【粉丝真实需求】外贸办公 Python 自动化・提单水印批量实战 6/6
- 2026-06-30 04:52:32
【粉丝真实需求】外贸办公 Python 自动化・提单水印批量实战 6/6点击上方“Python爬虫与数据挖掘”,进行关注 上一篇文章我们已经完成了客户的需求,一共提供了两个方法,顺利地完成了项目交付。这一篇文章我们针对客户提出的新要求,批量的对文件夹中的.doc文件进行处理替换,分享带批量遍历、异常容错、进程自清理、安全备份的 WPS 兼容全流水线代码。 前面的文章我们逐个踩坑:从错误 zip 解析 doc、Shape 抓取 0 匹配、WPS Shapes 属性报错、Find 检索失效、Word.Quit 兼容崩溃等问题出发,一步步摸透老式 doc 单证自动化的所有隐性陷阱。这篇文章在单文件的踩坑基础上,直接上批量实现。话不多说,直接上代码。 我本地也拿了两份文件进行测试,测试了这个批量的代码,发现运行正常,如下图所示。 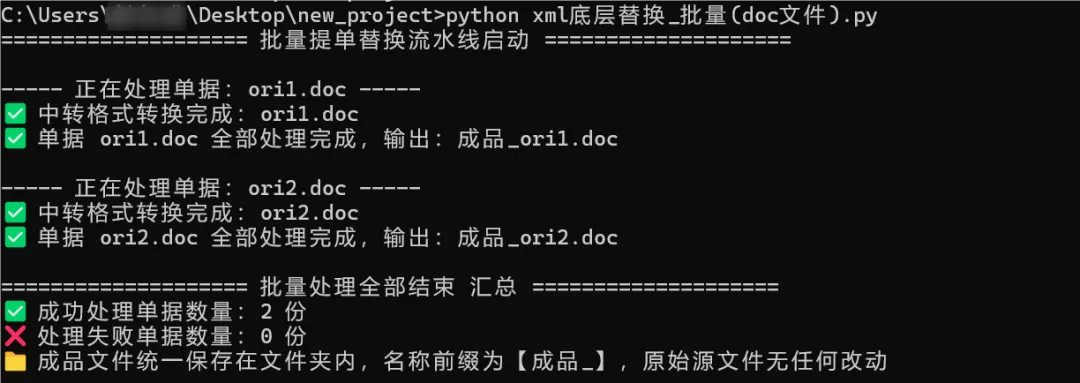
而且打开文件校验后发现如期替换成功。进一步说明了代码的可用性。有一说一,AI给的代码虽然可行,但是看上去代码确实AI,我理解应该有更加优化的代码,欢迎大家一起积极探索。 好了,以上就是【粉丝真实需求】外贸办公 Python 自动化・提单水印批量实战系列文章了,希望通过这次真实需求下的Python 自动化办公,能让大家感受到Python 自动化的魅力。如果大家平时也有遇到Python 自动化办公问题,不妨评论区聊聊。当然了,有需求的话,也可以随时联系我。 
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
横看成岭侧成峰,远近高低各不同。
前一阵子针对近期爆火的《给阿嬷的情书》电影写了一篇Python网络爬虫+数据分析文章,基于 Python 的《给阿嬷的情书》豆瓣短评文本挖掘与情感分析(附数据分析代码),当前阅读量已经突破1.2w了,是今年迄今为止本公众号阅读量最高的一篇文章。正是因为这篇文章的贡献,也让许多粉丝慕名前来,加上了好友。部分粉丝在工作和学习中,遇到了一些难题,提了一些自己的需求,我把需求也及时同步发布到我的接单群了。
import osimport shutilimport zipfileimport win32com.clientimport subprocess# ======================== 【公众号读者仅需修改这里2行】 ========================# 存放所有待处理提单doc的文件夹绝对路径WORK_FOLDER = r"C:\Users\Desktop\new_project"# 水印新旧文本(复制艺术字内完整文字,避免换行空格匹配失败)OLD_WATERMARK = "Non-Negotiable"NEW_WATERMARK = "Original"# ============================================================================# 临时缓存文件夹(程序自动创建删除,无需手动操作)TEMP_DOCX_CACHE = "temp_doc_cache"def kill_winword_process():"""【WPS兼容核心补丁】替代Word.Quit(),强制清理后台Office进程解决WPS COM无Quit属性、进程残留锁死文件问题"""try:# 强制终止所有WINWORD后台进程subprocess.call(["taskkill", "/f", "/im", "WINWORD.EXE"],stdout=subprocess.PIPE,stderr=subprocess.PIPE)except Exception:# 无进程时静默跳过,不抛报错passdef single_doc_to_docx(source_doc_path, output_docx_path):"""步骤1:单个老式.doc 中转转为 .docx仅做格式转换,不修改任何单据内容、排版样式"""# 初始化COM对象word_app = win32com.client.Dispatch("Word.Application")word_app.Visible = False # 后台静默运行,不弹出Word窗口word_app.DisplayAlerts = 0 # 屏蔽弹窗警告run_success = Falsetry:# 只读打开源doc文件,保护原始单据doc_file = word_app.Documents.Open(os.path.abspath(source_doc_path))# FileFormat=16 → 标准docx格式doc_file.SaveAs(os.path.abspath(output_docx_path), FileFormat=16)doc_file.Close()run_success = Trueprint(f"✅ 中转格式转换完成:{os.path.basename(source_doc_path)}")except Exception as err:print(f"❌ 转换失败 {os.path.basename(source_doc_path)}:{str(err)}")finally:# 释放COM对象内存del word_app# 强制清理后台进程kill_winword_process()return run_successdef xml_replace_watermark(docx_input, docx_output):"""步骤2:docx底层XML全局替换水印(稳定100%捕获页眉艺术字)纯标准库zip操作,无COM图形读取,彻底规避Shapes属性报错"""temp_unzip_dir = "tmp_unzip_buffer"# 清理上次解压残留if os.path.exists(temp_unzip_dir):shutil.rmtree(temp_unzip_dir)os.mkdir(temp_unzip_dir)# 1. 解压docx压缩包with zipfile.ZipFile(docx_input, "r") as zip_reader:zip_reader.extractall(temp_unzip_dir)# 2. 遍历全部XML文件,全局替换水印文本for root_path, _, file_names in os.walk(temp_unzip_dir):for file_name in file_names:if file_name.endswith(".xml"):full_file_path = os.path.join(root_path, file_name)# 读取XML文本with open(full_file_path, "r", encoding="utf-8") as f:xml_content = f.read()# 替换水印文字xml_content = xml_content.replace(OLD_WATERMARK, NEW_WATERMARK)# 写回修改后的XMLwith open(full_file_path, "w", encoding="utf-8") as f:f.write(xml_content)# 3. 