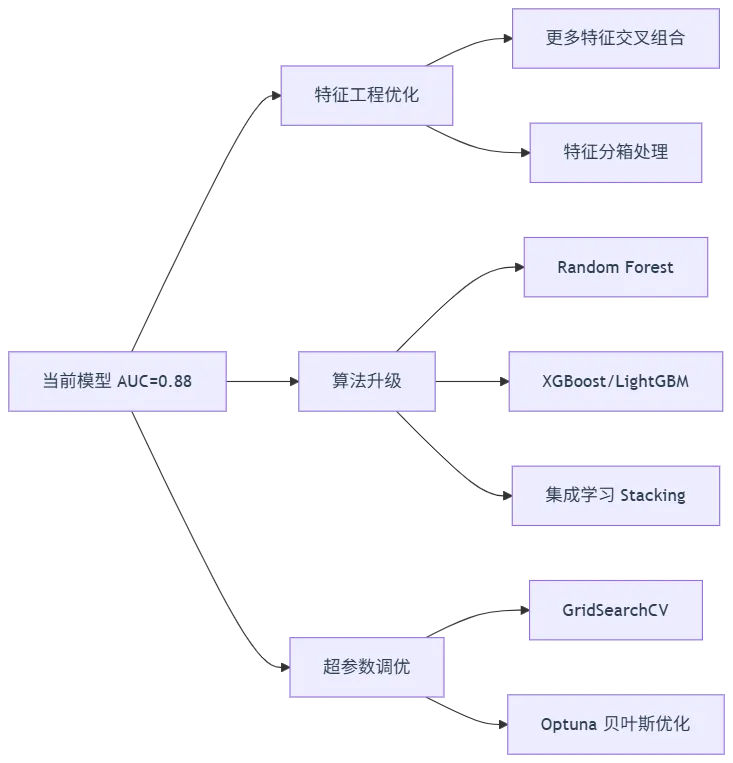
7.2 后续优化建议
八、总结与展望
8.1 本文核心要点
- 项目流程:从数据加载 → EDA → 缺失值处理 → 特征编码 → 特征衍生 → 建模评估,完整走通了一个分类项目
- 关键技巧:Label Encoding vs One-Hot Encoding 的选择、类别不平衡的处理、ROC-AUC 的正确使用
- 踩坑教训:测试集标签格式检查、One-Hot 编码列对齐、不要被高准确率迷惑
8.2 完整代码获取
本文完整代码已整理在以下仓库(可一键运行):
git clone https://github.com/your-repo/python-bigdata-projects.gitcd python-bigdata-projects/03-salary-predictionpython main.py
8.3 下一篇预告
下一篇我们将进入广告点击转化率预测项目,这是一个更贴近工业界实战的场景——如何处理超高维稀疏特征、如何应对极度不平衡的 CTR 数据(点击率通常只有 0.1%~1%),以及如何使用 FTRL 等在线学习算法。敬请期待!
参考链接
- UCI Adult 数据集官方页面 — 数据集详细说明和下载
- Scikit-learn 逻辑回归文档 — 官方 API 参考
- Understanding AUC - ROC Curve — ROC 曲线深度解读
- Imbalanced Classification Guide — 类别不平衡处理策略大全
📝 声明:本文为原创内容,数据集来自 UCI Machine Learning Repository 公开数据集。代码和图表均为作者独立编写。
🐾 作者:阿虎 | 系列:Python大数据实战 | 日期:2026-06-24
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