重新打包生成修改后的docxwith zipfile.ZipFile(docx_output, "w", zipfile.ZIP_DEFLATED) as zip_writer:for root_path, _, file_names in os.walk(temp_unzip_dir):for file_name in file_names:full_file_path = os.path.join(root_path, file_name)# 计算压缩包内相对路径relative_path = os.path.relpath(full_file_path, temp_unzip_dir)zip_writer.write(full_file_path, relative_path)# 清空解压缓存shutil.rmtree(temp_unzip_dir)return Truedef single_docx_to_doc(source_docx_path, output_final_doc_path):"""步骤3:修改好的docx 转回老式原生.doc格式交付客户FileFormat=0 锁定Word97-2003 .doc,杜绝字体加宽、水印偏移"""word_app = win32com.client.Dispatch("Word.Application")word_app.Visible = Falseword_app.DisplayAlerts = 0run_success = Falsetry:docx_file = word_app.Documents.Open(os.path.abspath(source_docx_path))# FileFormat=0 → 老式doc格式docx_file.SaveAs(os.path.abspath(output_final_doc_path), FileFormat=0)docx_file.Close()run_success = Trueexcept Exception as err:print(f"❌ 转回doc失败 {os.path.basename(source_docx_path)}:{str(err)}")finally:del word_appkill_winword_process()return run_successdef batch_auto_process_all_bl():"""【批量主调度函数】整篇代码闭环核心:自动遍历文件夹所有待处理提单1. 自动过滤后缀.doc,跳过已带「成品_」前缀的文件,防止二次重复处理2. 单文件失败隔离,批量不会整体崩溃3. 统计成功/失败总数,结束输出汇总报表"""# 初始化临时缓存文件夹if os.path.exists(TEMP_DOCX_CACHE):shutil.rmtree(TEMP_DOCX_CACHE)os.mkdir(TEMP_DOCX_CACHE)success_count = 0fail_count = 0print("==================== 批量提单替换流水线启动 ====================")# 遍历目标文件夹全部文件for file_name in os.listdir(WORK_FOLDER):# 筛选规则:只处理原始doc,跳过成品、docx、其他格式文件if file_name.lower().endswith(".doc") and not file_name.startswith("成品_"):origin_full_path = os.path.join(WORK_FOLDER, file_name)# 定义各阶段临时文件路径temp_mid_docx = os.path.join(TEMP_DOCX_CACHE, file_name.replace(".doc", ".docx"))modified_docx = os.path.join(TEMP_DOCX_CACHE, f"mod_{file_name.replace('.doc', '.docx')}")# 最终输出成品doc,带前缀隔离源文件final_export_doc = os.path.join(WORK_FOLDER, f"成品_{file_name}")print(f"\n----- 正在处理单据:{file_name} -----")# 流水线三步执行step1_ok = single_doc_to_docx(origin_full_path, temp_mid_docx)if not step1_ok:fail_count += 1continuestep2_ok = xml_replace_watermark(temp_mid_docx, modified_docx)step3_ok = single_docx_to_doc(modified_docx, final_export_doc)if step3_ok:success_count += 1print(f"✅ 单据 {file_name} 全部处理完成,输出:成品_{file_name}")else:fail_count += 1# 运行结束清理缓存shutil.rmtree(TEMP_DOCX_CACHE)kill_winword_process()# 批量任务汇总报表print("\n==================== 批量处理全部结束 汇总 ====================")print(f"✅ 成功处理单据数量:{success_count} 份")print(f"❌ 处理失败单据数量:{fail_count} 份")print(f"📁 成品文件统一保存在文件夹内,名称前缀为【成品_】,原始源文件无任何改动")# 程序入口启动if __name__ == "__main__":batch_auto_process_all_bl()
今日鸡汤分享:没有那么多天赋异禀,优秀的人总是在努力翻山越岭!
说明:我平时有正式工作,只做兼职副业,只接合理、合法、正规用途的需求,不接违法、违规、恶意攻击类项目。有需要的朋友可以直接留言。加了我微信后,我会自动发送一些自动回复,如有打扰,请忽略即可。那个都是我的微信,绝对是真人,你给我正常发消息即可,必回!
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的vx:2584914241),应粉丝要求,我创建了一些高质量的Python学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群。
------------------- End -------------------
往期精彩文章推荐:
欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

